1.本发明涉及机器翻译技术领域,尤其涉及一种基于后编辑译文的多任务机器翻译质量估计方法和系统。
背景技术:
2.机器翻译又称为自动翻译,是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。为了评估机器输出的翻译译文质量,需要对翻译译文进行翻译质量评估。
3.翻译质量估计是一种对于翻译译文进行评估的技术。传统的翻译译文估计大多属于人工翻译质量估计,人工翻译质量估计需要借助人工译文来作为参考译文,从而对于机器翻译的译文进行打分。然而,人工评估耗时长且主观性强,是最传统也是代价最高的翻译质量估计方法。为了解决人工翻译质量估计的问题,现有的翻译质量估计的最新技术大多采用机器翻译质量估计的方式,机器翻译质量估计是在无参考译文的情况下对机器翻译译文进行效果评估的一种技术。机器翻译质量估计在仅使用源语言和机器翻译译文的情况下,即可对译文的质量进行评估,因此在实际应用中具有更广泛的应用场景。
4.现阶段的机器翻译质量估计技术中,多任务联合训练是一种常用的质量估计方式,但目前的多任务联合训练方式,普遍采用句子级别任务和词级别任务联合训练的多任务联合训练方法。因为该多任务联合训练方法需要采用额外引入词汇级翻译质量估计,通过构成多任务训练完成模型建模。然而词汇级翻译质量估计需要对机器译文和后编辑译文之间词汇进行翻译质量标记,这就造成了词汇级翻译质量估计样本的构造成本增加,也导致词汇级翻译质量估计数据的处理量较大并且过程复杂,进而导致机器翻译质量估计的性能降低。
技术实现要素:
5.本发明提供一种基于分布式块存储的副本数据恢复方法和系统,旨在解决现有技术中句子级别任务和词级别任务联合训练的多任务联合训练方法,需要对机器译文和后编辑译文之间词汇进行翻译质量标记,造成样本的构造成本过高,数据的处理量过大,机器翻译质量估计的性能较低的问题。
6.为实现上述目的,根据本发明的第一方面,本发明提出了一种基于后编辑译文的多任务机器翻译质量估计方法,包括:
7.使用跨语言预训练mbart模型作为基础框架,执行包括句子级翻译质量估计任务和基于后编辑译文任务的多任务联合训练,得到总体损失函数收敛的mbart模型;
8.将原文和机器译文分别输入至总体损失函数收敛的mbart模型的编码器和解码器,预测得到机器译文的hter分数。
9.优选的,上述多任务机器翻译质量估计方法中,使用跨语言预训练mbart模型作为基础框架,执行包括句子级翻译质量估计任务和基于后编辑译文任务的多任务联合训练的
步骤,包括:
10.将原文输入至mbart模型的编码器,将机器译文输入至mbart模型的解码器,得到句子级翻译质量估计任务对应的第一隐向量;
11.使用第一隐向量训练mbart模型,得到句子级翻译质量估计任务对应的第一损失子函数;
12.以及,
13.将原文输入至mbart模型的编码器,将右移一位的后编辑译文输入至mbart模型的解码器,得到基于后编辑译文任务对应的第二隐向量;
14.使用第二隐向量训练mbart模型,得到基于后编辑译文任务对应的第二损失子函数;
15.对第一损失子函数和第二损失子函数进行加权计算,得到总体损失函数;
16.以总体损失函数收敛为目标,训练mbart模型。
17.优选的,上述多任务机器翻译质量估计方法中,使用第一隐向量训练mbart模型,得到句子级翻译质量估计任务对应的第一损失子函数的步骤包括:
18.将第一隐向量输入至mbart模型的全连接层,提取得到机器译文特征;
19.根据机器译文特征获取hter分数预测值,将hter分数预测值和hter分数真实值输入至均方误差函数,得到第一损失子函数。
20.优选的,上述多任务机器翻译质量估计方法中,根据机器译文特征获取hter分数预测值,将hter分数预测值和hter分数真实值输入至均方误差函数的步骤包括:
21.使用sigmoid函数作为mbart模型的激活函数,将机器译文特征输入至mbart模型的激活函数,得到hter分数预测值;
22.将hter分数预测值和hter分数真实值输入至均方误差函数,得到第一损失子函数。
23.优选的,上述多任务机器翻译质量估计方法中,将原文输入至mbart模型的编码器,将右移一位的后编辑译文输入至mbart模型的解码器,得到基于后编辑译文任务对应的第二隐向量的步骤包括:
24.将原文输入至mbart模型的编码器;
25.将右移一位的后编辑译文输入至mbart模型的解码器;
26.在解码器中,使用后编辑译文的前n项词预测第n 1项词,得到完整的后编辑译文;
27.从解码器的隐状态中分别获取完整的后编辑译文中每个词对应的第二隐向量。
28.优选的,上述多任务机器翻译质量估计方法中,使用第二隐向量训练mbart模型,得到基于后编辑译文任务对应的第二损失子函数的步骤包括:
29.将第二隐向量输入至mbart模型的全连接层,提取得到后编辑译文特征;
30.使用softmax分类器对后编辑译文特征进行分类,得到后编辑译文中每个词分别对应的词表维度向量;
31.将每个词分别对应的词表维度向量输入至交叉熵损失函数,使用交叉熵损失函数计算后编辑译文任务对应的第二损失子函数。
32.优选的,上述多任务机器翻译质量估计方法中,将原文和机器译文分别输入至总体损失函数收敛的mbart模型的编码器和解码器,预测得到机器译文的hter分数的步骤包
括:
33.将原文输入至mbart模型的编码器,将机器译文输入至mbart模型的解码器,得到预测用隐向量;
34.将预测用隐向量输入至mbart模型的全连接层,提取得到预测用隐向量对应的机器译文特征;
35.将机器译文特征输入至mbart模型的激活函数,得到机器译文的hter分数。
36.根据本发明的第二方面,本发明还提供了一种基于后编辑译文的多任务机器翻译质量估计系统,包括:
37.联合训练执行模块,用于使用跨语言预训练mbart模型作为基础框架,执行包括句子级翻译质量估计任务和基于后编辑译文任务的多任务联合训练,得到总体损失函数收敛的mbart模型;
38.翻译质量预测模块,用于将原文和机器译文分别输入至总体损失函数收敛的mbart模型的编码器和解码器,预测得到机器译文的hter分数。
39.优选的,多任务机器翻译质量估计系统中,联合训练执行模块包括:
40.第一隐向量输出子模块,用于将原文输入至mbart模型的编码器,将机器译文输入至mbart模型的解码器,输出得到句子级翻译质量估计任务对应的第一隐向量;
41.第一损失子函数计算子模块,用于使用第一隐向量训练mbart模型,得到句子级翻译质量估计任务对应的第一损失子函数;
42.以及,
43.第二隐向量输出子模块,用于将原文输入至mbart模型的编码器,将右移一位的后编辑译文输入至mbart模型的解码器,输出得到基于后编辑译文任务对应的第二隐向量;
44.第二损失子函数计算子模块,用于使用第二隐向量训练mbart模型,得到基于后编辑译文任务对应的第二损失子函数;
45.总体损失函数计算子模块,用于对第一损失子函数和第二损失子函数进行加权计算,得到总体损失函数;
46.模型训练子模块,用于以总体损失函数收敛为目标,训练mbart模型。
47.优选的,上述多任务机器翻译质量估计系统中,翻译质量预测模块包括:
48.预测用隐向量输出子模块,用于将原文输入至mbart模型的编码器,将机器译文输入至mbart模型的解码器,输出得到预测用隐向量;
49.机器译文特征提取子模块,用于将预测用隐向量输入至mbart模型的全连接层,提取得到预测用隐向量对应的机器译文特征;
50.分数计算子模块,用于将机器译文特征输入至mbart模型的激活函数,得到机器译文的hter分数。
51.综上,本发明上述技术方案提供的多任务机器翻译质量估计方案,通过使用跨语言预训练mbart模型作为基础框架,该mbart模型基于编码器-解码器结构,其解码器共享参数,这样使用该mbart模型作为基础框架执行句子级翻译质量估计任务和基于后编辑译文任务的多任务联合训练,能够将句子级pe数据(即后编辑译文)作为辅助任务来进行多任务建模,相较于其他多任务联合训练方法,本方案能够只使用句子级的数据完成整个mbart模型的训练,得到总体损失函数收敛的mbart模型。使用该总体损失函数收敛的mbart模型输
入原文和机器译文,输出用于机器翻译质量估计的hter分数,就能够在句子级别进行翻译质量评估。通过上述方案避免了现有技术中额外的词汇级翻译质量估计带来的样本构造成本过高,数据处理量大的问题,从而提高了句子级翻译质量估计的性能,使得翻译质量的自动评估更为可靠。
附图说明
52.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
53.图1是本发明实施例提供的一种基于后编辑译文的多任务机器翻译质量估计方法的流程示意图;
54.图2是图1所示实施例提供的一种多任务联合训练方法的流程示意图;
55.图3是图2所示实施例提供的一种第一损失子函数的计算方法的流程示意图;
56.图4是图3所示实施例提供的一种均方误差函数的计算方法的流程示意图;
57.图5是图2所示实施例提供的一种第二隐向量的计算方法的流程示意图;
58.图6是图2所示实施例提供的一种第二损失子函数的计算方法的流程示意图;
59.图7是图1所示实施例提供的一种hter分数预测方法的流程示意图;
60.图8是本发明实施例提供的一种mbart模型的结构示意图;
61.图9是图8所示实施例提供的一种句子级翻译质量估计任务的结构示意图;
62.图10是图8所示实施例提供的一种基于后编辑译文任务的结构示意图;
63.图11是本发明实施例提供的一种基于后编辑译文的多任务机器翻译质量估计系统的结构示意图;
64.图12是图11所示实施例提供的一种联合训练执行模块的结构示意图;
65.图13是图11所示实施例提供的一种翻译质量预测模块的结构示意图。
66.本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
67.应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
68.本发明实施例的主要解决的技术问题是:
69.现有的多任务联合训练方式,普遍采用句子级别任务和词级别任务联合训练的多任务联合训练方法。因为该多任务联合训练方法需要额外引入词汇级翻译质量估计,通过构成多任务训练完成模型建模。然而词汇级翻译质量估计需要对机器译文和后编辑译文之间词汇进行翻译质量标记,这就造成了词汇级翻译质量估计样本的构造成本增加,也导致词汇级翻译质量估计数据的处理量较大并且过程复杂,进而导致机器翻译质量估计的性能降低。
70.为了解决上述问题,本发明下述实施例提供了基于编辑译文的多任务机器翻译质量估计方案,通过使用跨语言预训练mbart模型作为基础框架,该mbart模型基于编码器-解码器结构,其解码器的参数是共享的,这样使用该mbart模型作为基础框架执行句子级翻译
质量估计任务和基于后编辑译文任务的多任务联合训练,能够将句子级pe数据(即后编辑译文)作为辅助任务来进行多任务建模,相较于其他多任务联合训练方法,本方案能够只使用句子级的数据完成整个mbart模型的训练,在句子级别进行翻译质量评估。从而避免了现有技术中额外的词汇级翻译质量估计带来的样本构造成本过高,数据处理量大的问题,达到提高句子级翻译质量估计的性能,使得翻译质量的自动评估更为可靠的目的。
71.为实现上述目的,请参见图1,图1为本发明实施例提供的一种基于后编辑译文的多任务机器翻译质量估计方法的流程示意图。如图1所示,该基于后编辑译文的多任务机器翻译质量估计方法包括:
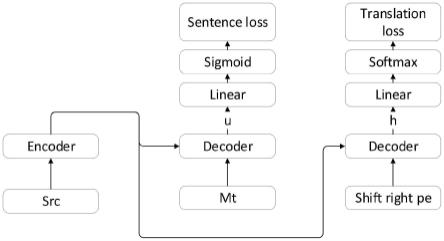
72.s110:使用跨语言预训练mbart模型作为基础框架,执行包括句子级翻译质量估计任务和基于后编辑译文任务的多任务联合训练,得到总体损失函数收敛的mbart模型。如图8所示,该跨语言预训练mbart模型基于编码器和解码器架构,其解码器共享参数,这样使用该mbart模型作为基础框架,能够共同处理句子级翻译质量估计任务和基于后编辑译文任务的多任务联合训练,从而使用后编辑译文作为辅助任务进行多任务建模,只需要使用句子级的数据就能够完成整个mbart模型的训练。其中,句子级翻译质量估计包括将原文输入至mbart模型的编码器,将机器译文输入至mbart模型的解码器,得到第一隐向量;基于后编辑译文包括将原文输入至mbart模型的编码器,将右移一位的后编辑译文输入至mbart模型的解码器,得到第二隐向量。
73.在得到上述第一隐向量和第二隐向量后,分别获取对应的损失函数,得到整个mbart模型的总体损失函数;以损失函数最小为目标(例如损失函数约等于0),训练所述mbart模型即可。
74.s120:将原文和机器译文分别输入至总体损失函数收敛的mbart模型的编码器和解码器,预测得到机器译文的hter分数。该hetr分数为模型的翻译编辑率,能够体现机器翻译质量的估计结果。将原文和机器译文输入至损失函数收敛的mbart模型后,就能够只使用句子级的数据完成翻译质量评估,避免了额外的词汇级翻译质量估计带来的样本构造成本过高,数据处理量过大的问题。将机器译文(mt)到后编辑译文(pe)的翻译任务作为辅助任务合理的加入到模型的训练中,能够避免额外的词汇级翻译质量估计的样本构造成本,提高了句子级翻译质量估计的性能。
75.综上,本发明上述实施例提供的多任务机器翻译质量估计方法,通过使用跨语言预训练mbart模型作为基础框架,该mbart模型基于编码器-解码器结构,其解码器共享参数,这样使用该mbart模型作为基础框架执行句子级翻译质量估计任务和基于后编辑译文任务的多任务联合训练,能够将句子级pe数据(即后编辑译文)作为辅助任务来进行多任务建模,相较于其他多任务联合训练方法,本方案能够只使用句子级的数据完成整个mbart模型的训练,得到总体损失函数收敛的mbart模型。使用该总体损失函数收敛的mbart模型输入原文和机器译文,输出用于机器翻译质量估计的hter分数,就能够在句子级别进行翻译质量评估。通过上述方案避免了现有技术中额外的词汇级翻译质量估计带来的样本构造成本过高,数据处理量大的问题,从而提高了句子级翻译质量估计的性能,使得翻译质量的自动评估更为可靠。
76.上述多任务联合训练的方式包括句子级翻译质量估计任务和基于后编辑问任务。其中,作为一种优选的实施例,如图2所示,上述步骤s110:使用跨语言预训练mbart模型作
为基础框架,执行包括句子级翻译质量估计任务和基于后编辑译文任务的多任务联合训练的步骤,包括:
77.s111:将原文输入至mbart模型的编码器,将机器译文输入至mbart模型的解码器,得到句子级翻译质量估计任务对应的第一隐向量。
78.s112:使用第一隐向量训练mbart模型,得到句子级翻译质量估计任务对应的第一损失子函数。
79.句子级翻译质量估计任务采用原文和机器译文作为训练数据,并分别作为编码器encoder和解码器decoder的输入得到对应的隐向量表示u;在解码器decoder端,将上述第一隐向量表示经由全连接层提取模型预测的hter分数,采用均方误差计算其与真实的hter分数对应的第一损失子函数。
80.以及基于后编辑译文任务,该任务具体步骤如下:
81.s113:将原文输入至mbart模型的编码器,将右移一位的后编辑译文输入至mbart模型的解码器,得到基于后编辑译文任务对应的第二隐向量。
82.s114:使用第二隐向量训练mbart模型,得到基于后编辑译文任务对应的第二损失子函数。
83.其中,基于后编辑译文的子任务,该任务在编码器encoder端输入的原文,在解码器decoder端输入右移了一位的后编辑译文x=[x1,
…
x
k 1
],这样在解码器端需要分别利用前n个词来预测第n 1个词,由此能生成对应的隐向量h=[h1,
…hk
]
[0084]
s115:对第一损失子函数和第二损失子函数进行加权计算,得到总体损失函数。
[0085]
s116:以总体损失函数收敛为目标,训练mbart模型。
[0086]
本技术实施例提供的技术方案,通过上述两个子任务,能够分别得到两个方向的隐向量,再经由mbart模型的全连接层提取特征,能够处理得到两个损失函数,将这两个损失函数按照一定的权重相加,就能够作为整个任务的损失函数。以缩小损失函数为目标训练mbart模型,就能够使用该mbart模型输入原文和机器译文,就能够得到hter分数。
[0087]
另外,作为一种优选的实施例,如图3所示,上述步骤s112:使用第一隐向量训练mbart模型,得到句子级翻译质量估计任务对应的第一损失子函数的步骤包括:
[0088]
s1121:将第一隐向量输入至mbart模型的全连接层,提取得到机器译文特征。
[0089]
s1122:根据机器译文特征获取hter分数预测值,将hter分数预测值和hter分数真实值输入至均方误差函数,得到第一损失子函数。
[0090]
结合图8所示示实施例提供的mbart模型的结构可知,该mbart模型包括一个编码器,两个解码器;能够共同执行句子级翻译质量估计任务和基于后编辑译文任务;其中,句子级翻译质量估计任务的模型参见图9,第一隐向量u输入至mbart模型的全连接层linear,提取得到机器译文特征,然后使用sigmoid作为激活函数,最终得到第一损失子函数sentence loss。上述句子级翻译质量估计任务的主要训练方向是使模型能够预测产生hter分数。
[0091]
其中,作为一种优选的实施例,如图4所示,上述步骤s1122,根据机器译文特征获取hter分数预测值,将hter分数预测值和hter分数真实值输入至均方误差函数的步骤包括:
[0092]
s11221:使用sigmoid函数作为mbart模型的激活函数,将机器译文特征输入至
mbart模型的激活函数,得到hter分数预测值。
[0093]
上述sigmoid函数如下:mbart模型的激活函数如下:output=sigmoid(fc(u)),output为hter分数预测值,fc(u)为所述第一隐向量计算得到的机器译文特征。
[0094]
s11222:将hter分数预测值和hter分数真实值输入至均方误差函数,得到第一损失子函数。
[0095]
上述均方误差函数为:所述第一损失子函数为:l
sentence_level
=mse(hter,output)。
[0096]
本技术实施例提供的技术方案,通过mbart模型在编码器端输入原文,在解码器端湖人机器译文,从解码器的最后一层隐状态获取隐向量u,然后输入到全连接层,从而提取特征。通过使用sigmoid函数作为激活函数,最终得到取值范围在0-1之间的输出表示output,即预测的hter分数。最后,使用句子级的翻译质量估计任务作为回归任务,采用均方误差(mean square error,mse)作为损失函数:
[0097]
损失sentence loss由hter分数预测值output和真实的hter分数真实值(该值事先由pe数据和机器译文mt数据经脚本计算得到)经过均方误差mse函数进行计算,得到句子级翻译质量估计子任务损失函数l
sentence_level
,最终模型优化目标为最小化第一损失子函数:l
sentence_level
=mse(hter,output)。
[0098]
另外,作为一种优选的实施例,如图5所示,上述步骤s113:将原文输入至mbart模型的编码器,将右移一位的后编辑译文输入至mbart模型的解码器,得到基于后编辑译文任务对应的第二隐向量的步骤包括:
[0099]
s1131:将原文输入至mbart模型的编码器。
[0100]
s1132:将右移一位的后编辑译文输入至mbart模型的解码器。
[0101]
s1133:在解码器中,使用后编辑译文的前n项词预测第n 1项词,得到完整的后编辑译文。
[0102]
s1134:从解码器的隐状态中分别获取完整的后编辑译文中每个词对应的第二隐向量。
[0103]
本技术实施例提供的技术方案,是属于基于后编辑译文任务,该任务在编码器encoder端输入原文,在解码器decoder端输入右移一位的后编辑译文x=[x1,
…
x
k 1
];在解码器端,分别利用前n个词来预测第n 1个词,由此能生成对应的隐向量h=[h1,
…hk
]。
[0104][0105]
另外,作为一种优选的实施例,上述基于后编辑译文任务如图6所示,该任务中,上述使用第二隐向量训练mbart模型,得到基于后编辑译文任务对应的第二损失子函数的步骤包括:
[0106]
s1141:将第二隐向量输入至mbart模型的全连接层,提取得到后编辑译文特征。
[0107]
s1142:使用softmax分类器对后编辑译文特征进行分类,得到后编辑译文中每个词分别对应的词表维度向量。
[0108]
s1143:将每个词分别对应的词表维度向量输入至交叉熵损失函数,使用交叉熵损
失函数计算后编辑译文任务对应的第二损失子函数。
[0109]
结合图10所示的基于后编辑译文任务的隐向量后续处理获取损失函数的结构可知,该任务是通过前n个词预测n 1个词。在编码器encoder端输入的是原文,在解码器decoder端输入的是右移一位的后编辑译文pe数据,从解码器decoder隐状态中获取隐向量h,然后将其输入全连接层linear提取特征;再使用softmax分类器进行分类,最终得到每个词i划分到概率表示在0-1之间的词表维度向量logiti。该词表维度向量logiti计算公式如下:
[0110]
logitj=softmax(fc(hi)));
[0111]
然后,损失translation loss是通过交叉熵损失函数计算,得出该子任务的机器翻译损失函数:
[0112][0113]
最后,总体损失函数为两个损失子函数的加权相加(其中,α为代表加权的常数),具体计算公式如下:
[0114]
l=l
sentence_level
α*l
translation
[0115]
在训练过程中最小化该总体损失函数,最后得到联合训练的模型。
[0116]
在得到联合训练的模型后,需要使用上述模型进行机器译文质量的预测。具体地,作为一种优选的实施例,如图7所示,上述多任务机器翻译质量估计方法中,步骤s120:将原文和机器译文分别输入至总体损失函数收敛的mbart模型的编码器和解码器,预测得到机器译文的hter分数的步骤包括:
[0117]
s121:将原文输入至mbart模型的编码器,将机器译文输入至mbart模型的解码器,得到预测用隐向量。
[0118]
s122:将预测用隐向量输入至mbart模型的全连接层,提取得到预测用隐向量对应的机器译文特征。
[0119]
s123:将机器译文特征输入至mbart模型的激活函数,得到机器译文的hter分数。
[0120]
本技术实施例提供的技术方案,在根据机器译文进行机器翻译质量预测时,只需要在训练得到模型的编码器端输入原文,在解码器端输入机器译文,得到隐向量u,按照原有的句子级机器翻译评估任务的流程将隐向量输入到全连接层后通过sigmod激活函数,得到输出output即为预测的hter分数。
[0121]
综上,本技术上述实施例提供的技术方案,探索采用了一种基于编码器-解码器结构的跨语言预训练模型mbart。以mbart模型作为基础框架,采用句子级翻译质量估计任务和基于后编辑译文任务,形成多任务联合训练的训练方式。通过训练后的mbart模型得到预测的hter分数,进而实现句子级翻译质量估计,增加了模型解码到后编辑译文的损失作为联合优化目标。
[0122]
本方案中以上述多任务训练方式降低了额外的词汇级翻译质量估计的样本构造成本(现有技术中词汇级翻译质量估计需要机器译文和人工后编辑译文之间词汇的翻译质量标记,其中,人工后编辑译文,以及机器译文和人工后编辑译文之间词汇的翻译质量标记,额外增加了成本),本技术技术方案仅引入了人工后编辑译文,并没有采用词汇级翻译质量估计,因此降低了成本,同时提高了句子级翻译质量估计的性能,避免了构建词汇级翻
译质量估计数据的代价,对训练数据中后编辑译文的信息利用更有效。另外,本技术技术方案不再引入以往的词汇级翻译质量估计过程来相乘多任务训练模型,避免了词汇级翻译质量估计所需的数据标注成本,同时也避免了该过程可能引入的噪声信息。
[0123]
基于上述方法实施例的同一构思,本发明实施例还提出了基于后编辑译文的多任务机器翻译质量估计系统,用于实现本发明的上述方法,由于该系统实施例解决问题的原理与方法相似,因此至少具有上述实施例的技术方案所带来的所有有益效果,在此不再一一赘述。
[0124]
参见图11,图11为本发明实施例提供的一种基于后编辑译文的多任务机器翻译质量估计系统的结构示意图。如图11所示,该基于后编辑译文的多任务机器翻译质量估计系统,包括:
[0125]
联合训练执行模块110,用于使用跨语言预训练mbart模型作为基础框架,执行包括句子级翻译质量估计任务和基于后编辑译文任务的多任务联合训练,得到总体损失函数收敛的mbart模型;
[0126]
翻译质量预测模块120,用于将原文和机器译文分别输入至总体损失函数收敛的mbart模型的编码器和解码器,预测得到机器译文的hter分数。
[0127]
作为一种优选的实施例,如图12所示,上述多任务机器翻译质量估计系统中,联合训练执行模块110包括:
[0128]
第一隐向量输出子模块111,用于将原文输入至mbart模型的编码器,将机器译文输入至mbart模型的解码器,输出得到句子级翻译质量估计任务对应的第一隐向量;
[0129]
第一损失子函数计算子模块112,用于使用第一隐向量训练mbart模型,得到句子级翻译质量估计任务对应的第一损失子函数;
[0130]
以及,
[0131]
第二隐向量输出子模块113,用于将原文输入至mbart模型的编码器,将右移一位的后编辑译文输入至mbart模型的解码器,输出得到基于后编辑译文任务对应的第二隐向量;
[0132]
第二损失子函数计算子模块114,用于使用第二隐向量训练mbart模型,得到基于后编辑译文任务对应的第二损失子函数;
[0133]
总体损失函数计算子模块115,用于对第一损失子函数和第二损失子函数进行加权计算,得到总体损失函数;
[0134]
模型训练子模块116,用于以总体损失函数收敛为目标,训练mbart模型。
[0135]
作为一种优选的实施例,如图13所示,上述多任务机器翻译质量估计系统中,翻译质量预测模块120包括:
[0136]
预测用隐向量输出子模块121,用于将原文输入至mbart模型的编码器,将机器译文输入至mbart模型的解码器,输出得到预测用隐向量;
[0137]
机器译文特征提取子模块122,用于将预测用隐向量输入至mbart模型的全连接层,提取得到预测用隐向量对应的机器译文特征;
[0138]
分数计算子模块123,用于将机器译文特征输入至mbart模型的激活函数,得到机器译文的hter分数。
[0139]
综上,本技术上述实施例提供的基于后编辑译文的多任务机器翻译质量估计系
统,针对以往对机器翻译译文进行质量评估时,没有充分利用后编辑译文(pe)的问题进行改进。将机器译文(mt)到后编辑译文(pe)的翻译任务作为辅助任务合理的加入到模型的训练当中,并且选择mbart跨语言预训练模型作为预训练模型,以这种多任务训练方式避免了额外的词汇级翻译质量估计的样本构造成本,提高了句子级翻译质量估计的性能。需要说明的是,这里的性能主要是指处理处理性能,即不需要机器译文和人工后编辑译文之间词汇的翻译质量标记过程,所以处理速度得到提升。
[0140]
使用上述基于后编辑译文的多任务机器翻译质量评估系统,进行了实际的技术实验,实验过程如下:
[0141]
数据集:
[0142]
在英-中和英-德两个语言对方向上进行句子级别翻译质量估计任务实验。本方法分别选取了wmt2021(en-de)方向以及wmt2021(en-zh)方向的句子级别翻译质量估计相关的句子级数据集。具体数据集规模如表1所示。
[0143]
表1翻译质量估计数据集规模
[0144][0145]
本技术实施例使用mbart模型作为基础框架,在上述数据集上进行了实验。对于wmt的数据,我们将使用后编辑译文的多任务方法分别和使用词级别多任务以及不使用多任务之使用句子级别任务训练进行了对比。对于ccmt数据,由于没有提供词级别任务的数据,我们只将使用后编辑译文的多任务方法和不使用多任务之使用句子级别任务训练进行了对比。
[0146]
实验参数及评价指标:
[0147]
实验训练框架使用pytorch深度学习框架。跨语言预训练模型使用了hugging face上公布的facebook/mbart-large-50-many-to-many-mmt。实验参数设置上选取adamw作为优化器在batch size设置为8,学习率设置为1e-5的条件下,使用单张3090进行训练。模型训练终止条件为验证集的性能的在2轮内没有提升。
[0148]
在句子级翻译质量估计任务中,使用皮尔森相关系数(pearson correlation coefficient,pearson)、平均绝对误差(meanabsolute error,mae)以及均方根误差(rootmean squared error,rmse)这三个指标来衡量一个翻译质量估计模型性能的好坏。皮尔森相关系数作为主要衡量指标,是一个线性相关的系数,能够反映两个量之间的线性相关程度的,范围在-1到1之间,绝对值越接近于1,表示相关性越强,因此值越高说明该翻译质量估计模型性能越好。均方根误差衡量的是真实值与预测值的偏离的绝对大小情况,作为参考指标,两者值越低模型性能越好。
[0149]
实验结果:
[0150]
wmt2021实验结果如表2所示。
[0151]
表2 wmt2021实验结果
[0152][0153]
wmt的实验结果表明,加入多任务训练后,在英德和英中实验结果上比只使用mbart提高了5.2%和2%。与增加单词级别作为多任务相比分别提高了2.1%和1.2%,增加翻译多任务训练的效果得到了更大的提高。
[0154]
ccmt2021实验结果如表3所示:
[0155]
表3 ccmt2021实验结果
[0156][0157][0158]
实验结果表明使用翻译多任务比只使用句子级别任务在英-中和中-英分别提升了2.7%和1.5%。
[0159]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产
品的形式。
[0160]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0161]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0162]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0163]
应当注意的是,在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的部件或步骤。位于部件之前的单词“一”或“一个”不排除存在多个这样的部件。本发明可以借助于包括有若干不同部件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
[0164]
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0165]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。