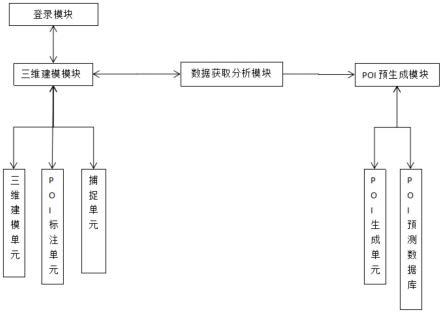
1.本发明属于不连续函数回归技术领域,涉及一种基于局部离群因子与符号回归的自动断点检测方法。
背景技术:
2.非参数回归是统计学的重要分支,在社会、经济、医疗等诸多领域中有着重要地位,关于非参数回归函数的统计推断问题也越来越被人们重视。但是在很多实际应用中,不连续的回归函数,即回归函数带断点的情况更适合去描述相关现象。如国六标准颁布前后的大气污染序列建模、奖助学金模式下的学生成绩建模、金融危机前后的股票市场价格指标序列建模等。这些问题都存在一个共性,即某一变量达到特定数值后,回归模型会突然发生变化。现有研究中,通常使用断点回归设计(regression discontinuity design)、门槛回归(thresholdregression)和时间序列分段算法(time series breakout detection)对不连续回归问题进行建模。
3.邹红等人发表的“基于断点回归设计的经验证据”基于断点回归设计,利用退休制度对城镇男性户主退休决策的外生冲击,检验了我国是否存在退休消费骤降现象。结果表明退休显著降低了城镇家庭非耐用消费支出的9%、与工作相关支出的25.1%、文化娱乐支出的18.6%和在家食物支出的7.4%。
4.在该方法中,断点的识别和预测较为困难,通常需要丰富的领域知识以及人们的直觉,人为假设断点的位置和数量,因此会受到人类认知偏见的限制。并且在确定断点位置后需要使用传统回归方法来估计断点位置两边的模型,而传统回归方法则需要事先假定模型结构,这样就有可能过滤掉更适合的潜在模型。
5.赵春燕发表的“人口老龄化对区域产业结构升级的影响——基于面板门槛回归模型的研究”采用面板回归门槛模型,通过利用1998-2015年我国30个省份的面板数据,证实老龄化对产业结构升级影响的门槛效应。实证结果显示:老龄化产业对结构升级影响存在显著门槛效应,当城镇化水平大于门槛值时,老龄化促进产业结构升级;反之,老龄化阻碍产业结构升级。
6.此研究相较于断点回归设计优势在于可以自动搜寻门限值,将回归模型区分为多个区间,每个区间的回归方程表达不同。该方法局限在于回归模型是一个固定的表达式,通过最小化残差平方和进行参数估计,但是不同的实际问题服从不同的数据分布,这种做法找到的模型可能拟合度不高且缺乏一定的解释性,会遗漏一定的信息。
7.熊智等人发表的“城市轨道交通客流量时间序列分段拟合方法”利用曲线拟合方法挖掘地铁客流量时间序列趋势性特征,通过整体拟合、人工分段拟合和自动分段拟合,对北京市36个地铁站单日内客流量进行时间序列建模优化。研究表明:分段拟合利用局部函数建模客流量变化的动力学过程,相较整体拟合能更好地逼近实际。
8.该研究涉及的时间序列自动分段拟合方法是通过人工确定分段个数,然后通过遍历分段点的取值组合,计算每种组合下的mse之和,取mse之和最小的最优分段点。该方法的
优势在于对每个可能的分段数据集都进行了拟合,分段结果较为精准。但局限在于需要人工确认分段个数,并且需要遍历每一种取值组合,时间复杂度太高,计算速度较慢。
9.中国专利cn201710881294.7公开了一种基于断点回归的公交专用道政策评价方法,采用的技术方案是利用实测数据对两种不同类型机动车的速度进行断点回归,结合图像分析间断点前后结果变量的突变情况,定量评估专用道对公交车和社会车辆速度的影响,辅助城市交通管理部门制定和优化公交专用车道政策。
10.该专利涉及的断点回归方法,首先确定断点的位置,即公交专用道开放的时间点,然后使用传统回归方法来估计断点位置两边的模型,而传统回归方法则需要事先假定模型结构,这样就有可能过滤掉更适合的潜在模型。
11.精确地识别断点以及为分段数据建立合理模型,是解决不连续回归问题的关键,现有方法还存在的以下问题:
12.(1)无法确定断点个数和断点位置。现有的方法通常需要丰富的领域知识以及人们的直觉,人为假设断点的位置和数量,因此会受到人类认知偏见的限制。
13.(2)无法对复杂数据进行拟合。现有方法在确定断点个数和断点位置后,通过事先假定的模型结构和参数估计确定最终的回归结果,模型结构大多是线性回归模型,难以对非线性结构进行拟合,这种做法有可能会过滤掉更适合的潜在模型。
技术实现要素:
14.本发明针对传统不连续回归问题中无法确定断点个数和断点位置、无法对复杂数据进行拟合等问题,提出了一种基于局部离群因子与符号回归的自动断点检测方法,首先利用局部离群因子方法确定数据集中的候选断点个数位置,然后根据候选断点生成候选断点组,最后基于符号回归算法对候选断点组进行拟合,选择拟合度最高的断点作为输出结果。
15.为了达到上述目的,本发明的技术方案如下:
16.一种基于局部离群因子与符号回归的自动断点检测方法,包括如下步骤:
17.步骤000:对于给定数据集,设定基本参数生成初始断点与对应数据集;
18.步骤010:设定基本参数;对于给定的数据集d,设置三个基本参数:带宽 bandwidth、离群比例outlier和阈值threshold;计算数据集长度t,设定计数器i初始值为0。
19.步骤020:生成初始断点与对应数据集;令初始断点bpi=x[n* bandwidth/2 i],对应初始数据集di=d[i:n*(bandwidth/2 outlier) i]。
[0020]
步骤100:根据生成的数据集与lof算法返回候选断点;
[0021]
步骤110:对lof算法输出结果进行转换;将数据集di作为局部离群因子算法lof的输入,计算lof算法输出结果res中,后n*outlier中值为-1的个数与 n*outlier的比值,记为score,即score=sum(res[-n*outlier:]==-1)/n* outlier。
[0022]
步骤120:选择候选断点;对score进行判断,若score>=threshlod,判断断点xi为候选断点。令i=i 1。
[0023]
步骤200:根据候选断点生成符号回归数据集;
[0024]
步骤210:生成候选断点组;计算候选断点的数量num_bp,将候选断点数量按照从1
至num_bp进行排列组合,生成候选断点组bp_candidate。
[0025]
步骤220:划分原始数据集;根据每一个候选断点组对原始数据集进行切分,生成对应的切分数据集d
kj
,其中,{k∈r|1≤k≤len(bp_candidate)},{j∈ r|0≤j≤num_bp}
[0026]
步骤300:根据符号回归输出结果,返回拟合优度最小的候选断点与其对应函数;
[0027]
步骤310:拟合切分数据集;调用符号回归函数sr,分别对切分数据集d
kj
中每一段切分数据进行拟合,拟合优度和拟合方程分别记为fit
kj
,function
kj
。
[0028]
步骤320:选择最优断点及其对应函数;选择切分数据集d
kj
平均拟合优度最小的值对应的索引,记为index,即则最优断点bp与其对应拟合函数function为指标index对应的bp_candidate与 function
kj
,即bp=bp_candidate[index],function=function
kj
[index]。
[0029]
本发明的有益效果:本算法具有自动识别断点个数和位置、可拟合复杂分布数据、拟合度高、计算速度快等优势。与现有技术方案相比,本发明的优点具有如下优点:
[0030]
1.能自动识别断点个数和位置。通过构造候选断点与切分数据集,利用lof 算法的异常值检测功能,可全面精准地识别数据集中存在的断点,
[0031]
2.可拟合复杂分布数据。基于符号回归算法进行拟合,实现数据分布假设、解释性强、拟合度高的数据建模。
[0032]
3.计算速度快。基于lof算法的断点检测过程,只需将数据集的每个点遍历一次,无冗余计算过程。
附图说明
[0033]
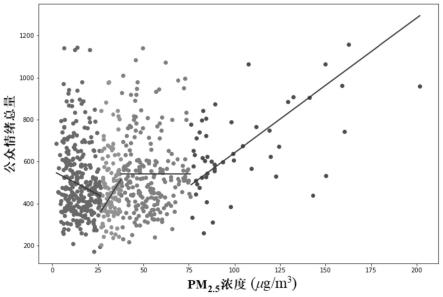
图1为网络公众情绪与pm2.5浓度间的关系模型拟合图。
具体实施方式
[0034]
以下结合技术方案和附图,详细说明本发明的具体实施方式。
[0035]
一种基于局部离群因子与符号回归的自动断点检测方法,步骤如下:
[0036]
(1)对于给定数据集,设定基本参数,生成初始断点与对应数据集,步骤如下:
[0037]
对于给定的二维数据集d={(x0,y0),(x1,y1),...,(xn,yn)},其中x为自变量, y为因变量。设置三个基本参数:带宽bandwidth(0<bandwidth<1)、离群比例outlier(0<outlier<bandwidth/2)和阈值threshold(0≤threshold≤1);计算数据集长度n,设定计数器i初始值为0。
[0038]
令初始断点bpi=x[n*bandwidth/2 i],对应初始数据集di=d[i:n* (bandwidth/2 outlier) i]。
[0039]
在本发明中,假设数据集d={(x0,y0),(x1,y1),...,(x
99
,y
99
)},bandwidth= 0.2,outlier=0.05,threshold=0.8,则得到初始断点bp0=x[10]=x9,得到初始数据集d0=d[0:15]={(x0,y0),(x1,y1),...,(x
14
,y
14
)}。
[0040]
(2)根据生成的数据集与lof算法返回候选断点,步骤如下:
[0041]
将数据集di作为局部离群因子算法(local outlier factor,lof)的输入, lof算
法是一种基于密度的方法,该方法将一个表征数据离群程度的局部离群因子赋予每个数据对象,根据局部离群因子的数值来确定离群点,lof算法能有效避免数据密度分布不同对检测带来的影响。lof的输出将正常数据点标记为1,离群点标记为-1。
[0042]
计算lof算法输出结果res中,后n*outlier中值为-1的个数与n*outlier的比值,记为score,即score=sum(res[-n*outlier:]==-1)/n*outlier。对score 进行判断,若score≥threshlod,判断断点bpi为候选断点。以此类推,令i=i 1,直至i=n-n*(bandwidth/2 outlier),计算完所有断点。
[0043]
假设将技术方案(1)中bp0与d0作为lof算法的输入,得到输出结果 res=[1,1,1-1,,......,-1,-1,-1,1,-1],则score=4/5=0.8,score≥ threshold,bp0记为候选断点。以此类推,令i=i 1,直至i=85,计算完最后一个断点bp
85
=x[95]=x
94
。假设生成的候选断点为bp=[bp0,bp
17
,bp
51
]
[0044]
(3)根据候选断点生成符号回归数据集,步骤如下:
[0045]
计算候选断点的数量num_bp,将候选断点数量按照从1至num_bp进行排列组合,生成候选断点组bp_candidate。根据每一个候选断点组对原始数据集进行切分,生成对应的切分数据集d
kj
,其中,{k∈r|1≤k≤len(bp_candidate)},{j∈r|0≤j≤num_bp},其中,k为排列组合后,候选断点组中每个候选断点下标,j为数据集被候选断点切分后,每个切分数据集的下标;
[0046]
假设技术方案(2)中生成的bp={bp0,bp
17
,bp
51
}为候选断点,则 num_bp=3,候选断点组bp_candidate与其对应切分数据集d
kj
如下表1所示
[0047]
表1候选断点与切分数据集对照表
[0048]
[0049][0050]
(4)根据符号回归输出结果,返回拟合优度最小的候选断点与其对应函数,步骤如下:
[0051]
调用符号回归算法(symbolic regression,sr),基于数据驱动的符号回归作为一种函数发现方法,能够自动描述输入变量和输出变量之间的关系,并且能够以数学函数的形式表示出来。利用sr算法分别对切分数据集d
kj
中每一段切分数据进行拟合,拟合优度和拟合方程分别记为fit
kj
,function
kj
。
[0052]
选择切分数据集d
kj
平均拟合优度最小的值对应的索引,记为index,即则最优断点bp与其对应拟合函数function 为指标index对应的bp_candidate与function
kj
,即bp=bp_candidate[index], function=function
kj
[index]。
[0053]
对技术方案(3)中生成的切分数据集d
kj
进行拟合,假设拟合结果如下表2 所示
[0054]
表2拟合结果
[0055]
[0056][0057]
则最优断点 bp=bp_candidate[6]=[bp
17
,bp
51
],对应拟合函数 function=function
kj
[6]=[y=x 0.76,y=x2 x 1,y=4.32]。
[0058]
实施例
[0059]
以北京市pm2.5污染与其网络公众关注度间的关系构建为例,对网络公众情绪与pm2.5浓度间的关系模型和阈值效应进行研究。
[0060]
第一步:构建数据集d
[0061]
采集北京2019年6月1日至2021年五月三十一日的pm2.5日均数据,数据来源为中国环境监测总站,采用线性插值方法对原始数据中的缺失值进行预处理,共731条数据,记为xn;采集北京市2019年6月1日至2021年五月三十一日的微博情绪数据,数据来源为新浪微博官方接口,以“pm2.5”、“雾霾”等6个关键词检索相关微博数据,对其情绪字段进行求和计数,共计731条数据,记为yn。
[0062]
对数据xn,yn按照日期进行匹配后,为了建模结果更加准确,需要去除离群点,方法如下:构造构造yn的四分位距iqr=q3-q1,即第一个四分位数q1和第三个四分位数q3之间的间距,然后位于q3 1.5*iqr或q1-1.5*iqr之外的数据被视为离群点。删除离群点后得到二维数据集 d={(x0,y0),(x1,y1),...,(x
682
,y
682
)}= {(2.29,685),(3.29,455),...,(201.66,960)},数据集长度n=683,设置基本参数 bandwidth=0.1,outlier=0.022,threshold=0.43,则得到初始断点 bp0=x[34]=x
33
,得到初始数据集 d0=d[0:49]={(x0,y0),(x1,y1),...,(x
48
,y
48
)}。
[0063]
第二步:根据生成的数据集与lof算法返回候选断点
[0064]
将bp0与d0作为lof算法的输入,得到输出结果res=[1,1,1,1,......,-1,-1,1,1,
1],则score=2/15=0.133,score<threshold, bp0记不是候选断点。以此类推,令i=i 1,直至i=634,计算完最后一个断点bp
634
=x[668]=x
667
。生成的候选断点为bp=[bp
271
,bp
330
,bp
620
]= [26.54,37.79,76.29]
[0065]
第三步:根据候选断点生成符号回归数据集
[0066]
假设第二步中生成的bp=[26.54,37.79,76.29]为候选断点,则num_bp=3,候选断点组bp_candidate与其对应切分数据集d
kj
如下表3所示
[0067]
表3候选断点与切分数据集对照表
[0068][0069][0070]
第四步:据符号回归输出结果,返回拟合优度最小的候选断点与其对应函数:
[0071]
利用sr算法分别对切分数据集d
kj
中每一段切分数据进行拟合,拟合优度和拟合方程分别记为fit
kj
,function
kj
,选择的拟合优度为mae,拟合结果如下表4所示:
[0072]
表4拟合结果
[0073][0074]
则最优断点 bp=bp_candidate[7]=[26.54,37.79,76.29],对应拟合函数function=function
kj
[7]=[y=556.32-4.53*x,y=13.63*x,y=540.17,y=6.41*x],拟合图如图1所示。
[0075]
图1中,散点表示的是北京市2019年6月1日至2021年5月31日不同pm2.5 日均值浓度水平对应的日均公众情绪总量,整体上来说,多数点位于pm2.5浓度低于75μg/m3的部分,即图1的左半部分,少部分点位于pm2.5浓度高于75 μg/m3的部分,仅凭借简单的散点图及应用传统分析方法无法识别其中是否存在断点。因此,传统方法研究二者间关系通常是基于既定模型形式的回归分析,例如利用线性回归模型对所有数据进行拟合,并根据回归系数对二者间关系进行分析。然而,这种分析方法在拟合数据量及波动水平均较大的日均值数据时,拟合效果往往不够理想,且无法对该回归问题是否存在断点的情况进行判断,研究结果可能存在因为模型选择带来的偏差。
[0076]
因此,本研究提出的一种基于局部离群因子与符号回归的自动断点检测方法,我们在上述北京市数据集中自动检测出三个pm2.5浓度断点,分别是26.54 μg/m3,37.79μg/m3,76.29μg/m3,对应四种变动趋势(模型形式),即下降(y=556.323-4.535*x)-上升(y=
13.638*x)-平稳(y=540.172)
ꢀ‑
上升趋势(y=6.419*x)。pm2.5浓度在0~26.54μg/m3时,空气质量相对较好,公众情绪数量并不会随着pm2.5的上升而增加,反而呈现下降趋势;当pm2.5 浓度由26.54上升至37.79时,pm2.5污染等级由优转为良,公众情绪数量也开始随之增加;pm2.5浓度在37.79-76.29时,pm2.5等级为良,此时公众情绪数量也无波动,呈平稳趋势;当pm2.5浓度大于76.29时,pm2.5等级为轻度污染,此时公众情绪数量随pm2.5浓度升高而增加。
[0077]
对北京市公众情绪表达数据的分析结果表明,现阶段,北京公众对于pm2.5 浓度的情绪表达敏感性存在波动特征,当pm2.5浓度较低且在某一等级范围内波动时,网络公众情绪并不会受到较大影响;当pm2.5浓度波动较大造成pm2.5 污染等级提高,网络公众情绪会随之提高,尤其当公众情绪渡过平台期以后, pm2.5污染等级高于轻度污染时,公众情绪总量会随着pm2.5浓度的升高而急剧攀升,进而导致爆发环境群体性事件的风险提高,甚至在一些有明显负面倾向性情绪的煽动下演变成由线上到线下的群体性事件。
[0078]
综上,在分析北京公众对pm2.5污染的情绪表达情况时,有效识别pm2.5 浓度的断点对于更加科学地制定北京市的污染物浓度控制目标有着重要意义,也是将公众意见和态度纳入污染治理过程的有效尝试。通过对pm2.5浓度进行断点识别,可以定量化的将不同污染水平下公众情绪随pm2.5浓度的变化过程描述出来,进而为pm2.5污染治理相关政策措施和控制目标的制定以及更好地把握公众对于pm2.5污染的态度、更精准化的网络舆情治理提供决策依据。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。