1.本发明涉及人工智能与社交网络技术领域,更具体的涉及一种基于增强网络对比约束的多通道社交圈子识别装置及方法。
背景技术:
2.社交圈子是一组拥有共同兴趣爱好且联系紧密的用户集合。随着信息化进程的发展和网络的普及,社交网络中用户社交圈的应用分析对不同的领域有着越来越重要的意义。社交圈子的识别已经成为各领域的研究焦点。根据社交圈固有的属性(位于同一个社交圈内的用户,由于共同的兴趣爱好具有较为紧密的连接;而位于不同社交圈的用户由于共同话题较少则连接稀疏),由于社交关系错综复杂,将社交系统抽象为复杂网络的形式,能有效实现对社交系统的处理、挖掘和建模,具体来说,将社交系统中代表用户身份的对象(如社交平台中的用户账号)抽象为网络中的节点,将用户间的联系(聊天、关注共同话题、相互评论等)映射为节点间的边。由于用户在现实世界中的社交活动具有多样性,仅对用户间单一社交关系的建模难以真正反映用户的社交行为。在实际生活中,用户往往会基于不同的社交平台进行交互,在网络空间中拥有多种虚拟身份,因而信息可以通过不同通道在网络中进行传播,例如,用户们通常会使用微信与家人朋友进行通讯,使用微博等软件与陌生的但有共同话题爱好的网友交流,这些社交关系有着不同的重要性与意义。多通道社交网络中用户关系的多元化导致传统的基于单层网络的社团挖掘方法很难精准有效地识别社交网络中的圈子。
3.因此,已有技术将多通道社交网络抽象为多层网络的形式,目前,学者们针对多层网络的特殊结构,提出了大量多层网络社团挖掘方法。其中,一些已有研究认为,只考虑多层网络的拓扑结构,难以保证方法在不同网络环境下的准确率,并提出了基于半监督学习的方法。然而,由于社交网络具有用户量大、连接关系复杂的特点,人工标注数据会造成巨大的经济开销和时间开销,鉴于此,现有半监督学习社团挖掘方法难以有效解决社交圈子识别问题。
技术实现要素:
4.针对现有技术难以有效解决社交圈子的识别问题,本发明的目的在于提供一种基于增强网络对比约束的多通道社交圈子识别装置及方法,用于精准挖掘多通道社交网络中的社交圈子。
5.为实现以上目的,本发明一方面涉及一种基于增强网络对比约束的多通道社交圈子识别装置,采用如下技术方案:
6.一种基于增强网络对比约束的多通道社交圈子识别装置,包括:
7.输入模块,该模块用于读取输入的多通道社交网络,并按算法需要格式,将其转化为邻接矩阵和特征矩阵的形式;
8.求解模块,该模块包含网络生成模型和节点表示模型。其中,网络生成模型用于根
据所输入网络聚合多层网络信息,并生成可学习增强网络;节点表示模型则用于求解输入网络的低维表示,并根据所求得的低维表示计算对比损失,进而反向优化装置中的所有模型参数;
9.输出模块,该模块基于聚类算法,将多层网络共识低维表示转化为多通道社交网络的共识社团划分,即社交圈子。
10.进一步地,所述多通道社交圈子识别装置适用于有特征网络和无特征网络,在有特征网络中,多通道社交圈子识别装置可利用已有特征作为特征矩阵求解;而在无特征网络中,则可使用邻接矩阵作为特征矩阵进行求解。
11.本发明另一方面涉及一种基于增强网络对比约束的多通道社交圈子识别方法,包括以下步骤:
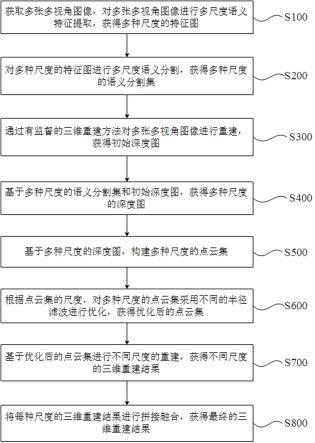
12.s1:将多通道社交网络建模为多层网络,向多通道社交圈子识别装置输入代表多通道社交网络的多层网络的邻接矩阵;其中每层网络表示一种社交网络平台构成的信息传播通道,包含相同的用户集合和不同的社交关系,网络中每个节点是现实世界中社交网络平台中用户账号的映射,节点间的连边代表用户账号间的社交行为,所述社交行为包括转发和评论;
13.s2:设置迭代次数epoch、学习率lr和丢弃概率dp;
14.s3:多通道社交圈子识别装置首先基于图卷积网络即gcn和多层感知机即mlp构建网络生成模型,并基于gcn构建节点表示模型;本质而言,网络生成模型是聚合多层网络信息生成增强信息的过程;而节点表示模型则是聚合增强网络和原始多层网络的信息,并将上述结果基于对比学习思想求解对比损失的过程;
15.s4:基于网络生成模型生成可学习增强网络:首先,利用gcn提取并聚合每层网络的信息,并基于mlp生成每个节点与其余节点间的权重,生成增强网络的邻接矩阵a
′
;增强网络本质上是一个n
×
n的矩阵,其中每个向量表示聚合了多层网络信息后,生成的每个节点的特征;
16.s5:基于节点表示模型,首先计算s4步骤中生成的可学习增强网络的低维表示,然后计算输入多层网络中每层网络的低维表示;
17.s6:利用可学习增强网络的低维表示与多层网络低维表示构建对比,计算对比损失;
18.s7:基于s6所求损失函数,反向优化网络生成模型和节点表示模型;
19.s8:循环执行训练过程s4-s7,迭代优化网络生成模型和节点表示模型,直到迭代次数达到预定参数epoch;
20.s9:基于训练好的节点表示模型,求解多层网络共识低维表示,并采用kmeans求解共识社团划分。
21.进一步地,s1中,多层网络表示为g={g1,g2,
…
,g
l
},利用多层网络的邻接矩阵a={a1,a2,
…
,a
l
}进行求解,l为网络的层数,矩阵规模为n
×
n,n表示节点也即用户账号的数量。
22.进一步地,s2中,设置epoch=100,lr=0.004,dp=0.2。
23.进一步地,s4中,gcn低维表示的计算公式如下所示:
24.25.其中,x表示输入特征,a为多层网络的邻接矩阵,i表示单位矩阵,是的度矩阵,w
(0)
和w
(1)
分别为第一层和第二层gcn的权重矩阵,σ为激活函数。
26.进一步地,s5中,可学习增强网络的低维表示h',标准化后记作z';多层网络中每层网络的低维表示hi,标准化后记作zi,其中i={1,2,
…
l},l为网络层数。
27.进一步地,s6中,基于如下公式,求解损失函数:
[0028][0029]
其中,diag(*)表示计算*的对角矩阵,s()为softmax函数,τ表示常数,mean()表示计算平均值,z
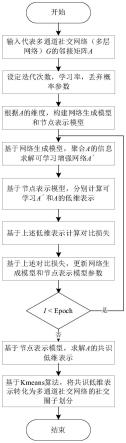
it
表示zi的转置。
[0030]
在本发明的一种优选实施方式中,设定τ=0.6。
[0031]
进一步地,s9中,求解得到的每个社团由若干个节点构成,每个节点代表社交网络中的一个用户账号,挖掘到的社团结构实质上表示现实中一组用户账号构成的具有相同爱好和话题的社交圈子。
[0032]
与现有技术相比,本发明的有益效果在于:
[0033]
(1)本发明将多通道社交网络抽象为多层网络的形式,其中,每层网络代表一个信息通信通道(即刻画了一种社交平台下的社交关系),解决了多通道社交网络中用户关系的多元化导致传统的基于单层网络的社团挖掘方法很难精准有效地识别社交网络中的圈子的问题;通过挖掘并聚合多层网络信息生成可学习增强网络,此外,网络生成模型参数会根据损失函数同步迭代更新,保证了可学习增强网络的有效性,提高了模型的学习能力,进而有效提高了装置的准确率和鲁棒性,能够在不同网络环境下,无需人工标签的指导,精准挖掘多层网络的共识社团结构;
[0034]
(2)本发明装置和方法基于节点表示模型,同时求解可学习增强网络和原始输入多层网络的低维表示,并基于对比学习的思想计算对比损失,能够充分发挥可学习增强网络的指导作用;
[0035]
(3)将本发明与其他方法在不同规模的人工数据集与真实数据集上进行对比实验,采用本发明方法具有较高的准确性与鲁棒性,证明了通过本发明方法能够有效挖掘多通道社交网络中的社交圈子。
附图说明
[0036]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
[0037]
图1为本发明方法流程图;
[0038]
图2为现实中多通道社交系统、多层网络和社交圈子的映射示意图;
[0039]
图3为本发明装置使用时示意图;
[0040]
图4为鲁棒性分析实验图;
[0041]
图5为收敛性分析实验图。
具体实施方式
[0042]
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
[0043]
一种基于增强网络对比约束的多通道社交圈子识别装置,包括:
[0044]
输入模块,该模块用于读取输入的多通道社交网络,并按算法需要格式,将其转化为邻接矩阵和特征矩阵的形式;
[0045]
求解模块,该模块包含网络生成模型和节点表示模型。其中,网络生成模型用于根据所输入网络聚合多层网络信息,并生成可学习增强网络;节点表示模型则用于求解输入网络的低维表示,并根据所求得的低维表示计算对比损失,进而反向优化装置中的所有模型参数;
[0046]
输出模块,该模块基于聚类算法,将多层网络共识低维表示转化为多通道社交网络的共识社团划分,即社交圈子。
[0047]
一种基于增强网络对比约束的多通道社交网络圈子识别方法,首先,构建网络生成模型和节点表示模型,并基于网络生成模型求解多层网络的可学习增强网络。然后,基于可学习增强网络与多层网络构建对比,并基于对比损失更新网络生成模型和节点表示模型的参数。
[0048]
如图1~3所示,具体包括以下步骤:
[0049]
s1:将多通道社交网络建模为多层网络,其中每层网络对应一种社交通道(即社交平台),节点代表不同网络平台下对应用户的账号,节点间的连边代表用户账号间的社交行为(如互相评论、聊天等);输入表示多通道社交网络的多层网络g={g1,g2,
…
,g
l
}的邻接矩阵a={a1,a2,
…
,a
l
},l为网络的层数,矩阵规模为n
×
n,n表示节点也即用户账号的数量,表示矩阵中i节点和j节点在现实世界中社交关系的权重(如互相评论、互相聊天次数、转发消息次数等)。如图2所示,该示例是由6个社交账号构成的多通道社交网络,两个社交平台分别为qq和微信,为了准确刻画两种社交关系,该装置分别将用户间基于qq和微信平台的社交关系抽象为第1、2层网络。每层网络中的节点一一对应,都表示现实世界中的社交用户(图2中用户v
1-v6);
[0050]
s2:设置迭代次数epoch,学习率lr、丢弃概率dp等参数,其中epoch=100,lr=0.004,dp=0.2;
[0051]
s3:基于图卷积网络(graph convolutional networks,gcn)和多层感知机(multilayer perceptron,mlp)构建网络生成模型。基于gcn构建节点表示模型。为了区分不同模型中的图卷积网络,图3中,利用gcn1表示网络生成模型中的图卷积网络模块,gcn2表示节点表示模型中的图卷积网络模块;
[0052]
s4:基于网络生成模型,计算每层网络的低维表示,本装置gcn计算公式如下所示:
[0053][0054]
其中,x表示输入特征,a为多层网络的邻接矩阵,i表示单位矩阵,是
的度矩阵,w
(0)
和w
(1)
分别为第一层和第二层gcn的权重矩阵,σ为激活函数。
[0055]
由于多层网络的特殊分层结构,为了使增强网络具备每层网络的信息,本装置平均聚合每层网络低维表示得到多层网络共识低维表示作为mlp的输入,mlp生成的节点间的权重作为可学习增强网络的邻接矩阵a
′
;
[0056]
s5:基于节点表示模型,首先计算可学习增强网络的低维表示h',标准化后记作z',然后计算输入多层网络中每层网络的低维表示hi,标准化后记作zi,其中i={1,2,
…
l},l为网络层数;
[0057]
s6:基于对比学习思想,利用可学习增强网络的低维表示与多层网络低维表示构建对比,基于如下公式,求解损失函数:
[0058][0059]
其中,diag(*)表示计算*的对角矩阵,s()为softmax函数,τ表示常数,设定τ=0.6,mean()表示计算平均值,z
it
表示zi的转置。根据如上所述公式,该公式通过计算标准化低维向量z'和zi间的节点相似度矩阵,然后通过diag()求解对应节点间的相似度,并根据mean()函数求解节点间相似性的平均值,以此获得两个低维表示的总体相似度;
[0060]
s7:基于s6所求损失函数,反向优化网络生成模型和节点表示模型,使可学习增强网络更好地聚合多层网络信息,同时提高了节点表示模型的鲁棒性,保证其在不同网络环境下的准确率;
[0061]
s8:循环执行训练过程s4-s7,迭代优化网络生成模型和节点表示模型,直到迭代次数达到预定参数epoch;
[0062]
s9:基于训练好的节点表示模型,求解多层网络共识低维表示,并采用kmeans求解共识社团划分。其中,每个社团由若干个节点构成,每个节点代表社交网络中的一个用户账号。因此,本装置最终求得的每个社团本质上表示输入的多通道社交网络中的一组社交帐号构成的社交圈子。即如图2所示示例中,所提装置将6个用户划分为了2个具有不同话题和爱好的社交圈子。
[0063]
为了验证本发明装置和方法,采用了7个不同的数据集,如表1所示,其中,前五个为真实数据集,syn1与syn2为用于鲁棒性测试的人工生成网络组。snd为社交网络,wtn和wbn分别为世界贸易网络和蠕虫脑网络。cora和citeseer均为文献网络。
[0064]
表1数据集汇总
[0065]
网络节点数层数社团数量snd7133wtn1831410wbn279510cora166223citeseer331223syn112834-8syn212894-8
[0066]
分别采用随机网络、真实网络和可学习增强网络作为测试对象,表2为消融实验结果。实验结果证明,在真实网络cora和人工网络s1,s2中,可学习增强网络均取得了最高的nmi,特别在s2中,相较于随机网络,提升幅度超过100%,该实验证明了可学习增强网络对于装置性能的有效提升。
[0067]
表2消融实验结果
[0068][0069]
图4为鲁棒性分析实验图,包含三个对比方法,其中nacc为本发明所提出的基于增强网络对比约束的多通道社交圈子识别装置。由于人工生成网络结构参数可调,为了验证发明装置的鲁棒性,该实验采用大量人工网络代替社交网络进行测试,人工网络分别通过μ,dc和layer控制网络结构。其中(a)和(b)属于第1组网络(syn1),包含3层网络,两组网络μ分别设置为0.5和0.6,dc={0.2-0.8}。(c)和(d)属于网络组syn2,包含9层网络,μ分别设置为0.5和0.6,dc={0.2-0.8}。对比方法分别为sc-ml,comclus,moea-multinet。从实验结果可以看出,在图(a)所示数据集中,所提出的nacc装置在精度上取得了较大的领先,且在不同dc参数的网络下,nacc波动明显小于对比方法,说明在可优化增强网络的指导下,本发明装置在面对不同拓扑结构的数据集时均能保持较高的精度。
[0070]
为了进一步证明本发明装置的性能,将μ设置为0.6(如图(b)所示),此时人工网络拓扑结构复杂,节点连接较为混乱,没有明显的社团关系,在这类数据集下,nacc总体保持较高的精度,尤其在dc={0.3,0.6}时,效果明显优于对比方法。如图(c)所示,在μ=0.5,layer=9的网络参数下,nacc取得了较为明显的优势。在图(d)所示结果中,nacc装置在dc=0.8网络中效果不佳,这是因为dc控制人工网络的不同层间节点的度数差异,该网络不同层间差异较大,导致所发明装置在聚合不同网络层低维表示时效果不佳。在dc={0.2-0.7}的网络中,性能明显优于对比方法,特别在dc=0.3时有较大领先。纵观全图,本发明提出的装置在接近89%的数据集中均取得了最高的准确率,且在结构复杂,社团模糊的网络中(μ=0.6),仍然取得了较大的优势。实验证明本装置在不同结构的网络中均能以较高的性能完成多层网络社团挖掘任务,即社交圈子识别任务。
[0071]
分别采用wbn真实网络和128节点人工网络作为测试数据,验证装置在迭代次数epoch=[10,30,50,70,90,110,130,150]下准确率(nmi)和损失函数(loss)的变化情况。图5展示了收敛性分析的结果,其中左轴和红色六边形折线代表nmi随迭代次数的变化情况,右轴和蓝色五角星曲线则为损失函数值的变化情况。在wbn和人工数据集(synthetic)中,损失函数值(loss)随着迭代次数(epoch)增加呈递减规律变化,且变化速率先快后慢,而nmi值则先增后减,在某个特定epoch值下达到峰值。这是由于gcn作为nacc装置中网络生成模型和节点表示模型的主要组成部分,在epoch和网络深度增加的过程中会导致过度平滑(over-smooth)问题。在wbn数据集中,nmi在epoch=110时达到最高,而在人工数据集中,则在epoch=50达到最优。
[0072]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。