1.本发明属于智能停车控制领域,具体来说是一种车辆进入无接触式智能控制方法。
背景技术:
2.伴随着国家经济快速发展和人民生活水平的提高,汽车作为方便快捷的交通工具越来越普及到市民的日常生活中,小区、商场等人流量大的区域中需要停放的车辆众多,因此地上停车场、地下车库成为必备的硬件设施。随着人工智能技术的发展,目前公共场车场、车库以及一些机关企事业单位车辆进出通过闸机和车牌识别系统进行控制管理,收费停车场均采用了车牌识别 自动计算 自助缴费 自动放行的无接触式停车管理系统,极大地提高了停车管理效率并降低了管理运营成本。
3.现有的车库停车管理设备并不能自动识别进入人员是否符合佩戴口罩的要求,还不能做到无接触式的人员检测,只能依靠车库管理员进行检查并控制是否放行,这不仅十分费时费力,且由于并非为非接触式管理,因此存在不安全的问题。
4.由于车牌是采用了固定尺寸、颜色,相同的位数和字体,自动识别相对容易。传统车牌识别采用opencv进行车牌区域提取后,采用轮廓提取的方式提取字符,然后将提取的字符进行分割,将分割的字符采用svm或者模板匹配的方式进行字符分类识别。但,这种识别方式还有一定缺陷,主要是在分割字符的时候比较容易分割到两个字符,并且受到外界环境的影响比较严重,识别效果不很理想,并且由于字符提取的方式依赖于阈值化的参数调节以及字符轮廓的参数设置,参数调节起来会比较麻烦。而相对于采用了统一标准的车牌识别,由于口罩的样式、规格、颜色没有统一标准,因此口罩自动识别难度比车牌识别更大,这也是目前智能停车管理系统不能通过简单软件升级实现口罩识别,所以还要人工检查口罩佩戴的原因。
5.另外,传统车牌识别采用opencv跨平台视觉库进行车牌区域提取后,采用轮廓提取的方式提取字符,然后将提取的字符进行分割,将分割的字符采用 svm或者模板匹配的方式进行字符分类识别。这种识别方式存在一些缺陷,比较容易在分割字符的时候分割到两个字符,并且受到外界环境的影响比较严重,识别效果不理想,并且由于字符提取的方式依赖于阈值化的参数调节以及字符轮廓的参数设置,参数调节起来会比较麻烦。
6.基于现状,始得本发明。
技术实现要素:
7.针对现有的智能停车管理系统无法适应无接触式管理的问题,本发明的目的在于提供一种车辆进入无接触式智能控制方法,通过口罩自动识别与车牌识别相结合,进行智能识别和管理,实现车辆的无接触式管理,以提高车辆进出检测效率。
8.为了解决上述问题,本发明提供一种车辆进入无接触式智能控制方法,包括如下过程:
9.s1触发系统启动:当车辆进入入口闸机预定位置,触发控制系统工作,链接系统硬件,并选择串口启动程序;
10.s2车牌和人面部图像采集:图像采集设备启动,识别车牌的摄像头和识别人面部的摄像头分别采集车牌图像和人面部图像;
11.s3图像识别:车牌识别模块和口罩识别模块分别对s2采集的所述车牌图像和人面识图像进行识别,得到车牌号码数据和是否佩戴口罩的判断结果;
12.s4识别数据的处理:对于口罩识别模块识别结果为否,控制模块控制反馈模块通过语音或文字提醒车内人员佩戴口罩;识别结果为是,启动健康码处理模块识别健康码,并判断健康码是否正常;
13.s5入口闸机的控制:当健康码处理模块识别结果为是,控制模块向闸机发送开启指令控制入口闸机开启,并记录车牌号码和进入时间;当健康码处理模块识别结果为否,控制模块不给闸机发送开启指令并通过所述反馈模块通过语音或文字提醒禁止进入。
14.进一步地,所述口罩识别模块,采用yolov4 mobilenetv2进行识别,包括训练子模块和检测子模块。
15.进一步地,所述检测子模块口罩检测方法为:
16.c1获取摄像头所采集的图像;
17.c2加载口罩检测模型;
18.c3加载检测种类标签文件;
19.c4加载先验框对应的txt文件;
20.c5对图像进行不失真图像尺寸调整;
21.c6判断gpu是否可用;
22.c7将图像输入网络中进行预测,得出预测框,对预测框进行堆叠,然后进行非极大值抑制;
23.c8输出目标位置以及目标种类概率;
24.c9将检测结果在图像上进行绘制并显示。
25.进一步地,所述车牌识别模块,包括车牌预处理、车牌提取和车牌字符识别步骤,具体为:
26.b1车牌预处理:对车牌图像进行灰度化处理,然后对图像边缘提取,对边缘提取的图像进行腐蚀和膨胀,再进行均值滤波,得到预处理图像;
27.b2车牌提取流程:使用findcontours对b1步骤预处理过后的图像进行轮廓查找,遍历轮廓,获取每个查找到的轮廓的最小外接矩形的中心坐标,宽高以及旋转角度,然后根据宽高变换进行宽高交换,然后根据车牌的宽高比进行车牌初步提取,将提取到的车牌进行仿射变换以及裁剪,获取到提取的车牌区域图像,将裁剪过后的车牌进行平均像素计算,根据计算到的图像rgb值进行判断当前车牌的颜色,筛选掉颜色不正确的车牌;
28.b3车牌字符识别:将b2步骤筛选后的图像进行尺寸调整,并进行字符识别,字符识别采用yolov4模型进行车牌字符识别,最后返回车牌识别字符结果。
29.进一步地,本技术车牌识别与口罩识别均使用yolov4,yolov4是一种目标检测模型,相较于r-cnn,fast-rcnn等two-stage的识别算法相比,识别速度更快,运行效率更高占用的硬件资源更少,可以在大部分不是特别复杂的情况下识别目标,并且经过多年的发展
yolo算法识别的精准度与识别速度进一步提高。
30.本技术车牌检测和口罩检测基于yolov4网络训练过程如下:
31.t1制作数据集:制作车牌或人脸图片,人脸图片要包括未佩戴口罩和佩戴口罩的人脸图片,使用labelme对图片信息做标记,每次标注一张图片完成时都将所标注的信息保存为.xml文件,所xml文件中会包含所标注图像的roi 区域信息;
32.t2训练参数设置:在训练时需要对模型的网络超参数进行设定,主要涉及图像输入分辨率、置信度阈值、与非极大值抑制的iou大小、初始学习速率、和优化器类型;
33.t3模型训练:将t1标记的图像数据集输入yolov4 mobilenetv2网络进行训练;
34.t4模型欠拟合与过拟合处理:在损失函数里添加限制权重参数过大的l1 范数正则化或者l2范数正则化,在损失函数下降的过程中,使得权重参数逐渐趋向0甚至等于0;
35.t5验证数据集与评测标准:验证数据集首先将原来训练数据集中划分为k 个不重叠的子数据集,接着再进行k个模型训练和验证,最后对这k次的训练偏差和验证误差各自求平均数;
36.评测标准采用map,其计算公式如式1-3所示:
[0037][0038]
其中qr是验证集个数。
[0039]
进一步所,所述t4步骤中的正则化可以分为l1正则化与l2正则化,l1 正则化的计算方法如公式1-1所示,l2正则化的计算方法如公式1-2所示:
[0040][0041][0042]
上式中,λ为正则化因子,是超参数;
[0043]
||w||1为l1范数,||w||1为l2范数。
[0044]
本发明,将口罩识别结果作为控制入口闸机开启的控制条件,实现了车牌与口罩佩戴的自动智能识别,特别是还结合健康码的自动识别判断,实现了车辆进入停车场、车库等的非接触式智能控制,不仅提高了效率,还提高的安全性。附图说明
[0045]
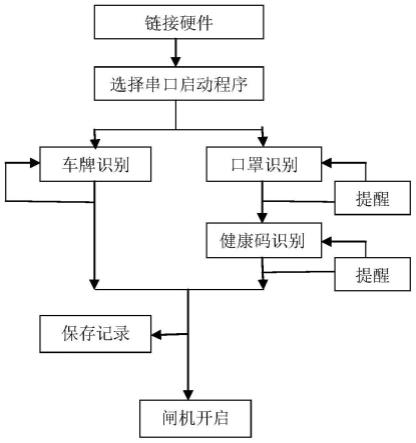
图1是本发明的流程示意图;
[0046]
图2是本发明的map曲线图;
具体实施方式
[0047]
下面结合附图和具体实施例对本发明作进一步说明,以助于理解发明内容。
[0048]
是本发明用于停车场、地下车库以及单位门口控制车辆入口闸机开启的智能控制方法,即车辆进入排接触式智能控制方法,与出口自动闸机和收费系统构成停车智能管理控制系统。由于本发明只对入口闸机的控制进行改进,因此对出口闸机的控制预以省略。
[0049]
对于车辆进出闸机智能管理控制系统硬件部分,包括进、出口闸机、控制器、摄像头、led照明系统,还可以包括地感线圈等。
[0050]
如图1所示,车辆进入无接触式智能控制方法,整个流程包括如下过程:
[0051]
s1触发系统启动:当车辆进入入口闸机预定位置,通过地感线圈或图像采集设置
获取到车辆进入信息,触发控制系统工作,链接硬件,并选择串口启动程序启动相应摄像头等串口硬件;
[0052]
s2车牌和人面部图像采集:图像采集设备启动,识别车牌的摄像头和识别人面部的摄像头分别采集车牌图像和车内人面部图像;
[0053]
s3图像识别:车牌识别模块和口罩识别模块分别对已经采集的所述车牌图像和人面识图像进行识别,得到车牌号码数据和是否佩戴口罩的判断结果;
[0054]
s4识别数据的处理:如果未正确识别出车牌,则再次进行图像采集和识别;对于口罩识别模块识别结果为否,控制模块控制口罩反馈模块通过语音或文字提醒车内人员佩戴口罩;识别结果为是,启动健康码处理模块识别健康码,并判断健康码是否正常;
[0055]
s5入口闸机的控制:当健康码处理模块识别结果为是(或正常),控制模块向闸机发送开启指令控制入口闸机开启,并保存记录车牌号码和进入时间;当健康码处理模块识别结果为否(或异常),控制模块不给闸机发送开启指令并通过所述反馈模块通过语音或文字提醒禁止进入。
[0056]
由于健康码涉及加密系统,本发明健康码识别使用二维码作为替代,即通过拍照获取健康码中的二维码信息,使用opencv4的qrcodedetector函数进行识别健康码的二维码,获取识别到的二维码解析的信息。
[0057]
本技术的核心是口罩识别模块和车牌识别模块,下面进行详细说明。
[0058]
车牌识别与口罩识别均使用yolov4目标检测模型,包括车牌识别模块和口罩识别模块,均由训练子模块和检测子模块组成。使用windows10进行模型的训练,在深度学习的训练和推导过程中对计算机硬件的需求都相当高,主要对内存和显存要求较高,不推荐用cpu来训练,本次训练采用如下配置:intel12 代i5cpu,双通道2x8g内存,nvidia rtx2070s显卡。
[0059]
一、训练子模块说明
[0060]
车牌检测和口罩检测基于yolov4网络训练过程如下:
[0061]
t1制作数据集:(1)分别制作车牌和人脸图片
[0062]
由于车牌有统一的标准,因此车牌图片使用程序进行车牌生成,一共生成 1000张车牌数据,分辨率为416
×
132。人脸图片要包括未佩戴口罩和佩戴口罩的人脸图片,本次训练采用800张开源数据图像作为训练数据,其中未佩戴口罩的人脸300张,佩戴了口罩的人脸500张。
[0063]
(2)制作车牌和人脸数据集
[0064]
使用labelme对图片信息做标记,把数据集中的任何要标注的图片进行标注,从而完成标注(即框选出待检测目标的位置和类别)。每次标注一张图片完成时都将所标注的信息保存为.xml文件,所有xml文件中会包含所标注图像的 roi区域信息,形成车牌数据集和人脸数据集,以便于对车牌检测模型和口罩检测模型进行训练。
[0065]
t2训练参数设置:在训练时需要对检测模型的网络超参数进行设定,在这里主要涉及图像输入分辨率、置信度阈值、与非极大值抑制的iou大小、初始学习速率、和优化器类型;置信度阈值以及与非极大值抑制的iou大小的,设定后可以通过过滤识别率较小的检测矩形框,学习速率控制代表着根据损失梯度调整神经网络权值的速率,学习率越小,损失梯度降低的速率就越缓慢,而收敛速率的持续时间也更长;而一旦学习率过大,梯度降低的步
子过大可能会跨过最优阈值。所以训练全过程中并没有使用一个恒定数值的学习速率,而只是随着持续时间的延长使学习速率动态地变化。
[0066]
车牌训练的网络超参数设定如下:
[0067]
使用sgd(随机梯度下降)作为损失函数优化器
[0068]
epoch分为init_epoch、freeze_epoch和unfreeze_epoch
[0069]
init_epoch=0
[0070]
freeze_epoch=50
[0071]
freeze_batch_size=4
[0072]
unfreeze_epoch=300
[0073]
unfreeze_batch_size=2
[0074]
momentum=0.937#momentum为优化器内部使用到的momentum参数
[0075]
weight_decay=5e-4#weight_decay为权值衰减,可防止过拟合
[0076]
init_lr=1e-2init_lr为模型的最大学习率
[0077]
min_lr=init_lr*0.01min_lr为模型的最小学习率,默认为最大学习率的 0.01
[0078]
lr_decay_type="cos"lr_decay_type是使用到的学习率下降方式
[0079]
save_period=10save_period多少个epoch保存一次权值
[0080]
口罩训练的网络超参数设定如下:
[0081]
epoch分为init_epoch、freeze_epoch和unfreeze_epoch
[0082]
init_epoch=0
[0083]
freeze_epoch=50
[0084]
freeze_batch_size=8
[0085]
unfreeze_epoch=300
[0086]
unfreeze_batch_size=4
[0087]
momentum=0.937#momentum为优化器内部使用到的momentum参数
[0088]
weight_decay=5e-4#weight_decay为权值衰减,可防止过拟合
[0089]
init_lr=1e-2init_lr为模型的最大学习率
[0090]
min_lr=init_lr*0.01min_lr为模型的最小学习率,默认为最大学习率的 0.01
[0091]
lr_decay_type="cos"lr_decay_type是使用到的学习率下降方式
[0092]
save_period=10save_period多少个epoch保存一次权值
[0093]
focal_loss=false focal_loss是否使用focal loss平衡正负样本
[0094]
focal_alpha=0.25focal_alpha focal loss的正负样本平衡参数
[0095]
focal_gamma=2focal_gamma focal loss的难易分类样本平衡参数
[0096]
t3模型训练:将t1标记的图像数据集输入yolov4 mobilenetv2网络进行训练;
[0097]
t4模型欠拟合与过拟合处理:深度学习模型在训练时常会发生欠拟合和过拟合的情形。欠拟合是指一类没有很好地拟合数据的现状,也就是训练与验证误差损失都相当大的状况,一般由网络层数不够多、不够深所造成,会造成网络训练的精度不够高,甚至无法很好地对非线性拟合数据进行分类。过拟合也是指一类过度拟合了数据的现状,实际上是因为所建的机器学习模型或者说是深度学习模型在训练数据中体现得过于优秀,使得在测试数据集上或者验证资料集上体现不佳,一般是由于网络层数过深或是训练样本数太小,
使得在模拟训练时陷入了极小值点所造成,会使得训练网络严重缺失了泛化学习能力,甚至根本无法对除训练样品以外的所有样品做出精确划分。
[0098]
随着模型复杂度的增高,过拟合的情况越来越严重,因此减少参数可以有效缓解过拟合,本发明是在损失函数里添加限制权重参数过大的l1范数正则化或者l2范数正则化,在损失函数下降的过程中,使得权重参数逐渐趋向0 甚至等于0;正则化可以分为l1正则化与l2正则化,l1正则化的计算方法如公式1-1所示,l2正则化的计算方法如公式1-2所示。
[0099][0100][0101]
同时,λ为正则化因子,是超参数,λ>0,当权重参数均为零时,惩罚项最小。当λ较大时,由于惩罚项在损失函数中的比重很大,它往往会使学到的权重参数的元素较接近零,当λ设为零时,惩罚项根本不起作用。||w||1为l1 范数,为l2范数,由于l1正则化最后得到w向量中将存在大量的零,使模型变得稀疏化,因此l2正则化更加常用。
[0102]
通常,如果在训练数据集中的样本数过少,尤其是比训练模型的参数更少时,过拟合更易于出现。因此,可以通过增加数据集的情况来防止欠拟合的发生。
[0103]
t5验证数据集与评测标准:由于验证数据集中并不参加模型训练,在训练数据不够用时,保留大批的验证数据过于浪费。一个可以改进的办法就是k折交叉验证(k-fold cross-validation)。在k折交叉验证当中,首先将原来训练数据集中划分为k个不重叠的子数据集,接着再进行k个模型训练和验证,最后对这k次的训练偏差和验证误差各自求平均数。
[0104]
评测标准:本设计在设计的同时考虑了评估模型检验结果的优劣,一个很关键的标准是map(mean average precision),代表全部类标签的平均准确率,是对多个验证集求平均ap(average precision)值,通过对召回率(recall)以及精确率(precision)的计算可以得出ap值,然后由此计算相应map,map计算公式如式1-3所示:
[0105][0106]
其中qr是验证集个数。
[0107]
训练map变化曲线如图2所示。
[0108]
二、检测方法
[0109]
1、车牌识别:车牌识别分为车牌预处理,车牌提取,车牌字符识别。 b1车牌预处理流程:对车牌图像进行灰度化处理,图像边缘提取,对边缘提取的图像进行腐蚀膨胀,进行均值滤波,得到预处理图像;
[0110]
b2车牌提取流程:使用findcontours对预处理过后的图像进行轮廓查找,遍历轮廓,获取每个查找到的轮廓的最小外接矩形的中心坐标,宽高以及旋转角度,然后根据宽高变换进行宽高交换,然后根据车牌的宽高比进行车牌初步提取,将提取到的车牌进行仿射变换以及裁剪,获取到提取的车牌区域图像,将裁剪过后的车牌进行平均像素计算,根据计算到的图像rgb值进行判断当前车牌的颜色,筛选掉颜色不正确的车牌。
[0111]
b3车牌字符识别:将筛选后的图像进行尺寸调整,并进行字符识别,本发明采用
yolov4模型进行车牌字符识别,最后返回车牌识别字符结果。 yolov4模型具有以下优点:backbone部分使用cspdarknet53结构,在网络架构中,将残差模块集成到resnet网络结构中,获得darknet53。为了进一步提高网络性能,需要结合cross stage partial network(cspnet),结合其优越的学习能力,形成cspdarknet53。将不同的特征层的信息输入到残差模块中,提供更高层次的特征映射作为输出。与resnet网络相比,这显著降低了网络参数,同时提高了残差特征信息,提高了特征学习能力。从输入图像中提取丰富的特征信息,解决了其他大型卷积网络结构中的重复梯度问题,减少模型参数和 flops,既保证了推理速度和准确率,又减小了模型尺寸,降低了环境的干扰,并且免去了参数的调节。yolov4中使用的dropblock,能够随机删除减少神经元的数量,使网络变得更简单。在neck部分,采用了spp模块以及pan模块,将特征层分别通过一个池化核大小为5
×
5、9
×
9、13
×
13的最大池化层,然后在通道方向进行concat拼接在做进一步融合,这样能够在一定程度上解决目标多尺度问题。通过前述方法处理,让车牌的字符识别可以更加精确,并且可以定位出每个字符的精确位置。
[0112]
2、口罩识别
[0113]
口罩检测方法为:
[0114]
c1获取摄像头所采集的图像:采用opencv的函数videocapture进行图像采集,将采集的图像在qt界面上显示。
[0115]
c2加载训练好的口罩检测模型:通过pytorch加载yolov3口罩检测模型,对采集的图像进行预测。
[0116]
c3加载检测种类标签文件(txt):加载口罩的种类文件,分别为戴口罩 (with_mask)与未带口罩(without_mask)。
[0117]
c4加载先验框对应的txt文件:加载事先设定的先验框数据,更加精确的预测。
[0118]
c5对图像进行不失真图像尺寸调整:对图像进行不失真调整,通过在图像周围补上黑色背景实现图像尺寸调整。
[0119]
c6判断gpu是否可用:通过pytorch函数对设备的cuda判断是否可用。
[0120]
c7图像预测:将图像输入网络中进行预测,得出预测框,对预测框进行堆叠,然后进行非极大值抑制;经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况,这时就需要用到nms来选取那些邻域里分数最高(口罩的概率最大),并且抑制那些分数低的窗口。
[0121]
c8输出目标位置以及目标种类概率:将目标概率最大的一类进行输出,得出输出概率以及输出的矩形框位置
[0122]
c9将检测结果在图像上进行绘制并显示。通过opencv的矩形绘制函数,将预测结果位置以及预测概率在图像上进行显示。
[0123]
以上所述,只公开了本发明的较优应用实例,不能以此限定本发明的范围,凡依此发明专利申请范围及说明内容所做的简单的等效变化与修饰,皆属于本发明专利涵盖的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。