1.本发明涉及网络安全语义摘要领域,特别涉及基于少样本学习的网络安全协同处置的语义分析方法。
背景技术:
2.网络安全信息化方法中利用人工智能协助安全运营人员完成网络安全保障任务可以提高任务完成的速度和效率。网络安全协同处置系统完成网络安全事件的预防、发现、预警和协调处置等工作,在工作过程中,运营人员之间的沟通中蕴含着大量关键信息,比如对网络安全事件的预防、发现等工作的细节操作,不同运营人员之间任务命令的交换,人工智能在运营人员沟通过程中为他们提供协助,比如提到查询ip地址,协同处置系统反馈给运营人员操作推荐的快捷方式。人工智能在协助运营人员的过程中,对于文本的处理、关键词的提取以及关键词触发的操作反馈这些技术的优化尤为重要。与此同时,在网络安全协同处置的场景下,运营人员的沟通语料依赖人工输入,能够获取的语料数据有限,我们需要利用少样本学习、迁移学习减少模型训练对数据的依赖。
3.在目前的先进技术中,对于网络安全运营过程中产生的文本做关键词提取和关键词触发的模型较少,关键词提取是从运营过程中产生的文本中获取能够表达文本主旨的关键词,通过对文本摘要的了解,在备选操作集中选取出运营人员可能需要的操作协助,反馈给运营人员,从而提高运营工作的效率。网络安全领域中对于网络安全事件的处理过程记录的文本有限,这给依赖大量数据训练的深度学习在网络安全领域发展产生了阻碍。在网络安全协同处置的场景下,语料依赖人工输入,样本较少,为解决训练数据少的问题,我们提出基于少样本学习的网络安全协同处置作的语义分析方法,利用有限的文本数据集资源,训练出能够更加泛化应用的关键词提取模型。对网络安全协同处置的语料进行语义分析的处理往往存在以下问题:(1)基于有监督学习的关键词提取模型需要依赖大量人工标注的数据,但网络安全领域内的数据集资源不丰富,对于一些新的关键词的提取需要大量人工标注,降低了模型的自适应性;(2)词语是词义的表现形式,现有关键词识别模型只关注词语层面的信息,而忽略词的语义信息;(3)现有模型处理对话文本时往往忽略了对话角色的重要性,网络安全协同处置系统中不同角色的运营人员对应的文本关键词会触发不同级别的任务列表。
4.因此,急需提供一种基于少样本学习的网络安全协同处置的语义分析方法,以解决上述问题。
技术实现要素:
5.为实现上述目的,发明人提供了一种基于少样本学习的网络安全协同处置的语义分析方法,包括以下步骤:
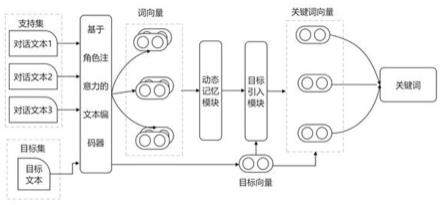
s1:记录网络安全协同处置的运营过程,将运营人员针对网络安全事件的应对过程作为语料库;s2:将语料库划分为支持集和目标集,从支持集中抽取支持文本,从目标集中抽取目标文本,对抽取的支持文本和目标文本进行文本嵌入和位置嵌入处理,得到由标记向量和位置向量拼接的词向量;s3:将词向量输入多级注意力文本编码器,多级注意力文本编码器的注意力机制关注对话中的角色信息,结合上下文,调整词向量的注意力权重;s4:将支持文本中的词向量输入动态记忆模块,动态记忆模块存放个语义向量,用于表示不同语义簇的质心,根据每次被送入动态记忆模块的词向量与语义向量的相似度动态调整个语义向量;s5:将支持文本和目标文本的词向量输入目标引入模块,将支持文本中代表关键词的词向量与目标文本中的词向量进行一一比对,找出目标文本中的关键词;s6:将关键词到对应处理网络安全事件的操作的映射集合放入操作集中,其中关键词到操作的映射集合由数据统计得到,根据目标文本中提取的关键词,找出操作集中和目标文本中提取的关键词对应的处理网络安全事件的操作,并向运营人员做出操作推荐。
6.作为本发明的一种优选方式,步骤s1中,网络安全协同处置的运营过程包括:建表序列化运营对话、标记出运营人员的角色、分析网络安全异常问题的关键词、根据分析安排对应的任务,以上运营人员针对网络安全事件的应对过程构成网络安全协同处置的语料库。
7.作为本发明的一种优选方式,步骤s2还包括:对于输入的文本p是由n个对话文本和关键词标签的样本对组成,表达式为:其中表示文本中的第i段对话,表示第i段对话对应的关键词标签;在文本开头标记start,对话和关键词标签之间用“$”隔开,文本末尾标记end;输入文本p通过词向量矩阵生成标记向量,为每个词分配的位置向量为,为对话中的角色分配的角色向量为,拼接标记向量和位置向量得到词向量,表达式为:将三个初始化矩阵和输入的词向量相乘,得到,其分别对应查询词向量、键词向量和值词向量,表达式为:。
8.作为本发明的一种优选方式,步骤s3还包括步骤:将初始化矩阵和输入的角色向量相乘,得到对应的角色向量,将角色向量加入注意力机制公式中,根据角色信息为文本分配权重:
其中,表示角色向量的权重;将词向量和角色向量送入多级注意力模块,多级注意力模块由多个注意力头组成,每个注意力头关注不同的文本信息,多级注意力模块根据当前词和其他词之间的相似度调整注意力权重,计算当前词和其他词的相似度,表达式为:对于计算出的相似度除以同一个系数,即对查询向量和键值向量的乘积进行缩小,然后用softmax函数做归一化处理,采用注意力机制公式计算相似度,注意力机制公式的表达式为:其中,是为矩阵上三角部分赋值为0的函数,为k的维度大小;将输出结果输入多级注意力文本编码器的归一化层,对输出结果进行归一化处理,将数据映射到[0,1]之间,表达式为:其中,表示经过多级注意力处理的词向量;将归一化处理的输出结果输入多级注意力文本编码器的前向传播层,进行前向传播处理,表达式为:其中,表示经过前向传播处理的词向量,为激活函数,为函数权重,为函数偏置;将前向传播处理的输出结果和归一化处理的输出结果做残差操作并进行归一化处理,表达式为:其中,表示经过归一化处理的词向量;通过叠加12层多级注意力文本编码器增加网络的容量、增强网络的表达能力,将经过残差操作并进行归一化处理的输出结果输入12层多级注意力文本编码器中,表达式为:其中,表示第 i 层的多级注意力文本编码器处理过的词向量,代表多级注意力文本编码器,i表示第i层多级注意力文本编码器。
[0009]
作为本发明的一种优选方式,步骤s4还包括步骤:训练阶段,将输入12层多级注意力文本编码器中的输出结果输入动态记忆模块,随着训练的迭代过程动态更新动态记忆模
块中存储的语义向量,采用 k-means 对词向量进行聚类,随机选取个聚类质心点为对于输入到动态记忆模块中的每一个词向量,计算其与质心的距离,选取最接近的质心,表达式为:并且更新记忆模块中存储的语义向量,即聚类质心点,表达式为:其中,为当前时刻送入多级注意力文本编码器中的词向量,为动量系数,此处设置。
[0010]
作为本发明的一种优选方式,步骤s4还包括步骤:测试阶段,根据聚类结果为不同的词语赋予不同的语义聚类类别。
[0011]
作为本发明的一种优选方式,步骤s5还包括步骤:将通过动态记忆模块聚类的词向量送入目标引入模块,目标文本经多级注意力编码器处理的词向量根据支持文本做出关键词权重调整,选出权重最高的n个目标词向量,得到目标文本中的关键词。
[0012]
区别于现有技术,上述技术方案所达到的有益效果有:(1)实现了网络安全协同处置系统中人工智能协同运营人员完成对网络安全事件的处置任务,即实现了人工智能模型在运营人员之间的沟通内容中提取关键词,通过关键词推荐与关键词相关的操作给运营人员,协助运营人员高效完成对网络安全事件的预防、发现、预警和协调处置等;(2)本方法利用了少样本学习框架代替传统的有监督学习框架进行关键词提取,减少了对标注数据的依赖,通过有限的标注数据有效的完成了对话文本的关键词提取和触发;(3)本方法利用了语义聚类将词义相近的词语聚集在一起,有效的减少了关键词的冗余;(4)本方法根据应用场景的特殊性将角色信息加入注意力机制中,根据角色为文本分配不同的权重,配合关键词有效的得到了不同的任务推荐;(5)本方法通过少样本框架、语义聚类方法和角色注意力实现网络安全协同处置的高效工作。
附图说明
[0013]
图1为具体实施方式所述基于少样本学习的网络安全协同处置的语义分析方法框架图。
[0014]
图2为具体实施方式所述多级注意力文本编码器中的词向量提取算法流程图。
具体实施方式
[0015]
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实
施例并配合附图详予说明。
[0016]
如图1所示,本实施例提供了一种基于少样本学习的网络安全协同处置的语义分析方法,包括以下步骤:s1:记录网络安全协同处置的运营过程,将运营人员针对网络安全事件的应对过程作为语料库;s2:将语料库划分为支持集和目标集,从支持集中抽取支持文本,从目标集中抽取目标文本,对抽取的支持文本和目标文本进行文本嵌入和位置嵌入处理,得到由标记向量和位置向量拼接的词向量;s3:将词向量输入多级注意力文本编码器,多级注意力文本编码器的注意力机制关注对话中的角色信息,结合上下文,调整词向量的注意力权重;s4:将支持文本中的词向量输入动态记忆模块,动态记忆模块存放个语义向量,用于表示不同语义簇的质心,根据每次被送入动态记忆模块的词向量与语义向量的相似度动态调整 个语义向量;s5:将支持文本和目标文本的词向量输入目标引入模块,将支持文本中代表关键词的词向量与目标文本中的词向量进行一一比对,找出目标文本中的关键词;s6:将通过数据统计的关键词到对应处理网络安全事件的操作的映射集合放入操作集中,根据找出的目标文本中的关键词,得出操作集中和找出的目标文本中的关键词对应的处理网络安全事件的操作,并向运营人员做出操作推荐。
[0017]
在上述实施例的步骤s1中,网络安全协同处置的运营过程包括:建表序列化运营对话、标记出运营人员的角色、分析网络安全异常问题的关键词、根据分析安排对应的任务,以上运营人员针对网络安全事件的应对过程构成网络安全协同处置的语料库。
[0018]
在上述实施例中,步骤s2具体的:将语料库划分为支持集和目标集,从支持集中抽取支持文本,从目标集中抽取目标文本,对抽取的支持文本和目标文本进行文本嵌入和位置嵌入处理,得到由标记向量和位置向量拼接的词向量;对于输入的文本p是由n个对话文本和关键词标签的样本对组成,表达式为:其中表示文本中的第i段对话,表示第i段对话对应的关键词标签;在文本开头标记start,对话和关键词标签之间用“$”隔开,文本末尾标记end;输入文本p通过词向量矩阵生成标记向量,支持文本和查询文本都是 p 的格式 p 泛指语料库的文本,为每个词分配的位置向量为,为对话中的角色分配的角色向量为,拼接标记向量和位置向量得到词向量,表达式为:将三个初始化矩阵和输入的词向量相乘,得到,其分别对应查询词向量、键词向量和值词向量,表达式为:
。
[0019]
在上述实施例中,步骤s3具体的:微调注意力机制,增加角色信息的,将初始化矩阵和输入的角色向量相乘,得到对应的角色向量,将角色向量加入注意力机制公式中,根据角色信息为文本分配权重:其中,表示角色向量的权重;将词向量和角色向量送入多级注意力模块,多级注意力模块由多个注意力头组成,每个注意力头关注不同的文本信息,多级注意力模块根据当前词和其他词之间的相似度调整注意力权重,即根据当前查询的词和文本中其他词之间的相似度调整注意力权重,首先计算当前词和其他词的相似度,表达式为:对于计算出的相似度除以同一个系数,即对查询向量和键值向量的乘积进行缩小,然后用softmax函数做归一化处理,采用注意力机制公式计算相似度,注意力机制公式的表达式为:其中,是为矩阵上三角部分赋值为0的函数,为k的维度大小;将输出结果输入多级注意力文本编码器的归一化层,对输出结果进行归一化处理,将数据映射到[0,1]之间,方便模型进行处理,表达式为:其中,表示经过多级注意力处理的词向量;如图2所示,将归一化处理的输出结果输入多级注意力文本编码器的前向传播层,进行前向传播处理,表达式为:其中,表示经过前向传播处理的词向量,为激活函数,为函数权重,为函数偏置;将前向传播处理的输出结果和归一化处理的输出结果做残差操作并进行归一化处理,表达式为:其中,表示经过归一化处理的词向量;通过叠加12层多级注意力文本编码器增加网络的容量、增强网络的表达能力,将经过残差操作并进行归一化处理的输出结果输入12层多级注意力文本编码器中,表达式
为:其中,表示第 i 层的多级注意力文本编码器处理过的词向量,代表多级注意力文本编码器,i表示第i层多级注意力文本编码器。
[0020]
在上述实施例中,步骤s4具体的:在训练阶段,将输入12层多级注意力编码器中的输出结果输入动态记忆模块,随着训练的迭代过程动态更新动态记忆模块中存储的语义向量,采用 k-means 聚类算法对词向量进行聚类,随机选取个聚类质心点为对于输入到动态记忆模块中的每一个词向量,计算其与质心的距离,选取最接近的质心,表达式为:并且更新记忆模块中存储的语义向量,即聚类质心点,表达式为:其中,为当前时刻送入多级注意力文本编码器中的词向量,为动量系数,此处设置;在测试阶段,根据聚类结果为不同的词语赋予不同的语义聚类类别。
[0021]
在上述实施例中,步骤s5具体的:将通过动态记忆模块聚类的词向量送入目标引入模块,支持文本作为先验知识,为目标文本提供外部知识,目标文本经多级注意力文本编码器处理的词向量根据先验知识做出关键词权重调整,选出权重最高的n个目标词向量,得到目标文本中的关键词。
[0022]
根据得到的关键词,找到处置网络安全事件操作集中相关的任务,为运营人员做出任务推荐,在上述实施例的步骤s6中,操作集由关键词到对应处理网络安全事件的操作的映射组成,即操作集由数据统计得到,此数据包括根据平时的一些运营过程记录下来的数据,也可以人工添加进去的数据。
[0023]
在一些实施例中,图1所示的整个流程框架需要预先进行训练,训练阶段采用少样本学习框架学习元知识,测试阶段使用基于多级注意力的文本编码器和动态记忆模块完成提取关键词提取任务,具体的:采用公开的对话数据集kdconv面向多转知识驱动会话的中文多域对话数据集进行训练:训练任务使用基于多级注意力文本编码器和基于语义聚类的动态记忆模块的关键词提取模型,在输入文本时,利用基于多级注意力文本编码器对输入文本中的词语编码生成词向量,之后用基于语义聚类的动态记忆模块对词向量进行语义聚类,用tf-idf词频-逆向文件频率方法统计出权重最高的关键词。
[0024]
用中文预训练的bert变压器的双向编码器作为多级注意力文本编码器的初始化模型,如图2所示,使用交叉熵损失函数监督模型训练,采用sgd随机梯度下降优化器,设置dropout=0.1,多级注意力文本编码器训练10000个轮回。
[0025]
训练完成之后,用开源数据集cmcse全面多源的网络安全数据集对网络模型进行性能测试,测试模型在跨领域对话数据集上的泛化能力。
[0026]
基于本实施例上述方案,使用公开的对话数据集kdconv对模型进行训练,结合开源数据集cmcse进行测试,其中cmcse数据集是记录网络安全协同处置运营过程,运营人员针对某一网络安全事件的应对过程形成的文本数据。kdconv数据集是包含了来自电影、音乐和旅游三个领域的4.5k个对话,86k个句子,这些对话包含了相关话题的深度讨论,以及多个话题之间的自然过渡。本方法提出的基于少样本学习的网络安全协同处置的语义分析方法,训练阶段,模型在kdconv数据集上训练,在标注数据充足的数据集上训练,确保模型获得足够的共有特征,这些文本词向量间的共有特征帮助模型在测试阶段遇到新领域的文本时提取准确的关键词。测试阶段,模型在cmcse数据集上进行测试,本方法的模型在跨领域的文本数据集上获得了极佳的性能,这也充分证明了本方法提出的模型好的泛化能力。
[0027]
大量实验表面,从精确率、召回率和f1值三个评价标准对本方法的性能做出衡量;如下表所示:对比了三种词向量提取算法和本方法提出的词向量提取算法,实验表明本方法选取的词向量提取算法性能最佳。
[0028]
对于关键词提取算法,本实验选取现阶段性能较好的三种关键词提取算法和本方法提出的关键词提取算法进行对比,如下表所示,本方法提出的模型精确率提升了1.87%,召回率提高了1.72%,f1值提高了0.53%。
[0029]
在相同数据集上,从词向量生成的效果上看,本方法和其他的模型方法相比有较高的提升,在横向比较中,不同的模型在cmcse数据集上进行比对,相比基础的循环神经网络基础的架构如:textrank基于图的关键词抽取方法、tf-idf词频-逆向文件频率方法、singlerank基于文档相似的关键词提取方法等模型的基础上增加了基于少样本学习的网络安全协同处置的语义分析方法,其提取关键词的精确率比表现最好的效果要略胜一筹,评价标准精确率、召回率和f1值分别提高了1.76%、2.37%和2.04%,并且利用少样本学习框架减少了对标签数据的需求。
[0030]
需要说明的是,尽管在本文中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本文所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
