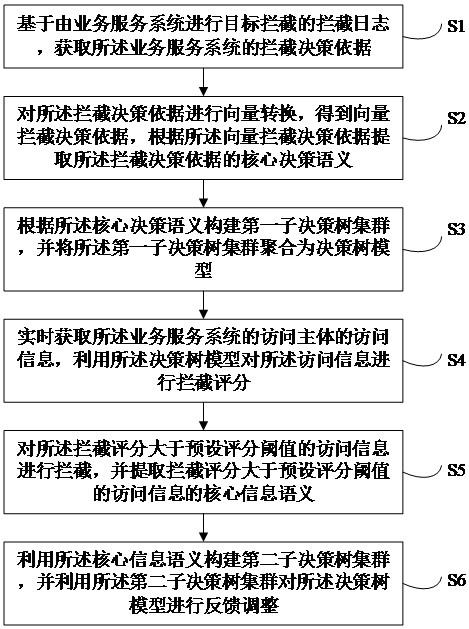
一种基于双注意力机制融合的fda-deeplab语义分割算法
技术领域
1.本发明涉及一种基于双注意力机制融合的fda-deeplab语义分割算法,属于图像处理领域。
背景技术:
2.在传统的语义分割问题上,存在着这样几个挑战:传统分类cnn中连续的下采样操作,导致特征图的分辨率不断下降。多尺度检测问题,一般是重新调节尺度并聚合特征图,该操作计算量较大。为了解决这些问题,deeplab模型应运而生。而deeplabv3 模型又是deeplab模型通过不断发展得到的。deeplabv3 模型把deeplabv3作为encoder部分,提取多尺度特征。在此基础上加入了decoder部分,形成了一种融合aspp、encoder和decoder的新方法,能够有效改善分割结构的物体边界。但在实际过程中存在以下几个问题:
3.1、对相似对象容易误判。
4.2、小目标容易遗漏。
5.3、边界分割误差大。
6.4、预测输出存在空洞。
技术实现要素:
7.发明目的:针对上述现有技术存在的问题,本发明提供了一种基于双注意力机制融合的fda-deeplab语义分割算法,主要目标是解决了原始deeplabv3 模型分割出的物体存在断裂和空洞的问题;解决了原始deeplabv3 模型对图像边界分割误差大的问题;解决了原始deeplabv3 模型对相似对象容易误判的问题;解决了实际训练过程中可能存在的数据集样本类别不平衡以及样本分类难度不平衡问题。
8.技术方案:
9.一种基于双注意力机制融合的fda-deeplab语义分割算法,其特征在于,包括以下步骤:
10.步骤1:按照deeplabv3 模型框架搭建特征提取网络和空间金字塔池化aspp模块;
11.步骤2:设计双注意力机制特征融合模块;
12.步骤3:基于双注意力机制特征融合模块,设计特征融合模块;
13.步骤4:对特征融合模块得到的输出图像进行深度可分离卷积和上采样,模型搭建完毕;
14.步骤5:训练模型,改进损失函数对训练进行优化,对比不同模型性能。
15.所述步骤1包括:
16.步骤1.1:采用resnet-50卷积神经网络模型,搭建特征提取网络,得到下采样率为4、8、16的低级特征图。
17.步骤1.2:在特征提取网络后搭建空间金字塔池化aspp模块,得到高级特征图。
18.所述步骤2包括:
19.步骤2.1:设对于同一个双注意力机制融合模块,低分辨率特征图输入为u
li
,特征图分辨率为h
′×w′
,高分辨率特征图输入为u
hi
,特征图分辨率为h
×
w;
20.步骤2.2:对u
li
进行上采样操作得到u
l
′i′
,使u
l
′i′
分辨率与u
hi
一致,即分辨率变为h
×
w。公式如下:
21.u
l'i'
=f
up
(u
li
),u
l'i'
∈h
×w×c22.式中,f
up
表示上采样操作,一般采用双线性插值方法;
23.步骤2.3:对u
l
′i′
进行通道注意力操作,得到u
li
′
,对u
hi
进行空间注意力操作,得到权重fs。将权重fs与u
li
′
相乘,得到u
lo
′
。公式如下:
24.u
li
′
=f(wr*z)*u
l
′i′
25.fs=[f(s
1,1
),f(s
1,2
),
…
,f(s
i,j
),
…
,f(s
h,w
)]
[0026][0027]
式中,f()表示sigmoid函数,s为映射特征,wr为对应卷积操作的参数,z为压缩特征;
[0028]
步骤2.4:把u
lo
′
和u
hi
相加,并在后面加上一个1
×
1卷积核降维。公式如下:
[0029]
uo=c(u
lo'
u
hi
)
[0030]
式中,c表示1
×
1卷积操作。
[0031]
所述步骤3包括:
[0032]
步骤3.1:把步骤1.1得到的下采样率为16的低级特征图和步骤1.2得到的高级特征图通过步骤2设计的双注意力机制特征融合模块得到输出特征图1;
[0033]
步骤3.2:把步骤1.1得到的下采样率为8的低级特征图和步骤3.1得到的输出特征图1通过步骤2设计的双注意力机制特征融合模块得到输出特征图2;
[0034]
步骤3.3:把步骤1.1得到的下采样率为4的低级特征图和步骤3.2得到的输出特征图2通过步骤2设计的双注意力机制特征融合模块得到输出特征图3;
[0035]
所述步骤4包括:
[0036]
步骤4.1:对步骤3.3得到的输出特征图3进行卷积核为3
×
3的深度可分离卷积和4倍上采样。
[0037]
所述步骤5包括:
[0038]
步骤5.1:对模型进行训练。采用在imagenet数据集上预先训练好的resnet-50预训练模型对fda-deeplab骨干模型进行初始化。设置批处理大小为10,迭代步数为40000,基础特征提取网络总的下采样倍数为16,初始学习率为0.007,训练数据大小为513
×
513,采用“poly”学习率策略。
[0039]
步骤5.2:改进损失函数对训练进行优化。采用焦点损失函数代替常规的交叉熵损失函数,公式如下:
[0040]
l
fl
(p
t
)=-α
t
(1-p
t
)
γ
log p
t
[0041]
式中,α为类别间(0-1二分类)的权重参数,(1-p
t
)y为简单/困难样本调节因子,γ为聚焦参数,p
t
为预测结果对应标签的概率。本实验中,设置γ=2,α=0.25。
[0042]
步骤5.3:对模型进行测试。采用miou作为性能评价指标,miou指标具有简洁与代表性强的特点,是语义分割领域最常用的评估标准。
[0043]
有益效果:
[0044]
1、解决了原始deeplabv3 模型分割出的物体存在断裂和空洞的问题;
[0045]
2、解决了原始deeplabv3 模型对图像边界分割误差大的问题;
[0046]
3、解决了原始deeplabv3 模型对相似对象容易误判的问题;
[0047]
4、解决了实际训练过程中可能存在的数据集样本类别不平衡以及样本分类难度不平衡问题。
附图说明
[0048]
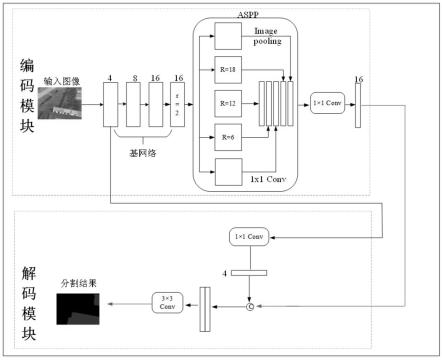
图1是原始deeplabv3 模型的网络模型图;
[0049]
图2是本发明设计的双注意力机制融合模块结构图;
[0050]
图3是本发明的总体架构图;
[0051]
图4是注意力机制对比实验结果图;
[0052]
图5是双注意力机制下多特征融合对比实验结果图;
[0053]
图6是损失函数对比实验结果图;
[0054]
图7是deeplabv3 改进前后对比实验结果图;
[0055]
图8是不同算法对比实验结果图。
具体实施方式
[0056]
为使本发明实施例的目的、技术方案和优点更加清楚,下面结合本发明实施例中的附图,对发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的发明的范围。
[0057]
如图所示,一种基于双注意力机制融合的fda-deeplab语义分割算法,包括以下步骤:
[0058]
步骤1:按照deeplabv3 模型框架搭建特征提取网络和空间金字塔池化aspp模块;
[0059]
步骤2:设计双注意力机制特征融合模块;
[0060]
步骤3:基于双注意力机制特征融合模块,设计特征融合模块;
[0061]
步骤4:对特征融合模块得到的输出图像进行深度可分离卷积和上采样,模型搭建完毕;
[0062]
步骤5:训练模型,改进损失函数对训练进行优化,对比不同模型性能。
[0063]
所述步骤1包括:
[0064]
步骤1.1:采用resnet-50卷积神经网络模型,搭建特征提取网络,得到下采样率为4、8、16的低级特征图。
[0065]
步骤1.2:在特征提取网络后搭建空间金字塔池化aspp模块,得到高级特征图。
[0066]
所述步骤2包括:
[0067]
步骤2.1:设对于同一个双注意力机制融合模块,低分辨率特征图输入为u
li
,特征图分辨率为h
′×w′
,高分辨率特征图输入为u
hi
,特征图分辨率为h
×
w;
[0068]
步骤2.2:对u
li
进行上采样操作得到u
l
′i′
,使u
l
′i′
分辨率与u
hi
一致,即分辨率变为h
×
w。公式如下:
[0069]ul'i'
=f
up
(u
li
),u
l'i'
∈h
×w×c[0070]
式中,f
up
表示上采样操作,一般采用双线性插值方法;
[0071]
步骤2.3:对u
l
′i′
进行通道注意力操作,得到u
li
′
,对u
hi
进行空间注意力操作,得到权重fs。将权重fs与u
li
′
相乘,得到u
lo
′
。公式如下:
[0072]uli
′
=f(wr*z)*u
l
′i′
[0073]fs
=[f(s
1,1
),f(s
1,2
),
…
,f(s
i,j
),
…
,f(s
h,w
)]
[0074][0075]
式中,f()表示sigmoid函数,s为映射特征,wr为对应卷积操作的参数,z为压缩特征;
[0076]
步骤2.4:把u
lo
′
和u
hi
相加,并在后面加上一个1
×
1卷积核降维。公式如下:
[0077]
uo=c(u
lo'
u
hi
)
[0078]
式中,c表示1
×
1卷积操作。
[0079]
所述步骤3包括:
[0080]
步骤3.1:把步骤1.1得到的下采样率为16的低级特征图和步骤1.2得到的高级特征图通过步骤2设计的双注意力机制特征融合模块得到输出特征图1;
[0081]
步骤3.2:把步骤1.1得到的下采样率为8的低级特征图和步骤3.1得到的输出特征图1通过步骤2设计的双注意力机制特征融合模块得到输出特征图2;
[0082]
步骤3.3:把步骤1.1得到的下采样率为4的低级特征图和步骤3.2得到的输出特征图2通过步骤2设计的双注意力机制特征融合模块得到输出特征图3;
[0083]
所述步骤4包括:
[0084]
步骤4.1:对步骤3.3得到的输出特征图3进行卷积核为3
×
3的深度可分离卷积和4倍上采样。
[0085]
所述步骤5包括:
[0086]
步骤5.1:对模型进行训练。使用公开数据集pascal voc 2012数据集对搭建的fda-deeplab模型进行训练。采用在imagenet数据集上预先训练好的resnet-50预训练模型对fda-deeplab骨干模型进行初始化。设置批处理大小为10,迭代步数为40000,基础特征提取网络总的下采样倍数为16,初始学习率为0.007,训练数据大小为513
×
513,采用“poly”学习率策略。
[0087]
步骤5.2:改进损失函数对训练进行优化。采用焦点损失函数代替常规的交叉熵损失函数,公式如下:
[0088]
l
fl
(p
t
)=-α
t
(1-p
t
)
γ
log p
t
[0089]
式中,α为类别间(0-1二分类)的权重参数,(1-p
t
)y为简单/困难样本调节因子,γ为聚焦参数,p
t
为预测结果对应标签的概率。本实验中,设置γ=2,α=0.25。
[0090]
步骤5.3:对模型进行测试。采用miou作为性能评价指标,miou指标具有简洁与代表性强的特点,是语义分割领域最常用的评估标准。
[0091]
本发明通过在deeplabv3 模型上添加双注意力机制特征融合模块、特征融合模块以及改进损失函数来解决原始deeplabv3 模型在图像语义分割上的缺点,提高了图像的分割效果。
[0092]
其中,图1是原始deeplabv3 模型的网络模型图。原始deeplabv3 模型整体分为了encoder和decoder两个模块。具体来说encoder模块包括负责基本特征提取的主干网络和
aspp模块,有效地提取图像特征是高精度语义分割的关键。decoder模块负责将encoder模块得到的特征图进行逐步上采样,并采用fpn特征融合的思想,将高、低特征进行融合,解决在特征提取过程中的细节损失问题,最终得到语义分割结果。
[0093]
图2是本发明设计的双注意力机制融合模块结构图。本发明综合两种注意力机制的优点,将低级空间细节和高级语义线索有效融合,得到效果更优的注意力机制模型。现阶段常用的融合方式是在同一张特征图上,分别进行两种注意力机制操作并将结果融合,区别更多在于不同的特征融合方式。而分辨率高的低级特征图适合采取空间注意力操作,提取输入图像的空间位置信息,从中定位出重要部位;分辨率低的高级特征图适合采取通道注意力操作,使其关注更为相关的特征通道,忽略其它干扰信息。因此本发明在不同分辨率的特征图上采用不同的注意力机制,然后再进行融合,提高了融合效果。
[0094]
图3是本发明的总体架构。
[0095]
图4、5、6、7、8分别为在pascal voc 2012验证集上进行的注意力机制对比实验结果、双注意力机制下多特征融合对比实验结果、损失函数对比实验结果、deeplabv3 改进前后对比实验结果以及不同算法对比实验结果。从实验结果可以看出,本发明设计的双注意力机制模块整体效果优于单独的通道注意力机制或空间注意力机制,更优于原始模型;本发明设计的基于双注意力机制的特征融合方法,要优于其他融合方法;本发明设计的焦点损失函数,对于数据分布较均衡的公开数据集,也有一定的提升。总的来说,本发明通过在deeplabv3 模型上设计双注意力机制特征融合模块、特征融合模块以及改进损失函数,得到了一种基于双注意力机制融合的fda-deeplab语义分割算法,改善了原始deeplabv3 模型的缺点,提高了分割效果。
[0096]
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。