一种基于改进yolov5模型的路边施工行为检测方法
技术领域
1.本发明涉及图像检测领域,尤其涉及一种基于改进yolov5模型的路边施工行为检测方法。
背景技术:
2.随着燃气管线、光缆输送线等地下铺设网的逐渐丰富,对埋设区域进行实时的监控保护,需要及时发现违法施工并进行预警变得尤为重要,光缆输送线和燃气管线路的早期巡检工作主要由人工排查方式来完成的,即工作负责人员到达现场通过肉眼观察,查找并识别线路上的安全隐患点,但这种巡检方式效率低、难度大且可靠性差。如今新巡检方法逐步取代人工巡检,这个新的巡检方法是通过图像采集工具,如高清摄像机,然后工作人员可以查看和分析收集到的视频图像,以此来判断光缆输送线和燃气管线路周边是否因为施工而存在安全隐患。然而,使用这种新的巡检方法,视频终端采集图像所产生的数据量巨大,还是需要工作人员再通过肉眼看,造成工作量繁重,以及容易出现漏判或者误判的情况,而且无法及时准确地发现光缆输送线和燃气管线路上存在的安全隐患。
技术实现要素:
3.为了解决上述技术问题,本发明的目的是提供一种基于改进yolov5模型的路边施工行为检测方法,能够通过沿途摄像头捕捉的视频,对路边施工行为检测识别并预警。
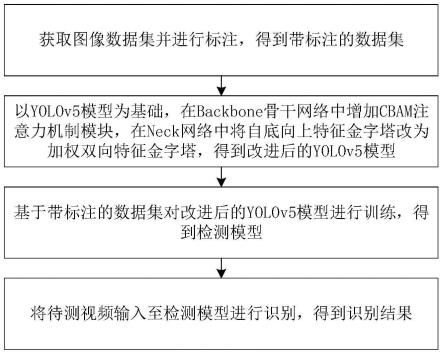
4.本发明所采用的第一技术方案是:一种基于改进yolov5模型的路边施工行为检测方法,包括以下步骤:
5.获取图像数据集并进行标注,得到带标注的数据集;
6.以yolov5模型为基础,在backbone骨干网络中增加cbam注意力机制模块,在neck网络中将自底向上特征金字塔改为加权双向特征金字塔,得到改进后的yolov5模型;
7.基于带标注的数据集对改进后的yolov5模型进行训练,得到检测模型;
8.将待测视频输入至检测模型进行识别,得到识别结果。
9.进一步,还包括:
10.根据精度指标和召回率指标评估检测模型的性能。
11.进一步,所述获取图像数据集并进行标注,得到带标注的数据集这一步骤,其具体包括:
12.获取图像数据集,所述图像图像数据集包括工程车辆、工人和施工警示物体;
13.对图像数据集进行标注,得到带标注的数据集;
14.工程车辆的标注包括挖掘机、卡车、装载机、推土机和混凝土车,施工警示物体的标注包括路锥、塑料隔离墩和施工预警牌。
15.进一步,所述改进后的yolov5模型包括输入端、backbone骨干网络、neck网络和head输出端。
16.进一步,所述基于带标注的数据集对改进后的yolov5模型进行训练,得到检测模
型这一步骤,其具体包括:
17.基于输入端对带标注的数据集中的图片进行预处理,得到预处理后的图片;
18.基于backbone骨干网络对预处理后的图片进行特征提取,得到初步特征图;
19.基于neck网络对初步特征图进行特征融合,得到最终特征图;
20.基于head输出端根据最终特征图输出特征张量;
21.根据特征张量生成预测框信息;
22.将预测框信息与真实框进行匹配并计算损失函数,优化改进后的yolov5模型的参数,得到检测模型。
23.进一步,所述基于输入端对带标注的数据集中的图片进行预处理,得到预处理后的图片这一步骤,其具体包括:
24.将带标注的数据集输入至输入端;
25.基于mosaic方式对带标注的数据集中的图片进行数据增强,得到数据增强后的数据集;
26.根据数据增强后的数据集设定初始锚框;
27.将数据增强后的数据集中的图片进行自适应图片缩放,得到预处理后的图片。
28.进一步,所述基于backbone骨干网络对预处理后的图片进行特征提取,得到初步特征图这一步骤,其具体包括:
29.将预处理后的图片输入至backbone骨干网络;
30.基于backbone骨干网络的focus结构进行切片操作;
31.将cbam注意力机制模块置于c3模块之后;
32.基于c3模块进行特征提取并通过cbam模块加强对小目标物体的特征信息的学习,得到初步特征图。
33.进一步,所述基于neck网络对初步特征图进行特征融合,得到最终特征图这一步骤,其具体包括:
34.将初步特征图输入至neck网络;
35.基于双向特征金字塔对初步特征图在不同尺度间进行融合,通过上采样和下采样同一特征分辨率尺度,并在同一特征的原始输入和输出节点之间添加横向连接,得到最终特征图。
36.进一步,所述损失函数的公式如下所示:
[0037][0038][0039][0040][0041]
上式中,b
p
为预测边界框,bg为标注边界框,ρ为欧氏距离,p为预测边界框中心点,p
gt
为标注边界框中心点,c为框之间最小外接矩形框的对角线距离,w和h为预测边界框的宽
和高,w
gt
和h
gt
为标注边界框的宽和高,α为权重函数,v表示衡量长宽比的一致性。
[0042]
本发明方法的有益效果是:本发明通过改进现有网络模型以实现高精度检测的目的,通过沿途摄像头捕捉的视频,对路边施工的工人,路锥和挖掘机、装载机、卡车等工程车辆进行检测识别并预警,达到智能巡检的效果,具备较高的实用价值。
附图说明
[0043]
图1是本发明一种基于改进yolov5模型的路边施工行为检测方法的步骤流程图;
[0044]
图2是本发明具体实施例改进后的yolov5模型的示意图;
[0045]
图3是现有的mosaic方式数据增强的原理示意图;
[0046]
图4是本发明具体实施例mosaic方式数据增强的原理示意图;
[0047]
图5是本发明具体实施例加权双向特征金字塔的结构示意图。
具体实施方式
[0048]
下面结合附图和具体实施例对本发明做进一步的详细说明。对于以下实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
[0049]
参照图1和图2,本发明提供了一种基于改进yolov5模型的路边施工行为检测方法,该方法包括以下步骤:
[0050]
s1、获取图像数据集并进行标注,得到带标注的数据集;
[0051]
s1.1、获取图像数据集,所述图像图像数据集包括工程车辆、工人和施工警示物体;
[0052]
s1.2、对图像数据集进行标注,得到带标注的数据集;
[0053]
s1.3、工程车辆的标注包括挖掘机、卡车、装载机、推土机和混凝土车,施工警示物体的标注包括路锥、塑料隔离墩和施工预警牌。
[0054]
具体地,还包括将标注后的数据集转化为yololabel格式,并进行训练集和测试集的划分,训练集和测试集比例为8:2。
[0055]
s2、以yolov5模型为基础,在backbone骨干网络中增加cbam注意力机制模块,在neck网络中将自底向上特征金字塔改为加权双向特征金字塔,得到改进后的yolov5模型;
[0056]
具体地,所述改进后的yolov5模型包括输入端、backbone骨干网络、neck网络和head输出端。
[0057]
s3、基于带标注的数据集对改进后的yolov5模型进行训练,得到检测模型;
[0058]
s3.1、基于输入端对带标注的数据集中的图片进行预处理,得到预处理后的图片;
[0059]
具体地,图片预处理是将输入的图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,yolov5使用mosaic数据增强操作提升模型的训练速度和网络的精度,并提出了一种自适应锚框计算与自适应图片缩放方法。
[0060]
s3.1.1、将带标注的数据集输入至输入端;
[0061]
s3.1.2、基于mixup和mosaic方式对带标注的数据集中的图片进行数据增强,得到数据增强后的数据集;
[0062]
具体地,mosaic方式是一种混合四幅训练图像的数据增强方法,这种数据增强的
方法可以丰富检测物体的背景,提高检测的精度。如图3所示,现有网络的mosaic数据增强的基本流程为首先随机读取四张图片,然后分别对四张图片进行裁剪、翻转、缩放、色域变化等,并且按照四个方向位置摆好,最后再进行图片的组合。基于此,本改进的模型采用mosaic方法的增强版—mosaic-9,如图4所示,对9张图片随机裁剪、随机缩放、随机排列组合成一张图片,以此来对现有的yolov5网络模型改进,更利于小样本目标的检测。同时在mosaic-9之前采用mixup数据增强,核心思想是从每个batch中随机选择两张图像,并以一定比例混合生成新的图像。需要注意的是,全部训练过程都只采用混合的新图像训练,原始图像不参与训练过程。mixup数据增强消除对错误标签的记忆、对对抗样本的敏感性以及对抗训练的不稳定性。
[0063]
s3.1.3、根据数据增强后的数据集设定初始锚框;
[0064]
具体地,在yolov5网络中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与真实框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框也是比较关键的一环,本发明中,yolov5网络模型的初始锚框为[10,13,16,30,33,23]、[30,61,62,45,59,119]、[116,90,156,198,373,326],网络模型在初始锚框的基础上训练得到预测框,并和真实框进行差值比较,根据差值反向更新,迭代调整网络模型参数。
[0065]
s3.1.4、将数据增强后的数据集中的图片进行自适应图片缩放,得到预处理后的图片。
[0066]
具体地,在网络训练阶段,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,也就是自适应图片缩放之后,再送入检测网络中进行训练,方式能够提高模型37%推理速度。在本发明中,网络在训练过程输入的图片统一尺寸为640
×
640
×
3。
[0067]
s3.2、基于backbone骨干网络对预处理后的图片进行特征提取,得到初步特征图;
[0068]
具体地,预处理后的图片进入backbone骨干网络,进行特征提取后得到三个不同大小的特征图。
[0069]
s3.2.1、将预处理后的图片输入至backbone骨干网络;
[0070]
具体地,backbone骨干网络包含focus结构和csp结构。
[0071]
s3.2.2、基于backbone骨干网络的focus结构进行切片操作;
[0072]
具体地,focus结构中含有切片操作,将预处理后尺寸为640
×
640
×
3的图片接入focus结构中,通过切片操作与concat操作,得到160
×
160
×
12的特征图,然后进行一次32个卷积核操作,得到160
×
160
×
32的特征图。
[0073]
s3.2.3、将cbam注意力机制模块置于c3模块之后;
[0074]
s3.2.4、基于c3模块进行特征提取并通过cbam模块加强对小目标物体的特征信息的学习,得到初步特征图。
[0075]
具体地,yolov5模型里中设计了2种跨阶段局部网络csp(cross stage partial network)结构,bottleneckcsp(true)和bottleneckcsp(false)。其中,bottleneckcsp(true)结构主要应用于backbone网络中,bottleneckcsp(false)结构主要应用于head网络结构中。这两种csp结构采用了密集跨层跳层连接的思想,进行局部跨层融合,利用不同层的特征信息来获得更为丰富的特征图。另外,现有的网络模型将bottleneckcsp优化为c3模
块,其实c3模块就是是简化版的bottleneckcsp,该部分除了bottleneck之外,只有3个卷积模块,可以减少参数,所以取名c3。c3模块主要用于提取图像特征的,在backbone部分,c3模块包含的位置信息、细节信息较多,但语义信息较少。而head部分,c3模块主要进行纹理特征提取,包含的位置信息、细节信息较少,而语义信息较多。小目标特征信息在经过多个c3模块处理后,位置信息粗糙,特征信息易丢失,从而引起网络模型对小目标的误检和漏检。
[0076]
因此本方案在backbone中增加cbam注意力机制模块,置于c3模块之后,cbam模块通过通道和空间注意力模块能在网络训练过程中加强对路锥和塑料隔离墩等小目标物体的点特征、线特征等特征信息的学习。cbam可分为2部分,先是通道注意力模块(channel attention)解决在卷积池化过程中feature map的不同通道所占的重要性不同带来的损失问题,然后是空间注意力模块(spatial attention),它融合了2种注意力机制,可添加在任意网络的卷积层后面。在通道注意力模块上分别经过最大值池化和平均池化将尺寸为c
×h×
w的特征图变成c
×1×
1,经过mlp转换,压缩通道数,再通过加和操作进行合并结果,并进行sigmoid归一化,使得提取到的高层特征更全面更丰富。将通道注意力模块的输出当作输入进入空间注意力模块,同样经过最大值池化和平均池化,再通过concat操作将两者堆叠,只压缩通道维度而不压缩空间维度。关注重点在目标的位置信息,并专注于有用的目标对象。
[0077]
s3.3、基于neck网络对初步特征图进行特征融合,得到最终特征图;
[0078]
具体地,将步骤s3.2得到的三个不同大小的特征图输入neck网络进行特征融合,得到三个尺度的特征图。
[0079]
s3.3.1、将初步特征图输入至neck网络;
[0080]
s3.3.2、基于双向特征金字塔对初步特征图在不同尺度间进行融合,通过上采样和下采样同一特征分辨率尺度,并在同一特征的原始输入和输出节点之间添加横向连接,得到最终特征图。
[0081]
具体地,现有的yolov5的neck网络采用fpn pan的结构,特征金字塔fpn利用上采样的方式对信息进行传递融合,路径聚合网络pan采用自底向上的特征金字塔。pan通过在fpn结构的基础上增加一条自下而上的路径,缩短了底层特征图信息与顶层特征图信息融合的路径,整个特征图融合的过程均使用concat拼接完成。
[0082]
本方法将自底向上特征金字塔(pan)改进为双向特征金字塔(bifpn)结构,其结构如图5所示,bifpn是加权双向特征金字塔,其bifpn主要思想有两点:一是高效的双向跨尺度连接,二是加权特征图融合。运用双向融合四项,构造自上而下、自下而上的双向通道,对来自主干网络不同尺度的信息,在不同尺度间进行融合时通过上采样和下采样同一特征分辨率尺度,并在同一特征的原始输入和输出节点之间添加横向连接,在不增加成本的情况下融合更多特征。且将自顶向下和自底向上融合构造为一个模块,使其可以重复堆叠,增强信息融合。而pan只有一层自顶向下和一层自底向上的路径。而利用bifpn结构能够加强特征融合,减少卷积过程中的特征丢失,提高了检测精度。
[0083]
s3.4、基于head输出端根据最终特征图输出特征张量;
[0084]
s3.5、根据特征张量生成预测框信息;
[0085]
具体地,将步骤s3.3得到的三个尺度的特征图输入head输出端,得到三个特征张量,由此得到预测框的位置、类别和置信度。
[0086]
s3.6、将预测框信息与真实框进行匹配并计算损失函数,优化改进后的yolov5模型的参数,得到检测模型。
[0087]
具体地,在训练数据集阶段,直接将预测框与真实框进行匹配得出正负样本,然后计算yolov5损失函数(包括分类损失函数、定位损失函数和置信度损失函数);在验证集阶段,采用加权非极大值抑制,筛选出预测框,得出准确率、平均精度等评价指标来不断优化模型参数。
[0088]
head输出端包括损失函数和非极大值抑制(nms)。yolov5的损失函数包括分类损失、定位损失和置信度损失,预测框的训练过程中使用giou_loss作为定位损失函数,通过计算损失函数giou_loss调节权重参数,有效解决了边界框不重合时问题。
[0089]
现有模型的giou考虑了预测边界框和标注边界框不相交的情况,但未考虑预测边界框在目标边界框内部的情况,因此,对边框损失函数进行改进,相较于giou考虑的是重叠面积,改进的损失函数考虑了边界框的中心点距离和宽高比,增加影响因子α以考虑边界框的宽高比,其中α为权重函数,v衡量长宽比的一致性。损失函数的改进一定程度上可以提高道路周边施工行为目标的识别抗遮挡干扰能力。所述损失函数的公式如下所示:
[0090][0091][0092][0093][0094]
上式中,b
p
为预测边界框,bg为标注边界框,ρ为欧氏距离,p为预测边界框中心点,p
gt
为标注边界框中心点,c为框之间最小外接矩形框的对角线距离,w和h为预测边界框的宽和高,w
gt
和h
gt
为标注边界框的宽和高,α为权重函数,v表示衡量长宽比的一致性。
[0095]
目标检测的后处理过程中,针对出现的众多目标框的筛选,采用加权nms(非极大值抑制)的方式筛选预测框,并通过与真实框比对,获得最优目标框,并使用反向传播算法以进一步训练yolov5网络,优化模型参数。但该方法具有以下两个缺点,第一,nms仅保留得分最大的预测边界框而丢弃得分小的预测边界框,但得分较小的边界框也同样包含一定的特征信息,直接丢弃相当于没有完全利用全部信息。第二,在一些情况下得分最高的预测边界框也不能很好的拟合真实的目标框,直接选用该预测框作为最终预测值具有较高的损失,其函数关系为:
[0096][0097]
其中,si为当前选中目标框和最高置信度框产生的新置信度,iou(m,bi)是当前最高置信度预测框m与剩余第i个预测框bi的交并比,n
t
为阈值,。
[0098]
基于以上两点,本方案使用soft-nms代替nms作为边界回归框中选择合适预测值的方法。因为nms直接将删除所有iou大于阈值的框,也就是将得分置零。而soft-nms在算法执行过程中不是简单的将iou大于阈值的检测框置零,而是降低它的得分。算法流程同nms
相同,但是对原置信度得分使用函数运算,目标是降低置信度得分。其实nms是soft-nms特殊形式,当得分重置函数采用二值化函数时,soft-nms和nms是相同的。soft-nms算法可以认为是一种更加通用的非最大抑制算法,其函数关系为:
[0099][0100]
s4、将待测视频输入至检测模型进行识别,得到识别结果;
[0101]
具体地,基于yolov5网络模型的识别结果,构建施工区域,数据上传,用于工作人员的辨别和处理。yolov5网络模型识别出传回视频的单帧图像中所有标定的目标,并得到视频图像包含的定位信息;通过设定目标数量的阈值初步辨别是否属于施工区域,低于阈值则不进行处理,若高于阈值则上传定位信息和识别的结果截图至云服务器中;工作人员对上传的信息进一步辨别和筛选,对于存在施工行为的且可能危害到地下管道安全的区域加以记录,以便公司安全管理部门去对施工方进行告知警示。
[0102]
s5、根据精度(precision)指标和召回率(recall)指标评估检测模型的性能。
[0103]
具体地,计算公式如下:
[0104][0105][0106]
上式中tp(true positive)表示正确检测识别出施工现场的物体,fp(false positive)表示错误检测识别出施工现场的物体,fn(false negative)表示未检测识别出施工现场的物体。
[0107]
根据其模型的精度和召回率不断的更新模型和优化模型,以求达到一个高的识别精度。
[0108]
一种基于改进yolov5模型的路边施工行为检测系统,包括:
[0109]
标注模块,用于获取图像数据集并进行标注,得到带标注的数据集;
[0110]
优化模块,以yolov5模型为基础,在backbone骨干网络中增加cbam注意力机制模块,在neck网络中将自底向上特征金字塔改为加权双向特征金字塔,得到改进后的yolov5模型;
[0111]
训练模块,基于带标注的数据集对改进后的yolov5模型进行训练,得到检测模型;
[0112]
识别模块,用于将待测视频输入至检测模型进行识别,得到识别结果。
[0113]
评估模块,用于根据精度指标和召回率指标评估检测模型的性能。
[0114]
上述方法实施例中的内容均适用于本系统实施例中,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法实施例所达到的有益效果也相同。
[0115]
一种基于改进yolov5模型的路边施工行为检测装置:
[0116]
至少一个处理器;
[0117]
至少一个存储器,用于存储至少一个程序;
[0118]
当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如上所述一种基于改进yolov5模型的路边施工行为检测方法。
[0119]
上述方法实施例中的内容均适用于本装置实施例中,本装置实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法实施例所达到的有益效果也相同。
[0120]
一种存储介质,其中存储有处理器可执行的指令,其特征在于:所述处理器可执行的指令在由处理器执行时用于实现如上所述一种基于改进yolov5模型的路边施工行为检测方法。
[0121]
上述方法实施例中的内容均适用于本存储介质实施例中,本存储介质实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法实施例所达到的有益效果也相同。
[0122]
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本技术权利要求所限定的范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。