1.本发明属于金融科技技术领域,涉及一种基于复合相似度的金融关联账户识别方法和设备。
背景技术:
2.近些年,信息技术的快速发展给金融市场带来了发展与变革,但是由此也引发了诸多危机。在市场日趋复杂的情况下,金融监管变得越来越困难,监管部门有提升自身监察能力和监管手段的迫切需求。其中,关联账户筛查作为监管部门的重点工作,能否精准地识别出隐藏在市场中的关联账户组,挖掘账户深层关联关系,以及关联账户间隐蔽的违规交易、市场操纵行为,是监管及防范潜在市场风险的关键环节。
3.为预防金融风险,专利cn107527144a公开了一种金融领域关联交易的检测方法,该发明采用带符号的委托量作为投资者交易活动的特征变量,利用带符号委托量序列构建投资者交易的统一聚集的带符号委托量序列;计算两个投资者交易行为相似性,构建多个投资者相关系数矩阵;根据交易日的相关系数矩阵构建单日权重图并将多个单日权重图合并为一个综合权重图,综合权重图中的一个连通子图对应的投资者集合就是一个潜在的关联账户组。
4.目前已有关联账户识别方法主要是利用账户的交易行为数据,通过监督及无监督机器学习方法构建关联账户识别系统。主要存在的缺陷有以下两个方面:
5.1.现有关联账户识别方法大多未考虑市场舆情影响,但在某些典型案例中市场舆情对揭示关联账户异常交易起到了关键作用,如“叶飞案”的微博爆料信息等。
6.2.现有关联账户识别方法通常是将面板数据转换成截面数据进行建模,但是这种方法忽略了指标之间的时变性,可能导致分析结果不准确。
技术实现要素:
7.本发明的目的是解决现有技术考虑数据不完全的局限性且没有考虑到指标之间时变性导致的计算相似度不准确,可能导致最终聚类结果不准确的问题,提供一种基于复合相似度的金融关联账户识别方法和设备。
8.为达到上述目的,本发明采用的技术方案如下:
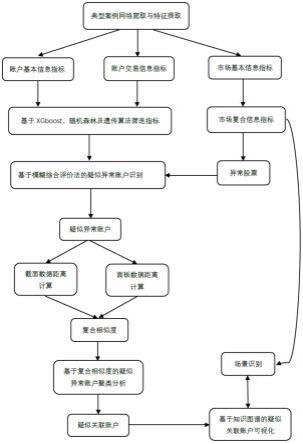
9.一种基于复合相似度的金融关联账户识别方法,包括如下步骤:
10.(1)典型案例爬取与特征提取;
11.所述典型案例是指中国证券监督管理委员会发布的涉嫌“账户组”的中国证监会行政处罚决定书中的典型案例;
12.所述典型案例中疑似关联账户的可识别、可衡量的特征指标的获取方式如下:
13.首先,利用网络爬虫技术获取涉及关联账户的典型案例;其次,将典型案例中“日内股价频繁震荡”、“通过对账户开户信息进行关联分析”等可识别的特征进行提取;最后,对提取的信息进行量化得到典型案例中疑似关联账户的可衡量的特征指标;
14.(2)指标体系设计;
15.所述指标体系包括账户基本信息指标、账户交易信息指标和市场基本信息指标三类;
16.构成所述指标体系的指标是从典型案例中挖掘出的疑似关联账户的可识别、可衡量的特征指标;
17.从短期、中期和长期三种不同的时间周期将基础性、单元性的指标要素组合设计成为可识别、可衡量且能反映关联账户识别特征的多维度、全周期实时监控指标体系。具体指标体系如下:
18.a.账户基本信息指标
19.账户基本信息指标包括但不限于:开户时间、客户经理、工作地址、家庭地址、身份证号码、银行卡开卡时间、开卡银行、籍贯、电话号码、电话号码归属地、账户开户时间长度共11个账户基本信息指标。
20.b.账户交易信息指标
21.账户交易信息指标包括但不限于:交易mac地址、交易ip地址、委托下单ip地址、委托下单地址、委托下单手机串号、委托日期、委托时间、委托方向、委托数量、委托价格、成交数量、成交价格、清算金额,发生清算后资金余额、期初余额、当前余额、可用余额、冻结余额、持仓股票和持仓数量共20个账户交易信息指标。
22.c.市场基本信息指标
23.市场基本信息指标包括但不限于:单位时间t周期内的开盘价、收盘价、最高价、最低价、成交量、报单量、撤单量以及市场舆情信息,其中t分别可取1分钟、5分钟、15分钟、30分钟、60分钟和120分钟的短期时间周期,1日、1周、1月、1季度和半年的中期时间周期以及1年、2年和3年的长期时间周期,共112个市场基本信息指标。
24.(3)账户基本信息指标和账户交易信息指标筛选;
25.首先,利用相关系数法剔除账户基本信息指标和账户交易信息指标中具有高度相关关系的指标;其次,利用xgboost、随机森林和遗传算法分别对剔除后的账户基本信息指标和账户交易信息指标进行筛选,获得三个最优指标集合(具体地,利用xgboost对账户基本信息指标和账户交易信息指标进行筛选获得最优指标集合s1,利用随机森林对账户基本信息指标和账户交易信息指标进行筛选获得最优指标集合s2,利用遗传算法对账户基本信息指标和账户交易信息指标进行筛选获得最优指标集合s3);最后,取三个最优指标集合的并集作为筛选出的账户基本信息指标和账户交易信息指标,所筛选出的主要指标具有较强的代表性、规律性、普遍性和前瞻性;
26.所述具有高度相关关系是指皮尔逊相关系数大于阈值,阈值默认为0.8;
27.xgboost特征选择取决于特征对模型贡献的重要度,重要度则是特征用于树分割次数的总和。xgboost中树的每次分割都采取贪婪地方式选择特征,即选择当前信息增益最大的特征用于树的分割。采用xgboost建模后即可统计样本数据特征的重要度。首先,计算所有特征对模型贡献的重要度;其次,利用重要度从高到低逐一添加特征进行建模,并计算模型预测的准确率;最后,模型预测准确率最高的模型所对应的特征集合即为最优特征集合,维度即为xgboost特征选择的维度。
28.随机森林与遗传算法均类似,只是某些评价指标略有区别,均是现有技术;
29.(4)市场复合信息指标构建;
30.基于步骤(2)中所述市场基本信息指标构建市场复合信息指标;市场复合信息指标由利用资金或持股优势大笔申报、连续申报、集中申报、大额申报、拉抬股价、打压股价、股价频繁波动、累计涨跌幅异常、股票集中度高、收盘前15分钟拉抬打压、频繁报撤单及涨跌幅限制价格大额申报等异常交易场景衍生而来,市场复合信息指标由人工构建且能反映上述异常交易场景。
31.具体指标涵义、刻画异常交易场景和阈值设置如下:
32.t周期内申报买入和卖出股票的笔数:用于刻画t周期内连续申报、频繁申报等,偏离历史t周期内申报买入和卖出股票笔数均值2倍标准差范围即视为存在异常;
33.t周期内申报买入和卖出股票的股数:用于刻画t周期内大笔申报等,偏离历史t周期内申报买入和卖出股票股数均值2倍标准差范围即视为存在异常;
34.t周期内申报买入和卖出股票的平均股价:用于刻画t周期内申报价格明显偏离该股行情的最近成交价、大额申报等,偏离历史t周期均值2倍标准差范围即视为存在异常;
35.t周期内成交买入和卖出股票的笔数:用于刻画t周期内利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内成交买入和卖出股票笔数均值2倍标准差范围即视为存在异常;
36.t周期内成交买入和卖出股票的股数:用于刻画t周期内利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内成交买入和卖出股票股数均值2倍标准差范围即视为存在异常;
37.t周期内成交买入和卖出股票的平均股价:用于刻画t周期内利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内均值2倍标准差范围即视为存在异常;
38.t周期内股价上穿或下穿t周期内平均股价正负k%的次数:k默认为2,用于刻画t周期内股价频繁震荡等,偏离历史t周期内均值2倍标准差范围即视为存在异常;
39.t周期内股价涨跌幅:用于刻画t周期内股价涨跌幅以及偏离大盘指数程度等,偏离历史t周期内股价涨跌幅均值2倍标准差范围即视为存在异常;
40.t周期内股票集中度,即t周期内账户持有该股票前n名账户的持有量占总量的比重,n默认为100,用于刻画该股票是否容易被操纵等,偏离历史t周期内股票集中度均值2倍标准差范围即视为存在异常;
41.t周期内股票曝光度,即该股票的舆情分析结果,正面为1,中性为0,负面为-1,用于刻画t周期内股票的舆情对股价的影响以及利用信息优势拉抬股价等,股票曝光度为0视为正常,其余则视为存在异常;
42.t周期内涨幅或跌幅限制的价格-申报买入和卖出股票的笔数:用于刻画以涨幅或跌幅限制的价格连续申报、频繁申报等,偏离历史t周期内涨幅或跌幅限制价格-申报买入和卖出股票笔数的均值2倍标准差范围即视为存在异常;
43.t周期内涨幅或跌幅限制的价格申报买入和卖出股票的股数:用于刻画以涨幅或跌幅限制的价格大笔申报等,偏离历史t周期内涨幅或跌幅限制价格申报买入和卖出股票股数的均值2倍标准差范围即视为存在异常;
44.t周期内涨幅或跌幅限制的价格成交买入和卖出股票的笔数:用于刻画以涨幅或跌幅限制的价格利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内涨幅或跌
幅限制价格申报买入和卖出股票笔数的均值2倍标准差范围即视为存在异常;
45.t周期内涨幅或跌幅限制的价格成交买入和卖出股票的股数:用于刻画以涨幅或跌幅限制的价格利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内涨幅或跌幅限制价格成交买入和卖出股票股数的均值2倍标准差范围即视为存在异常;
46.t周期内股票报撤单比:t周期内报单量/t周期内撤单量,用于刻画股票频繁报撤单,虚假交易,偏离历史t周期内股票报撤单比的均值2倍标准差范围即视为存在异常;
47.t周期包括:短期时间周期t1,默认1分钟、5分钟、15分钟、30分钟、60分钟和120分钟;中期时间周期t2,默认1日、1周、1月、1季度和半年;长期时间周期t3,默认1年、2年和3年;特殊时间周期t4,默认每日集合竞价和每日收盘前15分钟;周期维度根据需要可扩充;
48.(5)基于模糊层次综合评价的疑似异常账户识别;
49.疑似异常账户的判断基于以下规则:
50.一是账户交易股票疑似异常;二是根据模糊层次综合评价模型计算的持有异常股票的账户综合评价得分超过阈值;
51.(5.1)根据步骤(4)中构建的市场复合信息指标判断是否存在异常股票,如存在,则进入步骤(5.2);否则,终止。
52.(5.2)利用模糊层次综合评价模型,由评语集v、权重分配向量w和模糊综合评价矩阵r计算持有疑似异常股票的账户综合评价得分c,综合平均得分超过阈值的账户即为疑似异常账户;所述阈值默认为0.75;
53.(6)基于复合相似度的疑似异常账户聚类分析;
54.(6.1)获取步骤(5)中识别的疑似关联账户筛选后的账户基本信息指标和账户交易信息指标的数据,并对其进行z-score标准化预处理;
55.(6.2)对于类别为面板数据(既包含时间维度,又包含截面维度的数据称为面板数据)的指标,计算不同疑似异常账户之间的希尔伯特相似度;
56.(6.3)对于类别为截面数据的指标(不包含时间维度的数据称为截面数据),计算不同疑似异常账户之间的欧氏距离;
57.(6.4)利用步骤(5.2)中计算所得的权重分配向量w对步骤(6.2)中计算得到的希尔伯特相似度和步骤(6.3)中计算得到的欧氏距离进行加权平均,得到基于希尔伯特相似度和欧氏距离的复合相似度;
58.(6.5)基于复合相似度,利用系统聚类方法对疑似异常账户进行聚类分析,得到疑似关联账户。
59.作为优选的技术方案:
60.如上所述的一种基于复合相似度的金融关联账户识别方法,还包括:
61.(7)基于知识图谱的疑似关联账户可视化。
62.如上所述的一种基于复合相似度的金融关联账户识别方法,步骤(5.2)具体包括如下步骤:
63.(5.2.1)根据实际需要确定评价的对象集、因素集和评语集;对象集为p={p1,p2,...,pk},因素集为u={u1,u2,...,um},评语集为v={v1,v2,...,vn};
64.其中,对象集为待评价的账户,因素集为步骤(3)中筛选出的账户基本信息指标和账户交易信息指标;评语集为每一种因素所处状态的评价标准,归一化后即得评价等级向
量,记作h;
65.(5.2.2)计算m个评价因素的权重分配向量w;评价因素集中的每个因素在“评价目标”中有不同的地位和作用,即各评价因素在综合评价中占有不同的比重,称之为权重分配向量w;
66.(5.2.3)利用单因素模糊评价计算模糊综合评价矩阵:
[0067][0068]
其中,r
ij
表示因素集中第i个因素ui在评语集中第j个评语vj上的频率分布,一般将其归一化使之满足rr
ii
=(r
i1
,r
i2
,...,r
in
)为第i个因素ui的单因素评价,i=1,2,
…
,m;
[0069]
(5.2.4)将模糊综合评价矩阵r和权重分配向量w进行复合运算得到综合评价结果:
[0070]
b=w
·
r;
[0071]
(5.2.5)将综合评价结果b转换为综合分值c,即:
[0072]
c=b
·ht
;
[0073]
根据综合评价得分c判断对象集中的所有账户是否为疑似异常账户;综合评价得分超过阈值的账户即为疑似异常账户;所述阈值默认为0.75。
[0074]
如上所述的一种基于复合相似度的金融关联账户识别方法,步骤(5.2.2)中采用层次分析法计算所有评价因素的权重分配向量w。确定权重值的方法有很多,可以采用专家咨询法、层次分析法或“相对重要程度相关等级计算法”等,本发明采用层次分析法来计算所有评价因素的权重分配向量w。
[0075]
如上所述的一种基于复合相似度的金融关联账户识别方法,步骤(6.2)和(6.3)中,对指标中的文本数据(文本数据是指指标中包含文本信息,是字符串类型的,而不是数值类型的,如账户基本信息中的“账户开户地址”),利用预训练中文bert模型,将其映射到[512*1]维特征后再进行相似度度量(当文本数据属于面板数据时,计算希尔伯特相似度,属于截面数据时则计算欧式距离)。
[0076]
如上所述的一种基于复合相似度的金融关联账户识别方法,步骤(6.2)中不同疑似关联账户之间的希尔伯特相似度的计算步骤如下:
[0077]
(6.2.1)计算希尔伯特指数;
[0078]
希尔伯特指数是指通过将面板数据映射到希尔伯特空间构建的指数;
[0079]
文献yann et al.(2019)为构建希尔伯特相似度,提出了希尔伯特指数的概念,该指数是从希尔伯特曲线衍生而来。希尔伯特曲线(也称为希尔伯特空间填充曲线)是一个连续的分形空间填充曲线,该曲线被广泛应用于图像处理及数据库管理等领域。希尔伯特指数是指通过希尔伯特曲线,将p维数据映射为1维数据;
[0080]
本发明利用r软件中hilbertsimilarity包实现希尔伯特指数的计算,具体流程如
图2所示。
[0081]
(6.2.2)刻画不同疑似异常账户的离散概率分布;
[0082]
利用希尔伯特指数,刻画不同疑似异常账户的离散概率分布p(x)和q(x);
[0083]
(6.2.3)计算不同疑似异常账户之间的kullback-leibler距离;
[0084]
在相同的概率空间χ下,利用不同疑似异常账户的离散概率分布p(x)和q(x),计算二者之间的kullback-leibler距离;
[0085]
任意两个疑似异常账户之间的kullback-leibler距离计算公式如下:
[0086][0087]
其中,
[0088]
类似地,在相同的概率空间χ下,利用不同疑似异常账户的离散概率分布p(x)和q(x),计算二者之间的kullback-leibler距离d
kl
(q(x)||m(x));
[0089]
(6.2.4)计算不同疑似异常账户之间的希尔伯特相似度;
[0090]
利用疑似异常账户的离散概率分布,计算不同疑似异常账户之间的jensen-shannon距离,即希尔伯特相似度;
[0091]
任意两个疑似异常账户之间的jensen-shannon距离计算公式如下:
[0092][0093]
由任意不同疑似异常账户之间的希尔伯特相似度,即可得到面板数据的距离矩阵。
[0094]
如上所述的一种基于复合相似度的金融关联账户识别方法,步骤(6.3)中任意两个疑似异常账户之间的欧式距离计算公式如下:
[0095][0096]
其中,x和y分别表示两个不同的疑似关联账户,m表示疑似异常账户中指标的数量,xi和yi分别表示账户x和账户y中的第i个指标,i=1,2,
…
,m。
[0097]
如上所述的一种基于复合相似度的金融关联账户识别方法,步骤(6.5)中系统聚类方法为ward聚类法,本发明系统聚类的方法包括但不限于ward聚类法,其他聚类方法如k均值等也在本发明的保护范围内,但相比于其他聚类方法,ward聚类法鲁棒性更高,能适应于复杂数据。
[0098]
本发明还提供一种基于复合相似度的金融关联账户识别设备,应用所述基于复合相似度的金融关联账户识别设备执行如上任一项所述的基于复合相似度的金融关联账户识别方法;
[0099]
所述基于复合相似度的金融关联账户识别设备包括一个或多个处理器、一个或多个存储器、一个或多个程序及多个数据收集装置;
[0100]
所述多个数据收集装置用于获取可识别、可衡量的疑似关联账户的特征指标的数据;所述一个或多个处理器用于执行所述一个或多个程序;所述一个或多个程序被存储在
所述一个或多个存储器中;
[0101]
利用python实现基于所述复合相似度的金融关联账户识别方法,构建基于复合相似度的金融关联账户识别模型,并提供api接口,将所述多个数据收集装置获取的指标的数据输入至api接口,输出为疑似关联账户的聚类结果,通过输入数据可自动做出最终判断,并返回利用知识图谱绘制的可视化结果。
[0102]
作为优选的技术方案:
[0103]
如上所述的一种基于复合相似度的金融关联账户识别设备,还包括与所述一个或多个处理器连接的显示设备;所述显示设备用于显示最终得到的关联账户关联关系。
[0104]
本发明的原理如下:
[0105]
针对金融关联账户分析,现有方法均是将面板数据转换为截面数据,而后计算各账户之间的相似度。这忽略了面板数据天然具有的时序数据的性质,从而导致相似度计算不准确。本发明的核心思想是将面板数据看作一个整体,映射到希尔伯特空间中构建希尔伯特指数,利用不同疑似异常账户的离散概率分布计算二者之间的jensen-shannon距离,即希尔伯特相似度指数,以衡量各异常账户之间的距离。同时,针对截面数据,本发明利用经典欧式距离进行衡量。最后,利用层次分析法计算的权重分配向量对面板数据和截面数据距离进行加权平均,得到复合相似度。
[0106]
具体来说相似度准确不准确是不能直接衡量的,因为聚类问题是无监督问题。为量化聚类分析效果,dunn(1974)提出了dvi指数(邓恩指数)。本发明通过分析聚类结果,侧面反映相似度的准确程度。本发明利用复合相似度构建的金融关联账户聚类的dvi指数更高。
[0107]
有益效果:
[0108]
基于本发明可以开发金融关联账户识别和可视化系统,一方面通过金融关联账户识别功能能够揭示金融市场中关联账户组的动态发展规律,帮助银行、证券和期货等金融机构自动筛选关联账户特征以及对关联账户组风险特征进行自动量化度量;另一方面通过金融关联账户可视化功能可以为金融机构和监管部门精准地识别出隐藏在市场中关联账户群,挖掘深层账户关系,以及关联账户间隐蔽的违规交易、市场操纵行为等提供切实、清晰的科学参考。
附图说明
[0109]
图1为知识图谱可视化示例图;
[0110]
图2为希尔伯特指数计算流程图;
[0111]
图3为基于复合相似度的金融关联账户识别方法流程图。
具体实施方式
[0112]
下面结合具体实施方式,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
[0113]
一种基于复合相似度的金融关联账户识别方法,如图3所示,具体步骤如下:
[0114]
(1)典型案例爬取与特征提取;
[0115]
典型案例是指中国证券监督管理委员会发布的涉嫌“账户组”的中国证监会行政处罚决定书中的典型案例;
[0116]
首先,利用网络爬虫技术获取涉及关联账户的典型案例;其次,将所述典型案例中可识别的“日内股价频繁震荡”、“通过对账户开户信息进行关联分析”特征进行提取;最后,对提取的信息进行量化得到“账户开户地”、“预留手机号码”等可衡量的特征指标,多个特征指标共同构成指标体系;
[0117]
(2)指标体系设计;
[0118]
指标体系包括账户基本信息指标、账户交易信息指标和市场基本信息指标三类;
[0119]
从短期、中期和长期三种不同的时间周期将基础性、单元性的指标要素组合设计成为可识别、可衡量且能反映关联账户识别特征的多维度、全周期实时监控指标体系。具体指标体系如下:
[0120]
a.账户基本信息指标
[0121]
账户基本信息指标包括但不限于:开户时间、客户经理、工作地址、家庭地址、身份证号码、银行卡开卡时间、开卡银行、籍贯、手机号码、手机号码归属地、账户开户时间长度共11个账户基本信息指标;
[0122]
b.账户交易信息指标
[0123]
账户交易信息指标包括但不限于:交易mac地址、交易ip地址、委托下单ip地址、委托下单地址、委托下单手机串号、委托日期、委托时间、委托方向、委托数量、委托价格、成交数量、成交价格、清算金额,发生清算后资金余额、期初余额、当前余额、可用余额、冻结余额、持仓股票和持仓数量共20个账户交易信息指标;
[0124]
c.市场基本信息指标
[0125]
市场基本信息指标包括但不限于:单位时间t周期内的开盘价、收盘价、最高价、最低价、成交量、报单量、撤单量以及市场舆情信息,其中t分别可取1分钟、5分钟、15分钟、30分钟、60分钟和120分钟的短期时间周期;1日、1周、1月、1季度和半年的中期时间周期以及1年、2年和3年的长期时间周期,共112个市场基本信息指标;
[0126]
(3)账户基本信息指标和账户交易信息指标筛选;
[0127]
首先,利用相关系数法剔除账户基本信息指标和账户交易信息指标中具有高度相关关系的指标;其次,利用xgboost、随机森林和遗传算法分别对剔除后的账户基本信息指标和账户交易信息指标进行筛选,获得三个最优指标集合(具体地,利用xgboost对账户基本信息指标和账户交易信息指标进行筛选获得最优指标集合s1,利用随机森林对账户基本信息指标和账户交易信息指标进行筛选获得最优指标集合s2,利用遗传算法对账户基本信息指标和账户交易信息指标进行筛选获得最优指标集合s3)。最后,取三个最优指标集合的并集作为筛选出的账户基本信息指标和账户交易信息指标,所筛选出的主要指标具有较强的代表性、规律性、普遍性和前瞻性;
[0128]
所述具有高度相关关系是指皮尔逊相关系数大于阈值,阈值默认为0.8;
[0129]
xgboost特征选择取决于特征对模型贡献的重要度,重要度则是特征用于树分割次数的总和。xgboost中树的每次分割都采取贪婪地方式选择特征,即选择当前信息增益最大的特征用于树的分割。采用xgboost建模后即可统计样本数据特征的重要度。首先,计算
所有特征对模型贡献的重要度;其次,利用重要度从高到低逐一添加特征进行建模,并计算模型预测的准确率;最后,模型预测准确率最高的模型所对应的特征集合即为最优特征集合,维度即为xgboost特征选择的维度。
[0130]
随机森林与遗传算法均类似,只是某些评价指标略有区别,均是现有技术;
[0131]
(4)市场复合信息指标构建;
[0132]
基于步骤(2)中市场信息基本指标构建市场复合信息指标;市场复合信息指标由利用资金或持股优势大笔申报、连续申报、集中申报、大额申报、拉抬股价、打压股价、股价频繁波动、累计涨跌幅异常、股票集中度高、收盘前15分钟拉抬打压、频繁报撤单及涨跌幅限制价格大额申报等异常交易场景衍生而来,市场复合信息指标由人工构建且能反映上述异常交易场景。具体指标涵义、刻画异常交易场景和阈值设置如下:
[0133]
t周期内申报买入和卖出股票的笔数:用于刻画t周期内连续申报、频繁申报等,偏离历史t周期内申报买入和卖出股票笔数均值2倍标准差范围即视为存在异常;
[0134]
t周期内申报买入和卖出股票的股数:用于刻画t周期内大笔申报等,偏离历史t周期内申报买入和卖出股票股数均值2倍标准差范围即视为存在异常;
[0135]
t周期内申报买入和卖出股票的平均股价:用于刻画t周期内申报价格明显偏离该股行情的最近成交价、大额申报等,偏离历史t周期内均值2倍标准差范围即视为存在异常;
[0136]
t周期内成交买入和卖出股票的笔数:用于刻画t周期内利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内成交买入和卖出股票笔数均值2倍标准差范围即视为存在异常;
[0137]
t周期内成交买入和卖出股票的股数:用于刻画t周期内利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内成交买入和卖出股票股数均值2倍标准差范围即视为存在异常;
[0138]
t周期内成交买入和卖出股票的平均股价:用于刻画t周期内利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内均值2倍标准差范围即视为存在异常;
[0139]
t周期内股价上穿或下穿t周期内平均股价正负k%的次数:k默认为2,用于刻画t周期内股价频繁震荡等,偏离历史t周期内均值2倍标准差范围即视为存在异常;
[0140]
t周期内股价涨跌幅:用于刻画t周期内股价涨跌幅以及偏离大盘指数程度等,偏离历史t周期内股价涨跌幅均值2倍标准差范围即视为存在异常;
[0141]
t周期内股票集中度,即t周期内账户持有该股票前n名账户的持有量占总量的比重,n默认为100,用于刻画该股票是否容易被操纵等,偏离历史t周期内股票集中度均值2倍标准差范围即视为存在异常;
[0142]
t周期内股票曝光度,即该股票的舆情分析结果,正面为1,中性为0,负面为-1,用于刻画t周期内股票的舆情对股价的影响以及利用信息优势拉抬股价等,股票曝光度为0视为正常,其余则视为存在异常;
[0143]
t周期内涨幅或跌幅限制的价格申报买入和卖出股票的笔数:用于刻画以涨幅或跌幅限制的价格连续申报、频繁申报等,偏离历史t周期内涨幅或跌幅限制价格申报买入和卖出股票笔数的均值2倍标准差范围即视为存在异常;
[0144]
t周期内涨幅或跌幅限制的价格申报买入和卖出股票的股数:用于刻画以涨幅或跌幅限制的价格大笔申报等,偏离历史t周期内涨幅或跌幅限制价格申报买入和卖出股票
股数的均值2倍标准差范围即视为存在异常;
[0145]
t周期内涨幅或跌幅限制的价格成交买入和卖出股票的笔数:用于刻画以涨幅或跌幅限制的价格利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内涨幅或跌幅限制价格申报买入和卖出股票笔数的均值2倍标准差范围即视为存在异常;
[0146]
t周期内涨幅或跌幅限制的价格成交买入和卖出股票的股数:用于刻画以涨幅或跌幅限制的价格利用资金优势和持股优势拉抬和打压股价等,偏离历史t周期内涨幅或跌幅限制价格成交买入和卖出股票股数的均值2倍标准差范围即视为存在异常;
[0147]
t周期内股票报撤单比:t周期内报单量/t周期内撤单量,用于刻画股票频繁报撤单,虚假交易,偏离历史t周期内股票报撤单比的均值2倍标准差范围即视为存在异常;
[0148]
t周期包括:短期时间周期t1,默认1分钟、5分钟、15分钟、30分钟、60分钟和120分钟;中期时间周期t2,默认1日、1周、1月、1季度和半年;长期时间周期t3,默认1年、2年和3年;特殊时间周期t4,默认每日集合竞价和每日收盘前15分钟;周期维度根据需要可扩充;
[0149]
(5)基于模糊层次综合评价的疑似异常账户识别;
[0150]
(5.1)根据步骤(4)中构建的市场复合信息指标判断是否存在异常股票,如存在,则进入步骤(5.2);否则,终止;
[0151]
(5.2)利用模糊层次综合评价模型,由评语集v、权重分配向量w和模糊综合评价矩阵r计算持有疑似异常股票的账户综合评价得分c,综合平均得分超过阈值的账户即为疑似异常账户;
[0152]
(5.2.1)根据实际需要确定评价的对象集、因素集和评语集;对象集为p={p1,p2,...,pk},因素集为u={u1,u2,...,um}和评语集为v={v1,v2,...,vn};
[0153]
其中,对象集为待评价的账户,因素集为步骤(3)中筛选出的账户基本信息指标和账户交易信息指标,评语集为每一种因素所处状态的评价标准,归一化后即得评价等级向量,记作h;
[0154]
(5.2.2)计算m个评价因素的权重分配向量w;
[0155]
(5.2.3)利用单因素模糊评价计算模糊综合评价矩阵:
[0156][0157]
其中,r
ij
表示因素集中第i个因素ui在评语集中第j个评语vj上的频率分布,一般将其归一化使之满足rr
ii
=(r
i1
,r
i2
,...,r
in
)为第i个因素ui的单因素评价,i=1,2,
…
,m;
[0158]
(5.2.4)将模糊综合评价矩阵r和权重分配向量w进行复合运算得到综合评价结果,即
[0159]
b=w
·
r;
[0160]
(5.2.5)将综合评价结果b转换为综合评价得分c,即:
[0161]
c=b
·ht
;
[0162]
根据综合评价得分c判断对象集中的股票账户是否为疑似异常账户;综合评价得分超过阈值的账户即为疑似异常账户,阈值默认为0.75;
[0163]
(6)基于复合相似度的疑似异常账户聚类分析;
[0164]
(6.1)获取步骤(5)中识别的疑似关联账户筛选后的账户基本信息指标和账户交易信息指标的数据,并对其进行z-score标准化预处理;
[0165]
(6.2)对于类别为面板数据的指标,计算不同疑似异常账户之间的希尔伯特相似度;
[0166]
不同疑似异常账户之间的希尔伯特相似度的计算步骤如下:
[0167]
(6.2.1)计算希尔伯特指数
[0168]
希尔伯特指数是指通过将面板数据映射到希尔伯特空间构建的指数;
[0169]
本发明利用r软件中hilbertsimilarity包实现希尔伯特指数的计算,具体流程如图2所示;
[0170]
(6.2.2)刻画不同疑似异常账户的离散概率分布;
[0171]
利用希尔伯特指数,刻画不同疑似异常账户的离散概率分布p(x)和q(x);
[0172]
(6.2.3)计算不同疑似异常账户之间的kullback-leibler距离;
[0173]
在相同的概率空间χ下,利用不同疑似异常账户的离散概率分布p(x)和q(x),计算二者之间的kullback-leibler距离;
[0174]
任意两个疑似异常账户之间的kullback-leibler距离计算公式如下:
[0175][0176]
其中,
[0177]
类似地,在相同的概率空间χ下,利用不同疑似异常账户的离散概率分布p(x)和q(x),计算二者之间的kullback-leibler距离d
kl
(q(x)||m(x));
[0178]
(6.2.4)计算不同疑似异常账户之间的希尔伯特相似度;
[0179]
利用疑似异常账户的离散概率分布,计算不同疑似异常账户之间的jensen-shannon距离,即希尔伯特相似度;
[0180]
任意两个疑似异常账户之间的jensen-shannon距离计算公式如下:
[0181][0182]
由任意不同疑似异常账户之间的希尔伯特相似度,即可得到面板数据的距离矩阵。
[0183]
(6.3)对于类别为截面数据的指标,计算不同疑似异常账户之间的欧氏距离;
[0184]
任意两个疑似异常账户之间的欧式距离计算公式如下:
[0185][0186]
其中,x和y分别表示两个不同的疑似关联账户,m表示疑似异常账户中指标的数量,xi和yi分别表示账户x和账户y中的第i个指标,i=1,2,
…
m;
[0187]
(6.4)利用步骤(5.2)中计算的权重分配向量w对步骤(6.2)中计算得到的希尔伯特相似度与步骤(6.3)中计算得到的欧氏距离进行加权平均,得到基于希尔伯特相似度和欧氏距离的复合相似度;
[0188]
(6.5)基于复合相似度,利用系统聚类方法对疑似异常账户进行聚类分析,得到疑似关联账户;
[0189]
(7)基于知识图谱的疑似关联账户可视化;
[0190]
通过识别的异常关联账户及异常交易的特定场景,利用echarts构建可视化知识图谱,如图1所示。
[0191]
一种用于执行上述基于复合相似度的金融关联账户识别方法的设备,包括一个或多个处理器、一个或多个存储器、一个或多个程序、多个数据收集装置以及一个显示设备;多个数据收集装置用于获取可衡量关联账户可识别的特征的多个指标的数据;一个或多个处理器用于执行一个或多个程序;一个或多个程序被存储在一个或多个存储器中;显示设备与一个或多个处理器连接,用于显示最终得到的关联账户关联关系;利用python实现基于上述的复合相似度的金融关联账户识别方法,构建基于复合相似度的金融关联账户识别模型,并提供api接口,将多个数据收集装置获取的指标的数据输入至api接口,输出为疑似关联账户的聚类结果,通过输入数据可自动做出最终判断,并返回利用知识图谱绘制的可视化结果。
[0192]
实际应用案例:
[0193]
由于金融账户数据的安全性,本发明利用上市公司数据来验证复合相似度进行聚类的有效性;
[0194]
本发明选取2010年1月至2020年12月上证50成分股的财务数据,从公司发展能力、盈利能力和风险水平三个方面选取财务杠杆系数、净利润增长率、净资产收益率及营业利润率四个指标,作为反映公司经营发展状况的特定变量;分别利用欧式距离、希尔伯特相似度及复合相似度进行聚类分析;结果显示,基于欧式距离的系统聚类的dvi指数为0.328;基于希尔伯特相似度的系统聚类的dvi指数为0.561;基于复合相似度的系统聚类的dvi指数为0.612;初步的数值结果说明基于复合相似度的系统聚类方法的效果更好。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。