一种基于arima模型和gbdt算法的销售预测方法
技术领域
1.本发明涉及人工智能领域,尤其涉及一种基于arima模型和gbdt算法的销售预测方法。
背景技术:
2.随着经济的发展,对于各企业的产品销售来说,都希望自己在日趋激烈的角逐中实现利润最大化,为了实现这一目标,企业需要挖掘出历史数据中所蕴含的信息,从而把握市场动向,更加精确地制定出自己未来产品的营销和生产计划,使企业更有竞争力。面对已有的大量数据资源,商业企业迫切地想要寻找合适的人工智能和大数据技术来对它们的数据进行建模、分析,让数据发挥价值,从而来指导决策者做出好的销售策略,进而做到以最少的成本来获取最大的利润,做到科学有效的经营管理,规避风险和损失。传统时间序列分析方法虽然已自成体系,但不能充分考虑时间序列中的诸多因素,传统时间序列分析方法与机器学习方法的融合层出不穷,但依旧缺少稳定性和针对性,也缺少一个可以为企业提供销售数据分析的有效工具。
技术实现要素:
3.为了解决以上技术问题,本发明提供了一种基于arima模型和gbdt算法的销售预测方法。
4.本发明的技术方案是:
5.一种基于arima模型和gbdt算法的销售预测方法,基于销售企业的时间序列数据,通过融合arima模型和gbdt算法,建立销量预测模型,充分挖掘原始销售数据中的线性信息和非线性信息,预测未来一段时间内的销售数据。
6.进一步的,
7.步骤如下:
8.(1)数据获取及预处理
9.(2)构建arima模型
10.(3)构建arima_gbdt融合模型
11.(4)模型效果比对。
12.再进一步的,
13.(1)数据获取及预处理
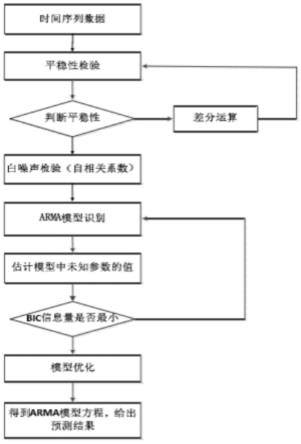
14.接入对数据进行去重、清洗、校验,将多源的数据进行整合。然后对数据进行分析、统计,必要的时候给出可视化展示,可以形象直观地帮助我们了解数据的内在规律性。
15.采用网络爬虫技术获取企业销售数据,然后以python语言为基础,利用 pandas进行数据的预处理工作,并以图表的形式将处理好的数据进行可视化展示,为后续算法模型的检验,提供可靠的数据集。
16.(2)构建arima模型
17.基于处理好的数据,构建arima模型,包括白噪声检验、序列平稳性检验及非平稳序列处理、模型识别和定阶、模型中未知参数的估计、模型优化,最后我们将应用得到的arima模型,给出数据集未来5个时间单位的销售额预测值
18.(3)构建arima_gbdt融合模型
19.将一个时间序列看做是线性部分和非线性部分的加和,用arima模型对时间序列进行拟合分析,提取序列中的线性部分,再通过gbdt算法来拟合残差,即可发现序列中的非线性信息。
20.利用python将原始数据、arima拟合数据和残差数据,作为算法的输入值,通过网格调参法,得到预测结果。
21.(4)模型效果比对
22.并采用rmse和mape两种评价指标,来对比和量化模型的优劣,基于以上结果,可得出arima_gbdt融合模型在趋势拟合、短期预测准确率和总体预测误差方面,都有相当可观的提升。
23.本发明的有益效果是
24.本发明基于销售企业的时间序列数据,通过融合arima模型和gbdt算法,建立销量预测模型,提高了销量数据预测的精确度和预测速度,使得我们在硬件水平一定的情况下,在更短的时间内,处理更多的数据,而精确度却更高。随着互联网和信息技术的发展,产品的销售模式也迈入了信息化,未来对于销售数据和销售预测的精确把握,将是企业决策的重要参考依据和核心竞争力。
25.在销量预测模型方面,利用arima模型拟合时间序列数据的线性部分,采用 gbdt模型对时间序列的非线性部分进行拟合,充分提取时间序列数据中的线性信息和混沌信息,预测结果相比传统的单一模型算法有了较大的提高。
附图说明
26.图1是arima模型分析预测流程图;
27.图2是rima模型和gbdt算法融合模型构建流程图。
具体实施方式
28.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
29.(1)arima模型
30.arima模型全为自回归积分滑动平均模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。
31.基本思想:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。这个模型一旦被识别后就可以从时间序列的过去值及现在值来预测未来值。
32.(2)gbdt算法
33.gbdt(gradient boosting decision tree),又叫mart(multiple additiveregression tree),是一种迭代的决策树算法,该算法由多棵决策树组成。决策树的学习过程,就是使用训练集的样本特征,对数据进行划分,得到每个节点的叶子节点的预测结果。同时该模型又基于boosting算法的思想,每次迭代都在减少残差的方向新建一颗决策树,不断迭代提高预测的准确性。
34.本发明提供了一种基于arima模型和gbdt算法的销售预测方法,基于销售企业的时间序列数据,通过融合arima模型和gbdt算法,建立销量预测模型,充分挖掘原始销售数据中的线性信息和非线性信息,预测未来一段时间内的销售数据。
35.利用网络爬虫技术获取企业销售数据,并使用python中的pandas工具包对销售数据进行预处理操作,包括合并、分类、统计等。
36.其中,
37.arima模型结构:
[0038][0039]
应用arima模型进行分析、预测。时间序列的分析、预测可归纳为白噪声检验、序列平稳性检验及非平稳序列处理、模型识别和定阶、模型中未知参数的估计、模型优化,最后我们将应用得到的arima模型,给出数据集未来5个时间单位的销售额预测值。
[0040]
差分处理结果
[0041]
差分阶数1差分序列均值1405.911差分序列标准差2417316观测数94差分去掉的观测数1
[0042]
白噪声检验结果
[0043][0044]
通过模型拟合,得到自回归因子:
[0045]
φ(b)=1 1.55274b**(1) 1.46831b**(2) 1.57256b**(3) 0.9015b**(4)
[0046]
移动平均因子:
[0047]
θ(b)=1 0.57509b**(1) 0.03837b**(2) 0.00215b**(3)
ꢀ‑
0.47539b**(4)-0.6768b**(5)
[0048]
则arima模型为:
[0049][0050]
根据得到的arima模型,基于获取的数据进行未来5周的销售数据预测:
[0051][0052][0053]
将一个时间序列看做是线性部分和非线性部分的加和,用公式表示如下:
[0054]zt
=l
t
n
t
(l
t
表示线性部分,n
t
表示非线性部分)
[0055]
首先,用arima模型对时间序列进行拟合分析,提取序列中的线性部分l
t
,得到用ε
t
表示arima模型的拟合序列之后的残差,则残差公示如下:
[0056]
(为arima模型在时刻的取值)
[0057]
然后,通过gbdt算法来拟合残差,即可发现序列中的非线性信息。得到 arima_gbdt融合算法的模型结构为:
[0058]
(为ε
t
的预测结果)
[0059]
利用python将原始数据、arima拟合数据和残差数据,作为算法的输入值,通过网格调参法,得到预测结果。
[0060]
预测准确率
[0061]
模型预测值1预测值2预测值3预测值4预测值5arima0.5627280.6077910.9490610.8722500010.660656456arima_gbdt0.8641510.8389470.9205460.8856979240.79938364
[0062]
再采用rmse和mape两种评价指标,比对和量化两种模型的优劣:
[0063]
[0064][0065][0066]
对以上实验结果的分析,我们可以清楚的看到基于arima的改进算法模型,相比于基础模型算法,有着更高的准确率,arima_gbdt融合模型在趋势拟合、短期预测准确率和总体预测误差方面有相当可观的提升。
[0067]
以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。