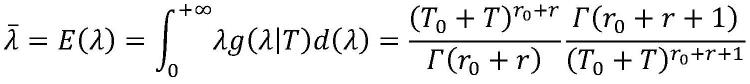
1.本发明属于数字图像处理技术领域,具体涉及一种基于注意力解码网络的航拍图像实时语义分割方法。
背景技术:
2.目前语义分割的实时性可采用三种策略实现:1)采用多分支卷积,2)利用卷积轻量化算法,3)利用轻量级骨干网络。多分支卷积网络icnet、bisenet和bisenetv2分离特征提取的策略虽然高效,但会造成语义信息分离。卷积轻量化算法虽然能提高网络的实时性,例如erfnet、enet、dabnet和adscnet,但是过度的轻量化使网络的特征提取能力变差。航拍图像分割网络abisenet是一种轻量级的双路径深度卷积结构,以感受域模块(rfm)为编码器,但其忽略了专用性使得分割的准确性降低。与其他轻量级网络相比,mobilenetv2的倒瓶颈式的卷积结构弥补了卷积轻量化算法造成特征提取能力不足的问题。
3.航拍图像非均匀的物体分布和语义分割网络高的下采样率,造成了对航拍图像进行语义分割存在轮廓信息丢失严重的问题。目前,解决语义分割网络轮廓信息丢失过多的策略有:1)低下采样率,2)多尺度特征融合,3)反池化上采样。erfnet、dabnet和adscnet的8倍下采样率保留了充足的轮廓信息,enet和segnet利用反池化恢复特征映射的轮廓信息。与低下采样率和反池化策不同,fcn、linknet和unet的多尺度特征混合方式具有内存消耗小和计算量低的优势,被广泛地用于获取轮廓信息,但是简单的多尺度特征混合方式降低了网络的准确性。
4.航拍图像物体形态不明显和角度多变的特点要求语义分割网络捕获充足的语义信息,多尺度特征聚集和注意力机制是满足这一要求的两种策略。deeplabev3的带孔空间金字塔池化和pspnet的金字塔池化模块是多尺度特征聚集的典型代表,但是这种在通道间获取的语义信息是不充足的。因此,nl在解码器中引入注意力机制,但是其存在高计算量和内存消耗的问题。anl和attanet的注意力机制虽然内存消耗和计算量低,但池化下采样造成信息丢失。
技术实现要素:
5.本发明针对现有技术的不足,提供一种基于注意力解码网络的航拍图像实时语义分割方法,该方法提出了注意力解码网络,采用mobilenetv2为骨干网络提高实时性推理速度,提出交叉注意力混合机制解决轮廓信息缺失的问题,提出金字塔注意力模块消除卷积神经网络无法捕获长范围语义信息的局限性。
6.为了达到上述目的,本发明提供的技术方案是一种基于注意力解码网络的航拍图像实时语义分割方法,包括以下步骤:
7.步骤1,准备图像数据集用于训练和测试。
8.步骤2,构建基于注意力解码网络的航拍图像实时语义分割网络。
9.步骤3,使用训练集图像对基于注意力解码网络的航拍图像实时语义分割网络模
型进行训练。
10.步骤4,使用步骤3训练好的网络模型对测试集图像进行分割,得到图像语义分割结果。
11.而且,所述步骤1中对训练集中的图像进行左右、上下翻转、随机裁剪来扩充数据集。
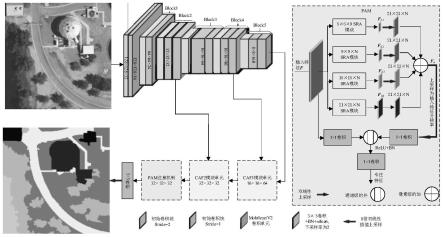
12.而且,所述步骤2中航拍图像实时语义分割网络以mobilenetv2为编码器,以两个交叉注意力混合模块caf1、caf2和金字塔注意力模块pam构成专注解码器。将mobilenetv2编码器的卷积块block2和block4的输出特征作为浅层特征分别注入到交叉注意力混合模块caf2和caf1,同时将卷积块block5作为深层特征注入caf1中,pam被附着在解码器的尾部以捕获长范围语义信息。
13.将编码块block2、block4和block5以及caf1和caf2的输出作为辅助损耗分支,所有的辅助损耗分支均无上采样操作,航拍图像实时语义分割网络的损耗函数定义如下:
[0014][0015]
式中,l为网络的总损耗,l
main
表示网络端到端的损耗,li表示辅助损耗分支的损耗,所有损耗函数均为交叉熵损耗函数,λ为各辅助损耗分支的权重。
[0016]
caf模块对输入的浅层特征、深层特征进行交叉注意力引导可用式(2)和式(3)表示:
[0017][0018][0019]
式中,m
l
为浅层亲和特征,mh为深层亲和特征,f
l
为浅层特征,fh为深层特征,ψ(
·
)为全局平均池化,f(
·
)表示1
×
1卷积,γ(
·
)表示反置卷积。
[0020]
caf将深层特征fh和浅层通道权值进行交叉引导获得深层亲和特征mh,将浅层特征f
l
与深层通道权值进行交叉引导获得浅层亲和特征m
l
,然后将浅层亲和特征m
l
和深层亲和特征mh进行像素级的加混合并使用1
×
1卷积f(
·
)修正混合特征,最后将混合特征和深层上采样特征γ(fh)再次进行像素级的加混合。
[0021]
caf模块的混合操作表示如下:
[0022]ffusion
=f(m
l
mh) γ(fh)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0023]
式中,f
fusion
为cfa模块得到的混合特征,f(
·
)表示1
×
1卷积,γ(
·
)表示反置卷积。
[0024]
pam由大小为5
×
5、9
×
9、15
×
15和21
×
21的4个小分辨率注意力模块sra构成的金字塔状的注意力机制,sra首先对输入特征f应用双线性下采样获得低分辨率特征f',然后对f'使用三个1
×
1卷积f(
·
)以生成键值k、特征值v和查询值q,对重塑键值k'与转置重塑查询值q'
t
的点积生成注意力矩阵w。
[0025]
sra模块生成注意力矩阵w的过程可表示为:
[0026][0027]
式中,n=w
×
h,为softmax柔性函数,c为语义类别数。
[0028]
注意力矩阵w和重铸特征值v'的点积,可公式化为:
[0029][0030]
式中,f
out
为最终输出的特征,n=w
×
h,为softmax函数,f(
·
)表示1
×
1卷积,c为语义类别数。
[0031]
而且,所述步骤3中采用动量为0.9的随机梯度下降优化器sgd,学习率初始值设为1
×
e-2
。采用“ploy”学习率衰减策略,实验最小训练批为16,总共训练300周期。模型的评价方法为平均交并比miou和像素准精度pa。
[0032]
miou的定义如下:
[0033][0034]
式中,k为标签类别数,tpi、fpi和fni分别为类别i的真实交集、非交集和假交集。
[0035]
pa的定义如下:
[0036][0037]
式中,p
ii
为类别i正确预测的像素数,p
ij
为总体像素数,k为标签类别数。
[0038]
与现有技术相比,本发明具有如下优点:
[0039]
基于注意力解码网络的航拍图像实时语义分割网络以mobilenetv2为编码器,以caf和pam模块构成专注解码器。caf和pam的轻量化设计使网络的性能进一步的提高,pam捕获到充足的上下文信息,满足了航拍图像语义分割对充足上下文信息的要求,caf模块交叉专注混合方式解决了航拍图像语义分割网络的高下采样率造成空间信息丢失的问题。
附图说明
[0040]
图1为本发明实施例的网络总体架构。
[0041]
图2为本发明实施例的caf模块结构图。
[0042]
图3为本发明实施例的sra模块结构图。
[0043]
图4为本发明与其他几种先进方法的可视化比较图,其中图4(a)为原图,图4(b)为
标签,图4(c)(d)(e)(f)分别为enet、epfnet、bisenetv2和本发明提出网络可视化的结果。
[0044]
图5为带有caf模块的可视化图,其中图5(a)为原图,图5(b)为标签,图5(c)为仅有骨干网络的可视化结果,图5(d)为带有caf模块的可视化结果。
[0045]
图6为带有pam模块的可视化图,其中图6(a)为原图,图6(b)为标签,图6(c)为仅有骨干网络的可视化结果,图6(d)为带有pam模块的可视化结果。
具体实施方式
[0046]
本发明提供一种基于注意力解码网络的航拍图像实时语义分割方法,下面结合附图和实施例对本发明的技术方案作进一步说明。
[0047]
本发明实施例的流程包括以下步骤:
[0048]
步骤1,准备图像数据集用于训练和测试。
[0049]
采用dlrsd数据集,总共包含2100张图像,每张图像分辨率为256
×
256
×
3,空间像素距离为30厘米(1英尺),被人为的标注为17个语义类。在dlrsd数据集中的每个类随机挑选出10张图像作为测试数据集,应用左右、上下翻转,采用尺度为[0.8,1.3]的随机裁剪进行数据增强处理。
[0050]
步骤2,构建基于注意力解码网络的航拍图像实时语义分割网络。
[0051]
航拍图像实时语义分割网络以mobilenetv2为编码器,以两个交叉注意力混合模块caf1、caf2和金字塔注意力模块pam构成专注解码器,总体结构如图1所示。
[0052]
将mobilenetv2编码器的卷积块block2和block4的输出特征作为浅层特征分别注入到交叉注意力混合模块caf2和caf1,同时将卷积块block5作为深层特征注入caf1中,pam被附着在解码器的尾部以捕获长范围语义信息。将编码块block2、block4和block5以及caf1和caf2的输出作为辅助损耗分支。为了加快收敛速度,所有的辅助损耗分支均无上采样操作。因此,航拍图像实时语义分割网络的损耗函数可定义如下:
[0053][0054]
式中,l为网络的总损耗,l
main
表示网络端到端的损耗,li表示辅助损耗分支的损耗,所有损耗函数均为交叉熵损耗函数,λ为各辅助损耗分支的权重。
[0055]
交叉注意力混合模块caf的结构如图2所示。与attanet混合模块的通道权值生成方式不同,caf分别生成深层通道权值和浅层通道权值的方式使得通道权值更具引导性。在注意力引导方面,caf与bisenetv2的bga(bilateral guided aggregation)类似,均为交叉的注意力引导方式。不同的是,caf为通道注意力引导的过程,避免了bga空间注意力权值引导力不强的问题。caf模块对输入的浅层特征、深层特征进行交叉注意力引导用式(2)和式(3)表示:
[0056][0057][0058]
式中,m
l
为浅层亲和特征,mh为深层亲和特征,f
l
为浅层特征,fh为深层特征,ψ(
·
)为全局平均池化,f(
·
)表示1
×
1卷积,γ(
·
)表示反置卷积。
[0059]
caf将深层特征fh和浅层通道权值进行交叉引导获得深层亲和特征mh,将浅层特征f
l
与深层通道权值进行交叉引导获得浅层亲和特征m
l
。caf交叉的注意力机制避免了attanet混合特征通道权值存在的引导低效率问题。为了提高性能,caf将浅层亲和特征m
l
和深层亲和特征mh进行像素级的加混合并使用1
×
1卷积f(
·
)修正混合特征。caf将混合特征和深层上采样特征γ(fh)再次进行像素级的加混合,避免了类似icnet的信息丢失问题。因此,caf模块的混合操作可表示如下:
[0060]ffusion
=f(m
l
mh) γ(fh)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0061]
式中,f
fusion
为cfa模块得到的混合特征,f(
·
)表示1
×
1卷积,γ(
·
)表示反置卷积。
[0062]
金字塔注意力模块pam的结构如图1右侧方框所示。在图1中,pam是由大小为5
×
5、9
×
9、15
×
15和21
×
21的4个小分辨率注意力模块(small resolution attention,sra)构成的金字塔状的注意力机制。小分辨率注意力模块sra的结构如图3所示,首先对输入特征f应用双线性下采样获得低分辨率特征f',简化了特征映射关键信息的表达,降低注意力机制高的内存消耗和计算量,然后对f'使用三个1
×
1卷积f(
·
)以生成键值k、特征值v和查询值q,对重塑键值k'与转置重塑查询值q'
t
的点积生成注意力矩阵w。
[0063]
sra模块生成注意力矩阵w的过程可表示为:
[0064][0065]
式中,n=w
×
h,为softmax柔性函数,c为语义类别数。
[0066]
注意力矩阵w和重铸特征值v'的点积,可公式化为:
[0067][0068]
式中,f
out
为最终输出的特征,n=w
×
h,为softmax函数,f(
·
)表示1
×
1卷积,c为语义类别数。
[0069]
虽然pam由4个sar模块构成,但是总体的计算量和内存消耗为6(5
×
5 9
×
9 15
×
15 21
×
21),小于nl6(w
×
h)的计算量和内存消耗。
[0070]
如图1中的右侧方框所示,pam将低分辨率sar模块的注意力特征f
a1
、f
a2
和f
a3
上采样到21
×
21
×
n的分辨率后与f
a4
进行加混合,提高了注意力的强度,避免了单种长范围语义信息捕获的低效性问题。pam分别对输入特征f与上采样的注意力混合特征fa使用1
×
1卷积f(
·
)提炼特征,并进行通道级的并混合,避免了信息丢失的问题。pam最后的1
×
1卷积f(
·
)用于选择混合特征。从图1中可以看出,pam可以同时完成多尺度特征聚集和注意力机制,因此引导能力强。
[0071]
步骤3,使用训练集图像对基于注意力解码网络的航拍图像实时语义分割网络模型进行训练。
[0072]
采用动量为0.9的随机梯度下降优化器(stochastic gradient descent,sgd),学习率初始值设为1
×
e-2
。采用“ploy”学习率衰减策略,实验最小训练批为16,总共训练300周期。模型的评价方法为平均交并比(mean intersection over union,miou)和像素准精度(pixel accuracy,pa)。
[0073]
miou的定义如下:
[0074][0075]
式中,k为标签类别数,tpi、fpi和fni分别为类别i的真实交集、非交集和假交集。
[0076]
pa的定义如下:
[0077][0078]
式中,p
ii
为类别i正确预测的像素数,p
ij
为总体像素数,k为标签类别数。
[0079]
步骤4,使用步骤3训练好的网络模型对测试集图像进行分割,得到图像语义分割结果。
[0080]
1对比实验结果分析
[0081]
(1)实时性比较
[0082]
本发明提出的网络在p1=256
×
256
×
3、p2=512
×
512
×
3和p3=1024
×
1024
×
3的图像分辨率中,与enet、erfnet和bisenetv2进行实时性比较。为了保证比较的公平性,所有网络均在单张gtx 3090卡上进行,结果如表1所示。
[0083]
表1实时性比较结果
[0084][0085]
在表1中,本发明提出的网络在p1和p2的输入下,获得最快的推理速度。由于注意力机制高的内存消耗问题,当分辨率增加到p3时本发明提出的网络的推理速度比erfnet少了3.5fps,出现明显的下降。然而,与同样使用多尺度特征混合bisenetv2相比,本发明提出的网络的推理速度高出0.3fps。
[0086]
(2)网络的轻量化比较
[0087]
对于轻量化的比较,本发明提出的网络在256
×
256
×
3的分辨率输入下,以flops、参数量和miou作为评价指标,比较结果如表2所示。
[0088]
表2轻量化比较
[0089][0090][0091]
在表2中,enet在轻量化方面突出,但本发明提出的网络的miou比enet高出了1.9%。表2的实验结果表明,本发明提出的网络不仅有较高的轻量化,同时取得最高73.4%的miou得分。因此,本发明提出的网络在准确性和轻量化之间取得了平衡。
[0092]
(3)网络的预测准确性比较
[0093]
表3为本发明提出的网络分割准确性的比较结果。
[0094]
表3与基准模型的比较
[0095][0096]
enet和erfnet低的大尺度物体miou得分表明,低下采样率无法捕获长范围语义信息。bisenetv2在大尺度和小尺度物体均表现出色,但多路径降低了网络的实时性。在表3中,本发明提出的网络在总体miou和pa上分别获得73.4%和85.4%的最高分。本发明提出的网络对土地、庭院、场地、路面和罐箱等大尺度物体分割高的miou得分,说明了pam模块有充足的长范围语义信息。本发明提出的网络对飞机、树木、码头、绿草和船只等小物体分割高的miou得分,则表明了caf模块有充足的轮廓信息。
[0097]
为了辅助论证,对实验结果进行了可视化,如图4所示。在图4白色方框圈出的物体中,本发明提出的网络的分割结果轮廓清晰可辨,物体形体适中,这证实了即使下采样率为32倍,caf模块依然获得充足的轮廓信息。本发明提出的网络对图4中白色方框的交叉路分割清晰,对储气罐的道路及其场地的分割明显,对交叉路口四周的房屋更加完整的分割,表明pam模块捕获充足的长范围语义信息。
[0098]
2消融实验分析
[0099]
对于消融实验,采用添加或去除pam以及上采样代替caf的控制变量法,实验结果如表4所示。
[0100]
表4对网络的性能分析
[0101][0102]
在表4中,骨干网络具有最少的flops和参数量,但只获得67.13%的miou得分。骨干网络带caf模块使flops和参数量分别增加了0.23g和0.06m,但是miou提高了5.71%。骨干网络带pam模块使flops和参数量微量增加,但是分割miou却提高了3.1%。网络在添加caf和pam模块后使flops和参数量分别增加了0.27g和0.08m,但是miou却提升了6.34%。显然,caf和pam使网络的flops和计算量有微量增加,但是分割准确性却取得极大的提高,说明caf和pam计算的高效性和分割的有效性。
[0103]
为了使论述清晰,测量caf、pam和总体网络每个类的miou得分。实验结果如表5所示。
[0104]
表5对模型带有caf和pam的实验比较
[0105][0106]
在表5中,caf模块对飞机、汽车、动房、路面和船只等小物体高的miou得分,表明caf获取充足的轮廓信息。网络带有pam模块擅长分割建筑、灌木、庭院和路面等复杂物体,则证实了pam有捕获到充足的长范围语义信息。
[0107]
为了直观地论述caf和pam模块的有效性,对预测结果进行可视化,如图5和图6所示。在图5中白色方框圈出区域,caf模块对飞机和高尔夫球场等小物体目标的分割轮廓清晰,错误分类少,这说明caf的交叉注意力有效的抑制浅层的噪声,提炼深层语义信息。在图6中白色方框中,飞机与其临近的汽车分割准确,路上的汽车轮廓明显,交叉路口的临近场地分离明显,这表明pam模块捕获到充足的长范围语义信息,提高了网络对复杂场景的语义信息分辨能力。
[0108]
具体实施时,以上流程可采用计算机软件技术实现自动运行流程。
[0109]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。