基于transformer的步态情绪识别方法、装置、电子设备及存储介质
技术领域
1.本发明涉及深度学习技术领域,特别是涉及一种基于transformer的步态情绪识别方法、装置、电子设备及存储介质。
背景技术:
2.相比较于其他情绪识别方法,步态具有远距离,不易欺骗和隐藏,关注全身动作而非局部特征相对不易遮挡等优点。
3.相比较于传统机器学习的方法,基于深度学习的方法识别效果显著提升。randhavane等人提出了一个包含四类情绪标签(快乐,悲伤,愤怒或中性)emotion-gait数据集,并采用lstm的方法进行情绪识别。venkatraman等人提出了proxemo一种新颖的端到端情感预测算法,应用于具有社交意识的机器人导航,通过步行步态预测行人的感知情绪。在会议aaai-2020上bhattacharya等人在step中应用空间时时图卷积网络(st-gcn)体系结构并通过变分自动编码器(cvae)生成的带注释的合成步态进行数据增强。在会议eccv-2020中bhattacharya等人在taew中提出了一种基于自动编码器的半监督方法,先用无情绪标签数据集训练基于gru的自编码器进行无监督学习,然后再用有情绪标签数据集进行监督学习,在emotion-gait基准数据集上的平均精度为84%。
4.针对目前基于小规模数据集深度学习方法研究现状中依旧存在的一些待解决的问题。现有的情绪步态数据集数据规模过小,无法满足深度学习对于训练样本需求量要求,单纯使用该数据集进行训练无法取得很好的效果并且存在过拟合的问题,step采用数据增强的方法进行数据扩充。这种方法一方面生成的数据质量无法保证也会引入噪声,另一方面理论上基于原有的数据集进行数据增强的方法也无法引入新的知识,效果相对有限。taew采取先引入其他步态相关数据集进行无监督学习完成预训练。但是这种方法只能使网络关注底层动作特征,无法获取高阶语义特征。步态的表征,taew采用传统的循环神经网络gru的方法,该网络更加关注时间维度的信息而忽略了关节点之间的空间联系。step采用基于空间时间图卷积网络(st-gcn)的方法,但是该方法依旧存在可以改进的空间,基于人工设定的规则进行关节点区域划分来获关节点之间的联系,这种人工设定的规则不能真实的反映实际运动中的关节点之间的客观联系。
技术实现要素:
5.基于此,本发明的目的在于,提供一种基于transformer的步态情绪识别方法、装置、电子设备及存储介质,将transformer算法引入并应用,设计了基于spatial-temporal transformer的自编码器网络模型,显著提高了算法性能。
6.第一方面,本发明提供一种基于transformer的步态情绪识别方法,包括以下步骤:
7.获取待识别情绪的步态视频;
8.对所述步态视频进行预处理,得到连续的步态序列;
9.将所述步态序列输入训练好的步态情绪识别网络,得到所述步态视频对应的情绪类别;
10.其中,所述步态情绪识别网络为基于spatial-temporal transformer的自编码器网络模型。
11.进一步地,所述步态情绪识别网络的训练步骤包括:
12.预训练阶段:采用无情绪标签的步态识别数据库,根据不同训练任务,从数据本身生成对应任务的训练标签,完成自监督多任务学习;
13.微调阶段:采用带有步态情绪标签的数据集,采用监督学习的方法,训练编码器的深层网络和分类器,最终完成模型训练。
14.进一步地,所述步态情绪识别网络的微调阶段包括:
15.冻结预训练模型的编码器的部分网络层;
16.将emotion-gait的步态序列和四类步态情绪标签输入经过预训练的所述步态情绪识别网络,采用监督学习的方法,完成基于监督学习的微调训练。
17.进一步地,所述步态情绪识别网络的预训练阶段包括:
18.将oumvlp-pose乱序的步态序列和正确的序列顺序标签输入所述步态情绪识别网络,通过学习以乱序的步态序列来重建原始输入步态序列;
19.将oumvlp-pose经过不同转换方法转化后的数据和相应的转换类型标签输入所述步态情绪识别网络,然后通过编码器提取特征空间,分类器学习判断该序列是何种转换类型;
20.将kinectcs步态序列和该数据库自带的动作类型标签输入所述步态情绪识别网络,然后经过编码器编码后分类器学习判断该步态序列为何种动作类型。
21.进一步地,所述步态情绪识别网络包括spatial-temporal transformer自编码器、平均池化层、二维卷积层、全连接层和softmax层;
22.所述spatial-temporal transformer自编码器由一个spatial transformer和一个temporal transformer组成,用于提取同一帧关节点之间的空间信息和不同帧之间时间维度信息。
23.进一步地,将所述步态序列输入训练好的步态情绪识别网络,得到所述步态视频对应的情绪类别,包括:
24.将所述步态序列顺次输入所述spatial-temporal transformer自编码器、所述平均池化层和所述二维卷积层进行特征空间提取,得到所述步态序列对应的特征空间向量;
25.将所述特征空间向量输入全连接层,并经过softmax激活函数,得到所述步态序列对应的预测情感类型的概率;
26.输出概率最大的情感类型为所述步态视频对应的情绪识别结果。
27.进一步地,所述步态序列包括多个步态序列帧,每个单个的步态序列帧含有18个关节点的3d pose信息。
28.第二方面,本发明还提供一种基于transformer的步态情绪识别装置,包括:
29.步态视频获取模块,用于获取待识别情绪的步态视频;
30.步态序列获取模块,用于对所述步态视频进行预处理,得到连续的步态序列;
31.情绪识别模块,用于将所述步态序列输入训练好的步态情绪识别网络,得到所述步态视频对应的情绪类别;
32.其中,所述步态情绪识别网络为基于spatial-temporal transformer的自编码器网络模型。
33.第三方面,本发明还提供一种电子设备,包括:
34.至少一个存储器以及至少一个处理器;
35.所述存储器,用于存储一个或多个程序;
36.当所述一个或多个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如本发明第一方面任一所述的一种基于transformer的步态情绪识别方法的步骤。
37.第四方面,本发明还提供一种计算机可读存储介质,
38.所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如本发明第一方面任一所述的一种基于transformer的步态情绪识别方法的步骤。
39.本发明提供的一种基于transformer的步态情绪识别方法、装置、电子设备及存储介质,将目前主流的transformer算法引入并应用,设计了基于spatial-temporal transformer的自编码器网络模型,显著提高了算法性能。解决了基于深度学习方法下步态情绪识别数据集过小的问题,本专利将引入其他步态相关数据集,应用自监督多任务预训练加微调的学习策略。基于新的学习策略,首先引入其他步态相关数据集进行预训练,从而引入新的先验知识,并采用自监督多任务的方法进行预训练,使得网络既能提取底层细节特征,又能关注高阶语义特征,并且提升鲁棒性。
40.为了更好地理解和实施,下面结合附图详细说明本发明。
附图说明
41.图1为本发明提供的一种基于transformer的步态情绪识别方法的步骤示意图;
42.图2为一个示例性的步态序列示意图;
43.图3为本发明在一个实施例中使用的步态情绪识别网络结构示意图;
44.图4为本发明在一个实施例中使用的步态情绪识别网络的自注意力机制示意图;
45.图5为本发明在一个实施例中的学习策略流程图;
46.图6为本发明在一个实施例中对步态情绪识别网络进行预训练的技术方案路线图;
47.图7为本发明在一个实施例中对步态情绪识别网络进行微调训练的技术方案路线图;
48.图8为本发明提供的一种基于transformer的步态情绪识别装置的结构示意图。
具体实施方式
49.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施例方式作进一步地详细描述。
50.应当明确,所描述的实施例仅仅是本技术实施例一部分实施例,而不是全部的实施例。基于本技术实施例中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本技术实施例保护的范围。
51.在本技术实施例使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本技术实施例。在本技术实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
52.下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是如所附权利要求书中所详述的、本技术的一些方面相一致的装置和方法的例子。在本技术的描述中,需要理解的是,术语“第一”、“第二”、“第三”等仅用于区别类似的对象,而不必用于描述特定的顺序或先后次序,也不能理解为指示或暗示相对重要性。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本技术中的具体含义。
53.此外,在本技术的描述中,除非另有说明,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。
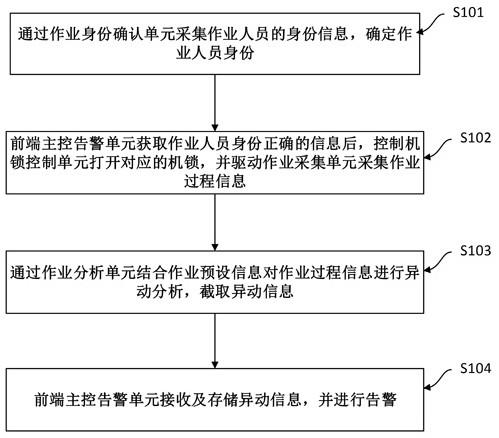
54.针对背景技术中的问题,本技术实施例提供一种基于transformer的步态情绪识别方法,如图1所示,该方法包括以下步骤:
55.s01:获取待识别情绪的步态视频。
56.步态情绪识别先比较于其他方法(人脸,生理信号等),有着远距离,不宜遮挡和欺骗,数据采集设备简单方便(摄像头),应用场景范围广等优势,应用前景广阔。
57.s02:对所述步态视频进行预处理,得到连续的步态序列。
58.在一个优选的实施例中,使用最新的姿势估计算法从rgb图像中提取姿势序列,例如以45度为例,步态序列如图2所示。
59.步态序列包括多个步态序列帧,每个单个的步态序列帧含有18个关节点的3d pose信息。
60.s03:将所述步态序列输入训练好的步态情绪识别网络,得到所述步态视频对应的情绪类别。其中,所述步态情绪识别网络为基于spatial-temporal transformer的自编码器网络模型。
61.在一个优选的实施例中,如图3所示,所述步态情绪识别网络包括spatial-temporal transformer自编码器、平均池化层、二维卷积层、全连接层和softmax层。
62.所述spatial-temporal transformer自编码器由一个spatial transformer和一个temporal transformer组成,用于提取同一帧关节点之间的空间信息和不同帧之间时间维度信息。
63.如今针对3d pose骨骼图的动作识别的应用最广泛方法是图神经网络(gnn),尤其是图卷积网络(gcn),因为它们可以有效地捕获空间(序列某帧)和时间(帧间)信息,因此本专利也将采用基于图卷积网络的方法。先前的研究,例如基于st-gcn的方法,关节点的拓扑图作都是固定的,这可能会阻碍挖掘时空步态序列中丰富的潜在信息。并且基于人工设定的规则进行关节点区域划分来获关节点之间的联系,这种人工设定的规则不能真实的反映实际运动中的关节点之间的客观联系,其次,从标准2d卷积开始实现空间卷积和时间卷积,这在某种程度上受到卷积核大小的限制。例如在“拍手”之类的动作中相关,在人体骨骼中未链接的身体关节之间的相关性(例如,左手和右手)也被低估了。因此我们通过使用
spatial-temporal transformer来应对这些限制,使用基于transformer的编码器,更好地挖掘步态序列下的潜在信息,提取不同帧之间的时间信息和关节点之间的空间信息,这使模型具有灵活性,可以在每个输入的步态序列下使关节点的相对重要性相互适应,例如关节点之间的连接强度是由transformer的自注意力机制确定的,而不是像先前基于gcn的典型公式那样通过邻接矩阵预先定义的。
64.如图3所示,spatial transformer模块设计用于从单个步态序列帧中提取embedding的高维特征。输入数据18个关节点的3d pose信息,然后将每个关节(即3个坐标值)视为一个patch,并遵循一般视觉transformer流程在所有patch之间进行特征提取。首先,我们使用可训练的linear projection将每个关节的坐标映射到高维空间,这被称为spatial patch embedding。我们将patch embedding与可学习的spatial positional embedding相加。将生成的关节序列特征输入到spatial transformer encoder中,如图该结构自注意层(self-attention)和归一化层(layer norm)组成,该编码器应用自注意机制来整合所有关节上的信息,以此来自动学习关节点之间的空间信息,自注意力机制如图4所示。对骨架图使用自注意力机制,包括:(1)对于每个身体关节点,计算query q,key k和value v。(2)对每个的q和k进行点乘得出v,代表每对节点之间的连接强度。(3)最后每个节点都依据其相关性进行缩放(4)将带权节点加在一起,获得其新特征。
65.基于上述步态情绪识别网络,由步态序列识别出对应的情绪类别包括以下子步骤:
66.s031:将所述步态序列顺次输入所述spatial-temporal transformer自编码器、所述平均池化层和所述二维卷积层进行特征空间提取,得到所述步态序列对应的特征空间向量。
67.s032:将所述特征空间向量输入全连接层,并经过softmax激活函数,得到所述步态序列对应的预测情感类型的概率。
68.s033:输出概率最大的情感类型为所述步态视频对应的情绪识别结果。
69.在一个优选的实施例中,学习策略流程图如图5所示,所述步态情绪识别网络的训练步骤包括以下子步骤:
70.s11:预训练阶段:采用无情绪标签的步态识别数据库,根据不同训练任务,从数据本身生成对应任务的训练标签,完成自监督多任务学习。
71.s12:微调阶段:采用带有步态情绪标签的数据集,采用监督学习的方法,训练编码器的深层网络和分类器,最终完成模型训练。
72.如图6所示,在预训练阶段,采用无情绪标签的大型步态识别数据库(oumvlp-pose)或者动作识别数据库(kinectcs),根据不同训练任务,从数据本身生成对应任务的训练标签,完成自监督多任务学习,使得网络即能够提取底层细节特征又能够提取高阶语义特征同时提高鲁棒性。微调阶段,用带有步态情绪标签的数据集,采用监督学习的方法,训练编码器的深层网络和分类器,最终完成模型训练。
73.oumvlp-pose多视图大群体姿势序列数据库包含由七个网络摄像机以15
°
的间隔捕获的10,307个来回步行序列对象。kinectcs是一个大规模,高质量动作数据集,包含多达65万个视频剪辑,涵盖400至700种人类动作类。这些视频包括诸如演奏乐器之类的人与物之间的交互,以及诸如握手和拥抱之类的人与人之间的交互。每个动作类至少具有400至
700个视频剪辑。每个剪辑都由一个动作类进行人工注释,并且持续10秒钟左右。
74.在生活中,不管是在单标签图像中还是多标签图像中往往不只包含单一的视觉信息,还包含了多种的语义信息。传统的自编码器,是以重构输入为目的而进行的研究,自监督学习则是通过设计辅助任务来学习可区分的视觉特征而进行的研究。自监督学习训练使用的标签能够直接从训练数据中获得,与有监督学习的原理相同的是标签可以为算法模型的训练提供监督信息。但是,自监督学习完成相应的学习任务的方法是通过挖掘数据的性质进行学习,进而生成视觉特征的语义标签信息,这也是与有监督学习的不同之处。本专利为了学习不带情绪标签的步态相关数据库,采用自监督学习的方法,通过设计不同自监督学习任务,可以使模型能够挖掘更多潜在的步态特征,提高模型识别效果的同时解决深度学习小规模数据集过拟合的问题。
75.具体地,自监督学习的预训练阶段包括以下子步骤:
76.s111:将oumvlp-pose乱序的步态序列和正确的序列顺序标签输入所述步态情绪识别网络,通过学习以乱序的步态序列来重建原始输入步态序列。
77.s112:将oumvlp-pose经过不同转换方法转化后的数据和相应的转换类型标签输入所述步态情绪识别网络,然后通过编码器提取特征空间,分类器学习判断该序列是何种转换类型。
78.s113:将kinectcs步态序列和该数据库自带的动作类型标签输入所述步态情绪识别网络,然后经过编码器编码后分类器学习判断该步态序列为何种动作类型。
79.如图6所示,在任务1步态序列重建中,输入数据是oumvlp-pose乱序(例如:反转或打乱序列)的步态序列和正确的序列顺序标签,通过学习以乱序的步态序列来重建原始输入步态序列,使得模型能够在步态编码期间学习嵌入在步态序列中的固有时间相关性,同时使模型学习底层细节特征。在任务2转换类型判断中,输入数据是oumvlp-pose经过不同转换方法(例如:旋转、顺序重洗、尺度变化等)转化后的数据和相应的转换类型标签,然后通过编码器提取特征空间,分类器学习判断该序列是何种转换类型,以此来提升模型鲁棒性。在任务3动作识别中,输入数据是kinectcs步态序列和该数据库自带的动作类型标签,然后经过编码器编码后分类器学习判断该步态序列为何种动作类型(例如:走路,快跑,跳远等),以此使模型能够挖掘更高阶步态语义特征。
80.监督学习的微调阶段使用emotion-gait微调数据集。emotion-gait包含2177个步态序列,其中包括342个实际采集的情绪步态序列,90位参与者在思考四种不同的情绪(愤怒,中立,快乐和悲伤)状态进行行走,每个参与者的总步行距离为7米。剩下的1835个步态序列来自edinburgh locomotion mocap database,由同一个领域专家将它们标记为4种情绪标签。这些视频由领域专家标记。
81.具体的,如图7所示,微调阶段包括以下子步骤:
82.s121:冻结预训练模型的编码器的部分网络层。
83.s122:将emotion-gait的步态序列和四类步态情绪标签输入经过预训练的所述步态情绪识别网络,采用监督学习的方法,完成基于监督学习的微调训练。
84.本技术实施例还提供一种基于transformer的步态情绪识别装置,如图8所示,该基于transformer的步态情绪识别装置400包括:
85.步态视频获取模块401,用于获取待识别情绪的步态视频;
86.步态序列获取模块402,用于对所述步态视频进行预处理,得到连续的步态序列;
87.情绪识别模块403,用于将所述步态序列输入训练好的步态情绪识别网络,得到所述步态视频对应的情绪类别;其中,所述步态情绪识别网络为基于spatial-temporal transformer的自编码器网络模型。
88.优选的,所述步态情绪识别网络的训练步骤包括:
89.预训练阶段:采用无情绪标签的步态识别数据库,根据不同训练任务,从数据本身生成对应任务的训练标签,完成自监督多任务学习;
90.微调阶段:采用带有步态情绪标签的数据集,采用监督学习的方法,训练编码器的深层网络和分类器,最终完成模型训练。
91.优选的,所述步态情绪识别网络的微调阶段包括:
92.冻结预训练模型的编码器的部分网络层;
93.将emotion-gait的步态序列和四类步态情绪标签输入经过预训练的所述步态情绪识别网络,采用监督学习的方法,完成基于监督学习的微调训练。
94.优选的,所述步态情绪识别网络的预训练阶段包括:
95.将oumvlp-pose乱序的步态序列和正确的序列顺序标签输入所述步态情绪识别网络,通过学习以乱序的步态序列来重建原始输入步态序列;
96.将oumvlp-pose经过不同转换方法转化后的数据和相应的转换类型标签输入所述步态情绪识别网络,然后通过编码器提取特征空间,分类器学习判断该序列是何种转换类型;
97.将kinectcs步态序列和该数据库自带的动作类型标签输入所述步态情绪识别网络,然后经过编码器编码后分类器学习判断该步态序列为何种动作类型。
98.优选的,所述步态情绪识别网络包括spatial-temporal transformer自编码器、平均池化层、二维卷积层、全连接层和softmax层;
99.所述spatial-temporal transformer自编码器由一个spatial transformer和一个temporal transformer组成,用于提取同一帧关节点之间的空间信息和不同帧之间时间维度信息。
100.优选的,情绪识别模块包括:
101.特征空间向量提取单元,用于将所述步态序列顺次输入所述spatial-temporal transformer自编码器、所述平均池化层和所述二维卷积层进行特征空间提取,得到所述步态序列对应的特征空间向量;
102.概率预测单元,用于将所述特征空间向量输入全连接层,并经过softmax激活函数,得到所述步态序列对应的预测情感类型的概率;
103.结果输出单元,用于输出概率最大的情感类型为所述步态视频对应的情绪识别结果。
104.优选的,所述步态序列包括多个步态序列帧,每个单个的步态序列帧含有18个关节点的3d pose信息。
105.对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以
不是物理单元。所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
106.本技术实施例还提供一种电子设备,包括:
107.至少一个存储器以及至少一个处理器;
108.所述存储器,用于存储一个或多个程序;
109.当所述一个或多个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如前所述的一种基于transformer的步态情绪识别方法的步骤。
110.对于设备实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的设备实施例仅仅是示意性的,其中所述作为分离部件说明的组件可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本公开方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
111.本技术实施例还提供一种计算机可读存储介质,
112.所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如前所述的一种基于transformer的步态情绪识别方法的步骤。
113.计算机可用存储介质包括永久性和非永久性、可移动和非可移动媒体,可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括但不限于:相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。
114.本发明提供的一种基于transformer的步态情绪识别方法、装置、电子设备及存储介质,将目前主流的transformer算法引入并应用,设计了基于spatial-temporal transformer的自编码器网络模型,显著提高了算法性能。解决了基于深度学习方法下步态情绪识别数据集过小的问题,本专利将引入其他步态相关数据集,应用自监督多任务预训练加微调的学习策略。基于新的学习策略,首先引入其他步态相关数据集进行预训练,从而引入新的先验知识,并采用自监督多任务的方法进行预训练,使得网络既能提取底层细节特征,又能关注高阶语义特征,并且提升鲁棒性。
115.以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。