1.本发明属于计算机视觉领域,具体涉及一种用于细粒度跨模态检索的通道混合方法。
背景技术:
2.细粒度检索作为细粒度分析的重要组成部分,近年来得到了越来越多的关注。细粒度检索是计算机视觉和模式识别领域的基础研究课题,旨在研究对某一传统语义类别下细粒度级别的不同子类类别进行视觉检索任务,如不同子类的狗、不同子类的鸟、不同车型的汽车等。由于细粒度的物体对象在类间差异中只有细微的视觉差异,却又在姿态、规模等类内差异上有较大的变化,因此有较大的检索难度。
3.跨模态检索任务主要研究如视频、图像、文本、音频等模态间数据表示及其关联信息。由于近年来多模态数据的爆炸式增长,跨模态检索受到了研究者的广泛关注。跨模态检索任务将一种模态的数据作为查询条件,检索其他模态中的相对应的数据。如用户可以通过一段文本检索与该文本相关的图像、视频等信息。由于查询及其检索结果模态表征的差异,如何度量不同模态之间的相似性是跨模态检索任务的主要挑战。近年来,跨模态检索的研究主要集中于图像与文本两个模态,对于视频与音频等模态则少有研究者关注。另一方面,大部分跨模态检索的工作仅关注粗粒度方向的检索,对于细粒度方向的跨模态检索方法仍显不足。
4.数据增强则是深度学习中训练模型常用的方法。良好的数据增强可以使模型在有限的样本中取得更好的表达结果。目前,最常见的数据增强方法均作用于图像模态中,比如fmix与cutmix等。这些方法对原图做切片、拼接等处理,旨在挖掘不同类别的图像之间的差异,从而使模型具有更好的表达效果。而对于其他模态的数据,目前仍然没有较为成熟的数据增强方法。
5.目前,已有的跨模态检索方法主要集中于粗粒度的跨模态检索中。在很多情况下,以狗的图片搜索为例,人们不仅仅希望搜索得到的图片是狗而不是其他动物,还希望知道这是什么品种的狗,比如是柯基还是萨摩耶。更近一步的,人们还希望看到对于这个品种的狗的详细描述或是生活视频。在这样的情况下,目前已有的跨模态检索方法准确率较低。另一方面,不同模态间的关联信息在跨模态检索任务中尤为重要,数据增强方法更是用于挖掘这些关联信息的最低成本方法。然而,目前仍然没有可以应用于不同模态数据间的数据增强方法。
技术实现要素:
6.本发明的目的在于提供一种用于细粒度跨模态检索的通道混合方法,在细粒度跨模态检索任务中,采用通道混合的方式,增强不同模态间数据信息的交互,从而提升检索性能。
7.实现本发明目的的技术方案为:第一方面,本发明提供一种用于细粒度跨模态检
索的通道混合方法,包括以下步骤:
8.步骤1,通过预训练卷积神经网络提取图像、视频、音频与文本共四个模态数据的特征信息;
9.步骤2,对于步骤1中提取到的图像、视频、音频与文本共四个模态数据的特征信息,在通道维度中做不同模态间数据特征的交互,挖掘不同模态间数据的相似语义信息;
10.步骤3,在缩小不同模态中拥有相同子类别数据的空间距离的同时,增加不同模态下不同子类别数据的空间距离,从而增加模型对不同类别数据的甄别能力。
11.第二方面,本技术还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述第一方面所述的方法。
12.第三方面,本技术还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述第一方面所述的方法。
13.第四方面,本技术还提供了一种计算机程序产品,包括计算机程序,其特征在于,该计算机程序被处理器执行时实现上述第一方面所述的方法。
14.本发明与现有技术相比,其显著优点为:(1)本发明通过不同模态间数据特征的通道信息交互,进行数据增强。发明将数据增强扩展到了不同的模态数据间,而以往的方法往往只能在单一模态中进行数据增强;(2)本发明在进行不同模态间数据特征的通道信息交互中,引入了负样本的特征信息交互,进一步提升了模型对不同模态数据特征的挖掘能力;(3)本发明在训练卷积神经网络的过程中,通过约束不同模态下不同子类别数据的空间距离来提升网络对不同模态及不同类别数据的甄别能力,这是其他方法所不具备的。
附图说明
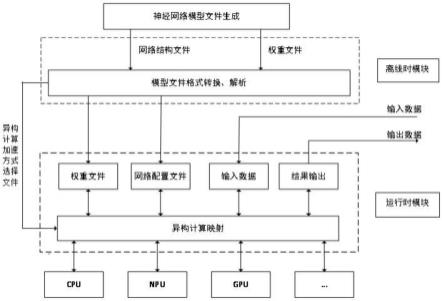
15.图1为本发明用于细粒度跨模态检索的通道混合方法的示意图。
具体实施方式
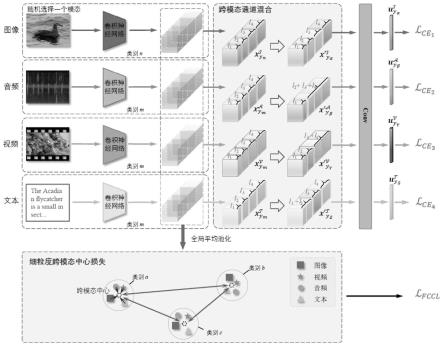
16.结合图1,本发明提供一种用于细粒度跨模态检索的通道混合方法,具体包括以下步骤:
17.步骤1,通过预训练卷积神经网络提取图像、视频、音频与文本共四个模态数据的特征信息;
18.首先通过不同的预训练卷积神经网络获取图像视频音频与文本共四个模态数据的特征组。
19.具体而言,假设共存在n个类别,记类别空间为那么整体样本空间可以记为其中代表四个不同的模态。代表模态下的属于类别yi的样本的集合。对于中的每个模态,我们从集合中随机选取四个样本组成一个图像-音频-视频-文本对,记为其中,代表类别ym下图像模态中的一个样本实例,含义与相似。
20.对于这个图像-音频-视频-文本对通过预训练的卷积神经网络提取特征组:
[0021][0022]
其中,其中,为图像实例的特征,含义与相似。分别代表特征的通道维度,它们的值相同,均为d。h与w代表这些特征的高度与宽度。为不同模态下的预训练卷积神经网络。
[0023]
步骤2,对于步骤1中提取到的图像、视频、音频与文本共四个模态数据的特征信息,在通道维度中做不同模态间数据特征的交互,挖掘不同模态间数据的相似语义信息,提升检索性能;
[0024]
对于步骤1中得到的特征组进行通道维度的信息交互。具体而言,首先需要替换中四种模态中任意一种模态的特征,使其属于类别yn且yn≠ym。而后需要将四个特征在通道维度上拆解成4份,最后重新组合这些拆解的特征并使用重新组合的特征参与模型训练。
[0025]
以替换中图像模态(了)的特征为例,完整的流程如下:
[0026]
1)在图像样本集中选取类别为yn的样本实例其中yn≠ym。根据公式(1)得到的特征
[0027]
2)用的特征替换中图像模态的特征得到一个新的特征组
[0028]
3)将新的特征组x中的4个特征均拆解为四份:
[0029][0030][0031][0032][0033]
其中,l1,l2,l3,l4代表每一部分的通道维度的大小。在每一次图像-音频-视频-文本对的特征组生成过程中,l1,l2,l3与l4都在保持l1 l2 l3 l4=d的基础上随机生成。
[0034]
4)重新组合这些拆解的特征,得到新的特征组,如下:
[0035][0036][0037][0038][0039]yα
,y
β
,y
γ
,y
δ
代表新的特征的类别标签。由于新的特征不仅包含某些模态下类别ym的语义信息,还包含某些模态下类别yn的语义信息(比如包含了音频、视频、文本模态下类别ym的语义信息和图像模态下类别yn的语义信息),因此需要重新定义这4个标签的值如
下:
[0040][0041][0042][0043][0044]
最后,在卷积神经网络中,可以通过交叉熵损失进行模型的训练。这种基于不同模态间特征通道混合的数据增强方式,不仅增加了不同模态间的信息交互,还增加了不同类别间的信息交互。
[0045]
步骤3,在缩小不同模态中拥有相同子类别数据的空间距离的同时,增加不同模态下不同子类别数据的空间距离,从而增加模型对不同类别数据的甄别能力。
[0046]
在采用步骤2提出的通道混合的方式进行数据增强的同时,缩小不同模态中拥有相同子类别数据的空间距离,增加不同模态下不同子类别数据的空间距离,从而增加模型对不同类别数据的甄别能力。
[0047]
具体而言,对于步骤2中得到的新的特征与通过一层1
×
1的卷积层与全局平均池化层将其变化为大小为h
×
w的特征向量w的特征向量与最后,对于这些特征向量,在卷积神经网络的训练过程中,还需进行如下损失函数约束:
[0048][0049]
其中,b是训练过程中每次随机选取图像-音频-视频一文本对的数量。代表通过第i个图像-音频-视频一文本对得到的特征向量,ci代表与相关的模态内类别中心向量。ψ(
·
)代表余弦相似函数。代表指示函数。[
·
]
代表校验函数max(0,
·
),即若中括号内函数计算值大于0,则输出不变,否则输出为0。ξ是控制不同类别间距离的阈值。θ,ζ是用于对齐量纲的超参数,σ是用于判断和相似程度的超参数。
[0050]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。