1.本发明涉及自然语言处理技术领域,特别是涉及一种端到端任务型对话方法及系统。
背景技术:
2.对话式人工智能一直是计算机科学中自然语言处理(natural language processing,nlp)领域的一个长期探索课题。如果说,nlp是人工智能皇冠上的明珠,那么对话系统就是nlp皇冠上的明珠。随着神经网络的发展和进步,对话系统最近在学术界和工业界都得到了更多的关注。
3.对话任务大致分为两类:开放域对话系统专注于与人类的闲聊,比如各类语音助手:小艺,小爱,小度,siri等,非常的自然和引人入胜,其通常使用来自社交媒体的大规模数据进行端到端的训练;而面向任务的对话(task-oriented dialogue,tod)系统需要完成用户用自然语言描述的相关领域目标,常见于公共交通订票系统、机票酒店预约系统等。tod任务通常被分解为三个子任务:理解用户输入信息、决策生成动作和产生自然语言响应,通常使用流水线的(pipeline)模块化方法来针对特定数据集的训练。流水线模块化方法包括自然语言理解模块来进行信念状态跟踪、对话策略模块来根据这些信念决定采取哪些动作,自然语言生成模块根据产生的动作来生成自然语言响应来和用户进行沟通交流。
4.在任务型对话系统中,用户有要完成的目标,系统提供了一个接口来访问外部数据库。双方用户只能通过自然语言交流从对方获取相关信息。任务型对话系统示意图如图1所示。用户应该以有组织的方式完整地表达目标(goal,g),通常包含约束(constraint,c)和需求(request,r)。例如约束c(市中心的一家中餐馆)和需求r(例如查询地址、酒店电话号码)组成,且目标g中可以有多个领域(比如餐厅restaurant,旅游景点attraction,出租车taxi,酒店hotel,火车train等)。系统应该利用其外部数据库准确、即时地响应有用的信息,并且给定所有满足条件的候选实体和相应信息。用户和系统在会话中相互通过自然语言交流、传递信息最终以实现用户目标。
5.目前许多任务型对话的许多研究工作都集中在优化特定模块上,并且仅针对该模块进行评估。这些模块包括通过意图检测理解用户意图,通过对话状态跟踪来跟踪用户提供的约束条件,通过对话策略确定对话系统动作,以及使用专用的自然语言响应生成的组件。然而这些独立模块之间的依赖关系使流水线方法容易受到跨组件的错误传播带来的错误累计的影响,且需要对每个组件模块进行微调,这些单独的步骤可以独立完成,但很难确保整个对话系统达到最优。
6.最近的方法越来越多的转向端到端解决方案,旨在减少人力和特定任务模块的设计。而salesforce研究院提出的simpletod(一种端到端的任务型对话生成模型)直接将所有面向任务的对话视为单个序列预测问题,使用单个预训练语言模型,通过单个、联合、多任务损失进行训练,在端到端设置中共同实现对话状态跟踪、行动决策和响应生成指标的先进性能。
技术实现要素:
7.为了弥补上述背景技术的不足,本发明提出一种端到端任务型对话方法及系统,以解决任务型对话中模块化优化的错误累计和无法到达全局最优的问题。
8.本发明的技术问题通过以下的技术方案予以解决:
9.本发明公开一种端到端任务型对话方法,其是基于自注意力机制而构建,包括如下步骤:
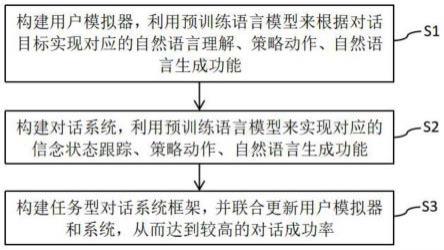
10.s1、构建用户模拟器,利用预训练语言模型来根据对话目标实现对应的自然语言理解、策略动作、自然语言生成功能;
11.s2、构建对话系统,利用预训练语言模型来实现对应的信念状态跟踪、策略动作、自然语言生成功能;
12.s3、构建任务型对话系统框架,并联合更新用户模拟器和系统,从而达到较高的对话成功率。
13.在一些实施例中,步骤s1中,用户模拟器是目标导向的端到端对话用户模拟器,利用基于自注意力机制的自然语言模型来将其构造成一个用户模拟器的序列预测问题。
14.在一些实施例中,步骤s1中,对于用户模拟器的序列预测问题,每一轮次用户模拟器的对话分解为:user_context、nlu、dynamic_goal、user_policy、user_nlg五个部分;其中user_context为每个轮次用户模拟器和系统的自然语言对话,nlu即用户模拟器对系统所作动作的理解,dynamic_goal即对话过程中的动态目标状态,user_policy即用户模拟器该轮次做出的动作,user_nlg即根据动作来生成用户模拟器的自然语言,生成的自然语言为去词化用户语言delex_user_utterance,同时结合目标goal信息来生成词汇化用户语言lex_user_utterance。
15.在一些实施例中,步骤s2中,所述对话系统为端到端对话系统;利用基于自注意力机制的自然语言模型来将其构造成一个对话系统的序列预测问题。
16.在一些实施例中,对于对话系统的序列预测问题,每一轮次的对话系统的对话分解为:sys_context、dst、db、sys_policy、sys_nlg四个部分;其中sys_context为每个轮次用户模拟器和系统的自然语言对话,dst即系统对用户所有有用信念状态的理解,db即外部数据库的搜索结果,sys_policy即系统该轮次做出的动作,sys_nlg即根据动作来生成系统的自然语言,生成的自然语言为去词化系统响应delex_sys_response,同时信念状态beliefstate信息来生成词汇化用户语言lex_sys_response。
17.在一些实施例中,步骤s3中,所述任务型对话系统框架针对用户模拟器的目标,用户模拟器首先进行理解,接着通过策略生成对应的动作以及自然语言,系统通过用户的用户语言来进行信念状态跟踪并生成对应的动作以及系统响应,两者通过自然语言交互,系统侧拥有外部数据库,两者交互来完成对应的目标。
18.在一些实施例中,步骤s3中包括优化步骤,采用transformer模型,同时设置用户模拟器的transformer模型为user_transformer,设置对话系统transformer模型为sys_transformer。
19.在一些实施例中,步骤s3中包括优化步骤,对于用户模拟器而言,在轮次t,用户模拟器生成用户语言u
t
,针对用户模拟器构造历史文本c
u_t
=[s0,u0,s1,u1......s
t-1
],自然语言理解记为nlu
u_t
,用户动态状态为goal
u_t
,用户策略记为pol
u_t
,整个过程归纳为:
[0020][0021]
在一些实施例中,步骤s3中包括优化步骤,对于系统而言,在轮次t,系统生成系统响应s
t
,针对对话系统构造历史文本c
s_t
=[u0,s0,u1,s1,......u
t
],信念状态跟踪记为dst
s_t
,外部数据库搜索为db
s_t
,系统策略记为pol
s_t
,整个过程归纳为:
[0022][0023]
本发明还公开一种端到端任务型对话系统,采用如上任一项所述的方法构建。
[0024]
本发明与现有技术对比的有益效果包括:
[0025]
本发明提供的端到端任务型对话方法,对于用户模拟器,利用预训练语言模型来根据对话目标实现对应的自然语言理解、策略动作、自然语言生成功能;对于对话系统,利用预训练语言模型来实现对应的信念状态跟踪、策略动作、自然语言生成功能;再构建任务型对话系统框架,并联合更新用户模拟器和系统,从而达到较高的对话成功率。本发明能够有效地构建端到端的用户模拟器和对话系统,同时可以实现较高的用户模拟器和系统的对话成功率。
附图说明
[0026]
图1是本发明现有技术的任务型对话系统示意图。
[0027]
图2是本发明实施例的端到端任务型对话方法流程图。
[0028]
图3是本发明实施例的用户模拟器端到端模型图。
[0029]
图4是本发明实施例的对话系统端到端模型图。
[0030]
图5是本发明实施例的任务型对话系统框架图。
具体实施方式
[0031]
下面对照附图并结合优选的实施方式对本发明作进一步说明。需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
[0032]
需要说明的是,本实施例中的左、右、上、下、顶、底等方位用语,仅是互为相对概念,或是以产品的正常使用状态为参考的,而不应该认为是具有限制性的。
[0033]
为了克服任务型对话中模块化优化的错误累计和无法到达全局最优的问题,提高用户模拟器和系统间对话成功率,本发明实施例提供一种基于自注意力机制(transformer)的端到端任务型对话方法。该方法能够有效地构建端到端的用户模拟器和对话系统。同时,该方法可以实现较高的用户模拟器和系统的对话成功率,为之后的基于transformer的任务型对话提供基础框架。
[0034]
本发明实施例需要解决的核心问题包括:(1)对于用户模拟器,如何利用预训练语言模型来根据对话目标来实现对应的自然语言理解、策略动作、自然语言生成功能;(2)对于对话系统,如何利用预训练语言模型来实现对应的信念状态跟踪、策略动作、自然语言生
成功能;(3)如何选择优化方法来联合更新用户模拟器和系统,从而达到较高的对话成功率。
[0035]
如图2所示,本发明实施例的端到端任务型对话方法包括如下步骤:
[0036]
s1、构建用户模拟器,利用预训练语言模型来根据对话目标实现对应的自然语言理解、策略动作、自然语言生成功能。
[0037]
具体地,用户模拟器的构建一直是任务型对话中被广泛关注的问题,但其难以评估,并且如何根据目标的变化来改变对应的策略生成是一个值得研究的问题。本发明实施例的用户模拟器是目标导向的端到端对话用户模拟器,利用基于自注意力机制的自然语言模型(gpt-2模型)来将其构造成一个用户模拟器的序列预测问题。包括以下功能:自然语言理解、策略动作、自然语言生成。用户模拟器的端到端模型如图3所示。
[0038]
其中,对于序列预测问题,每一轮次用户模拟器的对话可以分解为:user_context、nlu、dynamic_goal、user_policy、user_nlg五个部分。其中user_context为每个轮次用户模拟器和系统的自然语言对话,nlu即用户模拟器对系统所作动作的理解,dynamic_goal即对话过程中的动态目标状态,user_policy即用户模拟器该轮次做出的动作,user_nlg即根据动作来生成用户模拟器的自然语言,生成的自然语言为去词化用户语言(delex_user_utterance),同时结合目标(goal)信息来生成词汇化用户语言(lex_user_utterance)。每一轮次用户模拟器的对话示例如下:
[0039]
用户历史文本:《sos_sr》《eos_sr》《sos_uu》ineed to booka train that leaves after 13:45 on tuesday.《eos_uu》《sos_sr》what is your destination?《eos_sr》
[0040]
自然语言理解:《sos_sa》[act_request][train_destination]《eos_sa》
[0041]
动态目标:《sos_g》restaurant_info_area restaurant_info_food restaurant_book_day restaurant_book_people restaurant_book_time train_info_departure train_info_destination train_reqt_duration train_reqt_price《eos_g》
[0042]
策略动作:《sos_ua》[act_inform][train_day][train_leaveat]《eos_ua》
[0043]
自然语言生成:《sos_uu》i need to book a train that leaves after[train_leaveat]on[train_day].《eos_u》。
[0044]
s2、构建对话系统,利用预训练语言模型来实现对应的信念状态跟踪、策略动作、自然语言生成功能。
[0045]
具体地,对话系统的构建一直是任务型对话中被广泛关注的问题,但是如何根据用户模拟器的反馈来进行对应的信念状态跟踪和生成对应的响应是一个值得研究的问题。本发明实施例的对话系统为端到端对话系统,利用基于自注意力机制的自然语言模型(gpt-2)模型来将其构造成一个序列预测问题。包括以下功能:信念状态跟踪、策略动作、自然语言生成。对话系统的端到端模型如图4所示。
[0046]
其中,对于序列预测问题,每一轮次的对话系统的对话可以分解为:sys_context、dst、db、sys_policy、sys_nlg四个部分。其中sys_context为每个轮次用户模拟器和系统的自然语言对话,dst即系统对用户所有有用信念状态的理解,db即外部数据库的搜索结果,sys_policy即系统该轮次做出的动作,sys_nlg即根据动作来生成系统的自然语言,生成的自然语言为去词化系统响应(delex_sys_response),同时信念状态(beliefstate)信息来生成词汇化用户语言(lex_sys_response)。对话系统的对话示例如下:
[0047]
系统历史文本:《sos_uu》ineed to book a train that leaves after13:45 on tuesday.《eos_uu》《sos_sr》what is your destination?《eos_sr》《sos_uu》i am going to liverpool street in london.《eos_uu》
[0048]
信念状态跟踪:《sos_b》[train_destination]london liverpool street[train_day]tuesday[train_leaveat]13:45《e0s_b》
[0049]
数据库:
[0050]
《sos_db》[restaurant_db_0][hotel_db_0][attraction_db_0][train_db_2]《eos_db》
[0051]
策略动作:《sos_sa》[act_inform][train_choice]
[0052]
[train_departure][train_destination][train_leaveat][train_trainid]《eos_sa》
[0053]
自然语言生成:《sos_sr》the first train out of[train_departure]
[0054]
after[value_count],going to[train_destination],is the[train_id],which leaves at[train_leaveat].《eos_sr》。
[0055]
s3、构建任务型对话系统框架,并联合更新用户模拟器和系统,从而达到较高的对话成功率。
[0056]
具体地,针对上述提到的目标导向的端到端对话用户模拟器和端到端对话系统,构建的端到端任务型对话系统框架(transformer-based framework of task-oriented dialogue,tftod)如图5所示。在该框架下,针对用户模拟器的目标,用户模拟器首先进行理解,接着通过策略生成对应的动作以及自然语言,系统通过用户的用户语言来进行信念状态跟踪并生成对应的动作以及系统响应,两者通过自然语言交互,系统侧拥有外部数据库,两者交互来完成对应的目标。
[0057]
其中,采用如下优化方法联合更新用户模拟器和系统:
[0058]
本发明实施例中,对话通常会包括很多轮次,在轮次t,用户模拟器生成用户语言u
t
,系统生成系统响应s
t
;针对用户模拟器构造历史文本c
u_t
=[s0,u0,s1,u1......s
t-1
],针对对话系统构造历史文本c
s_t
=[u0,s0,u1,s1,......u
t
]。同时设置用户模拟器的transformer模型为user_transformer,设置对话系统transformer模型为sys_transformer。
[0059]
对于用户模拟器而言,在轮次t,自然语言理解记为nlu
u_t
,用户动态状态为goal
u_t
,用户策略记为pol
u_t
,整个过程归纳为:
[0060][0061]
在经过transformer的序列预测过程中实现了自然语言理解、策略动作、自然语言生成的功能,具体实现如图2所示。
[0062]
对于系统而言,在轮次t,信念状态跟踪记为dst
s_t
,外部数据库搜索为db
s_t
,系统策略记为pol
s_t
,整个过程归纳为:
[0063][0064]
在经过transformer的序列预测过程中实现了信念状态跟踪、策略动作、自然语言生成的功能,具体实现如图3所示。
[0065]
对于训练过程中,用户模拟器的输入序列x
u_t
和对话系统的输入序列x
s_t
的构成方式为x
u_t
=[c
u_t
,nlu
u_t
,goal
u_t
,pol
u_t
,u
t
],x
s_t
=[c
s_t
,dst
s_t
,db
s_t
,pol
s_t
,s
t
]。语言模型的学习目标是学习词和词之间的转移概率分布p(x),可以很自然地使用概率计算的链式法则来分解这个分布并用参数训练一个神经网络θ,以最小化数据集d上的负对数似然函数对于预训练语言模型transformer的应用,实现了端到端的框架,从而解决了模块化优化的错误累计、错误传播以及无法达到全局最优的问题。
[0066]
对于联合优化更新,针对用户模拟器的损失函数l
user
和对话系统的损失函数l
sys
构成的整体损失函数l
user
l
sys
。本发明实施例使用版本4.2.2的huggingface transformers库实现用户模拟器和对话系统模型。我们使用distilgpt-2(gpt-2的精炼版本)对其进行初始化。在监督学习期间,批量大小(batch size)设置为2,梯度累积步骤为16,使用adamw优化器和线性调度器,有20个预热步骤和最大学习率设置为1e-4,梯度(clip)设置为5。总训练轮次为30(在nvidia tesla 2v100-sxm2-32gb上大约需要20小时)。
[0067]
本发明还公开一种端到端任务型对话系统,采用如上任一项所述的端到端任务型对话方法构建。
[0068]
以下对本发明实施例的端到端任务型对话方法进行性能分析。
[0069]
任务型对话的常用的公开数据集是multiwoz。multiwoz是一个多领域、多意图的面向任务的对话语料库,包含7个域、13个意图、25个槽值类型、10483个对话会话和71544个对话轮次。在数据收集过程中,要求用户遵循预先指定的用户目标,并在必要时允许在会话期间更改目标,因此收集的对话更接近现实世界的对话。该语料库还提供将所有实体和属性定义为外部数据库的领域知识。
[0070]
而关于评估任务型对话的成功率有两种方式:一是所提出的模型在multiwoz测试集上根据通知率(info)、成功率(succ)和机器翻译评价指标(bleu)进行评估。通知率衡量对话系统是否提供与用户目标匹配的正确实体,而成功率衡量进一步要求系统正确回答所有用户问题,bleu则是评估自然语言的流畅性。近来还有相关标准组合性能分数(combined score),计算为0.5*(info succ) bleu。二是利用1000个对话目标用于自动评估。当对话启动时,用户模拟器和系统围绕给定的用户目标相互交互。两个受过训练的策略之间的交互性能利用两个指标:通知率和匹配率match来估计对话成功率。这两个指标都是在对话行为级别计算的。info评估是否所有请求的信息都已被告知,匹配率检查预订的实体是否与用户给出的所有指示的约束匹配。并且仅当通知召回率和匹配率均为1时,才达到总体任务成功。其中对话成功率一般被认为最重要的指标。
[0071]
本发明实施例的实验结果如表1所示:
[0072]
表1本算法tftod在官方multiwoz测试集中的成绩
[0073][0074]
对其他基于transformer的任务型对话方法相比,本发明实施例的端到端任务型对话方法在动作、信念状态、数据库搜索结果、特殊词的表征上均有区别。本发明实施例的端到端任务型对话方法实现了最高的基于multiwoz测试集的对话成功率和组合性能分数,实现了目前transformer类的对话系统。同时针对用户模拟器和系统之间对话的成功率,也实现了目前任务型对话的最高成功率,如表2所示:
[0075]
表2本算法tftod在官方multiwoz测试集用户模拟器系统交互对话中的成绩
[0076][0077]
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
