技术特征:
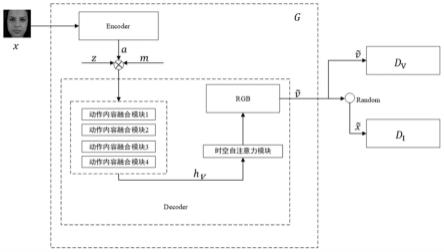
1.一种基于生成对抗网络的多模态输入视频条件生成方法,其特征在于所述方法包括如下步骤:步骤一、构建生成对抗网络模型所述生成对抗网络模型由生成器和判别器组成,其中:所述生成器由编码器和解码器组成;所述编码器为基于图像金字塔的图像编码器;所述解码器由动作内容融合模块和时空自注意力机制模块、rgb模块组成;所述判别器采用视频图像双判别器;步骤二、特征提取(1)获取训练集,根据视频序列的动作,将训练集中的每一个视频序列划分到对应的动作集合中,并设置对应的动作文本标签;(2)数据预处理,将视频序列的每一帧图像裁剪为指定大小,随机提取连续的32帧图像,读取到内存成tensor张量,并做归一化处理将rgb三通道的像素值除以255;(3)采用kaiming初始化方法初始化生成对抗网络模型,之后给图像编码器输入视频序列的随机一帧图像,获得对应的图像特征信息a;步骤三、模型训练(1)将视频序列对应的动作文本标签转化为张量与图像特征信息a、基于高斯分布的随机噪声结合输入到动作内容融合模块将动作特征信息和图像特性信息融合上采样,再通过时空自注意力机制模块将前后帧特征信息的关联增强,最后输入rgb模块生成rgb三通道的视频序列(2)将生成的视频序列和真实的视频序列v输入视频图像双判别器计算损失函数:l
total
=l
adv
(g,dv,d
i
) λl
co
(g);式中,l
adv
为对抗性损失函数,l
co
为生成视频整体的连贯性损失函数,λ为权重系数,dv为视频判别器,d
i
为图像判别器,g为生成器;(3)利用adam优化算法优化判别器和生成器的参数,重复步骤(1)和(2)训练模型,得到训练好的模型;步骤四、视频生成(1)将视频序列输入到步骤三训练好的生成对抗网络模型中,利用图像编码器获得对应的图像特征信息;(2)将视频序列对应的动作文本标签转化为张量与图像特征信息、基于高斯分布的随机噪声结合动作内容融合模块将动作特征信息和图像特性信息融合上采样,再通过时空自注意力机制模块将前后帧特征信息的关联增强,最后输入rgb模块生成视频序列。2.根据权利要求1所述的基于生成对抗网络的多模态输入视频条件生成方法,其特征在于所述基于图像金字塔的图像编码器中,卷积层步长为2,每一层图像都是缩减为上一层的1/2。3.根据权利要求1所述的基于生成对抗网络的多模态输入视频条件生成方法,其特征在于所述解码器有4级动作内容融合模块,动作内容融合模块采用2d 1d结构,即2维逆卷积和1维逆卷积结合。4.根据权利要求3所述的基于生成对抗网络的多模态输入视频条件生成方法,其特征
在于所述动作内容融合模块将动作和内容的特征信息连接到视频特征信息的通道维度上,如下式所示:式中,c
outi
为第i级动作内容融合模块的输出通道数,c
vi
为第i级动作内容融合模块生成的视频特征信息的通道数,c
mi
为第i级动作内容融合模块生成的动作特征信息的通道数,c
ai
为第i级动作内容融合模块生成的内容特征信息的通道数。5.根据权利要求1所述的基于生成对抗网络的多模态输入视频条件生成方法,其特征在于所述时空自注意力机制模块由时间自注意力机制模块和空间自注意力模块组成,时间自注意力机制模块和空间自注意力模块分别采用conv1d和conv2d组成。6.根据权利要求5所述的基于生成对抗网络的多模态输入视频条件生成方法,其特征在于所述时间自注意力机制模块后增加一个2维逆卷积,将图像特征信息大小扩大一倍。7.根据权利要求5所述的基于生成对抗网络的多模态输入视频条件生成方法,其特征在于所述空间自注意力机制模块中,query、key、value张量采用2维卷积获取。8.根据权利要求1所述的基于生成对抗网络的多模态输入视频条件生成方法,其特征在于所述视频图像双判别器包含一个视频判别器dv和一个图像判别器d
i
,在训练过程中,dv接受一个完整的视频序列作为输入,d
i
接受从输入的视频序列中随机采样得到的一帧图像。9.根据权利要求1所述的基于生成对抗网络的多模态输入视频条件生成方法,其特征在于所述对抗损失函数l
adv
的定义如下式所示:l
adv
(g,dv,d
i
)=l
i
(g,d
i
) lv(g,dv);其中:其中:式中,g表示生成器,dv表示视频判别器,d
i
表示图像判别器,z表示随机噪声,m表示动作标签,x表示真实的图像帧,其分布记为x,v表示真实的视频序列,上标
‘
*’表示从视频序列的n帧图像中随机采样,获取一帧图像。10.根据权利要求1所述的基于生成对抗网络的多模态输入视频条件生成方法,其特征在于所述连贯性损失函数l
co
的定义如下式所示:l
co
(g)=e[||v-g(z,x,m)||1];式中,g表示生成器,z表示随机噪声,m表示动作标签,x表示真实的图像帧,v表示真实的视频序列。
技术总结
本发明公开了一种基于生成对抗网络的多模态输入视频条件生成方法,所述方法基于动作内容解耦的方法,实现多模态输入视频条件生成,分为两个阶段,第一阶段为特征提取阶段,提取输入的标签文本和对象图片的特征信息;第二阶段为视频生成阶段,生成符合标签文本和对象图片约束的视频,并使用对抗训练的模式来完成网络的训练。在第一阶段中,通过图像金字塔对输入的目标图像进行特征提取,得到多尺度的视频内容特征信息,然后送往第二个阶段;在第二个阶段中,输入不仅为上一个阶段提取的特征信息,还需要加上动作文本标签的特征信息和随机噪声,然后输入Decoder模块生成最终的视频序列。该方法解决了多模态输入下的视频条件生成问题。问题。问题。
技术研发人员:吴爱国 谢锦洋 程诗文
受保护的技术使用者:哈尔滨工业大学(深圳)
技术研发日:2022.08.15
技术公布日:2022/11/15
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。