通过基于知识蒸馏的nas进行大型模型仿真
技术领域
1.本发明涉及通过更小、更高效的模型在机器学习中模拟大型、高容量模型。
背景技术:
2.在机器学习中,深度神经网络等大型模型可能具有较高的知识容量,但并非始终得到充分利用。评估此类模型的计算成本可能较高。此外,在计算机上开发和训练的最新机器学习模型无法始终部署在较小、计算复杂度较低的设备上。这可能是由于模型太大无法存储在设备的存储器中,或者只是需要执行设备硬件不支持的操作。
3.知识蒸馏(knowledge distillation,kd)可用于将知识从最新教师模型传输到较小的学生模型。这种方法的主要限制在于需要手动精心设计学生模型,这通常极其困难且耗时。
4.剪枝、量化和分解是可用于简化高容量最新模型的方法。然而,这些方法不能更改所使用的具体操作,因此在使用不受支持的操作时没有任何帮助。
5.liu yu等人在ieee/cvf国际计算机视觉与模式识别会议会刊所发表文章“从搜索到蒸馏:千里马常有而伯乐不常有(search to distill:pearls are everywhere but not the eyes)”(2020年)中公开的方法等可以自动搜索学生模型。然而,这种方法的效率可能较低,无法进行真正的多目标优化。
6.需要开发一种能够克服这些问题的大型模型仿真方法。
技术实现要素:
7.根据一方面,本文提供了一种由一台或多台计算机实现的机器学习机制,所述机制可以访问基础神经网络且用于通过迭代地执行以下一组步骤来确定简化神经网络:通过对当前候选神经网络的架构进行采样来形成样本数据;根据所述样本数据,选择第二候选神经网络的架构;通过训练所述第二候选神经网络形成经过训练的候选神经网络,其中,所述训练所述第二候选神经网络包括根据所述第二候选神经网络和所述基础神经网络的行为比较,将反馈应用到所述第二候选神经网络;采用所述经过训练的候选神经网络作为所述当前候选神经网络,用于所述一组步骤的后续迭代。这可能使得能够对可模拟更大基础网络的候选神经网络进行训练。所述机制可以在预期任务中实现卓越性能,并且具有自动适应不同需求的灵活性。因此,不需要人类专家。
8.所述机器学习机制包括:在所述一组步骤的多次迭代之后,将所述当前候选神经网络作为所述简化神经网络输出。这可能使得能够确定展现良好性能的简化神经网络。
9.与所述基础神经网络相比,所述简化神经网络具有更小的容量和/或实现的计算密集度更低。这可能使得所述简化网络能够在计算能力低于训练所述模型的所述计算机的设备上运行。
10.可以通过贝叶斯优化来执行所述选择第二候选神经网络的架构的步骤。这是因为贝叶斯优化框架的数据效率非常高,并且在评估成本高昂、无法获得导数以及相关函数是
非凸和多模态函数的情况下特别有用。在这些情况下,贝叶斯优化能够利用优化历史提供的全部信息来提高搜索效率。
11.可以通过多目标贝叶斯优化来执行所述选择第二候选神经网络的架构的步骤。这可能使得能够找到不仅具有最佳准确度而且根据次要(或其它)目标执行的架构。
12.可以通过具有一个或多个目标的贝叶斯优化来执行所述选择第二候选神经网络的架构的步骤,其中,所述目标中的至少一个是指以下各项中的一个或多个:(i)提高所述第二候选神经网络的分类准确度,(ii)降低所述第二候选神经网络的计算密集度。这可能使得能够为所述简化神经网络确定比所述基础网络精确度更高和/或计算密集度更低的网络架构。
13.可以通过根据预定采集函数对所述当前候选神经网络进行采样,来形成所述样本数据。这可能是形成所述样本数据的有效方法。
14.可以通过优化网络架构的随机图来执行所述选择第二候选神经网络的架构的步骤。优化架构的随机分布而不是确定性架构本身,可能以较低的成本提供具有较高准确度的结果。这可能使得能够确定所述学生模型的最佳网络架构。
15.所述形成经过训练的候选神经网络的步骤可以包括:使得所述第二候选神经网络执行多个任务,使得所述基础神经网络执行所述多个任务,并根据所述第二候选神经网络和所述基础神经网络在执行所述任务时的性能差异来修改所述第二候选神经网络。这可能使得能够确定准确的学生模型。
16.所述机制可以访问经过训练的神经网络且可以用于通过迭代地执行以下一组步骤来确定所述基础神经网络:通过对当前候选基础神经网络的架构进行采样来形成样本数据;根据所述样本数据,选择第二候选基础神经网络的架构;通过训练所述第二候选基础神经网络形成经过训练的候选基础神经网络,其中,所述训练所述第二候选基础神经网络包括根据所述第二候选基础神经网络和所述经过训练的神经网络的行为比较,将反馈应用到所述第二候选基础神经网络;采用所述经过训练的候选基础神经网络作为所述当前候选基础神经网络,用于所述一组步骤的后续迭代;在这些步骤的多次迭代之后,采用所述当前候选基础神经网络作为所述基础神经网络。这可能使得能够从所述教师网络(所述经过训练的神经网络)确定教学辅助网络作为所述基础网络。
17.与所述经过训练的神经网络相比,所述基础神经网络具有更小的容量和/或实现的计算密集度更低和/或复杂度更低。如果所述教师模型和所述学生模型之间存在较大的容量差距,则使用较小的教学辅助网络来确定所述学生模型可能会更高效。
18.所述基础神经网络可以是用于促进所述简化神经网络形成的教学辅助网络。在所述教师网络和所述学生网络之间存在较大容量差异的情况下,使用教学辅助网络可能特别有利。
19.所述机制用于安装所述简化神经网络,以在计算复杂度低于所述一台或多台计算机的设备上执行。这可能使得能够在较小、计算复杂度较低的设备(例如,平板电脑或手机)上有效地执行所述简化模型。
20.可以通过优化网络架构的随机图来执行所述选择第二候选神经网络的架构的步骤,所述随机图已根据所述设备的一种或多种功能预先确定。优化架构的随机分布而不是确定性架构本身,可能以较低的成本提供较高准确度的结果。
21.根据另一方面,本文提供了一种用于根据基础神经网络确定简化神经网络的计算机实现的方法,所述方法包括迭代地执行以下一组步骤:通过对当前候选神经网络的架构进行采样来形成样本数据;根据所述样本数据,选择第二候选神经网络的架构;通过训练所述第二候选神经网络形成经过训练的候选神经网络,其中,所述训练所述第二候选神经网络包括根据所述第二候选神经网络和所述基础神经网络的行为比较,将反馈应用到所述第二候选神经网络;采用所述经过训练的候选神经网络作为所述当前候选神经网络,用于所述一组步骤的后续迭代。这可能使得能够对可模拟更大基础网络的候选神经网络进行训练。所述方法可以在预期任务中实现卓越性能,并且具有自动适应不同需求的灵活性。因此,不需要人类专家。
附图说明
22.现将参考附图通过示例的方式对本发明进行描述。
23.在附图中:
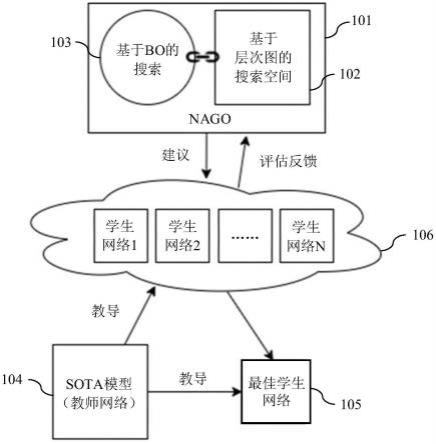
24.图1示出了能够确定最佳学生模型的机器学习机制的实施方式;
25.图2示出了根据基础神经网络确定简化神经网络的机器学习机制的步骤;
26.图3示出了利用教学辅助网络的实施方式;
27.图4示出了本发明实施例提供的利用教学辅助网络的机器学习机制的步骤;
28.图5示出了包括用于确定简化神经网络的计算机和用于实现简化神经网络的设备的系统示例。
具体实施方式
29.在本文描述的机器学习机制中,自动学习学生模型的架构以及最佳相关kd超参数,以便最大限度地利用kd,而无需人类专家。在本文描述的示例中,所述模型是神经网络,并且所述方法将知识蒸馏和神经网络架构搜索(neural architecture search,nas)相结合。搜索较小的学生模型的架构和所述相关超参数(例如,kd温度和损耗权重)。如果所述教师模型和所述学生模型之间存在较大的容量差距,则所述方法还将扩展到搜索教学辅助模型的架构和超参数。
30.图1示出了正在考虑的不同元素。在优选实施方式中,所述方法对作为所述搜索空间的随机图生成器(例如,nago)进行优化。网络架构生成器优化(neural architecture generator optimization,nago)是nas模块101。它定义了用于网络的搜索空间(如102所示),包括架构和训练参数以及基于多目标贝叶斯优化对其进行优化的策略(如103所示)。这意味着nago可以允许所述机制找到不仅具有最佳准确度而且根据次要(例如,浮点运算(floating-point operations,flops))目标执行的架构。
31.所述教师模型104是最新模型,需要在较小的学生模型中进行仿真。所述教师网络的容量(根据参数)可能有所不同,而所述学生网络的容量最好根据要求(例如,运行所述学生模型的设备的要求或功能)固定为给定值。
32.在所述搜索阶段,所述nas模块101提出架构和超参数(如106处的学生网络1至n所示),它们通过kd进行训练以吸收所述教师网络的知识。因此,通过网络架构的随机图来优化所述学生网络的架构。优化架构的随机分布而不是确定性架构本身,可能以较低的成本
提供相同的准确结果(例如,参见binxin ru、pedro esperanca、fabio carlucci在arxiv预印本arxiv:2004.01395(2020年)中发表的文章“网络架构生成器优化(neural architecture generator optimization)”以及saining xie等人在2019年ieee国际计算机视觉大会会刊中发表的文章“探索图像识别的随机有线神经网络”)。所述搜索阶段结束后,所述系统将返回最佳学生网络105。
33.更笼统地说,通过对当前候选学生神经网络的架构进行采样来形成样本数据。可以通过根据预定采集函数对所述当前候选学生神经网络进行采样,来形成所述样本数据。根据所述样本数据,确定第二候选学生神经网络的架构。
34.通常,所述形成经过训练的学生神经网络的步骤包括:使得所述候选学生神经网络执行多个任务,并使得所述教师神经网络执行所述多个任务。根据所述候选学生神经网络和所述教师神经网络在执行所述任务时的性能差异来修改所述候选学生神经网络。
35.更正式地说:
36.给定以下条件:教师网络t、贝叶斯优化代理模型s、采集函数a、预期任务q。
37.环路:
38.1、根据a对学生网络架构和kd参数(温度和损耗权重)进行采样
39.2、使用t提供的kd在q中训练学生网络,并获取任务指标
40.3、更新s和a
41.4、重复操作,直至有可用的预算
42.返回最佳学生网络架构和相应的kd参数。
43.然后,可以安装所述学生模型,以在计算复杂度低于训练所述学生网络的所述一台或多台计算机的设备上执行。可以根据所述设备的一种或多种功能预先确定经过优化的网络架构的随机图。
44.如上所述,本文描述的方法利用贝叶斯优化来选择所述学生网络架构。由于所述贝叶斯优化框架的数据效率非常高,因此它在评估成本高昂、无法获得导数以及相关函数是非凸和多模态函数的情况下特别有用。在这些情况下,贝叶斯优化能够利用优化历史提供的全部信息来提高搜索效率(例如,参见bobak shahriari等人在ieee会刊(104.1(2015):148-175)中发表的文章“走出圈子:贝叶斯优化回顾(taking the human out of the loop:a review of bayesian optimization)”)。在一些实施方式中,可以使用多目标贝叶斯优化。贝叶斯优化可以具有一个或多个目标,其中,所述目标中的至少一个是指:(i)提高所述第二候选神经网络的分类准确度和/或(ii)降低所述第二候选神经网络的计算密集度。这可能有助于形成比所述教师神经网络更精确且计算密集度更低的学生神经网络。
45.图2概括了由一台或多台计算机实现的机器学习机制200的步骤,所述机制可以访问基础神经网络(例如,本文描述的教师模型104)且用于通过迭代地执行以下一组步骤来确定简化神经网络(例如,本文描述的学生模型105)。在步骤201中,所述机制通过对当前候选神经网络的架构进行采样来形成样本数据。在步骤202中,所述机制根据所述样本数据,选择第二候选神经网络的架构。在步骤203中,所述机制通过训练所述第二候选神经网络形成经过训练的候选神经网络,其中,所述训练所述第二候选神经网络包括根据所述第二候选神经网络和所述基础神经网络的行为比较,将反馈应用到所述第二候选神经网络。在步骤204中,所述机制采用所述经过训练的候选神经网络作为所述当前候选神经网络,用于所
述一组步骤的后续迭代。在这一组步骤的多次迭代之后,所述当前候选神经网络作为所述简化神经网络输出。
46.与所述教师神经网络相比,所述简化学生神经网络具有更小的容量和/或实现的计算密集度更低。这可能使得所述学生网络能够在计算能力低于训练所述模型的所述计算机的设备上运行。
47.当所述教师网络的容量(以参数数量表示)远远高于所述学生网络的容量时,比较有利的做法是引入教学辅助网络(teaching assistant,ta),如seyed iman mirzadeh等人在arxiv预印本arxiv:1902.03393(2019年)中发表的文章“通过教师助理改进知识蒸馏(improved knowledge distillation via teacher assistant)”所述。所述教学辅助网络可用于简化所述教师网络(具有相对较高的容量)与所述学生网络(可能具有比所述教师网络低得多的容量)之间的传输。
48.可以手动设计所述教学辅助网络,无论是在架构和容量方面,都需要人类专家(与传统kd一样)。或者,所述教学辅助网络自身可以由kd/nas确定,如上文针对所述学生网络的描述所示。
49.在一实施方式中,在搜索所述学生网络期间,所述教学辅助网络并非自动搜索最佳教学辅助网络架构和容量,而是与所述学生网络共享同一架构,所述容量包含在所述搜索空间内并且因此得到优化。
50.如图3所示,需要评估新提案时,可以使用的提议架构、不同的容量对所述学生网络303和所述教学辅助网络302进行初始化:具有所需容量的所述学生网络303,以及具有(搜索)容量(允许从所述教师网络301进行最大知识转移)的所述教学辅助网络302。
51.因此,可以扩展先前的算法,如下所示:
52.给定以下条件:教师网络t、贝叶斯优化代理模型s、采集函数a、预期任务q。
53.环路:
54.1、根据a对架构、kd参数(温度和损耗权重)和ta系统容量进行采样
55.2、使用所述架构同时对所述学生网络(固定容量)和ta系统(建议值)进行初始化
56.3、与此同时,在t与ta系统、ta系统与学生系统之间执行kd。获取任务指标
57.4、更新s和a
58.5、重复操作,直至有可用的预算
59.返回最佳网络架构和相应的kd参数。
60.所述方法还可以扩展用于多目标优化。
61.图4示出了可用于确定所述教学辅助网络的机器学习机制,所述教学辅助网络之后可充当所述学生网络的基础神经网络。所述机制可以访问经过训练的神经网络(例如,教师网络301)且用于通过迭代地执行以下一组步骤来确定所述基础神经网络(例如,ta网络302)。在步骤401中,所述机制通过对当前候选基础神经网络的架构进行采样来形成样本数据。在步骤402中,所述机制根据所述样本数据,选择第二候选基础神经网络的架构。在步骤403中,所述机制通过训练所述第二候选基础神经网络形成经过训练的候选基础神经网络,其中,所述训练所述第二候选基础神经网络包括根据所述第二候选基础神经网络和所述经过训练的神经网络的行为比较,将反馈应用到所述第二候选基础神经网络。在步骤404中,所述机制采用所述经过训练的候选基础神经网络作为所述当前候选基础神经网络,用于所
述一组步骤的后续迭代。在步骤405中,在这些步骤的多次迭代之后,所述机制采用所述当前候选基础神经网络作为所述基础神经网络。如上所述,该基础神经网络的容量比所述原始经过训练的教师神经网络小,其可以用于确定所述学生神经网络。
62.为简单起见,此处所示的示例性算法是针对单个目标的情况提供的。然而,所述方法可以扩展到多个目标。例如,只需使用nago的多目标实现即可。这样做使得能够确定不仅在单个任务指标(例如精确度)方面而且在可能相关的任何其它次要指标(例如,内存占用、flops)方面最优的模型。
63.所述方法还可以处理不受支持的操作。优选地,所述搜索空间包含在大量硬件设备上可用的简单操作。例如,默认情况下,nago的搜索空间包含简单的操作,这些操作可能在非常广泛的设备硬件上可用。在特定设备具有特定硬件要求的情况下,可以轻松修改所述搜索空间以省略违规操作,并且可以如前所述运行所述算法的其余部分。
64.图5示出了包括设备501的系统500的示例。所述设备501包括处理器502和存储器503。所述处理器可以执行所述学生模型。所述学生模型可以存储在存储器503中。所述处理器502还可以用于所述设备的基本功能。
65.收发器504能够通过网络与其它实体505、506通信。这些实体可以在物理上远离所述设备501。所述网络可以是公共可访问网络,例如互联网。所述实体505、506可以基于云。实体505是计算实体。实体506是命令和控制实体。这些实体是逻辑实体。实际上,它们中的每一个都可以由一个或多个物理设备(例如,服务器和数据存储区)提供,并且两个或多个所述实体的功能可以由单个物理设备提供。实现实体的每个物理设备包括处理器和存储器。所述设备还包括收发器,用于向设备501的收发器504发送数据并从该收发器接收数据。所述存储器以非瞬时方式存储代码,所述代码可由所述处理器执行,以通过本文描述的方式实现相应实体。
66.所述命令和控制实体506可以训练所述设备中使用的所述模型。这通常是一项计算密集型任务,即使可以有效地描述所获得的学生模型,因此可以高效地在云中执行所述算法的开发,可以预见的是云中有大量能源和计算资源可用。
67.在一实施方式中,在云中开发所述算法后,所述命令和控制实体即可自动形成相应的模型并使其从所述计算机505传输到相关设备501。在该示例中,由处理器502在所述设备501处实现最佳学生模型。
68.因此,本文描述的机器学习机制可以通过多种方式部署,例如部署在云或专用硬件中。如上所述,云设施可以执行训练,以开发新算法或改进现有算法。根据数据语料库附近的计算能力,所述训练可以在靠近源数据的位置进行,也可以在云中进行,例如使用推理引擎。所述方法还可以在专用硬件中或在云中实现。
69.本文描述的方法可以在预期任务中实现卓越性能,并且具有自动适应不同需求的灵活性(例如,针对flops或内存使用情况进行优化)。在形成所述学生模型时,不需要人类专家。
70.与现有方法相比,所述方法具有更高的采样效率。例如,在一些实施方式中,所需的样本为现有技术的二十分之一。所述方法能够执行真正的多目标优化(而不是简单的加权和)。所述方法还具有通过使用教学辅助网络来处理大容量缺口的能力。
71.申请方在此单独公开本文描述的每一个体特征及两个或两个以上此类特征的任
意组合。以本领域技术人员的普通知识,能够基于本说明书将此类特征或组合作为整体实现,而不考虑此类特征或特征的组合是否能解决本文所公开的任何问题,并且不限于权利要求的范围。本技术表明本发明的各方面可由任何这类单独特征或特征的组合构成。鉴于前文描述可在本发明的范围内进行各种修改对本领域技术人员来说是显而易见的。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。