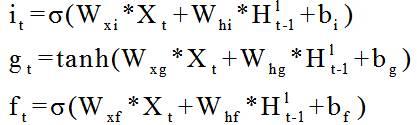
一种基于unet和dcn_lstm的降水预测方法
技术领域
1.本发明涉及天气预报技术领域,特别是涉及一种基于unet和dcn_lstm的降水预测方法。
背景技术:
2.暴雨事件会影响到人们的正常生活,造成重大的生命损失和财产损失,因此,准确的降水预测对人们生活和出行起到至关重要的作用,降水的提前预测可以向公众、减少灾害风险的机构、政府部门以及基础设施的管理人员提供早期警报,在暴雨预警发布后,上述相关人员、机构以及部门按照预定的标准操作程序来采取对应行动,以拯救生命和保护财产,所以降水预测对航空服务、公共安全以及人民的各个领域都有着巨大的影响,降水预测一直是一个重大问题,准确的预测降雨不仅对人们出行和对社会都至关重要,同时也可以避免暴雨和泥石流等重大灾害的出现。
3.降水预测的传统方法主要是基于数值预报模式(nwp),是指通过大气实况,采取超大型计算机作为数值计算工具,通过流体力学和热力学方程组,预测出未来一段时间的运动状态和天气状况,这种方法计算量超大,计算复杂,耗费时间长,对短时间降水预测显得无能为力。
4.现有的深度学习降水预测方法很多,但是都采取单一模型,没有将两个模型结合,单独使用unet作为降水预测,可以提取的时间相关性太少,且不适合长时间预测,比如一小时预测,单独使用lstm模型预测,计算量比较复杂,训练时间较长,而且模型参数量大,耗费计算机显存;因此,提出了一种基于unet和dcn_lstm的降水预测方法,与现有方法相比,能过有效提取时间空间相关性,由于特征图变小,可以更好的提取降水的全局特征,同时模型参数变小,训练时间变短,能够提升降水预测的精准度。
技术实现要素:
5.为了解决以上技术问题,本发明提供一种基于unet和dcn_lstm的降水预测方法,包括以下步骤s1、获取气象雷达数据,并对气象雷达数据预处理;s2、构建unet和dcn_lstm混合模型;s3、对unet和dcn_lstm混合模型加入贝叶斯算法,进行超参数优化,寻找最优参数组合;s4、对unet和dcn_lstm混合模型进行测试;s5、对测试集预测的结果,通过像素值转换成雷达反射率,再根据雷达反射率与降雨量的关系求得降雨量。
6.本发明进一步限定的技术方案是:进一步的,步骤s1中,对气象雷达数据预处理的方法,包括以下步骤s1.1、对数据异常值和重复值进行剔除,并对数据的缺失值进行双线性插值;
s1.2、对数据集进行筛选,保证每个回波序列有20%的降水覆盖率;s1.3、对数据进行归一化处理,具体公式如下,其中,x
*
表示归一化的雷达回波强度值,x
max
表示雷达回波强度最大值,x
min
表示雷达回波强度最小值,x表示雷达回波强度值;s1.4、采用8:2的比例对数据集进行划分,即80%为训练集,20%为测试集。
7.前所述的一种基于unet和dcn_lstm的降水预测方法,步骤s2中,构建unet和dcn_lstm混合模型的方法,包括以下步骤s2.1、混合模型编码器部分,将训练集数据输入到模型中,经过两个3
×
3卷积层,再通过最大池化层,特征图变为原来大小的一半,再经过两个3
×
3卷积层,通道数加倍;s2.2、混合模型中间采用dcn_lstm,用于提取雷达回波序列的时间特征和空间特征,dcn_lstm由多个dcn_lstm循环单元组成,用于将编码器输出的特征图进行分解,依次输入到dcn_lstm循环单元中进行训练;s2.3、混合模型解码器部分,经过dcn_lstm输出的雷达回波序列按通道进行拼接,然后经过两个3
×
3卷积层,再经过上采样,和编码器输出的的特征图跳过连接,再经过两个3
×
3卷积层和一个1
×
1卷积层,最后输出预测的雷达回波序列。
8.前所述的一种基于unet和dcn_lstm的降水预测方法,步骤s2.2中,dcn_lstm利用可行变卷积学习输入x对隐藏状态h和记忆细胞c的偏移量,从而更新隐藏状态h和记忆细胞c,在输入图片上滑动,可行变卷积把得到的特征图作为输入,对特征图再施加一个卷积层,从而得到可行变卷积的变形偏移量,偏移层为2n,在平面上进行平移,需要改变x和y两个方向;可行变卷积的具体公式如下,其中,r表示一个3
×
3的卷积核,(-1,-1),(-1,0),(0,1),(1,1)表示卷积核里的点,且坐标为整数;其中,表示可行变卷积得到的特征矩阵,表示在大小为3
×
3的卷积核内经过神经网络学习得到的每个点的学习量,表示中心点,即(0,0)点,表示定义在r范围内的点,相比标准卷积可行变卷积多了通过卷积学习到的一个偏移矩阵。
9.前所述的一种基于unet和dcn_lstm的降水预测方法,dcn_lstm模型包括若干个dcn_lstm循环单元,通过门控机制对特征信息进行筛选和传递,保留了convlstm的遗忘门、输入门、调制门、输出门、时间记忆细胞以及隐藏状态,分别为f
t、it、gt、ot、ct
以及h
t
;还包括
空间细胞m
t
,用于在不同层之间垂直地提取和传递空间结构特征,同时加入可行变卷积来学习输入x对隐藏状态h和记忆细胞c的偏移量,具体公式如下,其中,dcn表示可行变卷积网络,x
t
表示输入的图片,下坐标t表示输入的时刻,和分别表示隐藏状态和记忆细胞,下坐标t-1表示上一个时刻,上坐标1表示第一层,和分别表示更新后得到的新的隐藏状态和记忆细胞。
10.前所述的一种基于unet和dcn_lstm的降水预测方法,dcn_lstm模型中,用于更新记忆细胞的输入门、更新门以及遗忘门,公式如下,其中,i
t
表示更新记忆细胞的输入门;σ表示激活函数sigmoid;w
xi
表示对输入x,输入门i训练的参数矩阵;w
hi
表示对隐藏状态h,输入门i训练的参数矩阵;x
t
表示t时刻的输入;表示t-1时刻,第l层的隐藏状态;bi表示对输入门i的偏置;g
t
表示更新记忆细胞的更新门;tanh表示激活函数tanh;w
xg
表示对输入x,更新门g训练的参数矩阵;w
hg
表示对隐藏状态h,更新门g训练的参数矩阵;bg表示对更新门g的偏置;f
t
表示更新记忆细胞的遗忘门;w
xf
表示对输入x,遗忘门f训练的参数矩阵;w
hf
表示对隐藏状态h,遗忘门f训练的参数矩阵;bf表示对遗忘门f的偏置;*表示卷积;用于更新空间细胞的输入门、更新门以及遗忘门,公式如下,其中,表示更新空间细胞的输入门;σ表示激活函数sigmoid;表示对输入x,输入门i训练的参数矩阵;w
mi
表示对空间细胞m,输入门i训练的参数矩阵;x
t
表示t时刻的输入;表示t时刻,第l-1层的空间细胞;表示对输入门i的偏置;表示更新空间细胞的更新门;tanh表示激活函数tanh;表示对输入x,更新门g训练的参数矩阵;w
mg
表示对空间细胞m,更新门g训练的参数矩阵;表示对更新门g的
偏置;表示更新空间细胞的遗忘门;表示对输入x,遗忘门f训练的参数矩阵;w
mf
表示对空间细胞m,遗忘门f训练的参数矩阵;表示对遗忘门f的偏置;*表示卷积;通过记忆细胞、空间细胞以及输出门来更新隐藏状态,即输出,具体公式如下,其中,表示第t时刻,第l层的记忆细胞;i
t
表示输入门;g
t
表示更新门;f
t
表示遗忘门;表示t-1时刻,第l层的记忆细胞;表示第t时刻,第l层的空间细胞;表示空间细胞的输入门;表示空间细胞的更新门;表示空间细胞的遗忘门;表示第t时刻,l-1层的空间细胞;o
t
表示输出门;σ表示激活函数sigmoid;w
xo
表示对输入x,输出门o的参数训练矩阵;w
ho
表示对隐藏状态h,输出门o的参数训练矩阵;w
co
表示对记忆细胞c,输入门o的训练参数矩阵;w
mo
表示对空间细胞m,输入门o的训练参数矩阵;x
t
表示t时刻的输入;表示t-1时刻,第l层的隐藏状态;表示第t时刻,第l层的记忆细胞;表示第t时刻,第l层的空间细胞;bo表示对输出门的偏置;w
1x1
表示1
×
1大小的卷积核;表示更新得到的新的隐藏状态;
°
表示矩阵按位相乘;*表示卷积。
11.前所述的一种基于unet和dcn_lstm的降水预测方法,步骤s3中,通过贝叶斯算法优化隐藏层的神经元个数、批次大小以及学习率,包括以下步骤s3.1、假设一组超参数组合是,其中分别表示隐藏层神经元个数、批次大小以及学习率的参数组合,并假设损失函数和设置的超参数存在映射关系;假设函f:x
→
r,需要在x∈rs3.2、根据确定优化的超参数,在参数范围内得到超参数的随机初始化点,输入实验数据训练模型,损失函数的响应值为,建立高斯回归过程;已知数据集,假设f服从
,所以预测也服从正态分布,,所以预测也服从正态分布,,所以预测也服从正态分布,,所以预测也服从正态分布,其中,k为常数,k(x)和表示协方差矩阵,表示样本n的方差;求出和;s3.3、基于采样函数pi从高斯回归模型选择下一个超参数组合采样点,采样函数pi如下,其中,φ()表示正态分布积累密度函数,和分别表示目标函数值的均值和方差,表示最佳目标函数值,表示参数;s3.4、将选定的第一组超参数组合带入模型训练,输出地面观测的真实值与预测的雷达回波序列的均方误差值,若均方误差值小于预设阀值,则停止更新,输出最佳超参数组合;若均方误差值不小于预设阀值,则将超参数更新为,重复步骤s3.2至步骤s3.4,直至找到均方误差值小于预设阀值的超参数组合。
12.前所述的一种基于unet和dcn_lstm的降水预测方法,步骤3.4中,预设阈值设置为0.0001。
13.前所述的一种基于unet和dcn_lstm的降水预测方法,步骤s4中,对unet和dcn_lstm混合模型进行测试的方法,包括以下步骤s4.1、加载模型训练的权重,进行测试,并且保存为图片格式;s4.2、测试集的评价指标采取均方误差、结构相似性以及临界成功指数;均方误差用于评价两张图片像素点的差异性,具体公式如下,其中,n表示样本总数,i表示的是第几个样本点,y表示真实雷达回波图真实标签,表示预测的雷达回波图;结构相似性用于衡量两张图片的相似度,具体公式如下,
其中,u
x
和uy分别表示对x和y的均值,σ
x
和σy分别表示对x和y的方差,σ
xy
表示对两张图片x和y的协方差,c1和c2表示常数;临界成功指数的具体公式如下:其中,tp表示真实类别为正预测结果也为正,fp表示真实类别为负预测结果为正,fn表示指真实类别为正预测结果为负。
14.前所述的一种基于unet和dcn_lstm的降水预测方法,步骤s5中,对测试集预测的结果通过像素值转换成雷达反射率,具体公式如下,其中,radar_value表示通过公式转换每个像素点的雷达反射率的值,pixel_value表示每个像素点的值;再根据雷达反射率与降雨量的关系求得降雨量,具体公式如下,其中,z表示雷达反射率,r表示降雨量,a,b表示系数。
15.本发明的有益效果是:本发明中,可以减少训练时间,提升了降水预测的时效性,将两种模型有效结合,提升降水预测的精准度,同时能够有效捕获时空相关性,使用可形变卷积学习输入对隐藏状态和记忆细胞的偏置量,可以通过输入来调整卷积核的位置,使得卷积核位置不再是固定的,能对降水区域特征有效提取,使用了贝叶斯算法,能够解决手动调参的繁琐,通过贝叶斯算法可以学习到最佳的超参数组合,通过多项指标评价,使用unet和dcn_lstm混合模型比使用单一模型预测精准度更高,效果更好。
附图说明
16.图1为本发明的整体流程示意图;图2为本发明中unet和dcn_lstm混合模型的示意图;图3为本发明中贝叶斯算法进行超参数优化的流程示意图。
具体实施方式
17.本实施例提供的一种基于unet和dcn_lstm的降水预测方法,如图1至图3所示,包括以下步骤s1、获取气象雷达数据,所使用的数据是雷达回波序列数据集,输入为10帧,预测为10帧,且每帧的间隔为6分钟,即用前一个小时的历史数据去预测未来一个小时的降雨量,并对气象雷达数据预处理,具体步骤如下:s1.1、对数据异常值和重复值进行剔除,并对数据的缺失值进行双线性插值;s1.2、对数据集进行筛选,保证每个回波序列有20%的降水覆盖率,预测降雨时如果不对数据进行筛选,可能导致很多序列都没有降水覆盖,会导致训练的模型效果不理想;
s1.3、对数据进行归一化处理,具体公式如下,其中,x
*
表示归一化的雷达回波强度值,x
max
表示雷达回波强度最大值,x
min
表示雷达回波强度最小值,x表示雷达回波强度值;s1.4、采用8:2的比例对数据集进行划分,即80%为训练集,20%为测试集。
18.s2、构建unet和dcn_lstm混合模型,unet和dcn_lstm混合模型主要是由unet的前半部分和后半部分,分别构成模型的编码器和解码器部分,unet中间原来是卷积层,本方法中替换成dcn_lstm模型,能够有效提取时间和空间相关性,具体步骤如下:s2.1、混合模型编码器部分,编码器部分采用unet的前半部分,将训练集数据输入到模型中,输入为[8,10,200,200],其中8表示batch_size批次数,10表示输入的seq序列,200,200分别表示输入图片的长度和宽度;经过两个3
×
3卷积层,每一层之后都加一个校正线性单元,使得模型成为非线性和批归一化,接着通过2
×
2最大池化层,经过池化后通道数加倍,输入的雷达回波图片大小变为原来的一半,图片长度为100,宽度为100,再经过两个3
×
3卷积层,每一层之后都加一个校正线性单元,使得模型成为非线性和批归一化,通道数加倍变为128;s2.2、混合模型中间采用dcn_lstm,用于提取雷达回波序列的时间特征和空间特征,dcn_lstm由多个dcn_lstm循环单元组成,将编码器输出的[8,128,100,100]进行维度转换为[8,128,1,100,100],依次输入到dcn_lstm循环单元中进行训练;dcn_lstm利用可行变卷积学习输入x对隐藏状态h和记忆细胞c的偏移量offset,从而更新隐藏状态h和记忆细胞c,在输入图片上滑动,可行变卷积把得到的特征图作为输入,对特征图再施加一个卷积层,从而得到可行变卷积的变形偏移量,偏移层为2n,在平面上进行平移,需要改变x和y两个方向;可行变卷积的具体公式如下,其中,r表示一个3
×
3的卷积核,(-1,-1),(-1,0),(0,1),(1,1)表示卷积核里的点,且坐标为整数;其中,表示可行变卷积得到的特征矩阵,表示在大小为3
×
3的卷积核内经过神经网络学习得到的每个点的学习量,表示中心点,即(0,0)点,表示定义在r范围内的点,相比标准卷积可行变卷积多了通过卷积学习到的一个偏移矩阵;dcn_lstm模型包括若干个dcn_lstm循环单元,通过门控机制对特征信息进行筛选和传递,保留了convlstm的遗忘门、输入门、调制门、输出门、时间记忆细胞以及隐藏状态,
分别为f
t、it、gt、ot、ct
以及h
t
;还包括空间细胞m
t
,用于在不同层之间垂直地提取和传递空间结构特征,同时加入可行变卷积来学习输入x对隐藏状态h和记忆细胞c的偏移量,具体公式如下,其中,dcn表示可行变卷积网络,x
t
表示输入的图片,下坐标t表示输入的时刻,和分别表示隐藏状态和记忆细胞,下坐标t-1表示上一个时刻,上坐标1表示第一层,和分别表示更新后得到的新的隐藏状态和记忆细胞;dcn_lstm模型中,用于更新记忆细胞的输入门、更新门以及遗忘门,公式如下,其中,i
t
表示更新记忆细胞的输入门;σ表示激活函数sigmoid;w
xi
表示对输入x,输入门i训练的参数矩阵;w
hi
表示对隐藏状态h,输入门i训练的参数矩阵;x
t
表示t时刻的输入;表示t-1时刻,第l层的隐藏状态;bi表示对输入门i的偏置;g
t
表示更新记忆细胞的更新门;tanh表示激活函数tanh;w
xg
表示对输入x,更新门g训练的参数矩阵;w
hg
表示对隐藏状态h,更新门g训练的参数矩阵;bg表示对更新门g的偏置;f
t
表示更新记忆细胞的遗忘门;w
xf
表示对输入x,遗忘门f训练的参数矩阵;w
hf
表示对隐藏状态h,遗忘门f训练的参数矩阵;bf表示对遗忘门f的偏置;*表示卷积;用于更新空间细胞的输入门、更新门以及遗忘门,公式如下,其中,表示更新空间细胞的输入门;σ表示激活函数sigmoid;表示对输入x,输入门i训练的参数矩阵;w
mi
表示对空间细胞m,输入门i训练的参数矩阵;x
t
表示t时刻的输入;表示t时刻,第l-1层的空间细胞;表示对输入门i的偏置;表示更新空间细胞的更新门;tanh表示激活函数tanh;表示对输入x,更新门g训练的参数矩阵;w
mg
表示对空间细胞m,更新门g训练的参数矩阵;表示对更新门g的
偏置;表示更新空间细胞的遗忘门;表示对输入x,遗忘门f训练的参数矩阵;w
mf
表示对空间细胞m,遗忘门f训练的参数矩阵;表示对遗忘门f的偏置;*表示卷积;通过记忆细胞、空间细胞以及输出门来更新隐藏状态,即输出,具体公式如下,其中,表示第t时刻,第l层的记忆细胞;i
t
表示输入门;g
t
表示更新门;f
t
表示遗忘门;表示t-1时刻,第l层的记忆细胞;表示第t时刻,第l层的空间细胞;表示空间细胞的输入门;表示空间细胞的更新门;表示空间细胞的遗忘门;表示第t时刻,l-1层的空间细胞;o
t
表示输出门;σ表示激活函数sigmoid;w
xo
表示对输入x,输出门o的参数训练矩阵;w
ho
表示对隐藏状态h,输出门o的参数训练矩阵;w
co
表示对记忆细胞c,输入门o的训练参数矩阵;w
mo
表示对空间细胞m,输入门o的训练参数矩阵;x
t
表示t时刻的输入;表示t-1时刻,第l层的隐藏状态;表示第t时刻,第l层的记忆细胞;表示第t时刻,第l层的空间细胞;bo表示对输出门的偏置;w
1x1
表示1
×
1大小的卷积核;表示更新得到的新的隐藏状态;
°
表示矩阵按位相乘;*表示卷积。
[0019]
s2.3、混合模型解码器部分,由unet后半部分构成,经过dcn_lstm输出按通道进行拼接,并将经过跳过连接和原始输入的特征图进行特征融合,通道数变为256;再经过两个3
×
3的卷积层捕获原始图像的上下文,每一层之后都加一个校正线性单元,使得模型成为非线性和批归一化;再通过上采样,上采样使用的是双线性插值,恢复维度,同时经过跳过连接,特征通道数变为128;再经过两个3
×
3卷积层和一个1
×
1卷积层。最终,输出预测的雷达回波序列。
[0020]
s3、对unet和dcn_lstm混合模型加入贝叶斯算法,进行超参数优化,寻找最优参数组合,通过贝叶斯算法优化隐藏层的神经元个数、批次大小以及学习率,具体步骤如下:s3.1、假设一组超参数组合是,其中分别表示隐藏层神经元个数、批次大小以及学习率的参数组合,并假设损失函数和设置的超参数存在映射关系;假设函f:x
→
r,需要在x∈r
s3.2、根据确定优化的超参数,在参数范围内得到超参数的随机初始化点,输入实验数据训练模型,损失函数的响应值为,建立高斯回归过程;已知数据集,假设f服从,所以预测也服从正态分布,,所以预测也服从正态分布,,所以预测也服从正态分布,,所以预测也服从正态分布,其中,k为常数,k(x)和表示协方差矩阵,表示样本n的方差;求出和;s3.3、基于采样函数pi从高斯回归模型选择下一个超参数组合采样点,采样函数pi如下,其中,φ()表示正态分布积累密度函数,和分别表示目标函数值的均值和方差,表示最佳目标函数值,表示参数;s3.4、将选定的第一组超参数组合带入模型训练,输出地面观测的真实值与预测的雷达回波序列的均方误差值,设定预设阈值为0.0001,若均方误差值小于预设阀值,则停止更新,输出最佳超参数组合;若均方误差值不小于预设阀值,则将超参数更新为,重复步骤s3.2至步骤s3.4,直至找到均方误差值小于预设阀值的超参数组合。
[0021]
构建好模型后,将训练集输入到模型中训练,使用优化好的超参数,损失函数采用输出雷达回波图和地面真实的雷达回波图的均方误差(mse),设置最大训练epoch,通过反向传播,使得损失值loss达到最小值,最小值是指训练loss不断下降,直至不再下降,将训练最好的权重进行保存;损失函数使用均分误差(mse)和平均绝对值误差(mae)之和,公式如下:
其中,n表示样本总数,i表示的是第几个样本点,y表示真实雷达回波图真实标签,表示预测的雷达回波图;总的损失值为loss=loss1 loss2。
[0022]
s4、对unet和dcn_lstm混合模型进行测试,采用多个指标对模型进行评估,具体步骤如下:s4.1、加载模型训练的权重,进行测试,并且保存为图片格式;s4.2、测试集的评价指标采取均方误差(mse)、结构相似性(ssim)以及临界成功指数(csi);均方误差用于评价两张图片像素点的差异性,具体公式如下,其中,n表示样本总数,i表示的是第几个样本点,y表示真实雷达回波图真实标签,表示预测的雷达回波图;结构相似性用于衡量两张图片的相似度,具体公式如下,其中,u
x
和uy分别表示对x和y的均值,σ
x
和σy分别表示对x和y的方差,σ
xy
表示对两张图片x和y的协方差,c1和c2表示常数;临界成功指数的具体公式如下:其中,tp表示真实类别为正预测结果也为正,fp表示真实类别为负预测结果为正,fn表示指真实类别为正预测结果为负。
[0023]
s5、对测试集预测的结果,通过像素值转换成雷达反射率,具体公式如下,其中,radar_value表示通过公式转换每个像素点的雷达反射率的值,pixel_value表示每个像素点的值;再根据雷达反射率与降雨量的关系求得降雨量,具体公式如下,
其中,z表示雷达反射率,r表示降雨量,a,b表示系数。
[0024]
除上述实施例外,本发明还可以有其他实施方式。凡采用等同替换或等效变换形成的技术方案,均落在本发明要求的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。