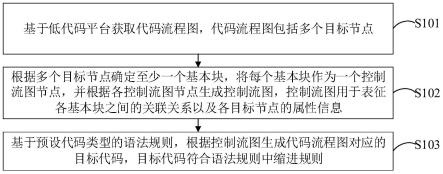
1.本发明涉及一种基于有意义学习的零样本语义分割方法,同时也涉及相应的零样本语义分割装置,属于计算机视觉技术领域。
背景技术:
2.零样本学习(zero shot learning)是计算机视觉领域常用的识别方法之一。利用零样本学习技术,可以识别出从未见过的数据类别,即训练的分类器不仅能够识别出训练集中已有的数据类别,还可以对于来自未见过的类别的数据进行区分。近年来,零样本学习技术引起了广泛的关注,主要在于它能够缓解语义边界明确的条件下标注样本的缺失,放松了对大规模数据的苛刻条件,从而能够快速地利用已有知识,泛化到未见过的类别或者是任务上。
3.目前,主流的零样本学习方法主要分为两种,一种是基于投射的方法,另一种是基于生成的方法。基于投射的方法是学习一个投射函数,将语义嵌入和视觉表征同时投影到公共隐空间,在测试阶段利用投影函数对不可见类的语义进行投影得到不可见类的视觉参数,从而进行判别。然而,基于投射的方法通常在更适用于实际应用的广义零样本学习任务上表现较差,因为没有不可见类的投影约束,并且不可见类的投影不可避免地会受到可见类的偏差影响。另一方面,基于生成的方法主要利用生成对抗网络生成不可见类的特征,并利用这种带标签的特征训练分类器,从而将零样本学习转换为一个全监督任务。尽管基于生成的方法可以在零样本学习任务上取得较好的效果,但是大多数零样本学习都是针对分类任务,在密集性任务如图像分割上,仍然难以取得较好的效果。
4.在专利号为zl 202110093474.5的中国发明专利中,公开了一种零样本图像语义分割方法,分为类别无关前背景图像分割模块与零样本目标分类模块两部分。其中,类别无关前背景图像分割采用基于mask-rcnn的两阶段图像分割框架,并辅助内外边缘判别器,边缘自监督模块提升图像前背景分割的精度。零样本目标分类模块基于cada-vae算法,并辅助deep inversion反向生成视觉特征减小视觉特征与语义特征的域距离,提升零样本目标分类的精度。利用该方法,在已知类上训练后可在未知类目标上也得到较好的图像分割性能,大大减少了样本的需求以及繁复的人工标注,大幅提升没有样本以及样本较少场景下图像语义分割任务的性能。
技术实现要素:
5.本发明所要解决的首要技术问题在于提供一种基于有意义学习的零样本语义分割方法。
6.本发明所要解决的另一技术问题在于提供一种基于有意义学习的零样本语义分割装置。
7.为了实现上述目的,本发明采用下述的技术方案:
8.根据本发明实施例的第一方面,提供一种基于有意义学习的零样本语义分割方
法,包括如下步骤:
9.s1:利用大规模的具有标注信息的已知类别数据对分割模型和生成模型进行预训练;
10.s2:利用预训练的生成模型以及未知类的语义编码,获取针对未知类的生成视觉表征;
11.s3:从可见类中随机挑选样本抽取视觉表征,并和步骤s2生成的未知类的视觉表征构建共轭关联损失;
12.s4:将未知类的生成视觉表征分别通过快分类器和慢分类器进行两次预测,并计算相应的损失函数,实现零样本图像分割。
13.其中较优地,所述步骤s1中,所使用的语义图像分割模型为deeplab v2,其中的判别器快分类器和慢分类器分别采用两个1
×
1卷积层实现,认知控制器采用一个卷积层实现。
14.其中较优地,所述步骤s1中,随机采样第n个可见类数据的真值语义图构造标签词向量图并与随机采样的噪声图zn进行拼接,输入给生成器获得生成视觉表征并引导生成视觉表征和真实视觉表征相接近,从而建立标签-视觉的语义映射,其中是特征提取器,n为正整数。
15.其中较优地,所述生成视觉表征和所述真实视觉表征被送入所述快分类器并计算分类损失,所述判别器与所述快分类器共享第一层的参数。
16.其中较优地,所述步骤s2中,根据可见类和不可见类的语义编码,随机采样一个语义编码矩阵作为未知类的语义编码,给定相应的标签词向量图并送入经过预训练的生成器获取针对未知类的生成视觉表征。
17.其中较优地,所述步骤s3具体包括如下子步骤:
18.s31,从可见类中随机采样一个图片;
19.s32,计算语义空间上的真实向量图和随机向量之间的语义空间关联;
20.s33,计算视觉空间上真实视觉表征和生成视觉表征的视觉语义关联;
21.s34,根据语义空间关联和视觉语义关联计算共轭关联损失。
22.其中较优地,所述语义空间关联为语义空间中随机产生的真实向量图的第i个补丁以及真实标签词向量图的第j个补丁之间的关联关系。
23.其中较优地,所述视觉语义关联为视觉空间中真实视觉表征的第j个补丁以及生成视觉表征的第i个补丁之间的关联关系。
24.其中较优地,所述步骤s4具体包括如下子步骤:
25.s41,通过快分类器对所有视觉语义进行预测;
26.s42,通过认知控制器评估快分类器的预测,并估计所述预测和可见类的概念之间的兼容性;
27.s43,通过慢分类器进一步预测认知控制器不确定的视觉语义表示;
28.s44,计算加权分类的损失函数以及认知控制器的损失函数。
29.根据本发明实施例的第二方面,提供一种基于有意义学习的零样本语义分割装置,包括处理器和存储器,所述处理器读取所述存储器中的计算机程序,用于执行以下操作:
30.s1:利用大规模的具有标注信息的已知类别数据对分割模型和生成模型进行预训练;
31.s2:利用预训练的生成模型以及未知类的语义编码,获取针对未知类的生成视觉表征;
32.s3:从可见类中随机挑选样本抽取视觉表征,并和步骤s2生成的未知类的视觉表征构建共轭关联损失;
33.s4:将未知类的生成视觉表征分别通过快分类器和慢分类器进行两次预测,并计算相应的损失函数,实现零样本图像分割。
34.与现有技术相比较,本发明具有以下的技术效果:能够在没有视觉样本的条件下很好地学习新概念,并且通过构建可见类的视觉表征和不可见类的视觉表征之间的共轭关联损失,处理新概念与已有概念之间的冲突,形成融合的概念模式,将新概念(不可见类)与已有的概念(可见类)联系起来进行快速的学习。相比于以前基于投射和基于生成的零样本分割方法,本发明更加注重可见类与不可见类之间的相关性,自然地促进了知识的持续构建,可以使图像分割效果更加优越。
附图说明
35.图1为本发明实施例提供的基于有意义学习的零样本语义分割方法的流程图;
36.图2为本发明实施例中,构建可见类的视觉表征和不可见类的视觉表征之间的共轭关联损失的流程图;
37.图3为本发明实施例中,对未知类的生成视觉表征进行预测并计算损失函数的流程图;
38.图4(a)为本发明实施例中,进行抠图实验的输入图片示意图;
39.图4(b)为本发明实施例中,通过spnet进行抠图的结果示意图;
40.图4(c)为本发明实施例中,通过zs3net进行抠图的结果示意图;
41.图4(d)为本发明实施例中,通过cagnet进行抠图的结果示意图;
42.图4(e)为本发明实施例中,通过本发明所述方法进行抠图的结果示意图;
43.图4(f)为本发明实施例中,通过本发明所述方法进行抠图的标签示意图;
44.图5为本发明实施例提供的基于有意义学习的零样本语义分割装置的结构示意图。
具体实施方式
45.下面结合附图和具体实施例对本发明的技术内容进行详细具体的说明。
46.首先需要说明的是,在计算机视觉领域中,本发明的处理对象主要为图像,因此也可以称其为零样本语义图像分割方法及零样本语义图像分割装置。为了表述简洁起见,在本发明中将它们分别简称为零样本语义分割方法及零样本语义分割装置。
47.图1为本发明实施例中,基于有意义学习的零样本语义分割方法的整体流程图。如图1所示,该零样本语义分割方法至少包括如下步骤:
48.s1:利用大规模的具有标注信息的已知类别数据对分割模型和生成模型进行预训练。
49.在本发明的一个实施例中,所使用的语义图像分割模型为deeplab v2(进一步的详细说明,可以参阅论文《deeplab:semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected crfs》,其网址为https://arxiv.org/abs/1606.00915)。deeplab v2主要由两部分组成,一个是区域分割网络,另一个是用于实现边界优化的crf概率图模型。另外,其中的判别器快分类器和慢分类器分别采用两个1
×
1卷积层实现,并且共享第一层的参数,认知控制器采用一个卷积层来实现。
50.在此基础上,对于可见类的所有训练数据(在本发明的不同实施例中,具体为各类图片),随机采样第n个可见类数据的真值语义图构造标签词向量图并与随机采样的噪声图zn进行拼接,输入给生成器获得生成视觉表征并引导生成视觉表征和真实视觉表征相接近,从而建立起标签-视觉的语义映射,其中是特征提取器,n为正整数。此外,生成视觉表征和真实视觉表征被送入快分类器并计算分类损失,判别器与快分类器共享第一层的参数,用于尽可能地区分出生成视觉表征和真实视觉表征
51.生成器和判别器组成生成对抗网络。其中,生成器生成像是真实的但含有噪音的视觉表征用于欺骗判别器判别器需要判别该视觉表征是真实的还是生成的。通过以上方式迭代训练,最终完成对生成器特征提取器判别器和快分类器的预训练。
52.通过上述的预训练步骤,可以构造一个性能卓越的生成模型,从而更好地学习不可见类(即未知类,下同)的真实概率分布,生成尽可能接近于真实不可见类样本的合成样本,以此缩小可见类和不可见类的之间的数据不平衡,从而提高图像分类精度。
53.s2:利用预训练的生成模型以及未知类的语义编码,获取针对未知类的生成视觉表征。
54.在本发明的一个实施例中,可以将输入样本表征为其中h、w、c分别代表图像的高度、宽度和通道数。在此基础上,根据可见类和不可见类的语义编码,随机采样一个语义编码矩阵作为未知类的语义编码,给定相应的标签词向量图并送入经过预训练的生成器获取针对未知类的生成视觉表征
55.s3:从可见类中随机挑选样本抽取视觉表征,并和步骤s2生成的未知类的视觉表征构建共轭关联损失。
56.如图2所示,在本发明的一个实施例中,上述步骤s3具体包括如下子步骤s31~s34:
57.s31,从可见类中随机采样一个图片;
58.具体地说,在可见类训练集中随机采样一张图片,假设是第n张图片,并获取相应的真实视觉表征生成视觉表征以及标签词向量图其中n为正整数。
59.s32,计算语义空间上的真实向量图和随机向量之间的语义空间关联;
60.在计算机视觉领域,语义指的是图像的内容。相应的语义空间关联具体为:语义空间中随机产生的真实向量图的第i个补丁以及真实标签词向量图的第j个补丁之间的关联关系,可以建模为:
[0061][0062]
s33,计算视觉空间上真实视觉表征和生成视觉表征的视觉语义关联;
[0063]
在计算机视觉领域,视觉语义是指通常所理解的底层语义特征,即颜色、纹理和形状等。相应的视觉语义关联具体为:视觉空间中真实视觉表征的第j个补丁以及生成视觉表征的第i个补丁之间的关联关系,可以建模为:
[0064]
s34,根据语义空间关联和视觉语义关联计算共轭关联损失。
[0065]
在本发明的一个实施例中,所述共轭关联损失l
con
通过如下公式进行计算:
[0066][0067][0068]
其中,α
i,j
是一个像素级的自适应边缘,用于充分保证不同像素位置的视觉语义多样性。通过计算语义空间关联和视觉语义关联的共轭关联损失,可以将不可见类与可见类联系起来,建立不可见类与可见类之间的相关性。其中,共轭关联损失l
con
越小,不可见类与可见类之间的相关性越强。
[0069]
s4:将未知类的生成视觉表征分别通过快分类器和慢分类器进行两次预测,并计算相应的损失函数,实现零样本图像分割。
[0070]
如图3所示,在本发明的一个实施例中,上述步骤s4具体包括子步骤s41~s44:
[0071]
s41,通过快分类器对所有视觉语义进行预测;
[0072]
所述快分类器的预测过程表达式为:
[0073][0074]
其中,是由生成器生成视觉表征。
[0075]
s42,通过认知控制器评估快分类器的预测,并估计所述预测和可见类的概念之间的兼容性;
[0076]
所述认知控制器的评估表达式为:
[0077][0078]
其中,p
m,i
∈[0,1]2是一个二维向量,分别表示和已有概念的匹配程度和不匹配程度。
[0079]
s43,通过慢分类器进一步预测认知控制器不确定的视觉语义表示;
[0080]
所述慢分类器的二次预测表达式为:
[0081][0082]
其中,表示克罗内克符号函数,如果p
m,i
[0]《p
m,i
[1]成立,则取值为1,反之则取值为0。
[0083]
s44,计算加权分类的损失函数以及认知控制器的损失函数。
[0084]
在本发明的一个实施例中,采用二值交叉熵引导认知控制器的学习,计算认知控制器的损失函数l
con
。其计算公式为:
[0085][0086]
其中,的值由该像素点的真值标签计算得到,其计算公式为:
[0087][0088]
由于慢分类器的部分参数是由已知概念初始化的,为了限制对可见类和不可见类的惩罚力度,在损失中引入了平衡因子,使得在训练慢分类器时更关注不可见类。在本发明的一个实施例中,形式化表示平衡因子为:
[0089][0090]
因此,加权分类的损失函数l
cls
的计算公式为:
[0091][0092]
需要说明的,加权分类的损失函数l
cls
越小,表明慢分类器的分类效果越好。
[0093]
上述步骤通过快分类器和慢分类器对生成视觉表征进行两次预测,通过计算得到尽量小的加权分类的损失函数以及认知控制器的损失函数,最终能够较准确地实现未知类的生成视觉表征的分类。
[0094]
在本发明的一个实施例中,将上述各个步骤应用于计算机视觉中的抠图处理。其中,物体分割选用数据集pascal-voc。在具体实施时,迭代执行上述步骤s1~s4,特征提取器采用初始学习率2.5e-4
的sgd优化器,生成器和判别器的优化器分别是初始学习率2e-4
和2.5e-4
的两个adam优化器。权重衰减设置为5e-4
,批次大小设置为8。对于超参数,通过交叉
验证设置了λ=10,β1=0.5,β1=0.5。在测试时,首先将输入图片的像素调整至513x513。实验中采用了两种不同的标签嵌入模型,在google news上训练的word2vec(维度d=600)和在common crawl上训练的快速文本(维度d=300),并按照之前的工作拼接了这两个嵌入作为最终词向量。对于具有多个单词的类别,直接平均每个单词的嵌入表示。
[0095]
如图4(a)所示,本发明通过所提供的不同类别的语义编码以及本发明预先训练完成的分割模型和生成模型,即可以完成对输入图片的抠图处理。如图4(b)~图4(f)所示,采用其他方法对输入图片进行抠图处理后,不能很好地识别出真实标签,但本发明所提供的零样本语义分割方法的图像分割效果较好,能准确识别图像内容并给出正确标签。
[0096]
表1 不同方法抠图处理的分割结果和真实标签之间的重合度
[0097]
方法spnetzs3cagnet本发明miou0.54670.61430.64230.6702
[0098]
结合表1所示,其中miou为计算预测的分割结果和真实的标签之间重合度的指标。从表1可以看出,本发明所提供的零样本语义分割方法的重合度相对最高。可以看出,无论是实际的抠图效果,还是与真实分割结果的重合度,本发明所提供的零样本语义分割方法均可以获得优于现有技术的显著效果。
[0099]
在上述零样本语义分割方法的基础上,本发明进一步提供一种基于有意义学习的零样本语义分割装置。如图5所示,该零样本语义分割装置包括一个或多个处理器51和存储器52。其中,存储器52与处理器51耦接,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器51执行,使得所述一个或多个处理器51实现如上述实施例中的零样本语义分割方法。
[0100]
其中,处理器51用于控制上述零样本语义分割装置的整体操作,以完成上述零样本语义分割方法的全部或部分步骤。该处理器51可以是中央处理器(cpu)、图形处理器(gpu)、现场可编程逻辑门阵列(fpga)、专用集成电路(asic)、数字信号处理(dsp)芯片等。存储器52用于存储各种类型的数据以支持在该零样本语义分割装置的操作,这些数据例如可以包括用于在该零样本语义分割装置上操作的任何应用程序或方法的指令,以及应用程序相关的数据。该存储器52可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,例如静态随机存取存储器(sram)、电可擦除可编程只读存储器(eeprom)、可擦除可编程只读存储器(eprom)、可编程只读存储器(prom)、只读存储器(rom)、磁存储器、快闪存储器等。
[0101]
综上所述,本发明所提供的基于有意义学习的零样本语义分割方法及装置,首先利用大规模的具有标注信息的已知类别数据对分割模型和生成模型进行预训练,通过预训练的生成模型以及未知类的语义编码,获取针对未知类的生成视觉表征;然后重点在于构建可见类的视觉表征和不可见类的视觉表征之间的共轭关联损失,利用可见类与不可见类之间的相关性进行学习,最后将未知类的生成视觉表征分别通过快分类器和慢分类器进行两次预测,并计算相应的损失函数,实现零样本图像分割。
[0102]
与现有技术相比较,本发明具有以下的技术效果:能够在没有视觉样本的条件下很好地学习新概念,并且通过构建可见类的视觉表征和不可见类的视觉表征之间的共轭关联损失,处理新概念与已有概念之间的冲突,形成融合的概念模式,将新概念(不可见类)与已有的概念(可见类)联系起来进行快速的学习。相比于以前基于投射和基于生成的零样本
分割方法,本发明更加注重可见类与不可见类之间的相关性,自然地促进了知识的持续构建,可以使图像分割效果更加优越。
[0103]
上面对本发明所提供的基于有意义学习的零样本语义分割方法及装置进行了详细的说明。对本领域的一般技术人员而言,在不背离本发明实质内容的前提下对它所做的任何显而易见的改动,都将构成对本发明专利权的侵犯,将承担相应的法律责任。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。