技术特征:
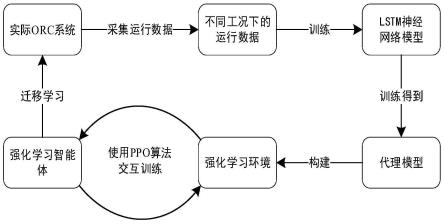
1.一种基于代理模型虚实迁移的有机朗肯循环强化学习控制方法,其特征在于,包括:(1)在余热工况存在扰动的情况下,每隔一段时间改变有机朗肯循环系统的设定值,采集历史积累的闭环运行数据;(2)利用采集得到的闭环运行数据训练基于神经网络预测的系统动力学模型,将其作为有机朗肯循环系统的代理模型,验证在闭环控制下代理模型与实际系统的准确性和一致性;若代理模型符合要求则执行步骤(3),否则重复步骤(2);(3)利用代理模型构建强化学习预训练的虚拟仿真环境,在一个强化学习episode内设置多个设定值并加入时变的余热扰动,训练强化学习智能体以控制代理模型;若训练效果达到预设条件则执行步骤(4),否则重复步骤(3);(4)将在虚拟仿真环境中预训练的强化学习智能体的结构和参数迁移到实际有机朗肯循环控制系统,并进行微调和继续训练,直至在实际系统上达到理想的控制效果;(5)将训练好的强化学习智能体用于实际有机朗肯循环系统的过程控制。2.根据权利要求1所述的基于代理模型虚实迁移的有机朗肯循环强化学习控制方法,其特征在于,步骤(1)中,采集历史积累的闭环运行数据具体为:在多种运行工况下采集若干条随时间变化的系统状态量,包括:蒸发器出口压力p
e
、蒸发器出口温度t
oe
、工质的质量流量m
ai
、冷凝流体温度t
ai
、工质泵转速u、过热值sh、跟踪误差sh-sh
set
和控制信号m;采集得到的系统状态序列将作为训练基于神经网络预测的系统动力学模型的输入输出数据。3.根据权利要求2所述的基于代理模型虚实迁移的有机朗肯循环强化学习控制方法,其特征在于,步骤(2)的具体过程为:(2-1)将t时刻的七个状态量p
e
,t
oe
,m
ai
,t
ai
,u,sh,sh-sh
set
和控制信号m输入神经网络预测模型,将t 1时刻的状态量作为标签进行训练,得到系统动力学模型,将其作为有机朗肯循环系统的代理模型;(2-2)在闭环控制下,给训练后的代理模型与实际系统设置相同的初态和控制器参数,通过比较两者的控制效果验证预测模型的准确性和一致性,如果模型预测效果未达到预期,则重复步骤(2-1)。4.根据权利要求3所述的基于代理模型虚实迁移的有机朗肯循环强化学习控制方法,其特征在于,步骤(2-1)中,所述神经网络预测模型的结构为:第一层为lstm,神经元个数为80,加入一个dropout层防止过拟合,再加入一层lstm,神经元个数为100,再加入一个dropout层防止过拟合。5.根据权利要求1所述的基于代理模型虚实迁移的有机朗肯循环强化学习控制方法,其特征在于,步骤(3)中,使用ppo算法训练强化学习智能体以控制代理模型。6.根据权利要求1所述的基于代理模型虚实迁移的有机朗肯循环强化学习控制方法,其特征在于,步骤(3)的具体过程为:(3-1)根据实际有机朗肯循环系统历史数据中状态变化的范围,设置强化学习状态的上下限和强化学习训练episode的终止条件;(3-2)将强化学习智能体的动作作为控制信号m,并根据实际有机朗肯循环控制系统中控制信号的范围设置动作空间;(3-3)在一个强化学习的episode内,每隔一段时间随机改变一次代理模型控制系统的
设定值,并加入时变的余热扰动,以增加迁移后的泛化性能;根据误差信号sh-sh
set
设置离散和连续的奖励,不断训练和调参,直至强化学习智能体能采取准确的动作快速减小误差,达到理想的控制效果。7.根据权利要求6所述的基于代理模型虚实迁移的有机朗肯循环强化学习控制方法,其特征在于,步骤(3-3)中,根据误差信号sh-sh
set
设置离散和连续的奖励具体为:设置离散部分奖励为:当sh-sh
set
的绝对值小于1时给予正奖励,其余为负奖励,误差区间越小奖励越大;连续部分奖励为reward=-5*(sh-sh
set
)
2-0.5(u
t-u
t-1
)。8.根据权利要求1所述的基于代理模型虚实迁移的有机朗肯循环强化学习控制方法,其特征在于,步骤(4)具体包括:将代理模型构建的虚拟仿真环境下预训练得到的强化学习智能体迁移到实际有机朗肯循环的控制系统,根据在实际系统和虚拟仿真环境中的控制效果的偏差继续调整强化学习奖励、算法参数、episode终止条件的参数设置,在实物上继续训练,直至强化学习智能体在实际有机朗肯循环控制系统中能实现同样的设定值跟踪性能。
技术总结
本发明公开了一种基于代理模型虚实迁移的有机朗肯循环强化学习控制方法,包括:(1)在余热工况存在扰动的情况下,每隔一段时间改变有机朗肯循环系统的设定值,采集历史积累的闭环运行数据;(2)利用采集的数据训练系统动力学模型,将其作为有机朗肯循环系统的代理模型;(3)利用代理模型构建强化学习预训练的虚拟仿真环境,在一个强化学习episode内设置多个设定值并加入时变的余热扰动,训练强化学习智能体;(4)将强化学习智能体的结构和参数迁移到实际有机朗肯循环控制系统,并进行微调和继续训练;(5)将强化学习智能体用于实际有机朗肯循环系统的过程控制。利用本发明,可以大幅提升训练效率,有效解决系统响应慢、计算耗时的问题。时的问题。时的问题。
技术研发人员:谢磊 罗杨杨 林润泽 苏宏业
受保护的技术使用者:浙江大学
技术研发日:2022.08.02
技术公布日:2022/11/11
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。