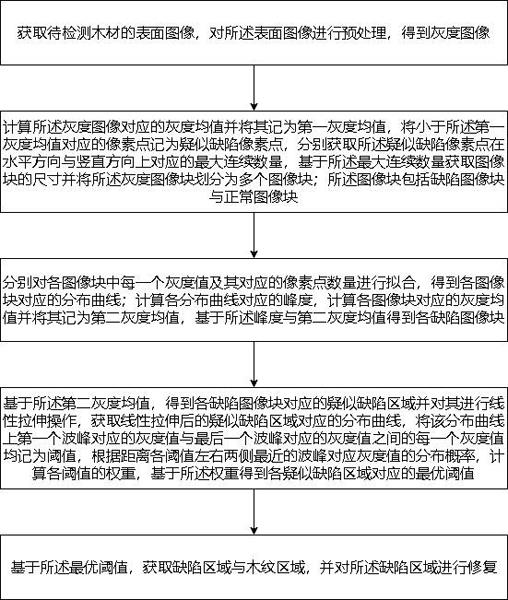
1.本发明涉及图神经网络技术领域,尤其涉及一种基于在线知识蒸馏的图神经网络模型压缩方法。
背景技术:
2.蒸馏模型是一种采用迁移学习的模型压缩方法,通过采用预先训练好的教师模型的输出作为监督信号去训练另一个简单的学生模型。这个过程传统上分为两个阶段:在第一阶段,教师模型被训练产生高精度的预测;在第二阶段,训练学生模型模仿教师的预测。
3.2020年,yan等人尝试学习一个称为tinygnn的小型图神经网络,它可以在短时间内推断节点表示,由于小型图神经网络不能像深层图神经网络那样探索那么多的局部结构,因此深层图神经网络和小型图神经网络之间存在着邻居信息的差距。为了解决这一问题,tinygnn利用对等节点信息对局部结构进行显式建模,并采用邻居蒸馏策略从更深层次的图神经网络中隐式学习局部结构知识。yang等人(yang y,qiu j,song m,et al.distilling knowledge from graph convolutional networks[c]//proceedings of the ieee/cvf conference on computer vision and pattern recognition.2020:7074-7083.)提出了一个局部结构保持模块,该模块显式地考虑了教师的拓扑语义。在这个模块中,教师和学生的局部结构信息被提取为分布,因此最小化这些分布之间的距离,使得教师可以实现拓扑感知的知识转移,从而产生一个紧凑而高性能的学生模型。此外,该方法很容易扩展到动态图模型,其中教师和学生的输入图可能不同。
[0004]
图神经网络中,在进行知识蒸馏时,效果依赖于教师-学生模型的设计。匹配的教师和学生模型设计,才能达到最好的模型压缩的效果。
技术实现要素:
[0005]
为了提升图神经网络模型压缩的效果,本发明提供一种基于在线知识蒸馏的图神经网络模型压缩方法。
[0006]
本发明提供的一种基于在线知识蒸馏的图神经网络模型压缩方法,包括:
[0007]
步骤1:构建n个图神经网络学生模型;
[0008]
步骤2:对原始图数据进行n次独立的图数据增强,得到n个不同的新的图数据,将n个新的图数据分别作为n个图神经网络学生模型的输入;
[0009]
步骤3:基于n个图神经网络学生模型的输出构建图神经网络教师模型的输出;
[0010]
步骤4:采用标准的交叉熵损耗,对所有网络进行端到端训练,并设置多任务损失函数,然后通过神经网络优化器最小化多任务损失函数的值以完成整个图神经网络模型的训练。
[0011]
进一步地,步骤1中,具体包括:
[0012]
根据模型压缩的要求,对图神经网络学生模型的模型参数进行设计以得到n个图神经网络学生模型,所述模型参数包括层数和/或注意力头数。
[0013]
进一步地,步骤4中,所述多任务损失函数如公式(1)所示:
[0014][0015]
其中,表示第i个图神经网络学生模型的输出logits与真实标签之间的交叉熵损失,表示第i个图神经网络学生模型的输出logits与图神经网络教师模型的输出logits之间的kl散度。
[0016]
进一步地,步骤4中,在公式(1)中引入权衡权重λ得到新的多任务损失函数:
[0017]
进一步地,按照公式(2)计算每个图神经网络学生模型的输出logits与图神经网络教师模型的输出logits之间的kl散度l
kd
:
[0018][0019]
其中,t是温度参数,p和q分别表示图神经网络教师模型和图神经网络学生模型产生的软化输出概率分布,n表示样本的总数量。
[0020]
本发明的有益效果:
[0021]
本发明提出一种基于在线知识蒸馏的图神经网络模型压缩方法,通过定义一组学生网络在整个训练过程中相互学习、相互指导的方式,避免了对教师模型和学生模型转换通路的定义。与传统的知识蒸馏的离线的两阶段方法(第一阶段训练教师模型,第二阶段训练学生模型)不同,本发明提出的方法可以通过一个阶段得到最终的学生目标模型。
附图说明
[0022]
图1为本发明实施例提供的图数据增强示意图;
[0023]
图2为本发明实施例提供的构建图神经网络教师模型输出的示意图;
[0024]
图3为本发明实施例提供的基于在线知识蒸馏的图神经网络模型的训练图。
具体实施方式
[0025]
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0026]
本发明实施例提供一种基于在线知识蒸馏的图神经网络模型压缩方法,包括以下步骤:
[0027]
s101:构建n个图神经网络学生模型;
[0028]
具体地,根据模型压缩的要求,对图神经网络学生模型的模型参数进行设计以得到n个图神经网络学生模型,所述模型参数包括层数和/或注意力头数。可以理解,当图神经网络学生模型采用的是图注意力网络时,模型参数还包括注意力头数。
[0029]
需要说明的是,n个图神经网络学生模型可以是相同类型的图神经网络模型,例如
都是gcn模型,但是各个学生模型的参数设置不同。n个图神经网络学生模型也可以为不同类型的图神经网络模型,例如gcn、gat、graphsage等。
[0030]
s102:对原始图数据进行n次独立的图数据增强,得到n个不同的新的图数据,将n个新的图数据分别作为n个图神经网络学生模型的输入;
[0031]
具体地,为了使学生模型具有不同的输入,对原始的图数据(邻接矩阵和特征矩阵)进行n次独立的图数据增强。需要说明的是,本发明实施例中,使用现有的图神经网络和图数据增强的方式即可。
[0032]
如图1所示,通过增加边、删除边、节点删除、属性掩盖等图数据增强方式,得到n个不同的图视图,作为上述的n个学生模型的输入。构造不同的输入是为了使学生模型之间存在差异,从而能够从不同的输入数据中学到不同的知识。
[0033]
s103:基于n个图神经网络学生模型的输出构建图神经网络教师模型的输出;
[0034]
具体地,教师模型虽然未显式的表达出来,但是教师模型的输出是通过结合n个学生模型的输出生成的,等价于构造了一个含有更多知识的教师模型,符合使用知识蒸馏进行模型压缩的前提。需要说明的是,在构建教师模型的输出时,可以采用不同的策略对n个学生模型的输出进行融合,本发明实施例对融合策略不作限制。
[0035]
如图2所示,假设第k个学生模型输出的logits为zk,教师模型的logits为z
t
。教师模型的logits通过所有学生模型的logits计算得到:z
t
=h(z1,z2,...,zn)。
[0036]
s104:采用标准的交叉熵损耗,对所有网络进行端到端训练,并设置多任务损失函数,然后通过神经网络优化器最小化多任务损失函数的值以完成整个图神经网络模型的训练。
[0037]
具体地,所有的学生模型都是从零开始训练的。作为一种可实施方式,所述多任务损失函数如公式(1)所示:
[0038][0039]
其中,表示第i个图神经网络学生模型的输出logits与真实标签之间的交叉熵损失,表示第i个图神经网络学生模型的输出logits与图神经网络教师模型的输出logits之间的kl散度。更进一步的,可以在公式(1)中加入权衡权重λ。设置合适的λ值(通常在0到1之间,根据具体任务进行调整),通过神经网络优化器,使损失函数的值不断下降完成模型的训练。加入衡量权重后的多任务损失函数为:
[0040]
其中,按照公式(2)计算每个图神经网络学生模型的输出logits与图神经网络教师模型的输出logits之间的kl散度l
kd
:
[0041][0042]
其中,t是温度参数,p和q分别表示图神经网络教师模型和图神经网络学生模型产生的软化输出概率分布,n表示样本的总数量。
[0043]
如图3所示,通过一系列的软目标生成方法,保证了不同能力的学生从协作学习中获益,增强了网络对输入扰动的不变性。因为所有的模型都可以独立地进行预测,因此改进
不会产生额外的测试计算成本。为了提高泛化性能,通过kd损失将软目标知识提取到各个学生模型中。知识蒸馏是在教师网络的监督下对学生网络进行优化。
[0044]
蒸馏模型是一种采用迁移学习的模型压缩方法,这个过程传统上分为两个阶段。在第一阶段,教师模型被训练产生高精度的预测。在第二阶段,训练学生模型模仿教师的预测。本发明提供的一种基于在线知识蒸馏的图神经网络模型压缩方法,通过定义一组学生网络在整个训练过程中相互学习、相互指导的方式,避免了对教师模型和学生模型转换通路的定义。与传统的知识蒸馏的离线的两阶段方法不同,本发明提出的方法可以通过一个阶段得到最终的学生目标模型。
[0045]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。