使用自适应网络来对全景声系数进行变换
1.依据35u.s.c.
§
119要求优先权
2.本专利申请要求享受于2021年3月23日递交的、名称为“transform ambisonic coefficients using an adaptive network”的非临时申请no.17/210,357的优先权,其要求享受于2020年3月24日递交的、名称为“transform ambisonic coefficients using an adaptive network based on other form factors than ideal microphone arrays”的临时申请no.62/994,158、以及于2020年3月24日递交的、名称为“transform ambisonic coefficients using an adaptive network”的临时申请no.62/994,147的优先权,上述申请被转让给本技术的受让人并且据此通过引用的方式被明确地并入本文中。
技术领域
3.概括而言,下文涉及全景声(ambisonic)系数生成,并且更具体地,下文涉及使用自适应网络来对全景声系数进行变换。
背景技术:
4.技术的进步已经导致更小且更强大的计算设备。例如,目前存在各种各样的便携式个人计算设备,包括小型、轻量级以及容易由用户携带的无线电话(诸如移动和智能电话、平板设备和膝上型计算机)。这些设备可以在无线网络上传送语音和数据分组。此外,许多这样的设备并入了额外的功能,诸如数字照相机、数字摄像机、数字记录器和音频文件播放器。此外,这样的设备可以处理可执行指令,包括可以用以接入互联网的软件应用(诸如网页浏览器应用)。照此,这些设备可以包括关键的计算能力。
5.计算能力包括处理全景声系数。由全景声系数表示的全景声信号是声场的三维表示。全景声信号或全景声信号的全景声系数表示可以以独立于用于回放从全景声信号渲染的多声道音频信号的本地扬声器几何结构的方式来表示声场。
技术实现要素:
6.一种设备包括存储器,其被配置为存储在不同时间段处的未经变换的全景声系数。所述设备还包括一个或多个处理器,其被配置为:获得在所述不同时间段处的所述未经变换的全景声系数,其中,在所述不同时间段处的所述未经变换的全景声系数表示在所述不同时间段处的声场。所述一个或多个处理器还被配置为:基于约束来将一个自适应网络应用于在所述不同时间段处的所述未经变换的全景声系数,以生成在所述不同时间段处的经变换的全景声系数,其中,在所述不同时间段处的所述经变换的全景声系数表示基于所述约束而修改的、在所述不同时间段处的经修改的声场。
7.在阅读整个申请(包括以下章节:附图说明、具体实施方式和权利要求书)之后,本公开内容的方面、优势和特征将变得显而易见。
附图说明
8.图1示出了根据本公开内容的一些示例的示例性全景声系数集合和可以用于捕获由全景声系数表示的声场的不同的示例性设备。
9.图2a是根据本公开内容的一些示例的可操作以利用约束和目标全景声系数来执行对自适应网络的权重的自适应学习的系统的特定说明性示例的图。
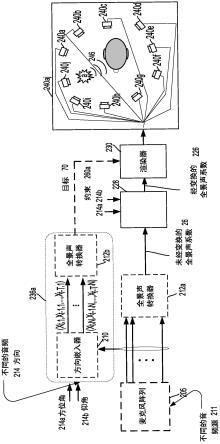
10.图2b是根据本公开内容的一些示例的可操作以利用约束和目标全景声系数来执行对自适应网络的权重的推断和/或自适应学习的系统的特定说明性示例的图,其中,约束包括使用方向。
11.图2c是根据本公开内容的一些示例的可操作以利用约束和目标全景声系数来执行对自适应网络的权重的推断和/或自适应学习的系统的特定说明性示例的图,其中,约束包括使用缩放值。
12.图2d是根据本公开内容的一些示例的可操作以利用多个约束和目标全景声系数来执行自适应网络的推断和/或进行推断的系统的特定说明性示例的示意图,其中,多个约束包括使用多个方向。
13.图2e是根据本公开内容的一些示例的可操作以利用约束和目标全景声系数来执行对自适应网络的权重的推断和/或进行推断和/或自适应学习的系统的特定说明性示例的图,其中,约束包括以下各项中的至少一项:理想麦克风类型、目标阶数、形状因子麦克风位置、模型/形状因子。
14.图3a是根据本公开内容的一些示例的可操作以结合一个或多个音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图。
15.图3b是根据本公开内容的一些示例的可操作以结合一个或多个音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图。
16.图4a是根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用使用编码器和存储器。
17.图4b是根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用编码器、存储器和解码器。
18.图4c是根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用渲染器、关键字检测器和设备控制器。
19.图4d是根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用渲染器、方向检测器和设备控制器。
20.图4e是根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用渲染器。
21.图4f是根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用在图
4c、图4d和图4e中描述的应用。
22.图5a是根据本公开内容的一些示例的可操作以执行自适应网络的推断的虚拟现实或增强现实眼镜的图。
23.图5b是根据本公开内容的一些示例的可操作以执行自适应网络的推断的虚拟现实或增强现实耳机的图。
24.图5c是根据本公开内容的一些示例的可操作以执行自适应网络的推断的车辆的图。
25.图5d是根据本公开内容的一些示例的可操作以执行自适应网络的推断的手持机的图。
26.图6a是根据本公开内容的一些示例的可操作以执行自适应网络225的推断的设备的图,其中,该设备在不同的方向上渲染两个音频流。
27.图6b是根据本公开内容的一些示例的可操作以执行自适应网络225的推断的设备的图,其中,该设备能够捕获在讲话者区域中的语音。
28.图6c是根据本公开内容的一些示例的可操作以执行自适应网络225的推断的设备的图,其中,该设备能够渲染在隐私区域中的音频。
29.图6d是根据本公开内容的一些示例的可操作以执行自适应网络225的推断的设备的图,其中,该设备能够从不同的方向捕获至少两个音频源,在无线链路上将它们发送给远程设备,其中,远程设备能够渲染音频源。
30.图7a是根据本公开内容的一些示例的可操作以执行训练的自适应网络的图,其中,自适应网络包括回归器和鉴别器。
31.图7b是根据本公开内容的一些示例的可操作以执行推断的自适应网络的图,其中,自适应网络是递归神经网络(rnn)。
32.图7c是根据本公开内容的一些示例的可操作以执行推断的自适应网络的图,其中,自适应网络是长短期记忆网络(lstm)。
33.图8是示出根据本公开内容的一些示例的执行基于约束来应用至少一个自适应网络的方法的流程图。
34.图9是根据本公开内容的一些示例的可操作以执行基于约束来应用至少一个自适应网络的设备的特定说明性示例的框图。
具体实施方式
35.在一些情况下,由于来自另一源的干扰,可能使包括语音的音频信号在质量方面降级。干扰可以是物理障碍物、其它信号、加性高斯白噪声(awgn)等的形式。用于去除干扰的一个挑战是当干扰和期望音频信号来自同一方向时。本公开内容的各方面涉及用于在存在噪声的情况下当噪声和音频信号两者在类似方向上行进时去除该干扰的影响(例如,提供对原始音频信号的纯净估计)的技术。举例来说,所描述的技术可以提供使用与源相关联的方向性和/或信号类型作为在生成纯净音频信号估计时的因素。本公开内容的其它方面涉及将初始包括多个音频源的声场的全景声表示变换为消除在特定方向之外的音频源的声场的全景声表示。
36.全景声系数表示整个声场;然而,有时期望对不同的音频源进行空间滤波。举例来
说,本文描述的自适应网络可以通过使期望空间方向通过并且抑制来自其它空间方向的音频源来执行空间滤波的功能。此外,与限于将音频信号的信噪比(snr)提高3db的传统波束成形器不同,本文描述的自适应网络将snr提高至少一个数量级以上(即30db)。另外,本文描述的自适应网络可以保留所通过的音频信号的音频特性。传统的信号处理技术可以使在期望方向上的音频信号通过;然而,它们可能无法保留某些音频特性,例如,混响量或易于随时间变化的其它瞬态音频特性。另外,本文描述的自适应网络可以在编码设备或解码设备中变换全景声系数。
37.通过在预先指定位置处的扩音器来播放使用基于声道的环绕声的空间编码的消费者音频。用于空间音频编码的另一种方法是基于对象的音频,其涉及用于单个音频对象的离散脉冲编码调制(pcm)数据以及包含对象在空间中的位置坐标的相关联的元数据(以及其它信息)。用于空间音频编码(例如,环绕声编码)的另一种方法是基于场景的音频,其涉及使用全景声系数来表示声场。全景声系数具有分层基函数,例如,球谐基函数。
38.举例来说,可以依据全景声系数,使用诸如以下表达式之类的表达式来表示声场:
[0039][0040]
该表达式表明:在声场的任何点处的压力pi可以通过全景声系数来唯一地表示。此处,波数c是声速(~343m/s),是参考点(或观测点),jn(
·
)是阶数为n的球贝塞尔函数,并且是阶数为n和次阶数为m的球谐基函数(全景声系数的一些描述将n表示为(即,相应的勒让德多项式的)度,并且将m表示为阶数)。可以认识到的是,方括号中的项是信号(即,)的频域表示,其可以通过各种时频变换(诸如离散傅立叶变换(dft)、离散余弦变换(dct)或小波变换)来近似。
[0041]
图1示出了高达4阶(n=4)的示例性全景声系数集合。图1还示出了可以用于捕获由全景声系数表示的声场的不同的示例性麦克风设备(102a、102b、102c)。麦克风设备102b可以被设计为直接输出包括全景声系数的声道。替代地,麦克风设备102a和102c的输出声道可以耦合到多声道音频转换器,该多声道音频转换器将多声道音频转换为全景声音频表示。
[0042]
用于表示声场的全景声系数的总数可以取决于各种因素。例如,对于基于场景的音频,全景声系数的数量的总数可能受麦克风设备102a、102b、102c中的麦克风换能器的数量约束。全景声系数的总数也可以通过可用存储带宽或传输带宽来确定。在一个示例中,使用涉及用于每个频率的25个系数(即,0≤n≤4,-n≤m≤ n)的四阶表示。可以与本文描述的方法一起使用的分层集合的其它示例包括小波变换系数集合和多分辨率基函数的其它系数集合。
[0043]
全景声系数可以是从使用各种麦克风阵列配置(诸如四面体102b、球状麦克风阵列102a、或其它麦克风布置102c)中的任何一种配置物理地获取(例如,记录)的信号中推导的。这种形式的全景声系数输入表示基于场景的音频。在一个非限制性示例中,进入自适应网络225的输入是作为四面体麦克风阵列的麦克风阵列102b的不同输出声道。四面体麦克风阵列的一个示例可以用于捕获一阶全景声(foa)系数。麦克风阵列的另一示例可以是不同的麦克风布置,其中,在麦克风阵列捕获音频信号之后,麦克风阵列的输出用于使用
全景声系数来产生声场的表示。例如,专利号为10,477,310b2(被转让给高通公司)的“ambisonic signal generation for microphone arrays”是针对被配置为进行以下操作的处理器的:对由每个麦克风阵列捕获的信号执行信号处理操作,并且通过对这些信号应用第一乘法因子集合以生成第一全景声信号集合来执行第一方向性调整,第一乘法因子集合是基于麦克风阵列中的每个麦克风的位置、麦克风阵列中的每个麦克风的朝向或两者来确定的。
[0044]
在另一非限制性示例中,麦克风阵列102a的不同输出信道可以由全景声转换器转换为全景声系数。例如,麦克风阵列可以是球形阵列,诸如eigenmiker(mh acoustics llc,加州旧金山)。eigenmiker阵列的一个示例是em32阵列,其包括32个麦克风,其被布置在直径为8.4厘米的球体的表面上,使得输出信号中的每一者pi(t),i=1到32是麦克风i在时间采样t处记录的压力。
[0045]
此外或替代地,全景声系数可以从声场的基于声道或基于对象的描述来推导。例如,用于对应于单个音频源的声场的系数可以被表示为:
[0046][0047]
其中,i是是阶数为n的(第二类)球汉克尔函数,是音频源的位置,并且g(ω)是作为频率的函数的源能量。应当注意的是,在该上下文中的音频源可以表示音频对象,例如,讲话的人、吠叫的狗、经过的汽车。音频源也可以一次表示这三个音频对象,例如,存在一个音频源(如录音),其中存在讲话的人、吠叫的狗或经过的汽车。在这种情况下,音频源的位置可以被表示为到坐标系的原点的半径、方位角和仰角。除非另有说明,否则贯穿本公开内容,音频对象和音频源可以互换地使用。
[0048]
知道源能量g(ω)是频率的函数使得我们将每个pcm对象以及其位置转换为全景声系数例如,可以使用时频分析技术(诸如通过对pcm流执行快速傅立叶变换(例如,256-、-512-或1024点fft))来获得该源能量。此外,可以表明(因为以上是线性且正交分解),用于每个对象的系数是相加的。以这种方式,多个pcm对象可以由系数来表示(例如,作为用于各个音频源的系数向量的总和)。本质上,这些系数包含关于声场的信息(压力作为3d坐标的函数),并且上述系数表示在观测点附近从各个对象到整个声场的表示的变换。
[0049]
本领域技术人员将认识到,可以使用除了在表达式(2)中所示的表示之外的全景声系数的表示(或者等效地,对应的时域系数的表示),诸如不包括半径分量的表示。本领域技术人员将认识到,已知球谐基函数的若干稍微不同的定义(例如,实数、复数、经归一化的(例如,n3d)、半归一化的(例如,sn3d)、furse-malham(fuma或fmh)等),并且因此该表达式(1)(即,声场的球谐分解)和表达式(2)(即,由点源产生的声场的球谐分解)可能以稍微不同的形式出现在文献中。本文描述不限于球谐基函数的任何特定形式,并且实际上通常也适用于其它分层元素集合。
[0050]
在基于场景的方法的情况下存在不同的编码和解码过程。这种编码可以包括用于带宽压缩的一种或多种有损或无损编码技术,诸如量化(例如,量化为一个或多个码本索引中)、冗余编码等。另外或替代地,这种编码可以包括将音频声道(例如,麦克风输出)编码为全景声格式,诸如b格式、g格式、或更高阶全景声(hoa)。hoa是使用mpeg-h 3d音频解码器来
解码的,该解码器可以对利用空间全景声编码器而编码的全景声系数进行解压缩。
[0051]
作为一个说明性示例,麦克风设备102a、102b可以在可以包括多个听觉源(例如,其它扬声器、背景噪声)的环境(例如,厨房、餐厅、健身房、汽车)内操作。在这种情况下,麦克风设备102a、102b、102c可以(例如,由设备的用户手动地,由设备的另一组件自动地)被定向为朝着目标音频源,以便接收目标音频信号(例如,音频或语音)。在一些情况下,可以调整麦克风设备102a、102b、102c朝向。在一些示例中,音频干扰源可能阻挡目标音频信号或向目标音频信号添加噪声。可能期望将干扰去除或衰减。干扰的衰减可以至少部分地基于以下各项来实现:与目标音频源相关联的方向性、目标音频信号的类型(例如,语音、音乐等)或其组合。
[0052]
波束成形器可以在时域或空间频域中利用传统的信号处理技术来实现,以减少对目标音频信号的干扰。当使用全景声表示来表示目标音频信号时,可以使用其它滤波技术,诸如特征值分解、奇异值分解或主成分分析。然而,上述滤波技术在计算上代价高昂并且可能消耗不必要的功率。此外,利用不同的形状因子和麦克风放置,滤波器必须被调谐用于每个设备和配置。
[0053]
相比之下,在本公开内容中描述的技术提供了用于通过使用自适应网络变换或操纵全景声系数表示来滤除不期望干扰的稳健方式。
[0054]
如今存在目前的商业工具来操纵全景声系数。例如,包括fb360 spatializer音频插件的facebook 360 spatial workstation软件套件。另一示例是audioease 360pan套件。然而,这些商业工具需要手动编辑音频文件或格式,以在声场中产生期望变化。相比之下,在本公开内容中描述的技术可以在训练自适应网络之后的推断阶段中不需要手动编辑文件或格式。
[0055]
将参照各图并且在下面的详细描述中描述解决方案的额外背景。
[0056]
所描述的技术可以应用于不同的目标信号类型(例如,语音、音乐、发动机噪声、动物声音等)。例如,每个这样的目标信号类型可以与给定的分布函数(例如,其可以被根据本公开内容的各方面的给定设备学习)相关联。所学习的分布函数可以与源信号的方向性(例如,其可以至少部分地基于设备内的麦克风的物理布置)结合使用以生成纯净的信号音频估计。因此,概括而言,所描述的技术提供使用空间约束和/或目标分布函数(其中的每一者可以至少部分地基于自适应网络(例如,经训练的递归神经网络)来确定)来生成纯净的信号音频估计。
[0057]
下文参照附图描述了本公开内容的特定实现方式。在该描述中,贯穿附图,共同的特征通过共同的附图标记来指定。如本文所使用的,各种术语仅用于描述特定实现方式的目的,而不旨在进行限制。例如,单数形式的“一(a)”、“一个(an)”和“所述(the)”也旨在包括复数形式,除非上下文另外明确地指出。还可以理解的是,术语“包括(comprise)”、“包括(comprises)”、和“包括(comprising)”可以与“包括(include)”、“包括(includes)”或“包括(including)”互换地使用。另外,将理解的是,术语“其中(wherein)”可以与“其中(where)”互换地使用。如本文所使用的,“示例性”可以指示示例、实现方式和/或方面,而不应当被解释为限制或指示优选方式或优选的实现方式。如本文所使用的,用于修饰诸如结构、组件、操作等的元素的序数词(例如,“第一”、“第二”、“第三”等)本身不指示该元素相对于另一个元素的任何优先级或次序,而仅是将该元素与具有相同名称(如果没有使用序数
词的话)的另一元素区分开。如本文所使用的,术语“集合”指代一组一个或多个元素,以及术语“多个”指代多个元素。
[0058]
如本文所使用的,“耦合”可以包括“通信地耦合”、“电耦合”或“物理地耦合”,并且还可以(或替代地)包括其任何组合。两个设备(或组件)可以经由一个或多个其它设备、组件、线、总线、网络(例如,有线网络、无线网络或其组合)等直接或间接地耦合(例如,通信地耦合、电耦合或物理地耦合)。作为说明性的非限制性示例,被电耦合的两个设备(或组件)可以被包括在同一设备或不同设备中,并且可以经由电子器件、一个或多个连接器或感应耦合进行连接。在一些实现方式中,被通信地耦合(诸如进行电子通信)的两个设备(或组件)可以直接或间接地(诸如经由一个或多个线、总线、网络等)发送和接收电信号(数字信号或模拟信号)。如本文所使用的,“直接耦合”可以包括在没有中间组件的情况下耦合(例如,通信地耦合、电耦合或物理地耦合)的两个设备。
[0059]
如本文所使用的,“集成”可以包括“一起制造或销售”。如果用户购买了将设备作为封装的一部分捆绑或包括的封装,则该设备可以是集成的。在一些描述中,两个设备可以耦合,但不一定集成(例如,不同的外围设备可以不集成到设备201、800,但仍然可以“耦合”)。另一示例可以是本文描述的发射机、接收机或天线中的任何一者,其可以“耦合”到一个或多个处理器208、810,但不一定是包括设备201、800的封装的一部分。作为又一示例,麦克风205可以不“集成”到全景声系数缓冲器215中,但可以“耦合”。当使用术语“集成”时,可以从本文所公开的上下文(包括本段)推断出其它示例。
[0060]
如本文所使用的,设备之间的“连接性”或“无线链路”可以是基于各种无线技术,诸如蓝牙、无线保真度(wi-fi)或wi-fi的变型(例如,wi-fi直连)。设备可以基于不同的蜂窝通信系统而是“无线连接的”,诸如长期演进(lte)系统、码分多址(cdma)系统、全球移动通信系统(gsm)系统、无线局域网(wlan)系统、5g、c-v2x或某种其它无线系统。cdma系统可以实现宽带cdma(wcdma)、cdma 1x、演进数据优化(evdo)、时分同步cdma(td-scdma)、或cdma的某个其它版本。另外,当两个设备在视线内时,“连接性”还可以是基于其它无线技术,诸如超声、红外线、脉冲射频电磁能、结构光、或在信号处理(例如,音频信号处理或射频处理)中使用的到达方向技术。
[0061]
如本文所使用的,“推断”或“进行推断”指代自适应网络已经基于约束而学习或收敛其权重并且正在基于未经变换的全景声系数进行推断或预测。推断不包括计算未经变换的全景声系数和经变换的全景声系数之间的误差以及更新自适应网络的权重。在学习或训练期间,自适应网络学习如何执行一任务或一系列任务。在学习或训练之后的推断阶段期间,自适应网络执行其学习的该项任务或该系列任务。
[0062]
如本文所使用的,“元学习”指代在自适应网络的权重已经收敛之后的细化学习。例如,在一般训练和一般优化之后,可以针对特定用户执行进一步的细化学习,使得自适应网络的权重能够适配特定用户。利用细化的元学习不仅仅局限于特定用户。例如,对于具有局部混响特性的特定渲染场景,可以对权重进行细化以适配对局部混响特性的更好执行。
[0063]
如本文所使用的,a“和/或”b意味着“a和b”、或“a或b”、或“a和b”和“a或b”两者是适用的或可接受的。
[0064]
在图2a-2e的相关联的描述中,使用虚线来绘制约束块以指定训练阶段。在图2a-2e、图3a-3b、图4a-4a、图5a-d、7a-7c中的其它块周围使用其它虚线,以根据上下文和/或应
用来指定这些块可以是可选的。如果一个块是利用实线来绘制的,但位于具有虚线的块内,则根据上下文和/或应用,具有虚线的块以及实线内的块可以是可选的。
[0065]
参考图2a,示出了根据本公开内容的一些示例的可操作以利用约束260和目标全景声系数70来执行对自适应网络225的权重的自适应学习的系统的特定说明性示例。在图2a中所示的示例中,处理器208包括自适应网络225,其对被存储在全景声系数缓冲器215中的全景声系数执行信号处理。在一些实现方式中,全景声系数缓冲器215中的全景声系数也可以被包括在处理器208中。在其它实现方式中,全景声系数缓冲器可以位于处理器208外部或可以位于另一设备(未示出)上。在学习自适应网络225的权重之后,全景声系数缓冲器215中的全景声系数可以由自适应网络225经由推断阶段进行变换,从而得到经变换的全景声系数226。自适应网络225和全景声系数缓冲器215可以耦合在一起以形成全景声系数自适应变换器228。
[0066]
在一个实施例中,自适应网络225可以使用上下文输入,例如,约束块236的约束260和目标全景声系数70输出可以帮助自适应网络225适配其权重,使得在自适应网络225的权重已经收敛之后,未经变换的全景声系数变为经变换的全景声系数226。应当理解的是,使用全景声系数缓冲器215可以存储利用麦克风阵列205直接捕获的或根据麦克风阵列205的类型而推导的全景声系数。全景声系数缓冲器215还可以存储合成的全景声系数、或从具有声道音频格式或对象音频格式的多声道音频信号转换的全景声系数。此外,一旦自适应网络225已经被训练并且自适应网络225的权重已经收敛,约束块260就可以可选地位于处理器208内,以用于继续适配或学习设备201的权重。在不同的实施例中,一旦权重已经收敛,就可以不再需要约束块236。一旦权重被训练还包括约束块236可能占用不必要的空间,因此其可以可选地被包括在设备201中。在另一实施例中,约束块236可以被包括在服务器(未示出)上并且离线处理,并且自适应网络225的经收敛的权重可以在设备201已经在操作之后被更新,例如,权重可以无线地在空中更新。
[0067]
也可以被包括在处理器208中的渲染器230可以渲染由自适应网络225输出的经变换的全景声系数。渲染器230的输出可以被提供给误差度量器237。误差度量器237可以可选地位于设备201中。替代地,误差度量器237可以位于设备201外部。在一个实施例中,无论位于设备201上还是设备201外部,误差度量器237都可以被配置为将多声道音频信号与经渲染的经变换全景声系数进行比较。
[0068]
另外或替代地,可以存在可选地被包括在设备201中(或者在一些实现方式中,在设备201外部(未示出))的测试渲染器238,其中测试渲染器对可选地从麦克风阵列205输出的全景声系数进行渲染。在其它实现方式中,被存储在全景声系数缓冲器215中的未经变换的全景声系数可以由测试渲染器238进行渲染,并且输出可以被发送给误差度量237。
[0069]
在另一实施例中,测试渲染器238和渲染器230的输出都不被发送给误差度量器237,而是将未经变换的全景声系数与经变换的全景声系数226的版本进行比较,其中,自适应网络225的权重尚未收敛。也就是说,经变换的全景声系数226和未经变换的全景声系数之间的误差使得针对包括目标全景声系数的约束的经变换的全景声系数226仍然在可接受的误差门限之外,即,不稳定。
[0070]
未经变换的全景声系数和经变换的系数226之间的误差可以用于更新自适应网络225的权重,使得经变换的全景声系数226的将来版本更接近经变换的全景声系数的最终版
本。随着时间的推移,随着在不同的方向处呈现不同的输入音频源和/或使用声级来训练自适应网络225,未经变换的全景声系数和经变换的系数的版本之间的误差变得更小,直到当未经变换的全景声系数和经变换的系数226之间的误差稳定时自适应网络225的权重收敛。
[0071]
如果误差度量器237正在比较经渲染的未经变换全景声系数和经变换的全景声系数226的经渲染的版本,则所描述的过程是相同的,除了在不同的域中。例如,经渲染的未经变换全景声系数和经渲染的经变换系数之间的误差可以用于更新自适应网络225的权重,使得经渲染的经变换全景声系数的将来版本更接近经渲染的经变换全景声系数的最终版本。随着时间的推移,随着在不同的方向处呈现不同的输入音频源和/或使用声级来训练自适应网络225,经渲染的未经变换全景声系数和经渲染的经变换系数的版本之间的误差变得更小,直到当经渲染的未经变换全景声系数和经渲染的经变换系数之间的误差稳定时自适应网络225的权值收敛。
[0072]
约束块236可以包括不同的块。本文描述了在约束块236中可以包括哪种类型的不同块的示例。
[0073]
参考图2b,示出了根据本公开内容的一些示例的可操作以利用约束和目标全景声系数来执行对自适应网络的权重的推断和/或自适应学习的系统的特定说明性示例,其中,约束包括方向。方向可以在三维坐标系中利用方位角和仰角来表示。
[0074]
在一个实施例中,多声道音频信号可以由麦克风阵列205输出或是先前合成的(例如,被存储的歌曲或由内容创建者或设备201的用户创建的音频录音),其包括处于固定角度的第一音频源。多声道音频信号可以包括一个以上的音频源,即,可以存在第一音频源、第二音频源、第三音频源或额外的音频源。可以包括第一音频源、第二音频源、第三音频源或额外的音频源的不同的音频源211可以在自适应网络225的训练期间被放置在不同的音频方向214处。进入自适应网络225的输入可以包括可以从麦克风阵列205直接输出或可以由内容创建者在训练之前合成的未经变换的全景声系数,例如,歌曲或录音可以以全景声格式来存储,并且未经变换的全景声系数可以被存储或从全景声格式来推导。如果麦克风阵列不一定输出未经变换的全景声系数,则未经变换的全景声系数也可以是耦合到麦克风阵列205的全景声转换器212a的输出。
[0075]
如上所讨论的,自适应网络225还可以具有与约束260(例如,约束260a)一起包括的目标或期望的全景声系数集合作为输入。可以利用约束块236b中的全景声转换器212a来生成目标或期望的全景声系数集合。还可以将目标或期望的全景声系数集合存储在存储器中(例如,在全景声系数缓冲器的另一部分中或在不同的存储器中)。替代地,特定方向和音频源可以由麦克风阵列205捕获或合成,并且自适应网络225可以限于学习对这些特定方向执行空间滤波的权重。
[0076]
此外,约束260a可以包括表示约束260a的标签或与约束260a相关联的标签。例如,如果自适应网络225正在以方向60度进行训练,则可以存在值60或60所在的值范围。例如,如果空间分辨率约束是相隔开10度,则可以表示(360/10)=36个值范围。如果空间约束是相隔开5度,则可以表示(360/5)=72个值范围。因此,标签可以是在值范围内60所在的二进制值。例如,如果当分辨率为10度时,0到9度是第0值范围,则60位于跨越60-69度的第6值范围内。对于这种情况,标签可以由二进制值6=000110来表示。在另一示例中,如果当分辨率为5度时,0到4度是第0值范围,则60位于跨越60-64度的第13值范围内。对于这种情况,标签
可以具有二进制值13=0001101。如果存在两个角度(例如,在三维坐标系中表示方向),则标签可以将两个角度串接为未经变换的全景声系数。所学习的角度的分辨率不一定必须相同。例如,一个角度(即仰角)可以具有10度的分辨率,而另一个角度(即方位角)可以具有5度的分辨率。标签可以与目标或期望的全景声系数相关联。标签可以是固定的数字,其可以在自适应网络225的训练和/或推断操作期间充当输入,以在自适应网络225从全景声系数缓冲器215接收到未经变换的系数时输出经变换的全景声系数226。
[0077]
在一个说明性示例中,自适应网络225初始基于约束(例如,约束260a)来适配其权重以执行任务。任务包括保留音频源(例如,第一音频源)的方向(例如,角度)246。自适应网络225具有在某个范围内的目标方向(例如,角)(例如,与坐标系的原点相距5-30度)。
[0078]
坐标系可以是相对于一个房间的,该房间的一个角或中心可以充当坐标系的原点。另外或替代地,坐标系可以是相对于麦克风阵列205的(如果存在的话,或者其可以位于的地方)。替代地,坐标系可以是相对于设备201的。另外或替代地,坐标系可以是相对于设备的用户(例如,可以在设备201和另一设备(例如,用户所佩戴的耳机)之间存在无线链路)或者位于设备201上以定位用户相对于设备201位于何处的相机或传感器的。在一个实施例中,如果例如设备201是耳机(例如,虚拟现实耳机、增强现实耳机、音频耳机或眼镜),则用户可以佩戴设备201。在不同的实施例中,设备201可以被集成到车辆的一部分中,并且用户在车辆中的位置可以用作坐标系的原点。替代地,车辆中的不同点也可以充当坐标系的原点。在这些示例中的每个示例中,第一音频源“a”可以位于特定角度处,该特定角度也被表示为相对于诸如坐标系的原点之类的固定点的方向。
[0079]
在一个示例中,用于保留第一音频源的方向246的任务在空间上滤除在某个范围内(例如,5-30度)的目标方向之外的其它音频源(例如,第二音频源、第三音频源和/或额外的音频源)或噪声。这样,如果第一音频源位于60度的固定方向处,则自适应网络225可以滤除在60度 /-2.5度到15度(即,[45-57.5度到62.5-75度])之外的音频源和/或噪声。因此,误差度量器237可以产生被最小化的误差,直到自适应网络225的输出是经变换的全景声系数226为止,经变换的全景声系数226表示包括位于固定角度(例如,15度、45度、60度、或在坐标系中在相对于至少一个固定轴的0到360度之间的任何角度)处的第一音频源“a”的目标信号的声场。
[0080]
在三维坐标系中,可以存在两个固定角度(有时被称为仰角和方位角),其中,一个角度是相对于参考坐标系中的x-z平面(例如,设备201的x-z平面、或房间的一侧、或车辆的一侧、或麦克风阵列205),而另一个轴是在参考坐标系的z-y平面(例如,设备201的y-z平面、或房间的一侧、或者车辆的一侧、或者麦克风阵列205)中。哪一侧被称为x轴、y轴和z轴可以根据应用而变化。然而,一个示例是考虑麦克风阵列的中心,并且直接在麦克风阵列前面朝着中心行进的音频源可以被认为来自x-y平面中的y方向。如果音频源是从麦克风阵列的顶部(不管定义如何)到达的,则顶部可以被认为是z方向,并且音频源可以在x-z平面中。
[0081]
在一些实现方式中,麦克风阵列205可选地被包括在设备201中。在其它实现方式中,麦克风阵列205不用于生成被实时地转换为未经变换的全景声系数的多声道音频信号。有可能将文件(例如,被存储的歌曲或由内容创建者或设备201的用户创建的音频录音)转换为未经变换的全景声系数26。
[0082]
自适应网络225可以一次对多个目标信号进行滤波。例如,自适应网络225可以对
位于不同的固定角度处的第二音频源“b”和/或位于第三固定角度处的第三音频源“c”进行滤波。尽管参考固定角度,但是本领域普通技术人员理解,固定角度可以表示三维坐标系中的方位角和仰角两者。因此,一旦自适应网络225已经将其权重适配以学习如何执行空间滤波的任务,自适应网络225就可以在多个固定方向(例如,方向1、方向2和/或方向3)处执行空间滤波的任务。对于每个目标信号,误差度量器237产生在目标信号(例如,目标或期望的全景声系数70或可以从中推导目标或期望的全景声系数70的音频信号)和经渲染的经变换全景声系数之间的误差。与误差度量器237类似,测试渲染器238可以可选地位于设备201内部或设备201外部。此外,测试渲染器238可以可选地渲染未经变换的全景声系数,或者可以使多声道音频信号通过进入误差度量器237。未经变换的全景声系数可以表示包括第一音频源、第二音频源、第三音频源或甚至更多音频源和/或噪声的声场。因此,目标信号可以包括一个以上的音频源。
[0083]
例如,在推断期间,自适应网络225可以使用所学习的或经收敛的权重集合,该权重集合允许自适应网络225在空间上滤除来自除了期望方向之外的所有方向的声音。这种应用可以包括声源在相对固定位置处。例如,声源可以是一个或多个人位于房间或车辆中的固定位置处(在例如5-30度的公差范围内)。
[0084]
在另一示例中,在推断期间,自适应网络225可以使用所学习的或经收敛的权重集合来保留来自某些方向或角度的音频,并且在空间上滤除位于其它方向或角度处的其它音频源和/或噪声。另外或替代地,与被保留的目标音频源或方向相关联的混响也可以被用作约束260a的一部分。在扩音器240aj的系统中,在经变换的全景声系数226被渲染器230渲染并且被扩音器240aj用来播放所产生的音频信号之后,用户可以听到在保留方向246处的第一音频源。
[0085]
其它示例可以包括保留在与图2b中所示的音频方向不同的音频方向处的一个音频源的方向。另外或替代地,示例可以包括保留在不同音频方向处的一个以上的音频源的方向。例如,可以保留在10度( /-5-30度范围)和80度( /-5-30度范围)处的音频源。另外或替代地,可以保留的可能音频方向的范围可以包括15到165度的方向,例如,在麦克风阵列的大部分的前方部分内或在设备的前方的任何角度,其中,前方包括15到165度的角度,或者在一些用例中包括更大的角度范围(例如,0到180度)。
[0086]
参考图2c,示出了根据本公开内容的一些示例的可操作以利用约束来执行对自适应网络的权重的推断和/或自适应学习的系统的特定说明性示例,其中,约束和目标全景声系数70是基于使用声场缩放器的。图2c的描述的部分与图2a和图2b的描述类似,除了与图2b的约束块236a相关联的包括方向嵌入器210的某些部分被替换为与图2c的约束块236b相关联的包括声场缩放器244的某些部分之外。
[0087]
在图2c的说明性示例中,音频源“a”(例如,其是第一音频源)、“b”(例如,其是第二音频源)和“c”(例如,其是第三音频源)分别位于45度、75度和120度的不同音频方向处。音频方向是相对于与麦克风阵列205相关联的坐标系的原点(0度)来示出的。然而,如上所述,坐标系的原点可以与麦克风阵列、房间、车辆的舱内位置、设备201等的不同部分相关联。第一音频源“a”、第二音频源“b”、第三音频源“c”可以位于在自适应网络225b的训练期间使用的不同的音频源211集合中。
[0088]
除了不同的音频方向214和不同的音频源211之外,不同的缩放值216可以针对不
同的音频方向214中的每个不同的音频方向和不同的音频源211中的每个不同的音频源而改变。不同的缩放值216可以将表示被输入到自适应网络225b中的不同的音频源211的未经变换的全景声系数放大或衰减。
[0089]
其它示例可以包括在训练之前或在训练之后以与图2c中所示的音频角度不同的音频角度来旋转表示音频源的未经变换的全景声系数。此外,特定方向和音频源可以由麦克风阵列205捕获或合成,以及自适应网络225b可以限于学习对那些特定方向执行空间滤波和旋转的权重。
[0090]
另外,在另一实施例中,可以省略方向嵌入器,并且声场可以利用缩放值216来缩放。在这种情况下,还可能直接在全景声域中缩放整个声场,并且使声场缩放器244直接对全景声系数进行操作(在被存储到全景声系数缓冲器215中之前)。
[0091]
例如,声场缩放器244可以单独地缩放音频源的未经变换的全景声系数26的表示,例如,第一音频源可以通过正或负缩放值216a来缩放,而第二音频源可能根本没有通过任何缩放值216进行缩放。在这种情况下,表示来自特定方向的第二音频源的未经变换的全景声系数26可以已经被输入到自适应网络225b中(其中不存在缩放值216a),或者表示来自特定方向的第二音频源的被输入到自适应网络225b中的未经变换的全景声系数26可以绕开声场缩放器244(即,没有被呈现给声场缩放器244)。
[0092]
此外,约束260b可以包括表示约束260b或与约束260b相关联的标签。例如,如果自适应网络225正在利用方位角214a、仰角214b或两者以及缩放值216进行训练,则可以将缩放值与未经变换的全景声系数串接。使用与图2b相关联的用于方位角214a和仰角214b的示例,可以在仰角214a、214b之前或在仰角214a、214b之后串接缩放值216的表示。也可以对缩放值216进行归一化。例如,假设未经归一化的缩放值216在-5到 5之间变化,则经归一化的缩放值可以在-1到1或0到1之间变化。缩放值16可以由不同的缩放值来表示,例如,以不同的缩放值分辨率和不同的分辨率步长来表示。假设每.01值,缩放值216就变化。这将表示100个不同的缩放值,并且可以由7比特数字来表示。作为一个示例,缩放值.17可以由二进制数字18来表示,即第18个分辨率步长.01。作为另一示例,假设分辨率步长是.05,那么.17的值可以用二进制数字3来表示,因为,.17最接近针对不同的缩放值分辨率的第四步长(.15),即0=00000,.05=00001,.1=00010,.15=00011。因此,作为一个示例,标签可以包括用于方位角214a、仰角214b和缩放值216的二进制值。
[0093]
参考图2d,根据本公开内容的一些示例的可操作以利用多个约束和目标全景声系数来执行对自适应网络的推断和/或进行推断的系统的特定说明性示例,其中多个约束包括使用多个方向。图2d的描述中的与图2b和/或图2c相关联的推断阶段有关的部分是适用的。
[0094]
在图2d中,存在被配置为在不同的约束260c下进行操作的多个自适应网络225a、225b、225c。在一个实施例中,多个自适应网络225a、225b、225c的输出可以利用组合器60进行组合。组合器60可以被配置为将由每个自适应网络225a、226b、225c分别输出的各个经变换的全景声系数226da、226db、226dc线性地相加。因此,经变换的全景声系数226d可以表示各个经变换的全景声系数226da、226db、226dc的线性组合。经变换的全景声系数226d可以由渲染器240进行渲染并且被提供给一个或多个扩音器241a。一个或多个扩音器241a的输出可以是三个音频流。第一音频流1 243a可以如同源自于第一方向214a1、214b1一样来由
一个或多个扩音器241a播放。第二音频流2 243b可以如同源自于第二方向214a2、214b2一样来由一个或多个扩音器241a播放。第三音频流3 243c可以如同源自于第二方向214a3、214b3一样来由一个或多个扩音器241a播放。本领域普通技术人员将认识到,第一、第二和第三音频流可以互换地被称为第一、第二和第三音频源。也就是说,一个音频流可以包括3个音频源243a、243b、243c,或者可以存在三个单独的音频流243a、243b、243c,它们听上去如同源自于三个不同的方向:方向1(方位角214a1,仰角214b1);方向2(方位角214a2,仰角214b2);方向3(方位角214a3,仰角214b3)。每个音频流或音频源可以被位于更靠近一个或多个扩音器241a正将音频源引导到的方向的不同的人听到。例如,第一个人254a可以被定位为更好地听到第一音频流或音频源214a1。第二个人254b可以被定位为更好地听到第二音频流或音频源214a2。第三个人25cb可以被定位为更好地听到第三音频流或音频源214a3。
[0095]
参考图2e,根据本公开内容的一些示例的可操作以利用约束和目标全景声系数来执行对自适应网络的权重的推断和/或进行推断和/或自适应学习的系统的特定说明性示例,其中,该约束包括以下各项中的至少一项:理想麦克风类型、目标阶数、形状因子麦克风位置、模型/形状因子。
[0096]
在图2e中,示出了一种理想麦克风类型,诸如可以具有位于球体的点周围的32个麦克风的麦克风阵列102a、或具有四面体形状的包括四个麦克风的麦克风阵列102b,其充当理想麦克风类型的示例。在训练期间,不同的音频方向214和不同的音频源可以用作由这些麦克风阵列102a、102b捕获的输入。对于四面体麦克风阵列102b的情况,其输出是来自每个麦克风的一组声压,其可以被分解为其球形系数并且可以利用记号(w,x,y,z)来表示,作为全景声系数。在球形麦克风阵列102a的情况下,其输出也是来自每个麦克风的一组声压,其可以被分解为其球形系数。
[0097]
通常,对于麦克风阵列,用于确定用于给定麦克风集合的最少全景声系数的麦克风数量取决于将全景声阶数加1并且然后进行平方。例如,对于具有25个系数的四阶全景声信号,输出麦克风输出的最小数量为25,m=(n 1)2,其中n=全景声阶数。使用该公式提供了最小方向采样方案,使得用于确定全景声系数的数学运算是基于球基函数乘以来自麦克风阵列102b的集体麦克风的声压的平方倒数。因此,对于理想麦克风阵列102b输出,全景声转换器212dt将麦克风的声压转换为如上所解释的全景声系数。可以在用于非理想麦克风阵列的全景声系数中使用其它操作,以将麦克风的声压转换为全景声系数。
[0098]
在自适应网络225e的训练阶段期间,约束块236e中的控制器25et可以将一个或多个目标全景声系数存储在全景声缓冲器30e中。例如,如图2e所示,全景声系数缓冲器30d可以存储一阶目标全景声系数,其可以是从四面体麦克风阵列102a输出的,或者在全景声转换器212et将麦克风阵列102b的输出转换为全景声系数之后输出的。控制器25et可以在训练期间向全景声系数缓冲器30e提供不同的阶数。
[0099]
在自适应网络225e的训练阶段期间,设备201(例如,手持机或耳机)可以包括捕获不同的音频源211和不同的音频方向214的多个麦克风(例如,四个)(理想麦克风102a、102b)。在一个实施例中,不同的音频源211和不同的音频方向214是与被呈现给理想麦克风102a、102b的音频源和方向相同的。在不同的实施例中,不同的音频源211和不同的音频方向可以被合成或模拟,如同它们被实时捕获一样。在任一情况下,在设备201包括四个麦克
风的示例中,麦克风输出210可以由全景声转换器212di转换为未经变换的全景声系数26,并且未经变换的全景声系数26可以被存储在全景声系数缓冲器215中。
[0100]
在自适应网络225e的训练阶段期间,控制器25e可以向自适应网络225e提供一个或多个约束260d。例如,控制器25e可以向自适应网络225e提供目标阶数的约束。在一个实施例中,自适应网络225e的输出包括经变换的全景声系数226处于全景声系数的期望目标阶数75e的估计。由于自适应网络225e的权重学习了如何从自适应网络225e产生估计用于不同的音频方向214和不同的音频源211的全景声系数的目标阶数75e的输出。然后,在权重的训练期间可以使用不同的目标阶数,直到自适应网络225e的权重已经收敛为止。
[0101]
在不同的实施例中,当呈现不同的目标阶数时,可以向自适应网络225e呈现额外的约束。例如,在自适应网络225e的训练阶段期间也可以使用理想麦克风类型73e的约束。这些约束可以作为被串接到未经变换的全景声系数26的标签来添加。例如,不同的阶数可以通过3比特数字来表示,以表示阶数0..7。理想麦克风类型可以通过二进制数字来表示,以表示四面体麦克风阵列102b或球形麦克风阵列102a。形状因子麦克风位置也可以作为约束来添加。例如,可以表示手持机具有多个侧面:例如,顶侧、底侧、前侧、后侧、左侧和右侧。在其它实施例中,手持机还可以具有朝向(其自身的方位角和仰角)。麦克风的位置可以被放置在与这些侧面之一上的参考点相距一定距离处。麦克风和每个侧面的位置以及朝向和形状因子可以被添加为约束。作为一个示例,各侧面可以利用6个数字{1、2、3、4、5、6}来表示。麦克风的位置可以被表示为表示32个数字{1..31}的4位二进制数字,其可以以厘米为单位来表示距离。形状因子也可以用于在手持机、平板设备、膝上型计算机等之间进行区分。根据设计,也可以使用其它示例。
[0102]
在一个实施例中,还可能认识到,未经变换的全景声系数也可以被合成并且被存储在全景声系数缓冲器215中,而不是由非理想麦克风阵列捕获。
[0103]
在一个特定实施例中,可以训练自适应网络225e以学习如何校正方向性调整误差。作为一个示例,设备201(例如,手持机)可以包括麦克风阵列205,如图2e所示。为了说明性目的,麦克风输出210被提供给两个方向性调整器(方向性调整器a 42a、方向性调整器b 42b)。方向性调整器和组合器44将麦克风输出210转换为全景声系数。这样,全景声转换器212eri的一种配置可以包括方向性调整器42a、42b和组合器44。输出w x yz 45是一阶全景声系数。然而,当音频源正来自某些方位角或仰角时,将这种架构用于全景声转换器212eri可能引入偏置误差。当音频源正来自某些方位角或仰角时,通过将目标一阶全景声系数呈现给渲染器230并且使用输出来更新自适应网络225e的权重,或者通过将目标一阶全景声系数直接与输出w x y z 45进行比较,自适应网络225e的权重可以被更新并且最终收敛以校正偏置误差。偏置误差可能出现在不同的时间频率处。例如,当音频源处于90度仰角时,一阶全景声系数可以准确地表示某些频带(例如,0-3khz、3khz-6khz、6khz-9khz、12khz-15khz、18khz-21khz)中的音频源。然而,在其它频带(9khz-12khz、15khz-18khz、21khz-24khz)中,音频源可能表现为偏离其应当处于的位置。
[0104]
在推断阶段期间,由被包括在设备201(例如,手持机)上的麦克风阵列205提供的麦克风输出210可以输出一阶全景声系数w x y z 45。在不同的实施例中,自适应网络225固有地提供经变换的全景声系数226以校正一阶全景声系数w x y z 45偏置误差,因为在某些配置中,可能期望限制自适应网络225的复杂性。例如,在具有有限的存储器大小或计
算资源的耳机的情况下,可能期望被训练以执行一种功能(例如,校正一阶全景声误差)的自适应网络225。
[0105]
在不同的实施例中,自适应网络225可以具有关于目标阶数是1阶的约束75e。可以存在关于理想麦克风类型是手持机的另一约束73e。另外,可以存在关于麦克风阵列205中的每个麦克风的位置在何处以及麦克风阵列205中的麦克风位于手持机的哪一侧的额外约束68e。向自适应网络225ei提供包括当音频源正来自某些方位角或仰角时的偏置误差的一阶全景声系数w x y z 45。自适应网络225ei校正一阶全景声系数w x y z 45偏置误差,并且经变换的全景声系数226输出准确地表示音频源的跨越所有时间频率的仰角和/或方位角。在一些实施例中,还可以存在关于哪种模型类型或形状因子的约束66e。
[0106]
在不同的实施例中,自适应网络225可以具有用于在不引入偏置误差的情况下执行方向性调整的约束75e。也就是说,基于调整由非理想麦克风阵列捕获的麦克风信号(如同麦克风信号已经由在理想麦克风阵列的不同位置处的麦克风捕获一样)的约束,来将未经变换的全景声系数变换为经变换的全景声系数。
[0107]
在另一实施例中,控制器25e可以向渲染器230选择性地提供经变换的全景声系数226e的子集。例如,控制器25e可以控制哪些系数(例如,一阶、二阶等)是全景声转换器212ei的输出。另外或替代地,控制器25e可以选择性地控制将哪些系数(例如,一阶、二阶等)存储在全景声系数缓冲器215中。例如,当球形32麦克风阵列102a提供高达四阶全景声系数(即,25个系数)时,这可能是期望的。全景声系数的子集可以被提供给自适应网络225。三阶全景声系数是四阶全景声系数的子集。二阶全景声系数是三阶全景声系数以及也是四阶全景声系数的子集。一阶全景声系数是二阶全景声系数、三阶全景声系数和四阶全景声系数的子集。另外,经变换的全景声系数226也可以以相同方式(即,较高阶全景声系数的子集)或在一些情况下以混合阶数的全景声系数而被选择性地提供给渲染器230。
[0108]
参考图3a,示出了根据本公开内容的一些示例的可操作以结合一个或多个音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图。可以存在多个音频应用390,这些音频应用390可以被包括在设备201中,并且结合上文与图2a-2e相关联地描述的技术来使用。设备201可以被集成到多个形状因子或设备类别中,例如,如图5a-5d所示。音频应用392也可以被集成到在图6a-6d中所示的设备中。在通过麦克风阵列205捕获或合成音频源的一些应用的情况下,音频应用的输出可以在无线链路301a上经由发射机382被发送给在图3a中所示的另一设备。在图4a-4f中示出了这样的应用390。
[0109]
参考图3b,示出了根据本公开内容的一些示例的可操作以结合一个或多个音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图。可以存在多个音频应用392,这些音频应用392可以被包括在设备201中,并且结合上文与图2a-2e相关联地描述的技术来使用。设备201可以被集成到多个形状因子或设备类别中,例如,如图5a-5d所示。音频应用392也可以被集成到在图6a-6d中所示的设备(例如,车辆)中。在图3b中所示的自适应网络225的经变换的全景声系数225输出可以被提供给一个或多个音频应用392,其中,由全景声系数缓冲器215中的未经变换的全景声系数表示的音频源可以在被存储在全景声系数缓冲器215中之前初始以压缩形式接收。例如,压缩形式的未经变换的全景声系数可以被存储在存储器381中的分组中,或者在无线链路301b上经由接收机385接收并且经由耦合到全景声系数缓冲器215的解码器383解压缩,如图3b所示。在图4c-4f中示
出了此类应用392。
[0110]
设备201可以包括如与图2b-2e和图3a-3b相关联地描述的不同能力。设备201可以包括被配置为存储在不同时间段处的未经变换的全景声系数的存储器。设备201还可以包括一个或多个处理器,其被配置为获得在不同时间段处的未经变换的全景声系数,其中,在不同时间段处的未经变换的全景声系数表示在不同时间段处的声场。一个或多个处理器可以被配置为基于约束260、260a、260b、260c、260d和目标全景声系数,来将至少一个自适应网络225a、225b、225c、225ba、225bb、225bc、225e应用于在不同时间段处的未经变换的全景声系数,以生成在不同时间段处的经变换的全景声系数226。在不同时间段处的经变换的全景声系数226可以表示在不同时间段处的经修改的声场,其是基于约束260、260a、260b、260c、260d来修改的。
[0111]
此外,经变换的全景声系数226可以由第一音频应用使用,第一音频应用包括由一个或多个处理器执行的指令。此外,设备201还可以包括全景声系数缓冲器215,其被配置为存储未经变换的全景声系数26。
[0112]
在一些实现方式中,设备201可以包括耦合到全景声系数缓冲器215的麦克风阵列205中的麦克风,麦克风阵列205被配置为捕获由全景声系数缓冲器215中的未经变换的全景声系数表示的一个或多个音频源。
[0113]
参考图4a,示出了根据本公开内容的一些示例的、可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用使用编码器和存储器。
[0114]
设备201可以包括自适应网络225、225g和音频应用390。在一个实施例中,第一音频应用390a可以包括由一个或多个处理器执行的指令。第一音频应用390a可以包括:利用编码器480来压缩在不同时间段处的经变换的全景声系数,并且将经压缩的经变换全景声系数226存储到存储器481中。经压缩的经变换全景声系数226可以由发射机482在发送链路301a上发送。发送链路301a可以是设备201与远程设备之间的无线链路。
[0115]
图4b示出了根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用编码器、存储器和解码器。
[0116]
在图4b中,设备201可以包括自适应网络225、225g和音频应用390。在一个实施例中,第一音频应用390b可以包括由一个或多个处理器执行的指令。第一音频应用390b可以包括利用编码器480来压缩在不同时间段处的经变换的全景声系数,并且将经压缩的经变换全景声系数226存储到存储器481中。经压缩的经变换全景声系数226可以利用一个或多个处理器从存储器481中检索,并且被解码器483解压缩。第二音频应用390b的一个示例可以是摄像机应用,其中,音频被捕获并且可以被压缩和存储以供将来回放。如果用户返回查看视频录制或者如果其仅仅是音频录音,则可以包括解码器483或与解码器483集成的一个或多个处理器可以对经压缩的在不同时间段处的经变换的全景声系数进行解压缩。
[0117]
参考图4c,示出了根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用渲染器230、关键字检测器402和设备控制器491。在图4c中,设备201可以包括自适应网络225、225g和音频应用390。在一个实施例中,第一音频应用390c可以包括由一个或多个
处理器执行的指令。第一音频应用390c可以包括渲染器230,渲染器230被配置为渲染在不同时间段处的经变换的全景声系数226。第一音频应用390c还可以包括关键字检测器402,其耦合到被配置为基于约束260来控制设备的设备控制器491。
[0118]
参考图4d,示出了根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用渲染器230、方向检测器403和设备控制器491。在图4d中,设备201可以包括自适应网络225和音频应用390。在一个实施例中,第一音频应用390c可以包括由一个或多个处理器执行的指令。第一音频应用390c可以包括被配置为渲染在不同时间段处的经变换的全景声系数226的渲染器230。第一音频应用390c还可以包括耦合到设备控制器491的方向检测器403,设备控制器491被配置为基于约束260来控制设备。
[0119]
应当注意的是,在不同的实施例中,经变换的全景声系数226可以被输出为具有作为自适应网络225的推断的一部分的方向检测。例如,在图2b中,经变换的全景声系数226在被渲染时表示其中一个或多个音频源可以听起来如同它们正来自某个方向的声场。在训练阶段期间,方向嵌入器210允许图2b中的自适应网络225执行方向检测功能,作为空间滤波的一部分。因此,在这样的情况下,在音频应用390d中的渲染器230之后可以不再需要方向检测器403和设备控制器491。
[0120]
图4e是根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用渲染器。如本文所解释的,在不同时间段处的经变换的全景声系数226可以被输入到渲染器230中。可以从一个或多个扩音器240播放经渲染的经变换全景声系数。
[0121]
图4f是根据本公开内容的一些示例的可操作以结合音频应用、使用所学习的权重来执行自适应网络的推断的系统的特定说明性方面的框图,其中,音频应用包括使用在图4c、图4d和图4e中描述的应用。图f是以如下方式绘制的:示出耦合到自适应网络225的音频应用392可以在利用解码器对经压缩的在不同时间段处的经变换的全景声系数226进行解压缩之后运行,如结合图3b所解释的。
[0122]
参考图5a,示出了根据本公开内容的一些示例的放置在条带中使得其可以被佩戴并且可操作以执行自适应网络225的推断的设备201的图。图5a描绘了被集成到诸如手持机之类的移动设备504中的、图2a、图2b、图c、图2d、图2e、图3a、图3b、图4a、图4b、图4c、图4d、图4e或图4f的设备201的实现方式的示例。可以在手机中包括多个传感器。多个传感器可以是两个或更多个麦克风105、图像传感器514(例如,被集成到相机中)。尽管被示为在单个位置上,但是在其它实现方式中,多个传感器可以被定位在手持机的其它位置处。诸如显示器520之类的可视接口设备可以允许用户在通过一个或多个扬声器240听到经渲染的经变换全景声系数的同时也观看视觉内容。此外,可以存在被包括在收发机522中的发射机382和接收机385,其提供本文描述的设备201和远程设备之间的连接性。
[0123]
参考图5b,示出了根据本公开内容的一些示例的设备201的图,设备201可以是可操作以执行自适应网络225的推断的虚拟现实或增强现实耳机。图5a描绘了被集成到诸如手持机之类的移动设备504中的、图2a、图2b、图c、图2d、图2e、图3a、图3b、图4a、图4b、图4c、图4d或图4e的设备201的实现方式的示例。可以在耳机中包括多个传感器。多个传感器可以是两个或更多个麦克风105、图像传感器514(例如,被集成到相机中)。尽管被示为在单个位
置上,但是在其它实现方式中,多个传感器可以被定位在耳机的其它位置处。诸如显示器520之类的可视接口设备可以允许用户在通过一个或多个扬声器240听到经渲染的经变换全景声系数的同时也观看视觉内容。此外,可以存在被包括在收发机522中的发射机382和接收机385,其提供本文描述的设备201和远程设备之间的连接性。
[0124]
参考图5c,示出了根据本公开内容的一些示例的设备201的图,设备201可以是可操作以执行自适应网络225的推断的虚拟现实或增强现实眼镜。图5a描绘了被集成到眼镜中的、图2a、图2b、图c、图2d、图2e、图3a、图3b、图4a、图4b、图4c、图4d、图4e或图4f的设备201的实现方式的示例。可以在眼镜中包括多个传感器。多个传感器可以是两个或更多个麦克风105、图像传感器514(例如,被集成到相机中)。尽管被示为在单个位置上,但是在其它实现方式中,多个传感器可以被定位在眼镜的其它位置处。诸如显示器520之类的视觉接口设备可以允许用户在通过一个或多个扬声器240听到经渲染的经变换全景声系数的同时也观看视觉内容。此外,可以存在被包括在收发机522中的发射机382和接收机385,其提供本文描述的设备201和远程设备之间的连接性。
[0125]
参考图5d,示出了根据本公开内容的一些示例的可操作以执行自适应网络225的推断的设备201的图。图5d描绘了被集成到车辆仪表板设备(诸如汽车仪表板设备502)中的、图2a、图2b、图c、图2d、图2e、图3a、图3b、图4a、图4b、图4c、图4d、图4e或图4f的设备201的实现方式的示例。可以在车辆中包括多个传感器。多个传感器可以是两个或更多个麦克风105、图像传感器514(例如,被集成到相机中)。尽管被示为在单个位置上,但是在其它实现方式中,多个传感器可以被定位在车辆的其它位置处(诸如分布在车辆的驾驶室内的各个位置处),或可以位于车辆中每个座椅附近,以检测来自车辆操作员和每个乘客的多模态输入。诸如显示器520之类的可视接口设备被安装或定位(例如,可移除地固定到车辆手持机支架上)在汽车仪表板设备502内,以便对于汽车的驾驶员是可见的。此外,可以存在被包括在收发机522中的发射机382和接收机385,其提供本文描述的设备201和远程设备之间的连接性。
[0126]
参考图6a,示出了根据本公开内容的一些示例的设备201(例如,电视机、平板设备或膝上型计算机、广告牌、或在公共场所中的设备)的图,设备201可操作以执行自适应网络225g的推断。在图6a中,设备201可以可选地包括相机204、和扩音器阵列240(其包括单独的扬声器240ia、240ib、240ic、240id)、和麦克风阵列205(其包括单独的麦克风205ia、205ib)、和显示屏206。与图2a-2e、图3a-3b、图4a-4f和图5a相关联地描述的技术可以在图6a中所示的设备201中实现。在一个实施例中,可以存在利用经变换的全景声系数226表示的多个音频源。
[0127]
扩音器阵列240被配置为输出由被包括在设备201中的渲染器230渲染的经渲染的经变换全景声系数226。经变换的全景声系数226表示指向不同的相应方向的不同音频源(例如,流1和流2被发射到两个不同的相应方向)。不同流的同时传输的一种应用可以用于公共空间中的公共地址和/或视频广告牌设施(诸如机场或火车站)或可能期望不同的消息或音频内容的另一种情况。例如,可以实现这样的情况,使得显示屏206上的相同视频内容对于两个或更多个用户中的每一者是可见的,其中,扩音器阵列240输出在不同时间段处的经变换的全景声系数226,以便在不同的相应视角以不同语言(例如,英语、西班牙语、汉语、韩语、法语等中的两种或更多种)表示相同的伴随的音频内容。在较小的环境(诸如家庭或
办公室)中,还可能期望视频节目的呈现以及以两种或更多种语言表示音频内容的伴随的经变换的全景声系数226的同时呈现。
[0128]
其中由经变换的全景声系数表示的音频分量可以包括不同的远端音频内容的另一应用是用于语音通信(例如,电话呼叫)。替代地或另外,由在不同时间段处的经变换的全景声系数226表示的两个或更多个音频源中的每一者可以包括用于不同的相应媒体再现(例如,音乐、视频节目等)的音频轨道。
[0129]
对于其中由经变换的全景声系数226表示的不同音频源与不同视频内容相关联的情况,可能期望在多个显示屏幕上和/或利用具有多视图能力的显示屏幕来显示这样的内容(例如,显示屏幕206也可以是具有多视图能力的显示屏幕)。具有多视图能力的显示屏的一个示例被配置为使用不同的光偏振(例如,正交线性偏振或相对偏手性的圆偏振)来显示视频节目中的每个视频节目,并且每个观看者佩戴一组护目镜,该组护目镜被配置为使具有期望视频节目的偏振的光通过并且阻挡具有其它偏振的光。在具有多视图能力的显示屏幕的另一示例中,不同的视频节目至少在两个或更多个视角处是可见的。在这种情况下,扩音器阵列的实现方式将用于不同视频节目中的每个视频节目的音频源引导到相应视角的方向上。
[0130]
在多源应用中,可能期望提供在由经变换的全景声系数226表示的相邻音频源的朝向的方向之间的大约30度或40度到60度的间隔。一种应用是向(例如,在沙发上)肩并肩坐在扩音器阵列240前方的两个或更多个用户中的每一者提供不同的相应音频源分量。在1.5到2.5米的典型视距下,观看者所占据的跨度大约为30度。利用四个麦克风的阵列205,可以获得大约15度的分辨率。在具有更多麦克风的阵列的情况下,用户之间的更窄距离是可能的。
[0131]
参考图6b,示出了根据本公开内容的一些示例的可操作以执行自适应网络225、225g的推断的设备201(例如,车辆)的图。在图6b中,设备201可以可选地包括相机204、扩音器阵列240(未示出)和麦克风阵列205。与图2a-2e、图3a-3b、图4a-4f和图5d相关联地描述的技术可以在图6b中所示的设备201中实现。
[0132]
在一个实施例中,由自适应网络225输出的经变换的全景声系数226可以表示在讲话者区域44中捕获的语音。如图所示,可以存在用于驾驶员的扬声器区域44。另外或替代地,也可以存在用于每个乘客的扬声器区域44。自适应网络225可以基于约束260b、约束260d或其某种组合来输出经变换的全景声系数226。由于在行驶时可能存在道路噪声,在由经变换的全景声系数226表示的扬声器区域外部的音频或噪声在被渲染时(例如,如果在电话呼叫上)可能由于自适应网络225的空间滤波特性而听起来更加衰减。在另一示例中,驾驶员或乘客可能正在说出用于控制车辆中的功能的命令,并且可以基于与图4d相关联地描述的技术来使用由经变换的全景声系数226表示的命令。
[0133]
参考图6c,示出了根据本公开内容的一些示例的可操作以执行自适应网络225的推断的设备201(例如,电视机、平板设备、或膝上型计算机)的图。在图6b中,设备201可以可选地包括相机204、和扩音器阵列240(其包括单独的扬声器240ia、240ib、240ic、240id)、和麦克风阵列205(其包括单独的麦克风205ia、205ib)、和显示屏206。与图2a-2e、图3a-3b、图4a-4f和图5a-5c相关联地描述的技术可以在图6c中所示的设备201中实现。在一个实施例中,可以存在利用经变换的全景声系数226表示的多个音频源。
[0134]
由于隐私可能是一个关注点,所以经变换的全景声系数226可以表示在被扩音器阵列240渲染时被定向为在隐私区域50中听起来更大声但在隐私外部听起来更柔和(例如,通过使用与图2b、图2c、图2d和/或图2e相关联地描述的技术的组合)的音频内容。在隐私区域50外部的人可能听到音频内容的被衰减的版本。可能期望设备201响应于传入和/或传出的电话呼叫来激活隐私区域模式。当用户期望更多隐私时,可以在设备201上发生这样的实现方式。可能期望通过使用掩码信号来增加在隐私区域50外部的隐私,掩码信号的频谱是对将在隐私区域50内听到的一个或多个音频源的频谱的互补。掩码信号也可以由经变换的全景声系数226来表示。例如,掩码信号可以在接收到语音(经由电话呼叫而接收的)的某个角度范围外部的空间方向上,使得在黑暗区域(在隐私区域外部的区域)中的附近人听到声音的“白色”频谱,并且保护用户的隐私。在替代的电话呼叫场景中,掩码信号是其电平仅足以高于语音的子带掩码门限的嘈杂语噪声,并且当渲染经变换的全景声系数时,在黑暗区域中会听到嘈杂语噪声。
[0135]
在另一用例中,该设备用于再现所记录的或流式传输的媒体信号,例如,音乐文件、广播音频或视频呈现(例如,无线电单元或电视机)或通过互联网而流式传输的电影或视频剪辑。在这种情况下,隐私可能不太重要,并且设备201可能期望使期望音频内容在黑暗区域中具有随时间而大幅降低的幅度电平并且在隐私区域50中具有正常范围。与语音通信信号相比,媒体信号可以具有较大的动态范围和/或可以随时间而不太稀疏。
[0136]
参考图6d,示出了根据本公开内容的一些示例的设备201(例如,手持机、平板设备、膝上型计算机、电视机)的图,设备201可操作以执行自适应网络225的推断。在图6d中,设备201可以可选地包括相机204、和扩音器阵列240(未示出)、和麦克风阵列205。与图2a-2e、图3a-3b、图4a-4f和图5a-c相关联地描述的技术可以在图6d中所示的设备201中实现。
[0137]
在一个实施例中,来自两个不同的音频源(例如,正在谈话的两个人)的音频可以位于不同的位置上,并且可以由自适应网络225的经变换的全景声系数226输出来表示。经变换的全景声系数226可以被压缩并且在发送链路301a上被发送。远程设备201r可以接收经压缩的经变换全景声系数,解压缩它们并且将它们提供给渲染器230(未示出)。经渲染的未经压缩的经变换全景声系数可以被提供给扩音器阵列240(例如,以双声道形式),并且被远程用户(例如,佩戴远程设备201r)听到。
[0138]
参考图7a,图7a是根据本公开内容的一些示例的可操作以执行训练的自适应网络的图,其中,自适应网络包括回归器和鉴别器。鉴别器740a可以是可选的。然而,当将约束260与未经变换的全景声系数26串接时,自适应网络225的输出的经变换的全景声系数226可以具有可以被提取的额外比特集合或其它输出。所提取的额外比特集合或其它输出是约束85的估计。可以将约束估计85和约束260与类别损失度量器83进行比较。类别损失度量可以包括相似性损失度量器包括的操作或某种其它误差函数。可以使用由相似性损失度量器81使用的技术之一,将经变换的全景声系数226与目标全景声系数70进行比较。可选地,渲染器230a、230b可以分别渲染经变换的全景声系数226和目标全景声系数70,并且渲染器230a、230b输出可以被提供给相似性损失度量器81。相似性度量器81可以被包括在与图2a相关联地描述的误差度量器237中。
[0139]
可以存在不同的方式来实现如何计算相似性损失度量(s)81。在下文所示的不同等式中,e等于期望值,k等于针对给定阶数的全景声系数的最大数量,并且c是在1和k之间
的系数数量。x是经变换的全景声系数,并且t是目标全景声系数。在一种实现方式中,对于4阶全景声信号,全景声系数的总数(k)是25。
[0140]
一种方式是如下将相似性损失度量s实现为相关性:
[0141]
对于k=1:k{s(k)=e[t(c)x(c k)]/(sqrt(e[t(k)]2)sqrt(e[(x(k)]2]),其中,比较所有的s(k)产生最大相似性值。
[0142]
用于实现s的另一种方式是如下作为累积量等式:
[0143]
对于k=1:k{s(k)={e[t2(c)x(c k)2 e[t2(c)]e[x(k)2]-2e[ti(c)x(c k)]2},其中,比较所有的s(k)产生最大相似性值。
[0144]
用于实现s的另一种方式是如下使用时域最小二乘拟合:
[0145]
对于k=1:其中,比较所有的s(k)产生最大相似性值。注意的是,代替使用如上所示的期望值,用于表示期望的另一种方式包括在构成所使用的音频源短语的至少一数量的帧(音频源短语帧)上至少使用快速求和。
[0146]
用于实现s的另一种方式是如下结合频域来使用快速傅立叶变换(fft):
[0147]
对于k=1:其中,
[0148]
比较所有的s(k)产生最大相似性值。注意的是,在fft中使用的不同频率(f=1..f_帧)上存在额外求和。
[0149]
另一种方式是如下使用itakura-saito距离来实现s:
[0150]
对于k=1:其中,比较所有的s(k)产生最大相似性值。
[0151]
用于实现s的另一种方式是如下基于平方差度量:
[0152]
对于k=1:其中,比较所有的s(k)产生最大相似性值。
[0153]
在一个实施例中,误差度量器237还可以包括类别损失度量器83和组合器84,组合器84用于组合(例如,相加或串行输出)类别损失度量器83和相似性损失度量器81的输出。误差度量器237的输出可以直接更新自适应网络225的权重,或者可以通过使用权重更新控制器78来更新它们。
[0154]
回归器735a被配置为估计从输入变量(未经变换的全景声系数和经串接的约束)到连续输出变量(经变换的全景声系数)的分布函数。神经网络是回归器735a的示例。鉴别器740a被配置为估计输入的类别或分类。因此,还可以对从经变换的全景声系数226的估计中提取的估计约束进行分类。使用这种额外技术可以有助于自适应网络225的训练过程,并且在一些情况下可以提高某些约束值(例如,更精细的度数或缩放值)的分辨率。
[0155]
参考图7b,示出了根据本公开内容的一些示例的可操作以执行推断的自适应网络的图,其中,自适应网络是递归神经网络(rnn)。
[0156]
在一个实施例中,全景声系数缓冲器215可以耦合到自适应网络225,其中,自适应网络225可以是输出经变换的全景声系数226的rnn 735b。递归神经网络可以指代一类人工神经网络,其中,单元(或细胞)之间的连接沿着序列形成有向图。这种性质可以允许递归神经网络表现出动态的时间行为(例如,通过使用内部状态或存储器来处理输入序列)。这种
动态时间行为可以将递归神经网络与其它人工神经网络(例如,前馈神经网络)区分开。
[0157]
参考图7c,示出了根据本公开内容的一些示例的可操作以执行推断的自适应网络的图,其中,自适应网络是长短期记忆网络(lstm)。
[0158]
在一个实施例中,lstm是rnn的一个示例。lstm网络735b可以由多个存储状态(例如,其可以被称为门控状态、门控记忆等)组成,其中,这些存储状态在一些情况下可以由lstm网络735c控制。具体地,每个存储状态可以包括细胞、输入门、输出门和遗忘门。细胞可能负责记忆在任意时间间隔内的值。输入门、输出门和遗忘门中的每一者可以是人工神经元的示例(例如,如在前馈神经网络中)。也就是说,每个门可以计算加权和的激活(例如,使用激活函数),其中,加权和可以是基于对神经网络的训练。尽管在lstm网络的背景中进行描述,但是应当理解的是,所描述的技术可以与多个人工神经网络(例如,包括隐马尔可夫模型、前馈神经网络等)中的任何一者相关。
[0159]
在训练阶段期间,基于应用损失函数来对约束块和自适应网络进行训练。在本公开内容的各方面中,损失函数通常可以指代将事件(例如,一个或多个变量的值)映射到可以表示与该事件相关联的成本的值的函数。在一些示例中,lstm网络可以通过调整用于各个门的加权和、通过调整不同细胞之间的连接性等来训练,以便使损失函数最小化。在一个示例中,损失函数可以是在目标全景声系数和由麦克风阵列205捕获或以合成形式提供的全景声系数(即,输入训练信号)之间的误差。
[0160]
例如,lstm网络735c(基于损失函数)可以使用对输入训练信号的实际(例如,但未知)分布进行近似的分布函数。举例来说,当基于来自不同方向的输入训练信号来训练lstm网络735b时,分布函数可以类似于不同类型的分布,例如,laplacian(拉普拉斯)分布或super gaussian(超高斯)分布。在lstm的输出处,可以至少部分地基于将最大化函数应用于分布函数来生成目标全景声系数的估计。例如,最大化函数可以识别与分布函数的最大值相对应的参数。
[0161]
在一些示例中,输入训练信号可以由设备201的麦克风阵列205接收。可以基于目标时间窗口来对所接收的每个输入训练信号进行采样,使得用于设备201的麦克风n的输入音频信号可以被表示为其中,y
t
表示目标听觉源(例如,经变换的全景声系数的估计),α表示与目标听觉源的源相关联的方向常数,micn表示麦克风阵列205中的接收目标听觉源的麦克风,并且表示在麦克风n处接收的噪声伪影。在一些情况下,目标时间窗口可以跨越从开始时间tb到最终时间tf,例如,子帧或帧、或者用于平滑数据的窗口的长度。因此,在麦克风阵列205处接收的输入信号的时间段可以对应于时间t
–
tb到t tf。尽管在时间窗口的背景中进行描述,但是将理解的是,在麦克风阵列205处接收的输入信号的时间段可以另外或替代地对应于频域中的采样(例如,包含频谱信息的样本)。
[0162]
在一些情况下,在lstm 735c的训练阶段期间的操作可以是至少部分地基于与时间t tf–
1相对应的采样集合(例如,先前采样集合)。对应于时间t tf–
1的采样在递归神经网络735aa中可以被称为隐藏状态,并且可以根据来表示,其中m对应于神经网络的给定隐藏状态。也就是说,递归神经网络可以包含多个隐藏状态(例如,可以是深度堆叠神经网络的示例),并且每个隐藏状态可以由如上所述的一个或多个门控函数来控制。
[0163]
在一些示例中,损失函数可以根据来定义,其
中z表示在给定接收的输入信号和神经网络的隐藏状态的情况下的概率分布,其中m是记忆容量,因为存在m个隐藏状态,并且t
f-1表示先行时间。也就是说,lstm网络735a的操作可以涉及基于所识别的损失函数而在麦克风阵列205处接收的输入信号的采样与期望全景声系数的所学习的分布函数z匹配的概率。
[0164]
在与图2b的描述相关联的实施例中,到达方向(doa)嵌入器可以基于与如参考图2b所描述的方向或角度(仰角和/或方位角)相关联的方向性来确定用于与每个音频源相关联的每个麦克风的时间延迟。也就是说,可以向用于音频源的目标全景声系数分配方向性约束(例如,基于麦克风的布置),使得目标全景声系数的系数可以是方向性约束360b的函数。全景声系数可以是至少部分地基于所确定的与每个麦克风相关联的时间延迟来生成的。
[0165]
然后可以根据至少部分地基于方向性约束226的状态更新来处理全景声系数。每个状态更新可以反映参考图2b描述的技术。即,多个状态更新(例如,状态更新745a到状态更新745n)。每个状态更新745可以是隐藏状态的示例(例如,如上所述的lstm细胞)。即,每个状态更新745可以对输入(例如,全景声系数的采样、来自先前状态更新745的输出等)进行操作以产生输出。在一些情况下,每个状态更新745的操作可以至少部分地基于递归(例如,其可以基于来自细胞的输出来更新该细胞的状态)。在一些情况下,递归可以涉及训练(例如,优化)递归神经网络735a。
[0166]
在lstm网络的输出处,发射函数可以生成目标全景声系数226。将理解的是,在不偏离本公开内容的范围的情况下,可以包括任何实际数量的状态更新715。
[0167]
参考图8,示出了根据本公开内容的一些示例的执行基于约束来应用至少一个自适应网络的方法的流程图。
[0168]
在图8中,方法800的一个或多个操作是由一个或多个处理器执行的。在设备201中包括的一个或多个处理器可以实现与图2a-2g、3a-3b、4a-4f、5a-5d、6a-6d、7a-7b和9相关联地描述的技术。
[0169]
方法800包括如下操作:获得在不同时间段处的未经变换的全景声系数,其中,在不同时间段处的未经变换的全景声系数表示在不同时间段处的声场802。方法800还包括如下操作:基于约束来将至少一个自适应网络应用于在不同时间段处的未经变换的全景声系数,以输出在不同时间段处的经变换的全景声系数,其中,在不同时间段处的经变换的全景声系数表示基于约束而修改的、在不同时间段处的经修改的的声场804。
[0170]
参考图9,示出了根据本公开内容的一些示例的可操作为执行基于约束来应用至少一个自适应网络的设备的特定说明性示例的框图。
[0171]
参考图9,描绘了设备的特定说明性实现方式的框图,并且总体上将其指定为900。在各种实现方式中,设备900可以具有与在图9中所示的相比更多或更少的组件。在一种说明性实现方式中,设备900可以对应于图2a中的设备201。在一种说明性实现方式中,设备900可以执行参考图1、图2a-f、图3a-b、图4a-f、图5a-d、图6a-d、图7a-b和图8所描述的一个或多个操作。
[0172]
在一种特定实现方式中,设备900包括处理器906(例如,中央处理单元(cpu))。设备900可以包括一个或多个额外处理器910(例如,一个或多个dsp、gpu、cpu、或音频核)。一个或多个处理器910可以包括自适应网络225、渲染器230和控制器932、或其组合。在一个特
定方面中,图2a的一个或多个处理器208对应于处理器906、一个或多个处理器910、或其组合。在一个特定方面中,图2f的控制器25f或图2g的控制器25g对应于控制器932。
[0173]
设备900可以包括存储器952和编解码器934。存储器952可以包括全景声系数缓冲器215和指令956,指令956可由一个或多个额外处理器810(或处理器806)执行以实现参照图1、图2a-f、图3、图4a-h、图5a-d、图6a-b和图7所描述的一个或多个操作。在一个特定方面中,存储器952还可以包括其它缓冲器,例如缓冲器30i。在一个示例中,存储器952包括存储指令956的计算机可读存储设备。指令956在由一个或多个处理器(例如,处理器908、处理器906、或处理器910,作为说明性示例)执行时,使得一个或多个处理器进行以下操作:获得在不同时间段处的未经变换的全景声系数,其中,在不同时间段处的未经变换的全景声系数表示在不同时间段处的声场;以及基于约束来将至少一个自适应网络应用于在不同时间段处的未经变换的全景声系数,以生成在不同时间段处的经变换的全景声系数,其中,在不同时间段处的经变换的全景声系数表示基于约束而修改的在不同时间段处的经修改的声场。
[0174]
设备900可以包括经由接收机950而耦合到接收天线942的无线控制器940。另外或替代地,无线控制器940还可以经由发射机954耦合到发射天线943。
[0175]
设备900可以包括耦合到显示控制器926的显示器928。一个或多个扬声器940和一个或多个麦克风905可以耦合到编解码器934。在一个特定方面中,麦克风905可以如关于在本公开内容内描述的麦克风阵列205描述地来实现。编解码器934可以包括或耦合到数模转换器(dac)902和模数转换器(adc)904。在一种特定实现方式中,编解码器934可以从一个或多个麦克风905接收模拟信号,使用模数转换器904来将模拟信号转换为数字信号,以及将数字信号提供给一个或多个处理器910。处理器910(例如,音频编解码器、或语音和音乐编解码器)可以处理数字信号,并且数字信号可以由全景声系数缓冲器215、自适应网络225、渲染器230或其组合进一步处理。在一种特定实现方式中,自适应网络225可以被集成为编解码器934的一部分,并且编解码器934可以位于处理器910内。
[0176]
在相同或替代实现方式中,处理器910(例如,音频编码、或语音和音乐编解码器)可以将数字信号提供给编解码器934。编解码器934可以使用数模转换器902来将数字信号转换为模拟信号,并且可以将模拟信号提供给扬声器936。设备900可以包括输入设备930。在一个特定方面中,输入设备930包括被包括在图5a-5d和图6a-6d的相机中的图像传感器514。在一个特定方面中,编解码器934对应于在与图4a、4b、4f和图6a-6d相关联地描述的音频应用中描述的编码器和解码器。
[0177]
在一种特定实现方式中,设备900可以被包括在系统级封装或片上系统设备922中。在一种特定实现方式中,存储器952、处理器906、处理器910、显示控制器926、编解码器934和无线控制器940被包括在系统级封装或片上系统设备922中。在一种特定实现方式中,输入设备930和电源944耦合到系统级封装或片上系统设备922。此外,在一种特定实现方式中,如图9所示,显示器928、输入设备930、扬声器940、麦克风905、接收天线942、发射天线943和电源944在系统级封装或片上系统设备922外部。在一种特定实现方式中,显示器928、输入设备930、扬声器940、麦克风905、接收天线942、发射天线943和电源944中的每一者可以耦合到系统级封装或片上系统设备922的组件,诸如接口或无线控制器940。
[0178]
设备900可以包括便携式电子设备、汽车、车辆、计算设备、通信设备、物联网(iot)设备、虚拟现实(vr)设备、智能扬声器、音箱、移动通信设备、智能电话、蜂窝电话、膝上型计
算机、计算机、平板设备、个人数字助理、显示设备、电视机、游戏控制台、音乐播放器、无线电单元、数字视频播放器、数字视频光盘(dvd)播放器、调谐器、相机、导航设备、或其任何组合。在一个特定方面中,处理器906、处理器910或其组合被包括在集成电路中。
[0179]
结合所描述的实现方式,一种设备包括:用于存储在不同时间段处的未经变换的全景声系数的单元,其包括图2a-2e、3a-3b、4a-4f、7a-7c的全景声系数缓冲器215。该设备还包括图2a的一个或多个处理器208和图9的一个或多个处理器910,其具有用于获得在不同时间段处的未经变换的全景声系数的单元,其中,在不同时间段处的未经变换的全景声系数表示在不同时间段处的声场。图2a的一个或多个处理器208和图9的一个或多个处理器还包括用于基于约束来将至少一个自适应网络应用于在不同时间段处的未经变换的全景声系数以生成在不同时间段处的经变换的全景声系数的单元,其中,经变换的全景声系数在不同时间段处。
[0180]
本领域技术人员还将明白的是,结合本文所公开的实现方式来描述的各个说明性的逻辑框、配置、模块、电路和算法步骤可以被实现为电子硬件、由处理器执行的计算机软件、或这两者的组合。上文已经对各种说明性的组件、框、配置、模块、电路和步骤均围绕其功能进行了总体描述。这样的功能是实现为硬件还是处理器可执行指令,取决于特定的应用和对整个系统施加的设计约束。本领域技术人员可以针对每个特定应用,以变化的方式实现所描述的功能,这样的实现方式决策将不被解释为造成对本公开内容的范围的背离。
[0181]
结合本文公开的实现方式所描述的方法或者算法的步骤可以直接地体现在硬件中、由处理器执行的软件模块中、或者这两者的组合中。软件模块可以位于随机存取存储器(ram)、闪存、只读存储器(rom)、可编程只读存储器(prom)、可擦除可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom)、寄存器、硬盘、可移动盘、压缩光盘只读存储器(cd-rom)、或本领域中已知的任何其它形式的非临时性存储介质。示例性的存储介质耦合到处理器,使得处理器可以从该存储介质读取信息以及向该存储介质写入信息。替代地,存储器设备可以整合到处理器中。处理器和存储介质可以位于专用集成电路(asic)中。该asic可以位于计算设备或者用户终端中。替代地,处理器和存储介质可以作为分立组件位于计算设备或者用户终端中。
[0182]
下文在第一组相关联的条款中描述了本公开内容的特定方面:
[0183]
根据条款1b,一种方法包括:存储在不同时间段处的未经变换的全景声系数;获得在所述不同时间段处的所述未经变换的全景声系数,其中,在所述不同时间段处的所述未经变换的全景声系数表示在所述不同时间段处的声场;以及基于约束来将一个自适应网络应用于在所述不同时间段处的所述未经变换的全景声系数,以生成在所述不同时间段处的经变换的全景声系数,其中,在所述不同时间段处的所述经变换的全景声系数表示基于所述约束而修改的在所述不同时间段处的经修改的声场。
[0184]
条款2b包括根据条款1b所述的方法,其中,所述约束包括保留在所述不同时间段处的所述声场中的一个或多个音频源的空间方向,并且在所述不同时间段处的所述经变换的全景声系数表示在所述不同时间段处的经修改的声场,在所述不同时间段处的所述经修改的声场包括具有所保留的空间方向的一个或多个音频源。
[0185]
条款3b包括根据条款2b所述的方法,还包括:压缩所述经变换的全景声系数,并且所述方法还包括:在发送链路上发送经压缩的经变换全景声系数。
[0186]
条款4b包括根据条款2b所述的方法,还包括:接收经压缩的经变换全景声系数,并且所述方法还包括:解压缩所述经变换的全景声系数。
[0187]
条款5b包括根据条款2b所述的方法,还包括:转换所述未经变换的全景声系数,并且所述约束包括:保留在所述声场中来自车辆的扬声器区域的一个或多个音频源的空间方向。
[0188]
条款6b包括根据条款2b所述的方法,还包括:额外的自适应网络、以及被输入到所述额外的自适应网络中的额外约束,所述额外的自适应网络被配置为输出额外的经变换的全景声系数,其中,所述额外约束包括保留与所述约束不同的空间方向。
[0189]
条款7b包括根据条款6b所述的方法,还包括:将所述额外的经变换的全景声系数和所述经变换的全景声系数线性地相加。
[0190]
条款8b包括根据条款7b所述的方法,还包括:在第一空间方向上渲染所述经变换的全景声系数,以及在不同的空间方向上渲染所述额外的经变换的全景声系数。
[0191]
条款9b包括根据条款8b所述的方法,其中,在所述第一空间方向上的所述经变换的全景声系数被渲染以在隐私区域中产生声音。
[0192]
条款10b包括根据条款9b所述的方法,其中,在所述不同的空间方向上的所述额外的经变换的全景声系数表示掩码信号,并且被渲染以在所述隐私区域外部产生声音。
[0193]
条款11b包括根据条款9b所述的方法,其中,在所述隐私区域中的所述声音比在所述隐私区域外部产生的声音要大声。
[0194]
条款12b包括根据条款9b所述的方法,其中,隐私区域模式是响应于传入或传出的电话呼叫而被激活的。
[0195]
条款13b包括根据条款1b所述的方法,其中,所述约束包括通过缩放因子来缩放在所述不同时间段处的所述声场,其中,所述缩放因子的应用将在由在所述不同时间段处的所述未经变换的全景声系数表示的所述声场中的至少第一音频源放大,其中,在所述不同时间段处的所述经变换的全景声系数表示在所述不同时间段处的经修改的声场,在所述不同时间段处的所述经修改的声场包括被放大的所述至少第一音频源。
[0196]
条款14b包括根据条款1b所述的方法,其中,所述约束包括通过缩放因子来缩放在所述不同时间段处的所述声场,其中,所述缩放因子的应用将在由在所述不同时间段处的所述未经变换的全景声系数表示的所述声场中的至少第一音频源衰减,并且在所述不同时间段处的所述经变换的全景声系数表示在所述不同时间段处的经修改的声场,在所述不同时间段处的所述经修改的声场包括被衰减的所述至少第一音频源。
[0197]
条款15b包括根据条款1b所述的方法,其中,所述约束包括将通过非理想麦克风阵列的麦克风位置捕获的在所述不同时间段处的所述未经变换的全景声系数变换为在所述不同时间段处的所述经变换的全景声系数,如同所述经变换的全景声系数已经通过理想麦克风阵列的麦克风位置捕获一样,在所述不同时间段处的所述经变换的全景声系数表示在所述不同时间段处的经修改的声场。
[0198]
条款16b包括根据条款15b所述的方法,其中,所述理想麦克风阵列包括4个麦克风。
[0199]
条款17b包括根据条款15b所述的方法,其中,所述理想麦克风阵列包括32个麦克风。
[0200]
条款18b包括根据条款1b所述的方法,其中,所述约束包括经变换的全景声系数的目标阶数。
[0201]
条款19b包括根据条款1b所述的方法,其中,所述约束包括用于形状因子的麦克风位置。
[0202]
条款20b包括根据条款19b所述的方法,其中,所述形状因子为手持机。
[0203]
条款21b包括根据条款19b所述的方法,其中,所述形状因子为眼镜。
[0204]
条款22b包括根据条款19b所述的方法,其中,所述形状因子是vr耳机或ar耳机。
[0205]
条款23b包括根据条款19b所述的方法,其中,所述形状因子为音频耳机。
[0206]
条款24b包括根据条款1b所述的方法,其中,所述经变换的全景声系数由第一音频应用使用,所述第一音频应用包括由所述一个或多个处理器执行的指令。
[0207]
条款25b包括根据条款24b所述的方法,其中,所述第一音频应用包括压缩在所述不同时间段处的所述经变换的全景声系数并且将其存储在所述存储器中。
[0208]
条款26b包括根据条款25b所述的方法,其中,经压缩的在所述不同时间段处的经变换的全景声系数是使用所述设备和远程设备之间的无线链路在空中发送的。
[0209]
条款27b包括根据条款25b所述的方法,其中,所述第一音频应用还包括对所述经压缩的在所述不同时间段处的经变换的全景声系数进行解压缩。
[0210]
条款28b包括根据条款24b所述的方法,其中,所述第一音频应用包括渲染在所述不同时间段处的所述经变换的全景声系数。
[0211]
条款29b包括根据条款28b所述的方法,其中,所述第一音频应用还包括:执行关键字检测以及基于所述关键字检测和所述约束来控制设备。
[0212]
条款30b包括根据条款28b所述的方法,其中,所述第一音频应用还包括:执行方向检测以及基于所述方向检测和所述约束来控制设备。
[0213]
条款31b包括根据条款28b所述的方法,还包括:通过扩音器来播放由渲染器渲染的在所述不同时间段处的所述经变换的全景声系数。
[0214]
条款32b包括根据条款1b所述的方法,还包括:将所述未经变换的全景声系数存储在缓冲器中。
[0215]
条款33b包括根据条款32b所述的方法,还包括:利用麦克风阵列来捕获一个或多个音频源,所述一个或多个音频源是由所述全景声系数缓冲器中的所述未经变换的全景声系数来表示的。
[0216]
条款34b包括根据条款32b所述的方法,其中,所述未经变换的全景声系数是由内容创建者在发起设备的操作之前生成的。
[0217]
条款35b包括根据条款1b所述的方法,其中,经变换的全景声系数被存储在存储器中,并且所述经变换的全景声系数是基于所述约束来解码的。
[0218]
条款36b包括根据条款1b所述的方法,其中,所述方法在被包括在车辆中的一个或多个处理器中操作。
[0219]
条款37b包括根据条款1b所述的方法,其中,所述方法在被包括在xr耳机、vr耳机、音频耳机或xr眼镜中的一个或多个处理器中操作。
[0220]
条款38b包括根据条款1b所述的方法,还包括:将非理想麦克风阵列的麦克风信号输出转换为所述未经变换的全景声系数。
[0221]
条款39b包括根据条款1b所述的方法,其中,所述未经变换的全景声系数表示具有包括偏置误差的空间方向的音频源。
[0222]
条款40b包括根据条款39b所述的方法,其中,所述约束校正所述偏置误差,并且由所述自适应网络输出的所述经变换的全景声系数表示不具有所述偏置误差的所述音频源。
[0223]
根据条款1c,一种装置包括:用于存储在不同时间段处的未经变换的全景声系数的单元;用于获得在所述不同时间段处的所述未经变换的全景声系数的单元,其中,在所述不同时间段处的所述未经变换的全景声系数表示在所述不同时间段处的声场;以及用于基于约束来将一个自适应网络应用于在所述不同时间段处的所述未经变换的全景声系数,以生成在所述不同时间段处的经变换的全景声系数的单元,其中,在所述不同时间段处的所述经变换的全景声系数表示基于所述约束而修改的在所述不同时间段处的经修改的声场。
[0224]
条款2c包括根据条款1c所述的装置,其中,所述约束包括用于保留在所述不同时间段处的所述声场中的一个或多个音频源的空间方向的单元,并且在所述不同时间段处的所述经变换的全景声系数表示在所述不同时间段处的经修改的声场,在所述不同时间段处的所述经修改的声场包括具有所保留的空间方向的一个或多个音频源。
[0225]
条款3c包括根据条款2c所述的装置,还包括:用于压缩所述经变换的全景声系数的单元,并且所述装置还包括:用于在发送链路上发送经压缩的经变换全景声系数的单元。
[0226]
条款4c包括根据条款2c所述的装置,还包括:用于接收经压缩的经变换全景声系数的单元,并且所述装置还包括:用于解压缩所述经变换的全景声系数的单元。
[0227]
条款5c包括根据条款2c所述的装置,还包括:用于转换所述未经变换的全景声系数的单元,并且所述约束包括:保留在所述声场中来自车辆的扬声器区域的一个或多个音频源的空间方向。
[0228]
条款6c包括根据条款2c所述的装置,还包括:额外的自适应网络、以及被输入到所述额外的自适应网络中的额外约束,所述额外的自适应网络被配置为输出额外的经变换的全景声系数,其中,所述额外约束包括保留与所述约束不同的空间方向。
[0229]
条款7c包括根据条款6c所述的装置,还包括:用于将所述额外的经变换的全景声系数和所述经变换的全景声系数相加的单元。
[0230]
条款8c包括根据条款7c所述的装置,还包括:用于在第一空间方向上渲染所述经变换的全景声系数的单元,以及用于在不同的空间方向上渲染所述额外的经变换的全景声系数的单元。
[0231]
条款9c包括根据条款8c所述的装置,其中,在所述第一空间方向上的所述经变换的全景声系数被渲染以在隐私区域中产生声音。
[0232]
条款10c包括根据条款9c所述的装置,其中,所述额外的经变换的全景声系数表示掩码信号,在所述不同的空间方向上被渲染以在所述隐私区域外部产生声音。
[0233]
条款11c包括根据条款9c所述的装置,其中,在所述隐私区域中的所述声音比在所述隐私区域外部产生的声音要大声。
[0234]
条款12c包括根据条款9c所述的装置,其中,隐私区域模式是响应于传入或传出的电话呼叫而被激活的。
[0235]
条款13c包括根据条款1c所述的装置,其中,所述约束包括用于通过缩放因子来缩放在所述不同时间段处的所述声场的单元,其中,所述缩放因子的应用将在由在所述不同
时间段处的所述未经变换的全景声系数表示的所述声场中的至少第一音频源放大,其中,在所述不同时间段处的所述经变换的全景声系数表示在所述不同时间段处的经修改的声场,在所述不同时间段处的所述经修改的声场包括被放大的所述至少第一音频源。
[0236]
条款14c包括根据条款1c所述的装置,其中,所述约束包括用于通过缩放因子来缩放在所述不同时间段处的所述声场的单元,其中,所述缩放因子的应用将在由在所述不同时间段处的所述未经变换的全景声系数表示的所述声场中的至少第一音频源衰减,并且在所述不同时间段处的所述经变换的全景声系数表示在所述不同时间段处的经修改的声场,在所述不同时间段处的所述经修改的声场包括被衰减的所述至少第一音频源。
[0237]
条款15c包括根据条款1c所述的装置,其中,所述约束包括用于将通过非理想麦克风阵列的麦克风位置捕获的在所述不同时间段处的所述未经变换的全景声系数变换为在所述不同时间段处的所述经变换的全景声系数,如同所述经变换的全景声系数已经通过理想麦克风阵列的麦克风位置捕获一样的单元,在所述不同时间段处的所述经变换的全景声系数表示在所述不同时间段处的经修改的声场。
[0238]
条款16c包括根据条款15c所述的装置,其中,所述理想麦克风阵列包括4个麦克风。
[0239]
条款17c包括根据条款15c所述的装置,其中,所述理想麦克风阵列包括32个麦克风。
[0240]
条款18c包括根据条款1c所述的装置,其中,所述约束包括经变换的全景声系数的目标阶数。
[0241]
条款19c包括根据条款1c所述的装置,其中,所述约束包括用于形状因子的麦克风位置。
[0242]
条款20c包括根据条款19c所述的装置,其中,所述形状因子为手持机。
[0243]
条款21c包括根据条款19c所述的装置,其中,所述形状因子为眼镜。
[0244]
条款22c包括根据条款19c所述的装置,其中,所述形状因子是vr耳机。
[0245]
条款23c包括根据条款19c所述的装置,其中,所述形状因子为ar耳机。
[0246]
条款24c包括根据条款1c所述的装置,其中,所述经变换的全景声系数由第一音频应用使用,所述第一音频应用包括由所述一个或多个处理器执行的指令。
[0247]
条款25c包括根据条款24c所述的装置,其中,所述第一音频应用包括用于压缩在所述不同时间段处的所述经变换的全景声系数并且将其存储在所述存储器中的单元。
[0248]
条款26c包括根据条款25c所述的单元,其中,经压缩的在所述不同时间段处的经变换的全景声系数是使用所述设备和远程设备之间的无线链路在空中发送的。
[0249]
条款27c包括根据条款25c所述的装置,其中,所述第一音频应用还包括用于对所述经压缩的在所述不同时间段处的经变换的全景声系数进行解压缩的单元。
[0250]
条款28c包括根据条款24c所述的装置,其中,所述第一音频应用包括用于渲染在所述不同时间段处的所述经变换的全景声系数的单元。
[0251]
条款29c包括根据条款28c所述的装置,其中,所述第一音频应用还包括:执行关键字检测以及基于所述关键字检测和所述约束来控制设备。
[0252]
条款30c包括根据条款28c所述的装置,其中,所述第一音频应用还包括:执行方向检测以及基于所述方向检测和所述约束来控制设备。
[0253]
条款31c包括根据条款28c所述的装置,还包括:通过扩音器来播放由渲染器渲染的在所述不同时间段处的所述经变换的全景声系数。
[0254]
条款32c包括根据条款1c所述的装置,还包括:将所述未经变换的全景声系数存储在缓冲器中。
[0255]
条款33c包括根据条款32c所述的装置,还包括:利用麦克风阵列来捕获一个或多个音频源,所述一个或多个音频源是由所述全景声系数缓冲器中的所述未经变换的全景声系数来表示的。
[0256]
条款34c包括根据条款32c所述的装置,其中,所述未经变换的全景声系数是由内容创建者在发起设备的操作之前生成的。
[0257]
条款35c包括根据条款1c所述的装置,其中,经变换的全景声系数被存储在存储器中,并且所述经变换的全景声系数是基于所述约束来解码的。
[0258]
条款36c包括根据条款1c所述的装置,其中,所述方法在被包括在车辆中的一个或多个处理器中操作。
[0259]
条款37c包括根据条款1c所述的方法,其中,所述方法在被包括在xr耳机、vr耳机或xr眼镜中的一个或多个处理器中操作。
[0260]
条款38c包括根据条款1c所述的装置,还包括:将非理想麦克风阵列的麦克风信号输出转换为所述未经变换的全景声系数。
[0261]
条款39c包括根据条款1c所述的装置,其中,所述未经变换的全景声系数表示具有包括偏置误差的空间方向的音频源。
[0262]
条款40c包括根据条款39c所述的装置,其中,所述约束校正所述偏置误差,并且由所述自适应网络输出的所述经变换的全景声系数表示不具有所述偏置误差的所述音频源。
[0263]
根据条款1d,一种具有存储在其上的指令的非暂时性计算机可读存储介质,所述指令在被执行时使得一个或多个处理器进行以下操作:存储在不同时间段处的未经变换的全景声系数;获得在所述不同时间段处的所述未经变换的全景声系数,其中,在所述不同时间段处的所述未经变换的全景声系数表示在所述不同时间段处的声场;以及基于约束来将一个自适应网络应用于在所述不同时间段处的所述未经变换的全景声系数,以生成在所述不同时间段处的经变换的全景声系数,其中,在所述不同时间段处的所述经变换的全景声系数表示基于所述约束而修改的在所述不同时间段处的经修改的声场。
[0264]
条款1d包括根据条款2d所述的非暂时性计算机可读存储介质,包括:使得所述一个或多个处理器执行在本公开内容的前述条款2b-40b中所述的步骤中的任何步骤。
[0265]
提供对所公开的方面的先前描述,以使本领域技术人员能够实现或使用所公开的方面。对于本领域技术人员而言,对这些方面的各种修改将是容易显而易见的,以及在不背离本公开内容的范围的情况下,本文中定义的原理可以应用于其它方面。因此,本公开内容不旨在限于本文中所示出的方面,而是要被赋予与通过下文的权利要求限定的原理和新颖特征相一致的可能的最广范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。