1.本发明涉及开源组件领域,具体提供一种通用软件缺陷统计方法及装置。
背景技术:
2.随着软件测试行业的不断发展,在软件测试过程中对检测出的缺陷进行统计分析显得越来越重要。当前,一些在测试领域较为著名的工具如jira、ones被软件测试行业广泛应用。
3.但目前对信息产品缺陷的记录大多数情况下仅仅是简单的记录,初步的统计和较为机械原始的数据展示,缺乏更加深入的、直观的、可视化的缺陷统计分析方法。
技术实现要素:
4.本发明是针对上述现有技术的不足,提供一种实用性强的通用软件缺陷统计方法。
5.本发明进一步的技术任务是提供一种设计合理,安全适用的通用软件缺陷统计装置。
6.本发明解决其技术问题所采用的技术方案是:
7.一种通用软件缺陷统计方法,具有如下步骤:
8.s1、收集bug原始信息数据;
9.s2、对bug原始信息数据进行初步的数据筛选和清洗;
10.s3、将筛选和清洗的数据进行赋值;
11.s4、将赋值后的数据使用k-means算法进行聚类分析;
12.s5、将分析完的数据存储在数据库中;
13.s6、基于python语言的flask框架,在后端调用数据库中的数据;
14.s7、将json格式的k数据传输到前端,利用开源组件echarts对数据进行可视化展示;
15.s8、可按不同需求对bug影响的其他不同方面进行定制化的深入分析。
16.进一步的于,在步骤s1中,通过网络爬虫形式自动化收集在软件开发测试过程中产生的bug的原始数据,并对bug的基础信息数据进行记录,记录为普通数据。
17.进一步的,在步骤s2中,对bug的原始数据进行初步的数据筛选和清洗,去掉无效数据,并按照需求处理成所需要的格式。
18.进一步的,在步骤s3中,将处理好的数据,以每个bug的影响范围和严重程度两项进行赋值,影响范围从小到大按照1-10十个等级进行赋值,严重程度从轻到重按照1-10十个等级进行赋值,每个bug赋值由四组人员进行赋值,最终结果取平均值并保留两位小数。
19.进一步的,在步骤s4中,将赋值后的数据使用k-means算法进行聚类分析,选取4个基点作为k-means算法的基础质心,分别为初始k1基点、初始k2基点、初始k3基点和初始k4基点,对经k-means算法处理后的最终轮数据进行二次记录,记录为k数据。
20.进一步的,在步骤s5中,将处理好的数据按照类别存储到数据库中,并对数据库中的数据并进行定期备份。
21.进一步的,在步骤s6中,基于python语言的flask框架,在后端调用数据库中的数据,对调用的数据进行二次处理,将数据转换为序列化的json格式使前端对数据进行调用和统计分析。
22.进一步的,在步骤s7中,将json格式的k数据传输到前端,利用开源组件echarts对数据进行可视化展示,得到k数据聚类散点图,图中包括坐标轴和按颜色分类展示的k数据点,坐标轴的x轴为bug的影响范围,y轴为bug的严重程度,数据点上带有坐标值、影响版本和影响模块的标签,可直观的观察到bug属于一个聚类,以及对应聚类的bug影响的模块和版本。
23.一种通用软件缺陷统计装置,包括:至少一个存储器和至少一个处理器;
24.所述至少一个存储器,用于存储机器可读程序;
25.所述至少一个处理器,用于调用所述机器可读程序,执行一种通用软件缺陷统计方法。
26.本发明的一种通用软件缺陷统计方法及装置和现有技术相比,具有以下突出的有益效果:
27.本发明通过对软件缺陷进行自动化地记录,利用人工智能和机器学习领域经典算法对bug进行更深层次的聚类分析,不仅能方便软件测试人员了解当前阶段软件缺陷数量和分布的基本情况,也能使测试管理人员和研发人员通过对比人工记录的结果和机器学习算法下的结果对测试过程进行更好的掌握和调整。
附图说明
28.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
29.附图1是一种通用软件缺陷统计方法的流程示意图;
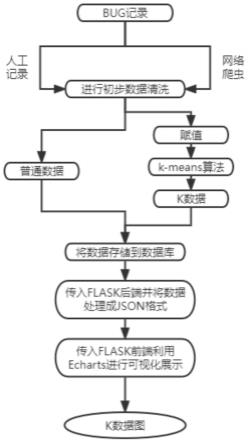
30.附图2是一种通用软件缺陷统计方法中部分k数据信息示意图;
31.附图3是一种通用软件缺陷统计方法中k数据聚类散点图。
具体实施方式
32.为了使本技术领域的人员更好的理解本发明的方案,下面结合具体的实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例都属于本发明保护的范围。
33.下面给出一个最佳实施例:
34.如图1所示,本实施例中的一种通用软件缺陷统计方法,具有如下步骤:
35.s1、收集bug原始信息数据;
36.通过网络爬虫形式自动化地收集在软件开发测试过程中产生的缺陷(bug)的原始
数据,并对bug的基础信息如id、标题、负责人、创建人、影响版本、产生模块等数据进行记录,记录为普通数据。
37.s2、对bug原始信息数据进行初步的数据筛选和清洗;
38.对bug的原始数据进行初步的数据筛选和清洗,去掉一些空值、错误值和无意义的乱码等无效数据,并按照需求处理成所需要的格式。
39.s3、将筛选和清洗的数据进行赋值;
40.将处理好的数据,以每个bug的影响范围和严重程度两项进行赋值,影响范围从小到大按照1-10十个等级进行赋值,严重程度从轻到重按照1-10十个等级进行赋值,每个bug赋值由四组人员进行赋值,最终结果取平均值并保留两位小数。
41.s4、将赋值后的数据使用k-means算法进行聚类分析;
42.如图2所示,将赋值后的数据使用k-means算法进行聚类分析,选取4个基点作为k-means算法的基础质心,分别为初始k1基点(影响范围大,严重程度重),初始k2基点(影响范围小,严重程度重),初始k3基点(影响范围小,严重程度轻),初始k4基点(影响范围大,严重程度轻),对经k-means算法处理后的最终轮数据进行二次记录,记录为k数据。
43.s5、将分析完的数据存储在数据库中;
44.将处理好的数据按照类别存储到数据库中,并对数据库中的数据并进行定期备份,降低因意外带来的数据丢失风险。
45.s6、基于python语言的flask框架,在后端调用数据库中的数据;
46.基于python语言的flask框架,在后端调用数据库中的数据,对调用的数据进行二次处理。将数据转换为序列化的json格式以方便前端对数据进行调用和统计分析。
47.s7、将json格式的k数据传输到前端,利用开源组件echarts对数据进行可视化展示;
48.如图3所示,将json格式的k数据传输到前端,利用开源组件echarts对数据进行可视化展示,便可得到直观的k数据聚类散点图,图中包括坐标轴和按颜色分类展示的k数据点,坐标轴的x轴为bug的影响范围(取值范围1-10),y轴为bug的严重程度(取值范围1-10),数据点上带有坐标值(保留两位小数)、影响版本和影响模块等标签,可直观的观察到哪些bug属于一个聚类,以及对应聚类的bug影响的模块和版本,对比人工记录的初始结果,方便测试管理人员对bug的影响情况对测试过程进行进一步判断和调整。
49.s8、可按不同需求对bug影响的其他不同方面进行定制化的深入分析。
50.基于上述方法,本实施例中的一种通用软件缺陷统计装置,包括:至少一个存储器和至少一个处理器;
51.所述至少一个存储器,用于存储机器可读程序;
52.所述至少一个处理器,用于调用所述机器可读程序,执行一种通用软件缺陷统计方法。
53.上述具体的实施方式仅是本发明具体的个案,本发明的专利保护范围包括但不限于上述具体的实施方式,任何符合本发明的一种通用软件缺陷统计方法及装置权利要求书的且任何所述技术领域普通技术人员对其做出的适当变化或者替换,皆应落入本发明的专利保护范围。
54.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以
理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。