1.本发明属于自然语义处理中的情感分析领域,尤其涉及一种识别语句中方面类别和情感极性的方法和系统。
背景技术:
2.随着电商的兴起和普及,人们越来越倾向网购,并且愿意在网络上分享自己的使用心得和商品评价,这些评价数据逐渐成为了能够决定人们购买决策的重要参考来源,同时商品厂家也会根据这些评价和建议不断改进自己的产品和服务质量,希望能够在激烈的市场竞争中取得领先地位。然而,随着产品评论的爆发式增长,用户很难充分使用这些海量信息。因此,面向方面的情感分析(absa)应运而生,该任务包括两个方面,第一识别出评论句子的方面类别,我们称作acd任务;第二对识别出的方面类别进行情感极性分类,称为sa任务。
3.现有的面向方面的情感分析方法中,仅将评论语句视为一个方面类别然后进行情感极性识别。例如对于“这个手机屏幕不错”的评价,由于只有一个方面类别“手机屏幕”,现有的方法能够正确识别出该评价的情感极性为“正面”。然而对于多个方面类别的评论如“这个手机屏幕不错,但电池不耐用”,现有的方法就容易出现情感极性识别错误。
技术实现要素:
4.有鉴于此,本发明提供一种语句中方面类别及情感极性联合识别的方法及系统,通过增加方面类别预测功能对语句包含的方面类别个数进行预测,降低在进行情感极性检测的时候出错的可能性。
5.为解决以上技术问题,本发明的技术方案为采用一种语句中方面类别及情感极性联合识别的方法,包括:获取训练语句的双向隐状态;获取预测的方面类别在当前时间步的隐状态,每个时间步仅输出一个方面类别;把训练语句的双向隐状态转换成训练语句方面类别数量的高阶表示向量,并通过训练语句的高阶表示向量预测训练语句仅包含一个方面类别的概率;将方面类别数量的高阶表示向量、当前时间步的隐状态、之前所有时间步隐状态的平均值进行聚合获得聚合值,利用聚合值以及方面类别数量的高阶表示向量获得训练语句的若干混合特征;利用混合特征预测训练语句当前步长的方面类别以及方面类别的情感极性。
6.作为一种改进,所述获取训练语句的双向隐藏状态的方法为:从正反两个方向读取训练语句的文本序列,获取训练语句中每个单词正反两个方向的隐状态;将每个单词正反两个方向的隐状态分别进行拼接获得每个单词的双向隐状态;将训练语句中所有单词的双向隐状态进行拼接从而获得整个训练语句的双向隐
状态。
7.作为一种改进,通过门控循环单元利用预测的前一个时间步的方面类别获取当前步长方面类别的隐状态。
8.作为一种改进,利用函数计算预测训练语句仅包含一个方面类别的概率,其中为概率,v为高阶表示向量,wv为概率预测权重矩阵,b为偏置,为sigmod函数。
9.作为一种改进,利用全连接层i预测训练语句的方面类别,其中为预测的当前步长t的方面类别,wa方面类别预测权重矩阵,u
t
为混合特征;利用全连接层ii预测当前方面类别的情感极性,其中为预测的方面类别的情感极性,ws为情感极性预测权重矩阵,u
t
为混合特征。
10.作为一种改进,利用预测的当前步长的方面类别和情感极性与真实的方面类别和情感极性对比,对权重矩阵中的参数进行优化。
11.作为一种改进,在获取训练语句的双向隐状态之后,对训练语句的方面类别进行排序;在训练语句的前后分别加上《bos》和《eos》符号用于标示一个训练语句的开始和结束。
12.本发明还提供一种语句中方面类别及情感极性联合识别的系统,包括:编码模块,用于获取整个训练语句的双向隐状态;解码模块,用于获取预测的方面类别在当前时间步的隐状态,每个时间步仅输出一个方面类别;方面个数预测模块,用于双向隐状态转换成训练语句方面类别数量的高阶表示向量,并通过训练语句的高阶表示向量预测训练语句仅包含一个方面类别的概率;方面类别及情感极性检测模块,用于将方面类别数量的高阶表示向量、当前预测的方面类别在当前时间步的隐状态、之前所有时间步隐状态的平均值进行聚合获得聚合值,利用聚合值以及方面类别数量的高阶表示向量获得训练语句的若干混合特征,通过混合特征预测当前步长的方面类别以及当前方面类别的情感极性。
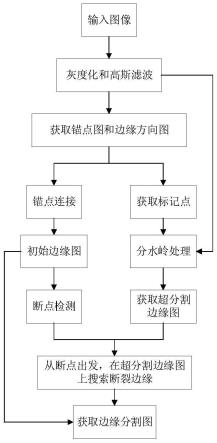
13.作为一种改进,所述编码模块包括:隐状态获取模块,用于从正反两个方向读取训练语句序列并输出每个单词正反两个方向的隐状态;隐状态拼接模块,用于将每个单词正反两个方向的隐状态分别进行拼接获得每个单词的双向隐状态,并将所有单词的双向隐状态拼接为整个训练语句的双向隐状态。
14.作为一种改进,所述解码模块包括:当前时间步隐状态获取模块,用于通过门控循环单元利用预测的前一个时间步的方面类别获取当前步长方面类别的隐状态。
15.作为一种改进,所述方面个数预测模块包括:高阶表示向量获取模块,用于计算训练语句方面类别数量的高阶表示向量;单个方面类别概率预测模块,用于利用函数计算预测训练语句仅包含一个方面类别的概率,其中为概率,v为高阶表示向量,wv为概率预测权重矩阵,b为偏置,为sigmod函数。
16.作为一种改进,所述方面类别及情感极性检测模块包括:聚合值获取模块,用于将方面类别数量的高阶表示向量、当前预测的方面类别在当前时间步的隐状态、之前所有时间步隐状态的平均值进行聚合获得聚合值;混合特征获取模块,用于利用聚合值以及方面类别数量的高阶表示向量获得训练语句的若干混合特征;方面类别预测模块,用于利用全连接层i预测当前时间步的方面类别,其中为预测的当前步长t的方面类别,wa为方面类别预测权重矩阵,u
t
为混合特征;情感极性预测模块,用于利用全连接层ii当前时间步的预测情感极性,其中为预测的方面类别的情感极性,ws为情感极性预测权重矩阵,u
t
为混合特征。
17.作为一种改进,还包括:优化模块,用于利用预测的当前步长的方面类别和情感极性与真实的方面类别和情感极性对比,对系统进行优化。
18.本发明的有益之处在于:本发明在现有的面向方面的情感分析方法的基础上,新增了方面类别个数预测功能用于预测语句中方面类别的个数。并在方面类别及情感极性检测过程中对每个方面类别进行预测同时预测每个方面类别所对应的情感极性,最大限度的避免了由于同一语句中出现多个方面类别及情感极性倒置的预测错误。
附图说明
19.图1为本发明的流程图。
20.图2为本发明的结构原理图。
具体实施方式
21.为了使本领域的技术人员更好地理解本发明的技术方案,下面结合具体实施方式对本发明作进一步的详细说明。
22.如背景技术所言,现有的面向方面的情感分析方法可实现方面类别以及对应的情感极性的预测。所谓方面类别是指评价语句中谈及的内容,而情感极性是指涉及方面类别的正面positive、负面negative或中性neutral的情感表达。
23.一般来说,绝大多数评论语句中仅包含一个方面类别以及对该方面类别的情绪表达,例如“这个手机屏幕不错”。其中“手机”为实体,“屏幕”为方面类别,“不错”为正面的情感极性。对于此类评论语句,现有的预测方法可以较为准确的进行预测。
24.然而在某些评价语句如“这个手机屏幕不错,但电池不耐用”中,
““
屏幕”和“电池”为方面类别,而“不错”和“不耐用”所表征的情感极性分别为“正面”和“负面”。该评论中两个方面类别分别表达了两种不同的情绪。由于现有的预测方法对于评论语句中方面类别的数量不得而知,因此最终预测的结果很有可能出错。
25.针对现有技术的上述缺陷,本发明提供一种语句中方面类别及情感极性联合识别的方法,该方法构建并训练优化了一种神经网络模型,包括编码器encoder、解码器decoder、方面个数预测器aspect quantity detector以及方面类别及情感检测器aspect category detector。通过该模型可实现对包含多种方面类别的评论语句进行预测,如图1所示,具体包括以下步骤:s1将训练集中的训练语句输入模型中的编码器,利用编码器从正反两个方向读取训练语句的文本序列,获取训练语句中每个单词正反两个方向的隐状态,并将每个单词正反两个方向的隐状态分别进行拼接获得每个单词的双向隐状态,从而获得整个训练语句的双向隐状态。
26.在训练集输入编码器之前,可对其进行预处理,按照特定的顺序对训练语句的方面类别进行排序;该顺序可根据实际情况确定如自然语序、出现频次等等。
27.假设一条训练语句的表达如下:其中,x为训练语句,为训练语句x中第i个单词的数字向量,u1为词嵌入的维数,n为句子长度。为编码器的输入。
28.为了结合前后文信息来准确预测方面类别,可使用双向门控循环单元(bi-gru)从两个方向读取训练语句的序列,输出每个单词的隐状态,具体为利用函数从正方向,利用函数从反方向读取训练语句序列并输出每个单词正反两个方向的隐状态;然后利用函数
将每个单词正方向的隐状态和反方向的隐状态分别进行拼接获得每个单词的双向隐状态hi,其长度为 2u2。最后,得到整个训练语句的隐状态,定义如下:。
29.其中为正方向隐状态,wi为单词的数字向量,hi为单词的双向隐状态i=1~n,h
i-1
为前一个单词的双向隐状态;为反方向隐状态,h
i 1
为后一个单词的双向隐状态,h为整个句子的双向隐状态。
30.h包含了输入句子的高维特征,用于预测训练语句包含的方面类别的数量。在获得训练语句的双向隐状态后,在训练语句的双向隐状态前后分别加上《bos》和《eos》符号用于标示一个训练语句的开始和结束。
31.s2利用模型中的解码器获取预测的方面类别在当前时间步的隐状态,每个时间步仅输出一个方面类别;解码器是由门控制机制gru实现的,具体为利用函数获取预测的方面类别在当前时间步的隐状态。需要注意的是,解码器的第一个时间步的输入是s0=w0hn,其中h0是编码器获取的最后一个单词的双向隐状态,w0为权重矩阵。其中s
t
为当前步长t的隐状态,s
t-1
为前一个时间步的隐状态;为预测的方面类别的数字向量,代表预测的时间步t-1的方面类别。
32.s3利用模型中的方面个数预测器把训练语句的双向隐状态转换成训练语句方面类别数量的高阶表示向量,并通过训练语句的高阶表示向量预测训练语句仅包含一个方面类别的概率,具体包括:把编码器输出的训练语句的双向隐状态h输入到方面个数预测器中,利用函数计算训练语句方面类别数量的高阶表示向量,其中v为高阶表示向量,h为训练语句的双向隐状态,w
cls
为高阶标示向量权重矩阵;然后把v输入一个全连接层(full chain layer也称全连接层),利用函数计算预测训练语句仅包含一个方面类别的概率,其中为概率,v为高阶表示向量,wv为概率预测权重矩阵,b为偏置,为sigmod函数。
33.另外,当预测器读取到一个《eos》符号后就立即停止对该训练语句的双向隐状态的预测,然后输出将该训练语句的方面类别数量标记为一个,避免重复预测,减小了系统开
销。
34.s4利用模型中的方面类别及情感极性检测器将方面类别数量的高阶表示向量、当前时间步的隐状态、之前所有时间步隐状态的平均值进行聚合获得聚合值,利用聚合值以及方面类别数量的高阶表示向量获得训练语句的若干混合特征,所述混合特征的数量为预测的方面类别的数量;将混合特征输入到方面类别及情感极性检测器的全连接层i预测当前步长的方面类别,将混合特征输入到方面类别及情感极性检测器的全连接层ii预测当前方面类别的情感极性,具体包括:把解码器输出的当前时间步的隐状态、之前所有时间步的隐状态以及方面个数预测器输出的方面类别数量的高阶表示向量利用函数通过门控制机制进行聚合获得聚合值;利用函数计算前t-1个时间步隐状态的和的平均值;然后利用函数计算混合特征,其中u
t
为混合特征,为点乘,gi为聚合值,wg为权重矩阵,s
t
为预测的方面类别在当前时间步t的隐状态,s
avg
为前t-1个时间步隐状态的和的平均值,v为方面类别数量的高阶表示向量;混合特征ut是利用gi对s
t
和v的优化组合自动确定各维度的组合因子。方面类别及情感检测器从v获取并输出与方面个数预测器预测的方面类别个数相应的若干个混合特征ut。
35.将获得的若干个混合特征ut输入到全连接层i中预测每个方面类别的具体类型,所述全连接层i为其中为预测的当前步长t的方面类别,wa为方面类别预测权重矩阵,u
t
为混合特征;将获得的若干个混合特征ut输入到全连接层ii中预测当前方面类别的情感极性,所述全连接层ii为其中为预测的方面类别的情感极性,ws为情感极性预测权重矩阵,u
t
为混合特征。
36.s5利用预测的当前步长的方面类别和情感极性与真实的方面类别和情感极性对
比,对模型进行优化。
37.在模型的训练过程中,需要把预测值与真实值比较,然后通过调整各个权重矩阵中的参数对模型进行优化,最终使得预测值和真实值接近。由于方面个数预测器的作用是预测一条评论语句是否仅含一个方面类别或者多个方面类别,因此可把这种预测看作是一个二分类任务,利用函数对方面个数预测器进行优化,其中l1为损失函数,为预测的训练语句仅含一个方面类别的概率,n为训练集子集的大小,pn为真实的训练语句仅含一个方面类别的概率。
38.另外,还可以利用函数另外,还可以利用函数对方面类别及情感极性检测器进行优化,其中l2和l3为损失函数,m是方面类别的最大个数,n是训练集子集的大小,是预测出的第n条训练语句的第m个方面类别的概率,是真实的的第n条语句的第m个方面类别的概率。是预测出的第n条训练语句的第m个方面类别的情感极性的概率,是真实的第n条训练语句的第m个方面类别的情感极性的概率。
39.然后利用函数将损失函数l1、l2、l3最小化,其中l为最小化损失函数,超参数。
40.s6模型优化完毕后,将需要识别的目标语句输入模型进行识别。
41.通过重复步骤s1~s5对模型进行不断的优化,使得预测值与真是值接近或者相等。优化完毕后,只需要将需要识别的评价即目标语句输入模型进行识别即可。
42.如图2所示,本发明还一种语句中方面类别及情感极性联合识别的系统,包括:编码模块,用于从正反两个方向读取训练语句的文本序列,获取训练语句中每个单词正反两个方向的隐状态,并将每个单词正反两个方向的隐状态分别进行拼接获得每个单词的双向隐状态,从而获得整个训练语句的双向隐状态;具体包括:隐状态获取模块,用于利用函数和
从正反两个方向读取训练语句序列并输出每个单词正反两个方向的隐状态;隐状态拼接模块,用于利用函数将每个单词正反两个方向的隐状态分别进行拼接获得每个单词的双向隐状态,其中为正方向隐状态,wi为单词的数字向量,hi为单词的双向隐状态,h
i-1
为前一个单词的双向隐状态;为反方向隐状态,h
i 1
为后一个单词的双向隐状态;利用函数将所有单词的双向隐状态拼接为整个训练语句的双向隐状态。
43.解码模块,用于获取当前时间步的隐状态,每个时间步仅输出一个方面类别;通过训练语句的高阶表示向量预测训练语句仅包含一个方面类别的概率,具体包括:当前时间步隐状态获取模块,用于利用函数获取预测的方面类别在当前时间步的隐状态,其中s
t
为预测的方面类别在当前步长t的隐状态,s
t-1
为前一个时间步的隐状态;为预测的方面类别的数字向量,代表预测的时间步t-1的方面类别。
44.方面个数预测模块,用于把训练语句的双向隐状态转换成训练语句方面类别数量的高阶表示向量,并通过训练语句的高阶表示向量预测训练语句仅包含一个方面类别的概率,具体包括:高阶表示向量获取模块,用于利用函数计算训练语句方面类别数量的高阶表示向量,其中v为高阶表示向量,h为训练语句的双向隐状态,w
cls
为高阶标示向量权重矩阵;单个方面类别概率预测模块,用于利用函数计算预测训练语句仅包含一个方面类别的概率,其中为概率,v为高阶表示向量,wv为概率预测权重矩阵,b为偏置,为sigmod函数。
45.方面类别及情感极性检测模块,用于将方面类别数量的高阶表示向量、预测的方面类别在当前时间步的隐状态、之前所有时间步隐状态的平均值进行聚合获得聚合值,利用聚合值以及方面类别数量的高阶表示向量获得训练语句的若干混合特征,所述混合特征的数量为预测的方面类别的数量;通过混合特征预测当前步长的方面类别以及当前方面类别的情感极性,具体包括:
聚合值获取模块,用于利用函数获得聚合值;利用函数计算前t-1个时间步隐状态的和的平均值;混合特征获取模块,用于利用函数计算混合特征,其中u
t
为混合特征,为点乘,gi为聚合值,wg为权重矩阵,s
t
为预测的方面类别在当前时间步t的隐状态,s
avg
为前t-1个时间步隐状态的和的平均值,v为方面类别数量的高阶表示向量;方面类别预测模块,用于利用全连接层i预测当前时间步的方面类别,其中为预测的当前步长t的方面类别,wa为方面类别预测权重矩阵,u
t
为混合特征;情感极性预测模块,用于利用全连接层ii当前时间步的预测情感极性,其中为预测的方面类别的情感极性,ws为情感极性预测权重矩阵,u
t
为混合特征。
46.优化模块,用于利用预测的当前步长的方面类别和情感极性与真实的方面类别和情感极性对比,对系统进行优化,具体包括:方面个数预测优化模块,用于利用函数对方面个数预测进行优化,其中l1为损失函数,为预测的训练语句仅含一个方面类别的概率,n为训练集子集的大小,pn为真实的训练语句仅含一个方面类别的概率;方面类别及情感极性检测优化模块,利用函数
对方面类别及情感极性检测进行优化,其中l2和l3为损失函数,m是方面类别的最大个数,n是训练集子集的大小,是预测出的第n条训练语句的第m个方面类别的概率,是真实的的第n条语句的第m个方面类别的概率。是预测出的第n条训练语句的第m个方面类别的情感极性的概率,是真实的第n条训练语句的第m个方面类别的情感极性的概率;损失函数最小化模块,用于利用函数将损失函数l1、l2、l3最小化,其中l为最小化损失函数,超参数。
47.以上仅是本发明的优选实施方式,应当指出的是,上述优选实施方式不应视为对本发明的限制,本发明的保护范围应当以权利要求所限定的范围为准。对于本技术领域的普通技术人员来说,在不脱离本发明的精神和范围内,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。