1.本技术涉及一种用于存储器内计算(compute-in-memory,cim)宏排列的方法及非暂时性计算机可读介质以及电子装置。
背景技术:
2.cim是一种用于对流行且广泛使用的冯诺依曼(von-neumann)处理器/架构内的带宽与计算不匹配问题进行解决的技术。可通过将存储器与计算组合在同一区块中来解决带宽不匹配问题。然而,由于卷积神经网络的高计算要求,将使用并且应使用多个cim宏,但多个cim宏的水平/垂直比率是固定的且无法根据用于不同卷积计算的不同数目的输入通道及输出通道来进行调整,且所述固定的比率不会针对计算功率/能量度量而进行优化。
技术实现要素:
3.本技术提出一种cim宏排列的方法及非暂时性计算机可读介质以及电子装置。
4.根据示例性实施例中的一个,所述用于cim宏排列的方法包括:获得cim宏的数目的信息及所述cim宏中的每一个的维度的信息;获得指定神经网络的指定卷积层的输入通道的数目及输出通道的数目的信息;以及根据所述cim宏的所述数目、所述cim宏中的每一个的所述维度、所述指定神经网络的所述指定卷积层的所述输入通道的所述数目及所述输出通道的所述数目来确定用于对所述cim宏进行排列的cim宏排列,以用于对所述输入通道进行卷积运算以产生所述输出通道。
5.根据示例性实施例中的一个,电子装置包括cim宏及处理电路。所述cim宏基于所述cim宏的数目、所述cim宏中的每一个的维度、以及指定神经网络的指定卷积层的输入通道的数目及输出通道的数目而排列成预定的cim宏排列。所述处理电路被配置成:在经排列的所述cim宏中加载权重;以及将一个输入特征图的多个输入通道输入到具有加载的所述权重的经排列的所述cim宏中,以进行用于产生多个输出特征图中的一个的输出激活的卷积运算。
6.根据示例性实施例中的一个,所述非暂时性计算机可读介质存储程序,所述程序使计算机获得cim宏的数目的信息及所述cim宏中的每一个的维度的信息;获得指定神经网络的指定卷积层的输入通道的数目及输出通道的数目的信息;以及根据所述cim宏的所述数目、所述cim宏中的每一个的所述维度、所述指定神经网络的所述指定卷积层的所述输入通道的所述数目及所述输出通道的所述数目来确定用于对所述cim宏进行排列的cim宏排列,以用于对所述输入通道进行卷积运算以产生所述输出通道。
7.然而,应理解,此发明内容可能不包含本技术的所有方面及实施例,且因此并不意指以任何方式进行限制或局限。另外,本技术将包括对所属领域中的技术人员来说显而易见的改善及修改。
附图说明
8.包括附图以提供对本技术的进一步理解,且附图被并入本说明书中并构成本说明书的一部分。附图示出本技术的实施例,且与说明一同用于阐释本技术的原理。
9.图1示出卷积神经网络(convolutional neural network,cnn)中的卷积。
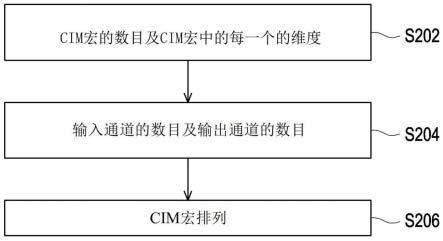
10.图2示出根据本技术示例性实施例中的一个的用于cim宏排列的所提出方法的流程图。
11.图3示出根据本技术示例性实施例中的一个的不同cim宏排列。
12.图4示出根据本技术示例性实施例中的一个的卷积运算。
13.图5示出根据本技术示例性实施例中的一个的垂直cim宏排列。
14.图6示出根据本技术示例性实施例中的一个的水平cim宏排列。
15.图7示出根据本技术示例性实施例中的一个的实行卷积运算的系统的方块图。
16.图8示出根据本技术示例性实施例中的一个的所提出电子装置的示意图。
17.为使本技术的以上特征及优点更易于理解,以下结合附图详细阐述若干实施例。
具体实施方式
18.深度神经网络(deep neural network,dnn)的常见形式是由多个卷积层构成的卷积神经网络(cnn)。在此种网络中,每一卷积层获取输入激活(input activation)数据且产生输入数据的更高层次的抽象(被称为特征图),所述更高层次的抽象保留必要而独特的信息。cnn中的卷积激活层中的每一个主要由高维卷积构成。举例来说,图1示出cnn中的卷积。
19.参照图1,在此计算100中,一个层的输入激活被构造为具有多个通道的一组二维(2d)输入特征图(ix
×
iy且具有c个通道),所述多个通道中的每一个被称为输入通道。每一输入通道与来自2d滤波器堆叠的不同2d滤波器(即,内核)进行卷积。此2d滤波器堆叠也被称为单个三维(3d)滤波器。多个3d滤波器110(具有维度fx
×
fy
×
c的m个滤波器)与输入特征图120进行卷积。跨所有输入通道对每一点的卷积结果进行求和。此计算的结果是一个输出通道的所有输出激活(output activations),即,具有维度ox
×
oy的一个输出特征图。换句话说,3d滤波器110被应用于3d输入特征图120(具有批量大小n)以创建n个输出特征图130。对于不同dnn中的不同层,输入通道的数目(由c或ic表示)及输出通道的数目(由m或oc表示)将依据不同的参数设计而发生大量变化。然而,现有技术中用于多个cim宏的cim宏排列是固定的且与卷积的输入/输出通道数目无关。
20.为解决上述问题,现在将在下文中参考附图更全面地阐述本技术的一些实施例,在附图中示出本技术的一些实施例但并非全部实施例。实际上,本技术的各种实施例可以许多不同的形式来实施且不应被视为仅限于本文中陈述的实施例;确切来说,提供这些实施例是为了使本技术满足适用的法律要求。通篇中相同的参考编号指代相同的元件。
21.图2示出根据本技术示例性实施例中的一个的用于cim宏排列的所提出方法的流程图。图2中的步骤将由产品开发阶段中的计算机系统来实施。
22.参照图2,获得cim宏的数目的信息及cim宏中的每一个的维度的信息(步骤s202),且获得指定神经网络的指定卷积层的输入通道的数目及输出通道的数目的信息(步骤s204)。接下来,根据cim宏的数目、cim宏中的每一个的维度、指定神经网络的指定卷积层的输入通道的数目及输出通道的数目来确定用于对cim宏进行排列的cim宏排列,以用于对输
入通道进行卷积运算以产生输出通道(步骤s206)。也就是说,通过在硬件中提供动态cim形状配置,在软件中被实施为模块的cim形状决策器(decider)可将输入通道及输出通道作为输入且决定能够产生最优配置的cim形状配置。
23.在本示例性实施例中,根据延迟(latency)、能量消耗(energy consumption)及利用率(utilization)来确定能够实行多个滤波器与输入通道的卷积的cim宏排列。所述延迟与存取动态随机存取存储器(dynamic random access memory,dram)的延迟、用于将权重加载到cim宏中的延迟以及cim宏的处理时间中的至少一个相关联。在本文中,权重意指滤波器的参数,且滤波器的参数的数目等于fx
×
fy
×
ic
×
oc。能量是表示用于使用一种类型的cim宏排列来对卷积层进行计算的能量成本的因素,且能量消耗与用于存取至少一个存储器的能量成本相关联,所述至少一个存储器包括与cim宏位于同一芯片中的芯片上静态随机存取存储器(static random access memory,sram)以及位于芯片之外的dram。利用率是cim宏的已使用部分对所有cim宏的比率。举例来说,dram:sram:cim=200:6:1的比率意指在存取相同数量的数据的基础上,存取sram相对于存取cim要花费6倍的能量成本。
24.在一种情况下,所确定的cim宏排列可提供的所有cim宏在垂直维度的总和能够让此排列的cim宏适于以最少的批量加载次数去载入输入通道以实行滤波器与指定卷积层的输入通道的卷积。在另一种情况下,所确定的cim宏排列可提供的所有cim宏在水平维度的总和能够让此排列的cim宏适于以最少的批量加载次数去载入输入通道以实行滤波器与指定卷积层的输入通道的卷积。
25.为直观地阐释如何有效地使用多个cim宏来将计算性能最大化,图3示出根据本技术示例性实施例中的一个的不同cim宏排列。
26.参照图3,cnn网络的每一卷积层可具有输入/输出通道的相应配置。假设cim宏的数目是4且每一cim宏具有256行(row)及64列(column)的cim单元。如果输入通道的数目多于输出通道的数目,则使用垂直排列310的cim宏可更高效。如果输出通道的数目多于输入通道的数目,则使用水平排列320的cim宏可更高效。如果输入通道的数目等于输出通道的数目,则使用正方形排列330的cim宏可更高效。
27.为进行更好地理解,图4示出根据本技术示例性实施例中的一个的卷积运算。
28.参照图4,假设对于输入数据来说ic=512、ox=28且oy=28,对于滤波器f0到f127来说fx=1、fy=1,且oc=128、ix=1、iy=1。在使用两个宏、每一宏具有256行及64列的情形中,用于对卷积进行计算的高效cim宏排列可为如图5中所示的根据本技术示例性实施例中的一个的垂直cim宏排列。
29.参照图5,64个滤波器f0、f1、
…
、f63预先存储在cim宏中。输入通道1到256被输入到第一cim宏(上部cim宏)且输入通道257到512被输入到第二cim宏(下部cim宏)。换句话说,具有维度1
×1×
512的输入立方体510的数据(对应于图4中的输入立方体410的数据)被分成两部分且分别被输入到第一cim宏及第二cim宏的每一列(每一列存储滤波器)以进行乘法运算。对于第一cim宏及第二cim宏中的每一个,由cim宏对每一列的256个乘法结果进行求和以作为输出值,且外部电路可将所述两个输出值相加作为512个乘法结果的总和,以产生卷积输出。因此,作为整体的第一cim宏与第二cim宏可产生64个卷积输出。举例来说:
30.对于滤波器f0的列,
31.且对于滤波器f1的列,
[0032][0033]
其余64个滤波器f65、f66、
…
、f127的卷积运算将是相似的。
[0034]
在使用两个cim宏、每一cim宏具有256行及64列的相同情形中,也可使用水平排列的cim宏对卷积进行计算。在此种情形中,第一半数量的输入通道1到256可被输入到两个水平排列的cim宏的共128列(所述128列分别预先存储128个滤波器)中的每一列,且每一列的256个乘法结果由cim宏进行求和以作为输出值。然而,由于尚未对第二半数量的输入通道257到512进行计算,因此此种输出值无法作为完整的卷积输出。这些输出值(不完整的卷积输出)必须存储在累加缓冲器(sram或d触发器(d flip-flop,dff))中。直到也完成第二半数量的输入通道257到512的卷积运算才将不完整的卷积输出的两个部分相加以产生128个卷积输出。在此种情形中,在对累加缓冲器进行存取上花费较多的能量,因此其效率比使用两个垂直排列的cim宏低。
[0035]
接下来,假设输入通道的数目是128且输出通道的数目是512。由于每一宏具有256行(大于128),因此无需将两个cim宏垂直排列。单个cim宏将能够完成输入通道1到256的卷积运算(即,单个cim宏的利用率仅为50%)。在此种情形中,用于对卷积进行计算的高效cim宏排列可为如图6中所示的根据本技术示例性实施例中的一个的水平cim宏排列。
[0036]
参照图6,将一次性加载128个滤波器f0到f127,以减少加载权重的数目。相似地,输入立方体610的数据被分别输入到第一cim宏及第二cim宏的每一列,以用于进行对应的输出的乘法运算。
[0037]
不同的产品可应用不同的cnn架构进行数据处理。举例来说,监视系统(surveillance system)可应用cnn架构a进行数据处理,而外科器械(surgical instrument)可应用cnn架构b进行数据处理。可由离线工具基于产品所选择的cnn架构的卷积层的配置(即,ox、oy、ic、oc、fx、fy、
…
等)来预先确定产品的适当cim宏排列。
[0038]
一旦离线确定出产品的cim宏排列,图7示出根据本技术示例性实施例中的一个的实行卷积运算的系统的方块图。
[0039]
参照图7,cim宏cim0、cim1、cim2及cim3在系统700中排列成预定的cim宏排列。权重(即,滤波器的参数)及指令可存储在dram 720中。当系统700接收到输入特征图时,中央处理器(central processing unit,cpu)710可触发cnn调度器770及cim宏cim0到cim3,以通过硬件(例如dram 720、ddr控制器730、系统芯片(system on chip,soc)总线740及数据线性地址(data linear address,dla)处理器75)对指定神经网络的指定卷积层实行卷积。cnn调度器770可从芯片上sram 760接收权重及输入特征图(input feature map,ifm)且从指令解析器750接收cim配置,将权重及输入特征图加载到cim0到cim4中以进行卷积运算,从cim0到cim3接收cim输出,对所有cim输出实行求和以向sram 760产生中间结果作为当前卷积层的输出特征图(output feature map,ofm)中且等待另一新的触发。
[0040]
在实际应用中,图8示出根据本技术示例性实施例中的一个的所提出电子装置的示意图,其中假设所述电子装置由终端用户使用。
[0041]
参照图8,电子装置800包括多个cim宏810及处理电路820。cim宏810基于cim宏的数目、cim宏中的每一个的维度、以及指定神经网络的指定卷积层的输入通道的数目及输出通道的数目而排列成预定的cim宏排列。在本示例性实施例中,可基于图2中提出的用于cim
宏排列的方法来确定预定的cim宏排列。处理电路820被配置成在经排列的cim宏中加载权重,且将一个输入特征图的多个输入通道输入到具有加载的权重的经排列的cim宏中,以进行用于产生输出特征图中的一个的输出激活的卷积运算。
[0042]
在实例中,首先可将滤波器的权重加载到cim宏中,且然后可将输入通道(输入特征图)输入到cim宏中以进行卷积运算。在另一个实例中,首先可将输入用到加载到cim宏,且然后可将权重输入到cim宏以进行卷积运算。
[0043]
在本示例性实施例中,处理电路820基于预定的cim宏排列、滤波器的数目、滤波器中的每一个的每一内核的高度及宽度以及每一滤波器中的内核的数目来在经排列的cim宏中加载多个滤波器的权重,其中每一滤波器的内核中的每一个分别被应用于指定神经网络的指定卷积层的输入通道中的对应一个。
[0044]
在一个示例性实施例中,处理电路820将滤波器中的每一个逐列加载到经排列的cim宏中。处理电路820可基于每一内核的高度及宽度以及经排列的cim宏的水平维度的总和来判断是否在经排列的cim宏中批量加载滤波器的权重。
[0045]
本技术还提供一种非暂时性计算机可读记录介质,所述非暂时性计算机可读记录介质对欲加载到计算机系统中的计算机程序进行记录以执行所提出方法的步骤。计算机程序由多个程序指令构成。一旦程序区段被加载到计算机系统中且由计算机系统执行,便完成所提出方法的步骤。
[0046]
鉴于前述说明,所提出技术使得能够有效地使用具有最优配置的多个cim宏来将计算性能最大化。
[0047]
对于所属领域中的技术人员来说将显而易见的是,在不背离本技术的范围或精神的条件下,可对所公开的实施例的结构进行各种修改及变化。鉴于以上内容,本技术旨在覆盖落入以下权利要求书及其等效内容的范围内的对本技术的修改及变化。
[0048]
[相关申请的交叉参考]
[0049]
本技术主张在2021年5月13日提出申请的序列号为63/187,952的美国临时申请的优先权权益。上述专利申请的全文并入本技术供参考且构成本说明书的一部分。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。