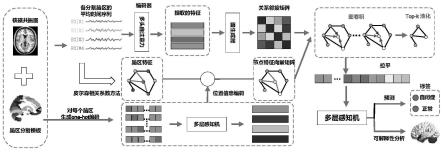
1.本技术属于医学图像处理技术领域,具体为一种基于核磁共振图像预测自闭症并寻找生物标记的方法。
背景技术:
2.自闭症谱系障碍asd是一种终身的发育残疾,临床特征是社会交流受损、重复行为以及兴趣受限。最近的研究提出,遗传和生活环境的结合可能是导致asd的主要原因。然而,神经科学家仍然在寻找可靠和客观的方法来改善目前倾向于主观和不准确的诊断方法,如问卷调查和临床观察。根据自闭症和发育障碍监测(addm)网络,大约每59名儿童中就有1名患有asd,这揭示了寻找客观的生物标志物来促进临床诊断和治疗迫切需要。
3.使用核磁共振图像预处理工具,可以得到大脑功能连接数据,有了它作为输入,许多深度学习方法开始形成。然而,大多数相关的研究存在如下问题:
4.(1)由于不同的扫描仪或在多个地点的研究组,造成所有数据属性的不一致。
5.(2)由于每次fmri扫描产生的数百万个体素,导致计算维数爆炸。
6.(3)有限数量(数十或数百)的训练样本。
7.(4)可解释性差。
8.为此,深入研究核磁共振图像,寻找客观的生物标志物来促进临床诊断和治疗,尤为必要。
技术实现要素:
9.本技术提出了一种基于核磁共振图像预测自闭症并寻找生物标记的方法,推动基于核磁共振图像进行asd诊断的研究进程,为临床医学诊治asd提供可靠的工具和生物标记。
10.为了实现上述目的,本技术技术方案如下:
11.一种基于核磁共振图像预测自闭症并寻找生物标记的方法,包括:
12.获取检测对象脑部核磁共振图像,采用预设的脑区分割模板进行脑部感兴趣区域分割,对各个脑部感兴趣区域内包含的所有体素序列值求平均,得到各脑部感兴趣区域记录血氧水平变化的时间序列;
13.对得到的时间序列使用皮尔森计算相关系数方法做相关运算,得到各脑部感兴趣区域对应的特征向量;
14.使用独热编码方法,为每个脑部感兴趣区域创建位置向量,将位置向量经过多层感知机的学习,得到最终的位置向量;
15.将每个脑部感兴趣区域作为一个节点,将每个脑部感兴趣区域的位置向量与特征向量对应相加,得到节点特征向量;
16.将时间序列输入到多头注意力编码器,将得到的编码特征输入到图生成器中,以每个脑部感兴趣区域作为一个节点,得到各个节点所构成图的关系邻接矩阵;
17.将所有节点特征向量构成的节点特征向量矩阵与关系邻接矩阵做图卷积操作,得到含有邻接节点关系的最终节点特征向量矩阵;
18.将最终节点特征向量矩阵经过top-k池化操作,得到所有节点的重要性分数,选取重要性分数排名在前的k个节点,将所选取的节点的特征向量进行拉平,得到用于进行预测的特征向量;
19.将用于进行预测的特征向量输入多层感知机中,得到预测结果。
20.进一步的,所述图卷积操作表示公式如下:
21.hs=batchnorm1d(relu(ah
s-1ws
))
22.其中,batchnorm1d表示一维批归一化操作,relu是激活函数,a是关系邻接矩阵,hs表示经过s次图卷积后得到的节点特征向量矩阵,h0是最初的节点特征向量矩阵。
23.进一步的,所述将最终节点特征向量矩阵经过top-k池化操作,得到所有节点的重要性分数,包括:
24.将最终节点特征向量矩阵与池化权重向量做矩阵相乘,得到所有节点的重要性分数。
25.进一步的,所述基于核磁共振图像预测自闭症并寻找生物标记的方法,还包括:
26.通过联合损失函数计算联合损失进行网络训练,所述联合损失函数如下:
27.l=l
ce
αl
intra
βl
inter
γl
tpk
28.其中,α,β,γ是各个损失的权重系数;
[0029][0030]
其中y为结果为自闭症的标签值,m表示在批训练中没批样本数量,zi为得出第i个样例为自闭症的分数,sigmoid为激活函数;
[0031][0032]
其中,c表示一个标签,c为所有标签的集合,sc={i|y
i,c
=1}是一个标签为c的样例集合,i表示一个样例;μc为sc中所有样例的邻接矩阵的权重的均值;ai表示样例i的邻接矩阵的权重值;表示sc中所有样例的邻接矩阵中权重的方差;
[0033][0034]
其中,a,b为c中的两个标签,μa和μb分别为标签为a的样例集合的邻接矩阵的均值和标签为b的样例集合的邻接矩阵的均值;
[0035][0036]
其中,n表示每个输入样例中节点的数量;s
m,i
表示在第m个输入样例中,第i个节点的重要性分数。
[0037]
本技术提出的一种基于核磁共振图像预测自闭症并寻找生物标记的方法,通过roi的时间序列,使用多头自注意力模型进行编码并建图,学到roi之间的非线性关系,而不是简单使用皮尔森计算相关系数的方法,得到线性关系;使用top-k池化方法,提升模型的可解释能力,减少计算复杂度;加入位置特征向量,区分不同位置的节点,为模型预测,引入节点的位置信息;使用了除标准二分类交叉熵损失函数的另外三种损失函数,正则化模型的训练效果。最后采用得到的网络模型对检测对象的脑部核磁共振图像进行检测,提高了检测的准确率。
附图说明
[0038]
图1为本技术网络模型结构流程图;
[0039]
图2为本技术top-k池化的功能流程图;
[0040]
图3为本技术实施例自闭症相关的重要脑区列表。
具体实施方式
[0041]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅用以解释本技术,并不用于限定本技术。
[0042]
本技术基于检测对象的核磁共振图像,通过对图像的预处理,并使用脑区分割方法进行分割,得到了各脑区的一系列血氧水平变化的时间序列。根据该时间序列,构建图,并以图卷积为核心,对检测对象进行自闭症预测,并根据所有检测对象的预测结果数据,找出asd重要相关的脑区。为临床医学提供可靠的工具和生物标志物。
[0043]
如图1所示,一种基于核磁共振图像预测自闭症并寻找生物标记的方法,包括:
[0044]
s1、获取检测对象脑部核磁共振图像,采用预设的脑区分割模板进行脑部感兴趣区域分割,对各个脑部感兴趣区域内包含的所有体素序列值求平均,得到各脑部感兴趣区域记录血氧水平变化的时间序列。
[0045]
本实施例中,先获取检测对象的脑部核磁共振图像,采用领域相关方法(the configurable pipeline for the analysis of connectomes,cpac)进行预处理,预处理过程包括:对核磁共振测量到的体素强度值归一化;找到运动前后体素之间的一一对应关系,对运动进行校正;切片定时校正。
[0046]
本实施例挑选合适的脑区分割模板(atlas)如aal、cc200等,对已预处理的图像进行脑部感兴趣区域(roi)分割,即按照脑区分割模板上划定的分割区域,对已预处理的图像进行分割。分割后,对每个分割区域内包含的所有体素序列值求平均,得到各roi记录血氧水平变化的时间序列t,所有roi的时间序列构成的矩阵尺寸为n
×
d,其中n为roi的数量,d为时间序列的长度。
[0047]
s2、对得到的时间序列使用皮尔森计算相关系数方法做相关运算,得到各脑部感兴趣区域对应的特征向量。
[0048]
具体公式为:
[0049]
[0050]
其中,ρ
x,y
表示相关系数值,cov(x,y)表示x和y的协方差,σ
x
表示x的标准差,σy表示y的标准差,e[(x-μ
x
)(y-μy)]表示协方差的计算公式,μ
x
表示x的均值,μy表示y的均值。x和y表示不同脑部感兴趣区域对应的时间序列。
[0051]
然后得到包含所有roi特征向量的矩阵z,尺寸为n
×
f,f为特征向量的长度,一般与n(roi数量)相等,矩阵中的一行表示一个节点的特征向量。第i个roi的特征向量z[i]中的各个特征值就是第i个roi与其他对应roi之间的相关系数值,如z[i][j]表示第i个roi和第j个roi的相关系数值。这样做使得生成的结点(roi)的特征向量包含了与其他结点之间的关系信息。
[0052]
s3、使用独热编码方法,为每个脑部感兴趣区域创建位置向量,将位置向量经过多层感知机的学习,得到最终的位置向量。
[0053]
本实施例采用独热编码进行位置编码,使得模型能够动态学习各roi的位置向量。第i个roi的位置向量中,第i位为1,其它位为0。并将位置向量经过多层感知机(multilayer perceptron(mlp)也叫人工神经网络,除了输入输出层,它中间可以有多个隐层)的学习,得到最终的位置向量p。
[0054]
s4、将每个脑部感兴趣区域作为一个节点,将每个脑部感兴趣区域的位置向量与特征向量对应相加,得到节点特征向量。
[0055]
本技术将每个脑部感兴趣区域作为一个节点,生成图,图中各节点之间的边表示两个节点之间的关系。本步骤将每个脑部感兴趣区域的位置向量与特征向量对应相加,得到节点特征向量,节点特征向量中包含其位置信息。所有节点特征向量构成节点特征向量矩阵
[0056]
s5、将时间序列输入到多头注意力编码器,将得到的编码特征输入到图生成器中,以每个脑部感兴趣区域作为一个节点,得到各个节点所构成图的关系邻接矩阵。
[0057]
本实施例多头注意力编码器实现的功能可表示为:
[0058][0059]
其中q、k、v均由各roi的时间序列t通过一层感知机特征映射得到。ha尺寸为n
×
l,l为提取到的特征向量的长度。让ha经过softmax激活函数得到编码特征he,尺寸不变。将he输入到图生成组件,得到图的关系邻接矩阵a。矩阵a中,存储着各个roi之间的连接强度值,即边的权重。
[0060]
图生成组件的原理为尺寸为n
×
n。本步骤可使模型能够构建学习出图上节点非线性关系的邻接矩阵,更好地拟合人脑的功能连接。
[0061]
s7、将所有节点特征向量构成的节点特征向量矩阵与关系邻接矩阵做图卷积操作,得到含有邻接节点关系的最终节点特征向量矩阵。
[0062]
本技术将包含所有节点特征向量的节点特征向量矩阵和关系邻接矩阵a,做s次图卷积操作和归一化操作,图卷积的核心原理为a和做矩阵乘法,这样使得各节点通过和邻接的节点关系来更新自己的特征向量,得到经过了s次信息传递更新(图卷积)后的节点特征向量矩阵此时矩阵中所有节点的特征向量已经饱和吸收了邻接节点的特征信息。
[0063]
每次图卷积,将节点特征向量输入到多层感知机中进一步提取节点特征(多层感知机的原理相当于将输入到感知机的对象与多层感知机参数矩阵相乘,多层感知机参数矩阵是通过训练学习到的,最后再经过激活函数relu),再使用归一化方法对提取的节点特征进行归一化,得到的结果作为最终节点特征向量。
[0064]
总体公式为hs=batchnorm1d(relu(ah
s-1ws
)),其中ws为在第s次图卷积时,其中多层感知机要学习的参数,即最初输入到第一个图卷积的节点特征向量矩阵。其中hs表示经过s次图卷积后节点特征向量矩阵batchnorm1d表示一维批归一化操作。
[0065]
s8、将最终节点特征向量矩阵经过top-k池化操作,得到所有节点的重要性分数,选取重要性分数排名在前的k个节点,将所选取的节点的特征向量进行拉平,得到用于进行预测的特征向量。
[0066]
本技术使用top-k池化方法,如图2所示。topk池化的主要作用是,根据一定的计算方法,给图上所有节点一个重要性分数,保留重要性分数排名前k的节点,舍去其他节点,池化的过程也是缩减计算量的过程。通过构造一个可学习的池化权重向量w,该池化权重向量即为模型在top-k池化层需要学习的参数,尺寸为f
×
1。将经过多层图卷积操作后得到的最终节点特征向量与池化权重向量w做矩阵相乘,得到所有节点的重要性分数,尺寸为n
×
1,根据重要性分数,保留成绩排名在前k的节点。
[0067]
然后,将保留节点的特征向量进行拉平,得到尺寸为1
×
(n
×
f)的向量。
[0068]
s9、将用于进行预测的特征向量输入多层感知机中,得到预测结果。
[0069]
本技术将用于进行预测的特征向量放入多层感知机中,经过多层的特征映射提取,最后得到尺寸为2
×
1的向量,对应预测的两个类别,在本方法中,类别为autism或control,若预测结果为autism表示输入模型的核磁共振图的被试者患有自闭症,control表示被试者正常。
[0070]
本技术如图1所示的网络模型,在训练时,通过计算联合损失来更新网络各个模块的参数。联合损失函数表示如下:
[0071]
l=l
ce
αl
intra
βl
inter
γl
tpk
[0072]
其中,α,β,γ是各个损失的权重系数。
[0073]
1、交叉熵损失函数l
ce
:
[0074][0075]
其中y为结果为自闭症的标签值;m表示在批训练中,一个批有多少个样例,zi为模型得出第i个样例为自闭症的分数,sigmoid为激活函数,将分数值控制到[0,1]之间。
[0076]
2、组内损失l
intra
:
[0077][0078]
其中l
intra
表示计算的损失值;c表示一个标签;c为所有标签的集合,sc={i|y
i,c
=1}是一个label为c的样例集合,i表示某一样例;μc为sc中所有样例的邻接矩阵的权重的均
值;ai表示某一个样例的邻接矩阵的权重值;表示sc中所有样例的邻接矩阵中权重的方差。
[0079]
该损失函数对模型进行正则化,使得相同类别的样例,他们通过模型学到的关系邻接矩阵尽可能相似。
[0080]
3、组间损失l
inter
:
[0081][0082]
其中l
inter
表示计算的损失值;a,b为c中的两个label,μa和μb分别为label为a的样例集合的邻接矩阵的均值和label为b的样例集合的邻接矩阵的均值。
[0083]
该损失函数对模型进行正则化,使得不同类别的样例,他们通过模型学到的关系邻接矩阵尽可能不同。
[0084]
4、top-k损失l
tpk
:
[0085][0086]
其中l
tpk
表示计算的损失值;m表示在批训练中,每批中包含的样例数量;n表示每个输入样例中,节点的数量;s
m,i
表示在第m个输入样例中,第i个节点的重要性分数。
[0087]
对模型进行正则化,使得样例通过模型后,模型选出的前k个被选中的重要节点,他的重要性分数(取值范围在0到1之间)倾向于1,未被选中的节点,重要性分数倾向于0。
[0088]
本技术技术方案,将关系邻接矩阵a和传统方法使用皮尔森计算相关系数得到的邻接矩阵进行对比,发现大脑的楔前叶部分的热度明显高于其他区域,据此推测楔前叶是asd相关的。而楔前叶属于dmn(默认模式网络),有医学研究表明dmn与asd有密切关系。
[0089]
将所有asd被试,通过本技术方法进行预测,统计每个roi在每次预测结果中,影响力排名前10的出现频率,根据频率找出asd相关的生物标志物。排名结果如图3所示,最后推测出颞中回和小脑相关区域与asd紧密联系,该结果与现有的医学研究结论相吻合。图3中。第一列为脑区id,第二列为脑区标签,第三列为出现频率。其中,temporal_pole_mid_l表示颞极颞中回(左),temporal_pole_mid_r表示颞极颞中回(右),temporal_mid_r表示颞中回(右),temporal_pole_sup_l表示颞极颞上回(左),temporal_mid_l表示颞中回(左),temporal_pole_sup_r表示颞极颞上回(右),cerebelum_crus1_l表示小脑(左),cerebelum_crus1_r表示小脑(右),temporal_sup_r表示颞上回(右),temporal_sup_l表示颞上回(左)。
[0090]
本技术技术方案最终在abide数据集上的测试效果如表1所示:
[0091]
脑区分割方法灵敏度%特异度%准确度%aal68.677.272.9cc20073.378.676.4
[0092]
表1
[0093]
其中,脑区分割分别采用的是aal(anatomical automatic labeling),和cc200(craddock 200)。与本领域现有技术方案相比,上述性能指标都得到了大大的提高。
[0094]
本技术通过roi的时间序列,使用多头自注意力模型进行编码并建图,学到roi之间的非线性关系,而不是简单使用皮尔森计算相关系数的方法,得到线性关系;使用top-k池化方法,提升模型的可解释能力,减少计算复杂度;加入位置特征向量,区分不同位置的节点,为模型预测,引入节点的位置信息;使用了除标准二分类交叉熵损失函数的另外三种损失函数,正则化模型的训练效果。
[0095]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。