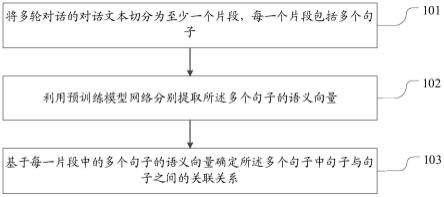
1.本发明涉及数据处理技术领域,具体为多维数据元融合实现数据收集和共享的时空数据湖方法。
背景技术:
2.多元融合技术是指多种数据的融合或集成技术,数据融合是20世纪80年代形成和发展起来的一种综合信息处理技术,它充分利用多源数据的互补性和计算机的高速运算与智能来提高结果信息的质量。
3.到了20世纪80年代以后,基于关系型数据库的事务处理成为了企业it应用的主流。在这个阶段,企业的it应用主要还是着重于业务职能的自动化及信息的存储、汇总、统计、查询等方面,而分析能力是比较薄弱的,因此这样的信息处理模式称之为事务处理。
4.数据湖和数据库、数据仓库一样,都是数据存储的设计模式,现在企业的数据仓库都会通过分层的方式将数据存储在文件夹、文件中,数据湖是一个集中式数据存储库,用来存储大量的原始数据,使用平面架构来存储数据,定义:一个以原始格式(通常是对象块或文件)存储数据的系统或存储库,通常是所有企业数据的单一存储,数据湖中数据,用于报告、可视化、高级分析和机器学习等任务,数据湖具有以下特点:a)容量大:数据湖汇聚吸收各个业务数据源流,容纳散落在各处的数据,理论上,存储空间巨大,b)格式多:数据湖架构面向多数据源的信息存储,可以快速高效地采集、存储、处理大量来源不同、格式不同的原始数据,这其中包括文本、图片、视频、音频、网页等各类无序的非结构化数据,能把不同种类的数据汇聚存储在一起,并对汇聚后的数据进行管理,建立数据之间的关联关系,具有很强的兼容性,c)处理速度快:数据湖技术能将各类原始数据快速转化为可以直接提取的、分析、使用的标准格式,统一优化数据结构并对数据进行分类存储,根据业务需求,对存储的数据进行快速的查询、挖掘、关联和处理,并实时传输给末端用户。
5.现有的数据湖技术作为用来存储大量的原始数据,因此没有良好的数据的优化与处理,在读取使用的过程中容易造成搜索共享混乱的情况,为此,我们提出多维数据元融合实现数据收集和共享的时空数据湖方法。
技术实现要素:
6.针对现有技术的不足,本发明提供了多维数据元融合实现数据收集和共享的时空数据湖方法,解决了上述背景技术中提出的问题。
7.为实现以上目的,本发明通过以下技术方案予以实现多维数据元融合实现数据收集和共享的时空数据湖方法,包括以下步骤:s1、数据收集从移动设备、网站、移动应用程序、社交媒体和企业应用程序中获取非关系与关系数据,其中获取的数据包括储存结构化数据、半结构化数据、非结构化数据和二进制数据,得到的数据为源数据;
s2、建立数据仓管理模型建立数据仓管理模型并将获取的源数据导入其中,利用数据仓管理模型对导入的源数据进行预处理,其中数据的预处理包括数据的清洗、数据补偿与数据格式处理统一,使得源数据能够精炼标准;s3、数据分类将数据仓中的源数据进行分类,并根据源数据的类型进行分类,然后对分类后的源数据根据数据的相似程度和相关性进行归类;s4、数据融合将归类后的源数据进行数据融合;s5、数据湖的建立基于hdfs可以构建存储数据的数据湖,并利用spark引擎将融合后的源数据摄取到数据湖中进行储存,并以数据湖为基础架构建时空大数据分析云平台,用于时空湖内部存储数据的共享;s6、资源共享在时空大数据分析云平台中接入共享登录入口,其中共享登录入口需要个人注册账号登录使用,账号的唯一性与等级性作为读取数据湖内部数据的基础,根据账号等级的权限用于读取获取对数据湖内部数据的操作,其中账号的等级根据使用者的使用时长权限决定,并建立搜索引擎,利用搜索引擎搜索共享数据湖中存储的信息。
8.进一步的,所述在步骤s1数据收集过程中采用的储存结构化数据为关系型数据库中的表,半结构化数据为csv、日志、xml和json文件,非结构化数据为电子邮件、文档和pdf,二进制数据为图形、音频和视频数据。
9.进一步的,所述在步骤s2建立数据仓管理模型过程中的将获取的源数据进行处理,其中处理过程为数据清洗将源数据中重复性相似性较多的数据删除,并在数据清洗的过程中对源数据进行补偿查缺,将源数据中不完整数据进行联想补充,接着将补偿后的源数据进行规格统一,保证数据流通格式的一致性。
10.进一步的,所述在步骤s3数据分类过程中对于源数据的分类首先根据数据的类型进行分类,并在分类后将源数据再次整合根据源数据中数据的相关性进行单元的归类。
11.进一步的,所述在步骤s5数据湖的建立过程中采用的数据湖允许存储大量的原始数据,不会拒绝任何数据的包容性,从源头获取源数据时不受数据结构的约束。
12.进一步的,所述在步骤s5数据湖的建立过程中利用引擎spark将融合后的源数据摄取到数据湖中进行储存,并在存储时加入时间轴,根据时间,在每一次存储前后均会自动生成时间戳,从而可以实现在仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据,有效避免了扫描更大时间范围的数据。
13.进一步的,所述在s6资源共享的过程中采用的搜索引擎分别为快照查询、增量查询和读优化查询,即快照查询为查询某个增量提交操作中数据集的最新快照,先进行动态合并最新的基本文件和增量文件来提供近实时数据集,增量查询为仅查询新写入数据集的文件,需要指定一个即时时间作为条件,来查询此条件之后的新数据,读优化查询为直接查询基本文件。
14.本发明提供了多维数据元融合实现数据收集和共享的时空数据湖方法,具备以下
有益效果:该多维数据元融合实现数据收集和共享的时空数据湖方法采用构建存储数据的数据湖使其能够存储大量的原始数据,利用数据仓对数据进行处理通过数据仓的建立不仅能够降低数据存储的成本,同时能够去除数据的重复性,同时能够对数据进行补偿补充数据的完整性,利用分类将数据根据类型相关性进行分类方便后续数据的提取存储过程,并提取在存储数据的过程中每一次存储前后均会自动生成时间戳,从而可以实现在仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据,有效避免了扫描更大时间范围的数据,并在数据湖的基础上建立时空大数据分析云平台,利用登录入口使得能够共享数据湖内部数据,并接入搜索引擎根据快照查询、增量查询和读优化查询三种不同查询表的方式,实现共享查询数据的效率,方便使用者使用。
具体实施方式
15.多维数据元融合实现数据收集和共享的时空数据湖方法,包括以下步骤:s1、数据收集从移动设备、网站、移动应用程序、社交媒体和企业应用程序中获取非关系与关系数据,其中获取的数据包括储存结构化数据、半结构化数据、非结构化数据和二进制数据,得到的数据为源数据,采用的储存结构化数据为关系型数据库中的表,半结构化数据为csv、日志、xml和json文件,非结构化数据为电子邮件、文档和pdf,二进制数据为图形、音频和视频数据;s2、建立数据仓管理模型建立数据仓管理模型并将获取的源数据导入其中,利用数据仓管理模型对导入的源数据进行预处理,其中数据的预处理包括数据的清洗、数据补偿与数据格式处理统一,使得源数据能够精炼标准,获取的源数据进行处理,其中处理过程为数据清洗将源数据中重复性相似性较多的数据删除,并在数据清洗的过程中对源数据进行补偿查缺,将源数据中不完整数据进行联想补充,接着将补偿后的源数据进行规格统一,保证数据流通格式的一致性;s3、数据分类将数据仓中的源数据进行分类,并根据源数据的类型进行分类,然后对分类后的源数据根据数据的相似程度和相关性进行归类,对于源数据的分类首先根据数据的类型进行分类,并在分类后将源数据再次整合根据源数据中数据的相关性进行单元的归类;s4、数据融合将归类后的源数据进行数据融合;s5、数据湖的建立基于hdfs可以构建存储数据的数据湖,并利用spark引擎将融合后的源数据摄取到数据湖中进行储存,并以数据湖为基础架构建时空大数据分析云平台,用于时空湖内部存储数据的共享,利用引擎spark将融合后的源数据摄取到数据湖中进行储存,并在存储时加入时间轴,根据时间,在每一次存储前后均会自动生成时间戳,从而可以实现在仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据,有效避免了扫描更大时间范围的数据;s6、资源共享
在时空大数据分析云平台中接入共享登录入口,其中共享登录入口需要个人注册账号登录使用,账号的唯一性与等级性作为读取数据湖内部数据的基础,根据账号等级的权限用于读取获取对数据湖内部数据的操作,其中账号的等级根据使用者的使用时长权限决定,并建立搜索引擎,利用搜索引擎搜索共享数据湖中存储的信息,采用的搜索引擎分别为快照查询、增量查询和读优化查询,即快照查询为查询某个增量提交操作中数据集的最新快照,先进行动态合并最新的基本文件和增量文件来提供近实时数据集,增量查询为仅查询新写入数据集的文件,需要指定一个即时时间作为条件,来查询此条件之后的新数据,读优化查询为直接查询基本文件。
16.综上所述,该多维数据元融合实现数据收集和共享的时空数据湖方法,使用时多维数据元融合实现数据收集和共享的时空数据湖方法包括以下具体步骤:s1、数据收集:选移动设备、网站、移动应用程序、社交媒体和企业应用程序中获取非关系与关系数据,其中获取的数据包括储存结构化数据、半结构化数据、非结构化数据和二进制数据,得到的数据为源数据,采用的储存结构化数据为关系型数据库中的表,半结构化数据为csv、日志、xml和json文件,非结构化数据为电子邮件、文档和pdf,二进制数据为图形、音频和视频数据;s2、建立数据仓管理模型并将获取的源数据导入其中,建立数据仓管理模型并将获取的源数据导入其中,利用数据仓管理模型对导入的源数据进行预处理,其中数据的预处理包括数据的清洗、数据补偿与数据格式处理统一,使得源数据能够精炼标准,获取的源数据进行处理,其中处理过程为数据清洗将源数据中重复性相似性较多的数据删除,并在数据清洗的过程中对源数据进行补偿查缺,将源数据中不完整数据进行联想补充,接着将补偿后的源数据进行规格统一,保证数据流通格式的一致性;s3、数据分类:将数据仓中的源数据进行分类,并根据源数据的类型进行分类,然后对分类后的源数据根据数据的相似程度和相关性进行归类,对于源数据的分类首先根据数据的类型进行分类,并在分类后将源数据再次整合根据源数据中数据的相关性进行单元的归类;s4、数据融合:将归类后的源数据进行数据融合;s5、数据湖的建立:基于hdfs可以构建存储数据的数据湖,并利用spark引擎将融合后的源数据摄取到数据湖中进行储存,并以数据湖为基础架构建时空大数据分析云平台,用于时空湖内部存储数据的共享,利用引擎spark将融合后的源数据摄取到数据湖中进行储存,并在存储时加入时间轴,根据时间,在每一次存储前后均会自动生成时间戳,从而可以实现在仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据,有效避免了扫描更大时间范围的数据;s6、资源共享:在时空大数据分析云平台中接入共享登录入口,其中共享登录入口需要个人注册账号登录使用,账号的唯一性与等级性作为读取数据湖内部数据的基础,根据账号等级的权限用于读取获取对数据湖内部数据的操作,其中账号的等级根据使用者的使用时长权限决定,并建立搜索引擎,利用搜索引擎搜索共享数据湖中存储的信息,采用的搜索引擎分别为快照查询、增量查询和读优化查询,即快照查询为查询某个增量提交操作中数据集的最新快照,先进行动态合并最新的基本文件和增量文件来提供近实时数据集,增量查询为仅查询新写入数据集的文件,需要指定一个即时时间作为条件,来查询此条件
之后的新数据,读优化查询为直接查询基本文件。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。