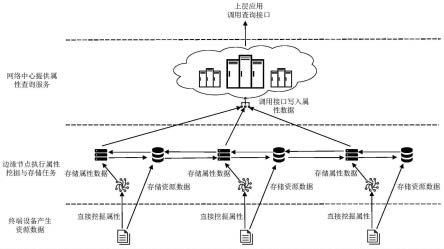
一种融合视觉回环检测的激光slam方法及系统
技术领域
1.本发明涉及机器人技术领域,具体涉及一种融合视觉回环检测的激光slam方法及系统。
背景技术:
2.同步定位与地图构建(slam)技术是指移动机器人通过传感器感知周围环境,估计自身位姿并且建立地图储存环境信息,完成对外部环境感知的过程,是移动机器人智能化的关键技术和先决条件。slam系统可分为前端里程计、回环检测、后端优化和地图构建四部分。
3.回环检测是指机器人再次经过同一地点时,检测到当前时刻与某历史时刻之间的场景一致性,并建立两时刻之间位姿状态的关联关系。机器人可根据当前位姿与历史位姿之间的联系来消除运行过程中的累积误差,获得更加精确的定位与建图结果。激光slam是前端应用激光雷达的slam系统,在激光slam中,待匹配历史帧的数量随系统运行而不断增长,激光回环检测算法的准确性与实时性难以同时保证,导致定位误差逐渐累积,进而影响系统定位与建图的精度。
技术实现要素:
4.为了解决上述技术问题,本发明提供一种融合视觉回环检测的激光slam方法及系统。
5.本发明技术解决方案为:一种融合视觉回环检测的激光slam方法,包括:
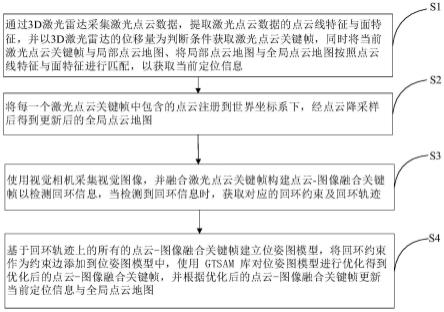
6.步骤s1:激光里程计:通过3d激光雷达采集激光点云数据,提取所述激光点云数据的点云线特征与面特征,并以所述3d激光雷达的位移量为判断条件获取激光点云关键帧,同时将当前所述激光点云关键帧与局部点云地图、将所述局部点云地图与全局点云地图按照所述点云线特征与面特征进行匹配,以获取当前定位信息;
7.步骤s2:地图构建:将每一个所述激光点云关键帧中包含的点云注册到世界坐标系下,经点云降采样后得到更新后的全局点云地图;
8.步骤s3:视觉回环检测:使用视觉相机采集视觉图像,并融合所述激光点云关键帧构建点云-图像融合关键帧以检测回环信息,当检测到回环信息时,获取对应的回环约束及回环轨迹;
9.步骤s4:全局图优化:基于所述回环轨迹上的所有的所述点云-图像融合关键帧建立位姿图模型,将所述回环约束作为约束边添加到所述位姿图模型中,使用gtsam库对所述位姿图模型进行优化得到优化后的点云-图像融合关键帧,并根据所述优化后的点云-图像融合关键帧更新当前所述定位信息与所述全局点云地图。
10.本发明与现有激光slam技术相比,具有以下优点:
11.本发明公开了一种融合视觉回环检测的激光slam方法及系统,将视觉图像结合到激光回环检测中,通过视觉图像的词袋模型可将包含大量信息的图像数据转化为词袋向
量,极大地减少了场景匹配的计算量,提高了图像匹配效率,保证回环检测的实时性。最终将视觉回环应用到全局图优化中,减小了累积误差,提高激光slam系统定位与建图的精度。
附图说明
12.图1为本发明实施例中一种融合视觉回环检测的激光slam方法的流程图;
13.图2为本发明实施例中视觉词典的构建过程示意图;
14.图3a为本发明实施例中为无回环检测模块的loam建图结果示意图;
15.图3b为本发明实施例中是使用本发明提供的方法得到的建图结果示意图;
16.图4为本发明实施例中一种融合视觉回环检测的激光slam系统的结构框图。
具体实施方式
17.本发明提供了一种融合视觉回环检测的激光slam方法,减小了累积误差,提高激光slam系统定位与建图的精度。
18.为了使本发明的目的、技术方案及优点更加清楚,以下通过具体实施,并结合附图,对本发明进一步详细说明。
19.实施例一
20.如图1所示,本发明实施例提供的一种融合视觉回环检测的激光slam方法,包括下述步骤:
21.步骤s1:激光里程计:通过3d激光雷达采集激光点云数据,提取激光点云数据的点云线特征与面特征,并以3d激光雷达的位移量为判断条件获取激光点云关键帧,同时将当前激光点云关键帧与局部点云地图、将局部点云地图与全局点云地图按照点云线特征与面特征进行匹配,以获取当前定位信息;
22.步骤s2:地图构建:将每一个激光点云关键帧中包含的点云注册到世界坐标系下,经点云降采样后得到更新后的全局点云地图;
23.步骤s3:视觉回环检测:使用视觉相机采集视觉图像,并融合激光点云关键帧构建点云-图像融合关键帧以检测回环信息,当检测到回环信息时,获取对应的回环约束及回环轨迹;
24.步骤s4:全局图优化:基于回环轨迹上的所有的点云-图像融合关键帧建立位姿图模型,将回环约束作为约束边添加到位姿图模型中,使用gtsam库对位姿图模型进行优化得到优化后的点云-图像融合关键帧,并根据优化后的点云-图像融合关键帧更新当前定位信息与全局点云地图。
25.在一个实施例中,上述步骤s1:激光里程计:通过3d激光雷达采集激光点云数据,提取激光点云数据的点云线特征与面特征,并以3d激光雷达的位移量为判断条件获取激光点云关键帧,同时将激光点云关键帧与局部点云地图、将局部点云地图与全局点云地图按照点云线特征与面特征进行匹配,以获取当前定位信息,具体包括:
26.首先,在车辆上安装3d激光雷达,可在一个工作周期旋转360
°
采集激光点云数据,并提取激光点云数据的点云线特征与面特征,同时,计算3d激光雷达运行时的位移量,当位移量超过预定的阈值时创建一帧激光点云关键帧,本发明中阈值设为0.5m,并在当前工作周期[tk,t
k 1
]的t
k 1
时刻发布该激光点云关键帧。
[0027]
其次,将激光点云关键帧与局部点云地图进行特征匹配,以10hz的频率进行位姿估计,实现了高频里程计粗定位功能;再将局部点云地图与全局点云地图以1hz的频率进行匹配,实现低频里程计精定位功能,从而获取当前定位信息。
[0028]
在一个实施例中,上述步骤s2:地图构建:本发明采用了基于关键帧的点云地图构建方法,即将步骤s1得到的每一个激光点云关键帧中包含的点云注册到世界坐标系下,经点云降采样后得到更新后的全局点云地图。
[0029]
在一个实施例中,上述步骤s3中使用视觉相机采集视觉图像,并融合激光点云关键帧构建点云-图像融合关键帧,具体包括:
[0030]
步骤s301:获取距离时刻t
k 1
最近的t
p
时刻的视觉图像作为视觉图像关键帧与t
k 1
时刻发布的激光点云关键帧进行关联,构成初始点云-图像融合关键帧,其中,t
p
在工作周期[tk,t
k 1
]之间;
[0031]
由于激光雷达点云关键帧和视觉图像关键帧的采集设备不一样,因此二者的时间戳不一样,因此需要对初始点云-图像融合关键帧中所包含的所有激光点云数据通过线性插值方法进行运动补偿,使其在激光雷达坐标系下,与视觉图像关键帧时间戳进行统一,以实现激光点云关键帧与视觉图像关键帧的时间戳同步。
[0032]
步骤s302:对[tk,t
k 1
]时间内初始点云-图像融合关键帧所包含的激光点云数据通过线性插值方法进行运动补偿,首先如公式(1)所示,计算初始点云-图像融合关键帧在ti时刻点云xi在[tk,ti]之间的位姿变换t
k,i
,同理可计算[tk,t
p
]之间的位姿变换t
k,p
如公式(2):
[0033][0034][0035]
其中,t
k,k 1
是激光点云数据在激光点云时间戳[tk,t
k 1
]之间的位姿变换,可由激光里程计直接获得;
[0036]
将初始点云-图像融合关键帧中的点云xi利用位姿变换t
k,i
转换到tk时刻坐标下,得到点云xk,再将点云xk利用位姿变换t
k,p
转换到视觉图像时间戳t
p
时刻下,得到与视觉图像的时间戳同步的x
p
,实现了激光点云与视觉图像的时间同步,得到运动补偿后的点云-图像融合关键帧。
[0037]
在一个实施例中,上述步骤s3中检测回环信息、获取对应的回环约束及回环轨迹具体包括:
[0038]
步骤s311:选用orb特征对已有的视觉图像样本集提取特征点集合,使用kmeans算法对特征点集合进行聚类,将聚类结果作为单词并以树形数据结构存储,构建视觉词典;
[0039]
本发明实施例使用dbow3库构建视觉词典,选用具有高实时性的orb特征对大量视觉图像样本进行特征提取,再使用kmeans算法对特征点集合进行聚类,将聚类结果作为单词并以树形数据结构存储,实现视觉词典的构建。
[0040]
步骤s312:对当前视觉图像关键帧进行orb特征提取得到特征点,在视觉词典中查询特征点对应单词出现的词频,采用tf-idf方法计算每个单词的分数,得到当前视觉图像关键帧的词袋向量vk(v1,v2,
···
vn);
[0041]
如图2所示,展示了视觉词典的构建过程,以及利用视觉词典生成单幅视觉图像的
词袋向量的过程。
[0042]
步骤s313:遍历所有历史点云-图像融合关键帧,将其中历史点云-图像融合关键帧中所对应的视觉图像作为历史视觉图像关键帧,并获取所有历史视觉图像关键帧的词袋向量vh(v1,v2,
···
vn),并根据公式(3)~(4)计算vk(v1,v2,
···
vn)与vh(v1,v2,
···
vn)的曼哈顿距离s得到二者图像相似度η,选取相似度η最高且大于阈值t的历史帧作为回环关键帧:
[0043][0044][0045]
其中,vi∈vk,vj∈vh,s
(k,h)
为vk和vh之间的曼哈顿距离用来表示词袋向量距离;s
(k,k-1)
)表示当前视觉图像关键帧与前一视觉图像关键帧之间的词袋向量距离;
[0046]
步骤s314:将检测到回环关键帧的点云-图像融合关键帧的点云特征点投影到视觉图像关键帧,得到视觉图像关键帧特征点二维像素坐标,采用三点估计的方法对二维像素坐标进行深度赋值,可得到当前视觉图像关键帧特征点的三维空间坐标;
[0047]
步骤s315:利用特征点的三维空间坐标,将特征点与回环关键帧进行特征点匹配,应用pnp算法构建重投影误差模型,通过l-m算法优化求解式(x)最小二乘问题,可得到回环约束。
[0048]
在一个实施例中,上述步骤s4:全局图优化:基于回环轨迹上的所有的点云-图像融合关键帧建立位姿图模型,将回环约束作为约束边添加到位姿图模型中,使用gtsam库对位姿图模型进行优化得到优化后的点云-图像融合关键帧,并根据优化后的点云-图像融合关键帧更新当前定位信息与全局点云地图。
[0049]
本发明实施例使用kitti数据集的sequence_05对本发明提出的融合视觉回环检测的激光slam方法及系统进行实验评估,图3a为无回环检测模块的loam建图结果,在方框处建图结果与真实地图的道路点云不匹配,图3b为使用本发明提供的方法得到的建图结果,在方框处建图结果道路点云清晰,与真实地图的道路点云匹配良好。
[0050]
此外,本发明实施还采用绝对位姿误差(absolute pose error,ape)对轨迹精度进行分析,ape定义为实验估计位姿与真实位姿之差的绝对值,此项指标可以直观的衡量实验轨迹与真实轨迹的接近程度。从表1中可以看出,在数据集sequence_05上使用ape统计指标,本发明相比于无回环检测模块的loam方法均方根误差减少了65.0%,误差平均值减少了59.4%,误差最大值减少了73.6%,因此,使用本发明方法得到的轨迹精度显著提高。
[0051]
表1 ape统计指标对比(单位:m)
[0052]
统计指标loam方法本发明方法轨迹均方根误差11.76994.1118误差平均值9.26483.7937误差中位数5.95683.9271误差标准差7.25891.5856误差最大值33.55598.8587
[0053]
本发明公开了一种融合视觉回环检测的激光slam方法,将视觉图像结合到激光回环检测中,通过视觉图像的词袋模型可将包含大量信息的图像数据转化为词袋向量,极大
地减少了场景匹配的计算量,提高了图像匹配效率,保证回环检测的实时性。最终将视觉回环应用到全局图优化中,减小了累积误差,提高激光slam系统定位与建图的精度。
[0054]
实施例二
[0055]
如图4所示,本发明实施例提供了一种融合视觉回环检测的激光slam系统,包括下述模块:
[0056]
激光里程计模块51,用于通过3d激光雷达采集激光点云数据,提取激光点云数据的点云线特征与面特征,并以3d激光雷达的位移量为判断条件获取激光点云关键帧,同时将激光点云关键帧与局部点云地图、将局部点云地图与全局点云地图按照点云线特征与面特征进行匹配,以获取当前定位信息;
[0057]
地图构建模块52,用于将每一个激光点云关键帧中包含的点云注册到世界坐标系下,经点云降采样后得到更新后的全局点云地图;
[0058]
视觉回环检测模块53,用于使用视觉相机采集视觉图像,并融合激光点云关键帧构建点云-图像融合关键帧以检测回环信息,当检测到回环信息时,获取对应的回环约束及回环轨迹;
[0059]
全局图优化模块54,用于基于回环轨迹上的所有的点云-图像融合关键帧建立位姿图模型,将回环约束作为约束边添加到位姿图模型中,使用gtsam库对位姿图模型进行优化得到优化后的点云-图像融合关键帧,并根据优化后的点云-图像融合关键帧更新当前定位信息与全局点云地图。
[0060]
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。