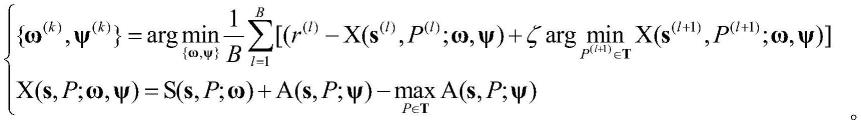
1.本发明涉及无线通信的安全,属于现代无线通信安全领域,尤其是涉及一种面向无线通信安全的安全探索强化学习方法。
背景技术:
2.随着无线通信技术的飞速发展,例如无人机视频图传、语音通话和无线体域网等,无线通信已经和人们的生活息息相关。然而,无线通信由于其开放性,导致在通信过程中容易遭受干扰和窃听等攻击,严重威胁通信系统安全的隐私和安全。无线通信系统中通常利用跳频、功率控制等技术应对非法攻击,以提高通信系统的安全性。
3.强化学习在未知环境中通过“试错”的方式学习,无需预知干扰等攻击策略或信道状态等网络参数,在无线通信安全领域应用广泛。如中国专利cn112291495b提出一种基于强化学习的无线视频低时延抗干扰传输方法,使用一种改进的深度强化学习算法,将玻尔兹曼分布与dqn算法进行结合,动态优化传输信道、发射功率、编码调制方式以抵抗干扰攻击;中国专利cn113079167a提出一种基于深度强化学习的车联网入侵检测方法及系统,使用深度确定性策略梯度算法建立基于流量数据的入侵检测模型;中国专利cn113225794a提出一种基于深度强化学习的全双工认知通信功率控制方法,直接使用dqn算法去优化次级用户发射机的功率控制策略。
4.c.dai等人[c.dai,l.xiao,x.wan and y.chen,"reinforcement learning with safe exploration for network security,"in proc.ieee international conference on acoustics,speech and signal processing(icassp),brighton,uk,may 2019.]提出一种针对网络安全的安全探索强化学习算法,利用安全性能指标评估动作的风险值,从而提高网络安全应用的安全性能。lu x等人[lu x,xiao l,niu g,et al.safe exploration in wireless security:a safe reinforcement learning algorithm with hierarchical structure[j].ieee transactions on information forensics and security,2022.]提出一种基于动作选择优先级的分层结构和安全准则的安全强化学习算法,利用分层结构和动作风险评估准则压缩动作空间,优化无线通信安全应用的安全策略,从而预防网络崩溃等严重后果。wachi akifumi和yanan sui[wachi a,sui y.safe reinforcement learning in constrained markov decision processes[c]//international conference on machine learning.pmlr,2020:9797-9806.]提出一种在未知安全约束下的马尔可夫决策过程探索和优化的方法,通过扩展安全区域来学习安全约束,然后在认证的安全区域内优化累积奖励,在约束马尔可夫决策过程中保证安全性的同时达到近似最优累积奖励。c.tessler等人[c.tessler,d.j.mankowitz,and s.mannor,“reward constrained policy optimization,”in proc.int.conf.learning representations(iclr),new orleans,la,may 2019.]提出一种基于奖励约束的策略优化方法,该方法引入两个评判网络,分别拟合奖励和安全约束的回报,并将安全约束作为惩罚信号引入到奖励函数中,以实现强化学习的安全探索。
[0005]
虽然上述现有基于强化学习的无线通信安全方案在无线通信安全场景中达到一定的抗干扰或者入侵检测等效果。但是大多数方案在初始学习阶段中没有考虑到风险策略的探索,例如导致通信中断的策略等,而且上述所提出的安全强化学习算法没有区分状态的风险和动作的风险,无法准确地拟合出动作风险程度。
技术实现要素:
[0006]
本发明的目的在于针对现有技术存在的上述问题,提供设计状态风险网络和动作风险网络,提高动作风险程度的拟合准确度,修正风险动作从而实现安全探索,避免选择造成系统通信中断的风险策略,提高无线通信安全性的一种面向无线通信安全的安全探索强化学习算法。
[0007]
本发明包括以下步骤:
[0008]
步骤1:初始化参数:
[0009]
无线通信系统中需要传输数据包的总个数为k,每传输一个数据包的时间构成一个时隙,总时隙为{1,2,
…
,k,
…
,k};信息发送方能够调整n种无线通信安全策略,例如跳频、功率控制、编码调制方式等来应对无线通信中的干扰攻击;统计第i种安全策略pi(1≤i≤n)可行的取值个数为li(1≤li≤n),由所有可能的安全策略的组合组成的动作空间集合为t,动作空间集合中的动作个数为通信系统中有m个性能评价指标{di}
1≤i≤m
,例如时延、误码率等,其中性能i(1≤i≤m)满足正常通信的条件为信息发送方能够感知j个通信状态信息{oi}
1≤i≤j
,例如信道状态和传输信息类型等;构建三个具有三层全连接层的神经网络v、网络s和网络a,网络v包含m j个输入神经元、h个隐藏神经元和l个输出神经元;网络s包含m j个输入神经元、h个隐藏神经元和1个输出神经元;网络a包含m j个输入神经元、h个隐藏神经元和l个输出神经元;随机初始化三个神经网络的权重矩阵ω和ψ,初始化学习参数ζ∈(0,1)、缓存区采样个数b、随机探索概率η及初始性能{d
i(0)
}
1≤i≤m
;
[0010]
步骤2:第k时隙,信息发送方接收上一时隙通信系统的性能评价指标{d
i(k-1)
}
1≤i≤m
并通过感知计算获得通信状态信息{o
i(k)
}
1≤i≤j
,构建系统当前状态
[0011]
步骤3:信息发送方将状态s
(k)
分别作为网络v、网络s和网络a的输入,将网络v的输出记为v={vm}
1≤m≤l
,代表不同动作的价值;将网络s的输出记为s,代表当前状态的风险值;将网络a的输出记为a={am}
1≤m≤l
,代表当前状态下采取不同的风险值;网络s和网络a的输出共同构成状态动作对的风险程度x={xm}
1≤m≤l
:
[0012][0013]
步骤4:记q值向量q=v-x,信息发送方以1-η的概率选择具有最大对应q值的动作pi,其中1≤i≤n,以η的概率随机选择其他的安全策略,根据得到的动作组合p
(k)
=[p1,p2,
…
pn]调整无线通信安全策略,将数据包发送至信息接收方;
[0014]
步骤5:信息接收方收到数据包后,计算当前通信系统的性能评价指标{di(k)
}
1≤i≤m
,并将性能评价指标反馈至信息发送方;
[0015]
步骤6:信息发送方接收到性能评价指标,通过效益函数f计算效益u
(k)
:
[0016]u(k)
=f(d
1(k)
,d
2(k)
,
…
,d
m(k)
)
[0017]
步骤7:信息发送方通过下式评估当前状态动作对的风险程度r
(k)
,其中i(
·
)为指示函数,若括号里的参数条件成立则为0,反之则为1,用于衡量风险程度:
[0018][0019]
步骤8:将四元组χ
(k)
={s
(k)
,p
(k)
,u
(k)
,r
(k)
}存入缓存区c,若缓存区中的数据个数大于等于采样个数b,则从缓存区中随机抽出b条数据{χ(i)}
1≤i≤b
,并通过下面的式子更新网络v、网络s和网络a的参数ω
(k)
和ψ
(k)
,其中v(
·
)、s(
·
)和a(
·
)分别代表网络v、网络s和网络a的输出值:
[0020][0021][0022]
步骤9:重复步骤2-8,直到通信系统的性能评价指标都满足正常通信要求,即其中1≤i≤m。
[0023]
与现有技术相比,本发明具有以下突出的优点:
[0024]
本发明根据通信系统的性能评价指标和通信需求评估当前状态下采取不同动作的风险值,引入状态风险网络和动作风险网络区分状态的风险和动作的风险,提高动作风险程度的拟合准确度,并利用动作风险程度修正动作的选择,避免探索危险策略,在无线通信安全应用中降低对风险策略的探索,提高无线通信的安全性。
附图说明
[0025]
图1为图像传输丢包率对比。
[0026]
图2为通信中断概率对比。
[0027]
图3为通信能耗对比。
具体实施方式
[0028]
为更加清楚地了解本发明的技术内容,以下将本发明的技术方案结合以下具体实施例和附图进行说明。
[0029]
本发明实施例包括以下步骤:
[0030]
步骤1:无线通信系统中需要传输数据包的总个数为1000个,每传输一个数据包的时间构成一个时隙,总时隙为{1,2,
…
,k,
…
,1000}。信息发送方能够调整跳频、功率控制和编码调制方式三种无线通信安全策略来应对无线通信中的干扰攻击。统计第i种安全策略pi(1≤i≤3)可行的取值个数为li(1≤li≤n)。由所有可能的安全策略组成的动作空间集合
为t,动作空间集合中的动作个数为通信系统中有时延和误码率两个性能评价指标d1和d2,满足正常通信的条件为d1≤0.4s且d2≤0.01%,信息发送方能够感知信道状态和传输信息类型两个通信状态信息。构建三个具有三层全连接层的神经网络v、神经网络s和神经网络a,网络v包含4个输入神经元、128个隐藏神经元和l个输出神经元;网络s包含4个输入神经元、128个隐藏神经元和1个输出神经元;网络a包含4个输入神经元、128个隐藏神经元和3个输出神经元。随机初始化三个神经网络的权重矩阵ω和ψ,初始化学习参数ζ=0.5、缓存区采样个数b=64、随机探索概率η=0.05及初始性能d
1(0)
=1和d
2(0)
=0.001。
[0031]
步骤2:第k时隙,信息发送方接收上一时隙通信系统的性能评价指标包括时延d
1(k-1)
和误码率d
2(k-1)
,并通过感知计算获得信道状态o
1(k)
和传输信息类型o
2(k)
,构建系统当前状态
[0032]
步骤3:信息发送方将状态s
(k)
分别作为网络v、网络s和网络a的输入,将网络v的输出记为v={vm}
1≤m≤l
,代表不同动作的价值;将网络s的输出记为s,代表当前状态的风险值;将网络a的输出记为a={am}
1≤m≤l
,代表当前状态下采取不同的风险值。网络s和网络a的输出共同构成状态动作对的风险程度x={xm}
1≤m≤l
:
[0033][0034]
步骤4:记q值向量q=v-x,信息发送方以0.95的概率选择具有最大对应q值的跳频、功率和编码调制方式p1、p2、p3三种动作,以0.05的概率随机选择其他的安全策略,根据得到的动作组合p
(k)
=[p1,p2,p3]调整无线通信安全策略,将数据包发送至信息接收方。
[0035]
步骤5:信息接收方收到数据包后,计算当前通信系统的性能评价指标d
1(k)
和d
2(k)
,并将性能评价指标反馈至信息发送方。
[0036]
步骤6:信息发送方接收到性能评价指标,通过下式计算效益u
(k)
:
[0037]u(k)
=-d
1(k)-1000*d
2(k)
[0038]
步骤7:信息发送方通过下式评估当前状态动作对的风险程度r
(k)
,其中i(
·
)为指示函数,若括号里的参数条件成立则为0,反之则为1,用于衡量风险程度:
[0039]r(k)
=i(d
1(k)
《=0.4s) i(d
2(k)
<=0.01%)
[0040]
步骤8:将四元组χ
(k)
={s
(k)
,p
(k)
,u
(k)
,r
(k)
}存入缓存区c,若缓存区中的数据个数大于等于采样个数b,则从缓存区中随机抽出b条数据{χ(i)}
1≤i≤b
,并通过下面的式子更新网络v、网络s和网络a的参数ω
(k)
和ψ
(k)
,其中v(
·
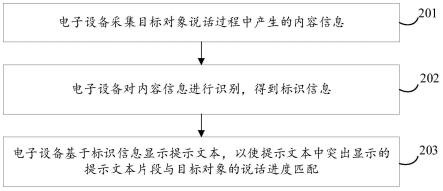
)、s(
·
)和a(
·
)分别代表网络v、网络s和网络a的输出值:
[0041][0042][0043]
步骤9:重复步骤2-8,直到通信系统的性能评价指标都能够满足正常通信要求,即
d1≤0.4s且d2≤0.01%。
[0044]
图1给出本发明实施例所述面向无线通信安全的安全探索强化学习方法对比于谷歌提出的dqn算法的图像传输丢包率。图2给出本发明实施例所述面向无线通信安全的安全探索强化学习方法对比于谷歌提出的dqn方法的通信中断概率。图3给出本发明实施例所述面向无线通信安全的安全探索强化学习方法对比于谷歌提出的dqn方法的通信能耗。本发明根据通信系统的性能评价指标和通信需求评估当前状态下采取不同动作的风险值,引入状态风险网络和动作风险网络区分状态的风险和动作的风险,提高动作风险程度的拟合准确度,并利用动作风险程度修正动作的选择,避免探索危险策略,在无线通信安全应用中降低对风险策略的探索,提高无线通信的安全性。
[0045]
上述实施例仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。