1.本发明属于计算机视觉图像处理技术领域,特别涉及一种异源图像的匹配方法,可用于飞行器的辅助制导。
背景技术:
2.遥感信息随着技术的发展展现出多传感器、多模态、数据量大的特性,从海量的遥感图像中获取信息已经成为一项重要的信息渠道。不同的星载传感器能获取不同模态的遥感数据,传统可见光遥感系统获取的遥感图像采用被动式成像模式,接收太阳光照射到地表目标之后反射、散射的电磁辐射,语义清晰、直观,是最常用的遥感图像类型。但受限于被动式传感器,夜间及云雾遮挡的情况下光学遥感的性能将收到较大的影响。而随着合成孔径雷达sar这一技术的不断发展,其在地理测绘、军事侦察等方面被广泛的应用。sar相对于传统可见光波段的遥感技术而言,由于sar使用主动式的传感器发射微波波段的辐射并接收回波,所以sar具有全天时、全天候的观测能力,同时不受大气云层的影响。传统可见光遥感图像能弥补sar图像语义不直观的问题,sar能补充可见光传感器夜间的观测能力。不同模态的图像中包含有相同地物不同的电磁散射特征和几何空间信息,所以将异源的sar与可见光图像进行结合对于实际应用具有很重要的意义。模板匹配是在给定的大尺寸图像中寻找某一小尺寸的图像的精确位置的图像处理技术,在众多场景中均有应用。而对于异源的图像的匹配而言,由于模态的差异,相同地物在不同的模态之中的显著程度是不同的;其次由于sar成像方式,sar图像本身还有大量的乘性噪声,两者共同增加了异源图像之间进行匹配的难度。
3.目前已有的多模态图像匹配方法主要分为传统方法和基于神经网络的方法。
4.对于传统方法,其主要分为两类:
5.其中一类传统方法直接利用图像的像素灰度信息,根据不同模态图像的灰度信息,以两幅图像之间灰度的归一化互相关ncc、互信息mi等作为相似度度量标准来寻找对应的匹配位置。liang等人利用空间互信息法结合蚁群优化算法实现图像之间局部区域相似性度量;patel等人为了提高基于互信息的匹配方法的速度,提出了一种基于最大似然估计的方法用于计算互信息。基于灰度的方法出发点简单,实现容易,但由于不同模态的图像中同一区域的灰度分布可能会存在较大的差异,因此这类方法并不能很好的适应多模态的图像之间的匹配。一方面,直接使用相似性度量准则需要适应图像灰度畸变造成的变化,另一方面需要准确区分不同对象之间的差异。这两个要求之间是有冲突的,灰度畸变造成的变化和对象间的差异无法通过灰度值区分,而且对于异源图像来说,图像间的灰度映射无法体现出稳定的规律性,所以有着很大的局限性;
6.另一类传统方法是基于人为手工设计的图像特征,在两幅图像中提取到特征描述子后,计算特征描述子的相似性,根据计算得到的相似性度量获取相似性最大的位置作为匹配位置。此类方法在同源图像上应用十分广泛,如应用非常广泛的尺度不变特征变换sift特征描述子。除此之外。众多学者开发了针对于异源图像的特征描述子,ye等人提出了
相位一致性直方图hopc,该方法利用具有光照和对比度不变性的相位一致性模型构建几何结构特征描述子,基于该异源影像间的结构特征进行匹配。xiang等人着眼于解决模态间的差异,使用哈里斯尺度空间的模态特定梯度算子,能较好的应对不同模态中同一区域辐射强度的差异带来的匹配误差。人为手工设计的特征描述子的提出具有较好的数理可解释性,在该描述子的假设前提下通常具有很高的性能,但实际应用场景中的情况复杂多变,假设的先决条件不一定能保证满足。尤其在地物场景本身较复杂的区域,图像的信息量更大,纹理细节等更加复杂外加成像中的噪声干扰等因素,共同造成了手工设计方法难以在实际的应用中发挥出理想的效果。
7.对于基于深度学习的匹配方法近年来取得了长足的进步。本质上而言,深度学习也是基于特征的方法,但与传统方法不同的是深度特征是在训练模型的过程中模型从大量的训练数据中抽象、提取出的特征,而非人为设计。基于深度学习可以实现端到端的训练、端到端的推理。同时由于深度模型强大的特征提取能力,提取到的深度特征通常比手工设计的特征更加符合实际的数据分布情况。han等人提出了匹配网络matchnet,该网络通过卷积神经网络提取特征,之后利用几个全连接层的连接,将输出的结果作为匹配程度的度量。merkle等人提出了一种孪生网络结构,模板图与源图像之间的相对位移来判断匹配的位置。mou等人将匹配定义为一个二元分类问题,并训练一个伪孪生网络来预测sar和光学贴片之间的中心像素对应关系。citak提出了使用sar和光学视觉显著性图谱作为孪生匹配网络特征提取臂的注意机制。wang等人利用自学习深度神经网络直接学习源图像和参考图像之间的映射,目的是应用该映射遥感图像配准。hoffmann等人训练了一个全卷积网络fcn,以学习对于sar和光学块对之间的小仿射变换不变的相似性度量。ma等人提出了一种基于微调vgg16模型特征提取精确配准方法。
8.上述这些基于深度学习的匹配方法虽说大大提高了匹配的准确率,但这类方法的弊端在于:如果要找到模板图在源图像中的位置,就需要逐像素滑窗计算,通过判断每一对图像块是否匹配来找到匹配的位置,这种做法应用在大尺寸的图像上,不仅会大大增加匹配的时间,同时也难以区分正确匹配位置的图像块与正确位置周围邻域内相似的图像块之间的区别,造成像素级上的较大的误差。
技术实现要素:
9.本发明的目的在于针对上述现有技术匹配精度和匹配速度上的不足,提出基于跨模态注意力与最优传输理论的异源图像匹配方法,以提升匹配速度,提高匹配准确率。
10.本发明的技术思路是:通过构建端到端的跨模态transformer匹配网络,提高匹配速度,让可见光和sar两个模态有更好的交互,并得到sar图像和可见光图像的相似性度量;通过最优传输对匹配结果进行优化,提高匹配的准确率。
11.根据上述思路,本发明基于跨模态转换网络与最优传输理论的异源图像匹配方法的实现方案,包括如下:
12.1.基于跨模态转换网络与最优传输理论的异源图像匹配方法,其特征在于,包括:
13.(1)构建异源图像匹配的训练数据和测试数据:
14.(1a)从开源数据集os dataset中选择尺寸为512
×
512的图像对作为选用数据集,该数据集包含成对的已经完成配准的sar和可见光图像;
15.(1b)将选用数据集每对图像中的可见光图像作为搜索图像,在每幅可见光对应的sar图像中随机选择像素作为左上角坐标,剪裁出256
×
256的图像作为模板图像,并保存该左上角坐标作为该图像对的真实标签;
16.(1c)将成对的剪裁后的sar图像和对应的可见光图像中80%的图像对作为训练集,20%的图像对作为测试集;
17.(2)构建跨模态transformer匹配网络n1:
18.(2a)设置包含相关图约束的segformer特征提取骨架;
19.(2b)建立包含跨模态交叉注意力的transformer网络n0;
20.(2c)将包含相关图约束的segformer特征提取骨架、包含跨模态交叉注意力的transformer网络依次级联,组成跨模态transformer匹配网络n1;
21.(3)利用训练数据和最优传输理论,使用adam算法对匹配网络n1进行迭代训练,得到训练好的匹配网络n2;
22.(4)利用最优传输理论和训练好的匹配网络n2对测试集的图像对进行匹配。
23.本发明与现有技术相比,具有以下优点:
24.1.具有更高的准确率和更小的匹配误差
25.本发明通过构建基于transformer的匹配网络模型,在segformer网络结构中加入了相关图约束及跨模态注意力对搜索图中特征的重要性进行了约束,并进行了基于最优传输的匹配优化,提高了匹配的精度。
26.2.具有更快的匹配速度
27.本发明采用余弦相似度进行特征相似性度量,无需进行非常耗时的逐像素的互相关运算,并且整个网络进行端到端的推理,匹配时间与现有深度学习方法相比更少,提高了匹配速度。
28.3.更能适应不同的地物场景
29.本发明使用了基于注意力机制的特征提取能力强的segformer作为特征提取骨架,面对复杂多变的地物场景,网络能提取到更有效的特征表示,并得到准确的匹配结果,提高了泛化能力。
附图说明
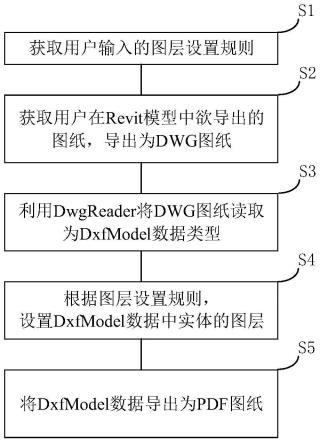
30.图1是本发明的实现流程图;
31.图2是本发明中构建添加相关图约束的segformer特征提取骨架结构图;
32.图3是本发明中构建的跨模态注意力tranformer网络结构图;
33.图4是用本发明和现有的八种算法分别在开源数据集os dataset中对一副城市区域图像上的sar图像与可见光图像进行匹配的结果对比图;
34.图5是用本发明和现有的八种算法分别在开源数据集os dataset中对一副机场区域图像上的sar图像与可见光图像进行匹配的结果对比图。
具体实施方式
35.下面结合附图对本发明的实施例和效果作进一步详细描述。
36.参照图1,本发明的实现步骤如下:
37.步骤1.构建异源图像匹配的训练数据和测试数据。
38.(1.1)从开源数据集os dataset中选择尺寸为512
×
512的图像对作为选用数据集,该数据集包含成对的已经完成配准的sar和可见光图像;
39.(1.2)将选用数据集中每对图像中的可见光图像作为搜索图像,在每幅可见光图像对应的sar图像中随机选择像素作为左上角坐标,剪裁出256
×
256的图像作为模板图像,并保存该左上角坐标作为该图像对的真实标签;
40.(1.3)将成对的剪裁后sar图像和对应的可见光图像中80%的图像对作为训练集,20%的图像对作为测试集。
41.步骤2.构建跨模态transformer匹配网络n1。
42.(2.1)构建包含相关图约束的segformer特征提取骨架:
43.本步骤的具体实现是对现有的segformer网络进行改进,该segformer网络包含4个transformer block和两个多层感知机mlp;每个transformer block中包含n个高效自注意力模块efficient self-attention和混合前馈神经网络mix-ffn的级联结构,以及最后的一个重叠块合并overlap patch merging模块。其中高效自注意力模块为带序列压缩的自注意力模块,该模块计算输入特征的注意力分数;混合前馈神经网络mix-ffn为带有零填充的卷积核大小为3的卷积前馈神经网络;重叠块合并模块为卷积核为7、零填充为4、步长为2的卷积层。网络接收输入后经过每个transformer block,对各个图像块的特征进行合并得到transformer block的输出;通过第一个多层感知机对多个不同分辨率的transformer block的输出特征进行融合得到融合后的特征,再将融合后的特征输入第二个多层感知机得到该segformer的最终输出特征。
44.参照图2,本步骤对现有的segformer网络的改进是在其中加入相关图约束,具体实现如下:
45.(2.1.1)对现有的segformer网络中第1个、第3个transformer block输出sar图像特征和可见光图像特征分别计算其各自的互相关矩阵cor1和cor3;
46.(2.1.2)分别构建两个尺寸为和的零矩阵和作为初始的第一相关图和第二相关图;
47.(2.1.3)对第一相关图和第二相关图分别进行迭代,得到各自最终的相关图:
48.设对迭代的总迭代次数为cor1中的元素个数,每轮迭代不重复地从cor1中选取一个点(x,y)得到本轮迭代的修改范围将中修改范围内的值修改为与cor1(x,y)之间的最大值,迭代结束得到最终的第一相关图其中,cor1(x,y)为cor1在点(x,y)处的值;
49.设对迭代的总迭代次数为cor3中的元素个数,每轮迭代不重复地从cor3中选取一个点(x,y)得到本轮迭代的修改范围将中修改范围内的值修改为与cor3(x,y)之间的最大值,迭代结束得到最终的第二相关图其中,cor3(x,y)为cor3在点(x,y)处的值;
50.(2.1.4)将最终的第一相关图与第1个transformer block输出的可见光图像
特征相乘作为第2个transformer block的输入,将最终的第二相关图与第3个transformer block输出的可见光图像特征相乘作为第4个transformer block的输入,完成相关图约束的添加,得到包含相关图约束的segformer特征提取骨架;
51.(2.2)构建包含跨模态交叉注意力的transformer网络n0:
52.参照图3,本步骤建立包含跨模态交叉注意力的transformer网络,是通过对现有segformer网络的改进建立,具体实现如下:
53.(2.2.1)将现有segformer网络中的第3、第4个transformer block去除;
54.(2.2.2)交换第1个transformer block中的可见光图像特征查询和sar图像特征查询
55.(2.2.3)交换第2个transformer block中的可见光图像特征查询和sar图像特征查询得到包含跨模态交叉注意力的transformer网络n0;
56.(2.3)将包含相关图约束的segformer特征提取骨架与跨模态交叉注意力的transformer网络n0依次级联,得到跨模态transformer匹配网络n1。
57.步骤3.利用训练数据和最优传输理论,使用adam算法对网络n1进行迭代训练得到训练好的匹配网络n2。
58.(3.1)选择训练集中的一对sar图像和可见光图像,依次将sar图像和可见光图像输入到步骤2中构建的跨模态transformer匹配网络n1,得到sar图像特征图fs和可见光图像特征图fo;
59.(3.2)对sar图像特征图fs和可见光图像特征图fo计算相似性矩阵m:
[0060][0061]
其中t表示矩阵的转置,|| ||表示取模;
[0062]
(3.3)根据训练集sar图像特征和可见光图像特征的相似性矩阵m使用最优传输计算其最优匹配概率c
*
:
[0063]
(3.3.1)设置一个矩阵c作为sar图像到可见光图像的匹配概率;
[0064]
(3.3.2)为了避免平凡解,将跨模态交叉注意力的transformer匹配网络第二个tranformer block输出sar图像特征和可见光图像特征的类激活图cam分别作为最优传输的约束条件μ
sar
和μ
opt
;
[0065]
(3.3.3)通过sinkhorn-knopp算法求解如下最优传输问题,得到训练集sar图像和可见光图像的最优匹配概率c
*
:
[0066][0067]
其中,c
ij
为矩阵c在(i,j)处的值,m
ij
代表矩阵m在(i,j)处的值,hs,ws分别表示sar图像特征的高度和宽度,ho,wo分别表示可见光图像特征的高度和宽度;表示大小为h
sws
的单位列向量;表示大小为howo的单位列向量;表示矩阵c每行的和,表示矩阵c每列的和,t表示矩阵的转置;
[0068]
(3.4)将(3.3.3)得到的最优匹配概率c
*
与(3.2)得到的相似性矩阵m相乘得到优化后的训练集相似性度量矩阵m
opt
:
[0069]mopt
=c
*
⊙m[0070]
其中,
⊙
表示矩阵中对应位置的元素相乘;
[0071]
(3.5)将m
opt
中最大值点的坐标作为匹配点并计算匹配点与真实标签之间的损失函数loss:
[0072][0073]
其中,(x
t
,y
t
)是真实标签坐标;
[0074]
(3.6)重复(3.1)~(3.5),根据每次迭代的损失函数值更新网络各层的参数,直到达到设定的迭代次数e=300,得到训练好的跨模态transformer匹配网络n2。
[0075]
步骤4.利用最优传输理论和训练好的匹配网络n2对测试集的图像对进行匹配。
[0076]
(4.1)将测试集中的sar图像和可见光图像输入到训练好的匹配网络n2中,得到测试图像对的sar图像特征fs′
和可见光图像特征fo′
;
[0077]
(4.2)计算测试图像对输出特征的相似性矩阵m
′
:
[0078][0079]
其中,t表示矩阵的转置,|| ||表示取模;
[0080]
(4.3)根据测试图像对输出特征的相似性矩阵m
′
,利用最优传输计算测试图像对最优匹配概率c
*
′
:
[0081]
(4.3.1)设置一个矩阵c
′
作为测试集sar图像与可见光图像的匹配概率;
[0082]
(4.3.2)将跨模态交叉注意力的transformer匹配网络第二个tranformer block输出sar图像特征和可见光图像特征的类激活图cam分别作为测试图像最优传输的约束条件μ
′
sar
和μ
′
opt
;
[0083]
(4.3.3)通过sinkhorn-knopp算法求解如下问题,得到测试图像的最优匹配概率c
*
′
:
[0084][0085]
其中,c
′
ij
为矩阵c
′
在(i,j)处的值,m
′
ij
代表矩阵m
′
在(i,j)处的值,h
′s,w
′s分别表示测试集sar图像特征的高度和宽度,h
′o,w
′o分别表示测试集可见光图像特征的高度和宽度;表示大小为h
′
sw′s的单位列向量;表示大小为h
′ow
′o的单位列向量;表示矩阵c
′
每行的和,表示矩阵c
′
每列的和,t表示矩阵的转置;
[0086]
(4.4)将测试图像最优匹配概率c
*
′
与其相似性矩阵m
′
相乘,得到优化后的相似性
度量矩阵m
′
opt
:
[0087]m′
opt
=c
*
′⊙m′
[0088]
其中,
⊙
表示矩阵中对应位置的元素相乘;
[0089]
(4.5)将m
′
opt
中最大值点的坐标作为匹配点该点即为测试集中sar图像在可见光图像中的对应匹配位置,完成异源图像的匹配。
[0090]
本发明的效果可通过以下实验进一步说明:
[0091]
1.实验条件
[0092]
本实验使用的服务器配置为3.2ghz的intel core i7-9700k cpu和一张12-gb的nvidia geforce rtx2080ti gpu,使用pytorch 1.5.1代码框架实现深度网络模型,编程开发语言为python 3.7。
[0093]
实验用到的数据集为开源数据集os dataset,包括1300对异源图像和其标签,sar图像的尺寸为256
×
256,sar图像采集自中国多极化c波段sar卫星高分3号,分辨率为1米。可见光图像的尺寸为512
×
512,图像采集自谷歌地球平台,并重新采样至1米分辨率;
[0094]
本实例将80%的图像作为训练集,20%图像作为测试集,实验在测试集上的受试者误差小于等于5个像素的匹配准确率、正确匹配图像的平均误差、所有图像的平均误差和匹配时间;
[0095]
实验使用的对比方法有八种,分别是归一化互相关算法ncc,归一化互信息算法nmi,定向梯度的通道特征算法cfog,相位一致性直方图hopc,辐射变化不敏感特征变换算法rift,伪孪生卷积神经网络算法psiam,基于视觉显著性特征的深度匹配网络vsmatch以及分步级联匹配网络scmnet。
[0096]
2.实验内容
[0097]
实验一,在上述实验条件下,使用本发明和现有八种ncc,nmi,hopc,cfog,rift,psiam,vsmatch,scmnet算法,对上述测试集中一对城市区域的sar图像和可见光图像进行匹配,结果如图4所示,其中:
[0098]
图4(a)为sar图像模板,
[0099]
图4(b)为真实标签,
[0100]
图4(c)为ncc算法的匹配结果,
[0101]
图4(d)为nmi算法的匹配结果,
[0102]
图4(e)为hopc算法的匹配结果,
[0103]
图4(f)为cfog算法的匹配结果,
[0104]
图4(g)为可见光图像,
[0105]
图4(h)为rift算法的匹配结果,
[0106]
图4(i)为psiam算法的匹配结果,
[0107]
图4(j)为vsmatch算法的匹配结果,
[0108]
图4(k)为scmnet算法的匹配结果,
[0109]
图4(l)为本发明方法的匹配结果。
[0110]
每幅图中的实线正方形框为真实的匹配位置,虚线正方形框为各个方法得到的预测匹配位置,当虚线预测框的位置越接近实线框真实匹配位置,则该算法的匹配效果越好。
[0111]
从图4的结果可以看出,对比方法的预测位置与真实位置相比都有所偏移,而本方
法对应的图4(l)在局部特征差异较小的城市区域,预测位置和真实位置完全重合,表明本发明能够在相似的地物场景中实现精确的匹配。
[0112]
实验二,在上述实验条件下,使用本发明和现有八种ncc,nmi,hopc,cfog,rift,psiam,vsmatch,scmnet算法,对上述测试集中一对机场区域的sar图像和可见光图像进行匹配,结果如图5所示,其中:
[0113]
图5(a)为sar图像模板,
[0114]
图5(b)为真实标签,
[0115]
图5(c)为ncc算法的匹配结果,
[0116]
图5(d)为nmi算法的匹配结果,
[0117]
图5(e)为hopc算法的匹配结果,
[0118]
图5(f)为cfog算法的匹配结果,
[0119]
图5(g)为可见光图像,
[0120]
图5(h)为rift算法的匹配结果,
[0121]
图5(i)为psiam算法的匹配结果,
[0122]
图5(j)为vsmatch算法的匹配结果,
[0123]
图5(k)为scmnet算法的匹配结果,
[0124]
图5(l)为本发明提出算法的匹配结果。
[0125]
每幅图中的实线正方形框为真实的匹配位置,虚线正方形框为各个方法得到的预测匹配位置,当虚线预测框的位置越接近实线框真实匹配位置,则该算法的匹配效果越好。
[0126]
从图5的结果可以看出,实验图像中飞机的存在使得场景的局部特征差异较大,而且由于sar图像的成像方式使得飞机在sar图像中产生更多的相干斑噪声,使精确匹配更加困难,所有对比方法的匹配结果均出现了较大的误差,而本发明在此区域的预测位置与真实位置一致,实现了精确的匹配。
[0127]
实验三,将测试集中的sar图像和可见光图像进行匹配,根据所有匹配结果和标签计算其评价指标,结果如表1:
[0128]
表1本发明和现有8种方法的评价指标
[0129][0130]
由表1的结果可以看出,本发明在实验中准确率达到了81.67%,显著提高了异源图像匹配的准确率;相较于参与对比的同类深度学习匹配方法,本发明完成匹配所需时间有明显减少,大幅提高了匹配速度,且在实验中本发明正确匹配图像的平均误差和所有图像的平均误差均最低,提高了匹配的精度。
[0131]
综上,本发明构建的基于跨模态转换网络与最优传输理论的异源图像匹配方法,与现有的ncc,nmi,cfog,hopc,rift,psiam,vsmatch,scmnet算法相比,能够得到更好的匹配结果,结果具有更高的匹配准确率和更小的平均误差,匹配时间在同类基于深度学习的算法中处于领先地位,对不同类型地物场景的适应性良好,具有更强的泛化能力。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。