技术特征:
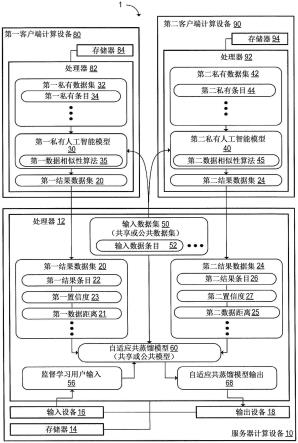
1.一种用于与计算设备一起使用的方法,所述方法包括:将输入数据集输入到已使用第一私有数据集生成的第一私有人工智能模型和已使用第二私有数据集生成的第二私有人工智能模型中;作为将所述第一私有人工智能模型应用于所述输入数据集的结果,从所述第一私有人工智能模型接收第一结果数据集;作为将所述第二私有人工智能模型应用于所述输入数据集的结果,从所述第二私有人工智能模型接收第二结果数据集;在第一训练阶段,以所述输入数据集作为输入并且以所述第一结果数据集作为第一目标输出来训练自适应共蒸馏模型;并且在第二训练阶段,以所述输入数据集作为所述输入并且以所述第二结果数据集作为第二目标输出来进一步训练所述自适应共蒸馏模型,其中,所述自适应共蒸馏模型不在所述第一私有数据集或所述第二私有数据集上训练。2.根据权利要求1所述的方法,其中,所述第一私有人工智能模型具有第一模型架构,并且所述第二私有人工智能模型具有不同于所述第一模型架构的第二模型架构。3.根据权利要求2所述的方法,其中,所述第一私有人工智能模型和所述第二私有人工智能模型中的每一个是深度神经网络、内核机或随机森林。4.根据权利要求1所述的方法,其中:所述自适应共蒸馏模型是分类模型;并且所述第一结果数据集和所述第二结果数据集各自包括相应的多个分类标签。5.根据权利要求4所述的方法,其中,所述输入数据集是部分标记的数据集,所述部分标记的数据集包括具有相应输入分类标签的输入数据条目的第一子集和不具有相应输入分类标签的输入数据条目的第二子集。6.根据权利要求1所述的方法,其中:所述自适应共蒸馏模型是回归模型;并且所述第一结果数据集和所述第二结果数据集各自包括相应的多个数值。7.根据权利要求1所述的方法,其中:所述自适应共蒸馏模型是递归神经网络;并且所述输入数据集包括多个输入序列,每个输入序列包括多个有序输入值。8.根据权利要求1所述的方法,其中,至少在所述第一训练阶段,使用利用加权损失函数的训练算法来训练所述自适应共蒸馏模型。9.根据权利要求8所述的方法,其中,所述加权损失函数通过加权因子对所述自适应共蒸馏模型的预测输出与所述第一结果数据集的目标数据输出之间的损失进行加权,所述加权因子基于以下项中的一项或多项:通过第一相似性算法确定的所述输入数据集中的元素与所述第一私有数据集之间的数据距离、所述第一结果数据集中的置信度值、以及人工指定的输入。10.根据权利要求1所述的方法,其中,对所述第一结果数据集或所述第二结果数据集进行同态加密。11.根据权利要求1所述的方法,其中,至少部分地通过监督学习来训练所述自适应共
蒸馏模型。12.一种计算系统,包括:服务器计算设备,包括处理器,所述处理器被配置为:将输入数据集发送到以下设备:第一客户端计算设备,被配置为执行已使用第一私有数据集生成的第一私有人工智能模型;以及第二客户端计算设备,被配置为执行已使用第二私有数据集生成的第二私有人工智能模型;作为将所述第一私有人工智能模型应用于所述输入数据集的结果,从在所述第一客户端计算设备处执行的所述第一私有人工智能模型接收第一结果数据集;作为将所述第二私有人工智能模型应用于所述输入数据集的结果,从在所述第二客户端计算设备处执行的所述第二私有人工智能模型接收第二结果数据集;在第一训练阶段,以所述输入数据集作为输入并且以所述第一结果数据集作为第一目标输出来训练自适应共蒸馏模型;并且在第二训练阶段,以所述输入数据集作为所述输入并且以所述第二结果数据集作为第二目标输出来进一步训练所述自适应共蒸馏模型,其中,所述自适应共蒸馏模型不在所述第一私有数据集或所述第二私有数据集上训练。13.根据权利要求12所述的计算系统,其中,所述第一私有人工智能模型具有第一模型架构,并且所述第二私有人工智能模型具有不同于所述第一模型架构的第二模型架构。14.根据权利要求13所述的计算系统,其中,所述第一私有人工智能模型和所述第二私有人工智能模型中的每一个是深度神经网络、内核机或随机森林。15.根据权利要求12所述的计算系统,其中:所述自适应共蒸馏模型是分类模型;并且所述第一结果数据集和所述第二结果数据集各自包括相应的多个分类标签。16.根据权利要求12所述的计算系统,其中:所述自适应共蒸馏模型是回归模型;并且所述第一结果数据集和所述第二结果数据集各自包括相应的多个数值。17.根据权利要求12所述的计算系统,其中:所述自适应共蒸馏模型是递归神经网络;并且所述输入数据集包括多个输入序列,每个输入序列包括多个有序输入值。18.根据权利要求12所述的计算系统,其中,所述处理器还被配置为:在模板数据集上训练模板机器学习模型;并且将所述模板机器学习模型发送到所述第一客户端计算设备和所述第二客户端计算设备,其中:所述第一私有人工智能模型是已在所述第一私有数据集上被进一步训练的所述模板机器学习模型的第一副本;并且所述第二私有人工智能模型是已在所述第二私有数据集上被进一步训练的所述模板机器学习模型的第二副本。
19.根据权利要求12所述的计算系统,其中,至少部分地通过监督学习来训练所述自适应共蒸馏模型。20.一种用于与计算设备一起使用的方法,所述方法包括:将输入数据集输入到已使用第一私有数据集生成的第一私有人工智能模型和已使用第二私有数据集生成的第二私有人工智能模型中;作为将所述第一私有人工智能模型应用于所述输入数据集的结果,从所述第一私有人工智能模型接收第一结果数据集,其中,所述第一结果数据集包括多个第一分类标签;作为将所述第二私有人工智能模型应用于所述输入数据集的结果,从所述第二私有人工智能模型接收第二结果数据集,其中,所述第二结果数据集包括多个第二分类标签;在第一训练阶段,以所述输入数据集作为输入并且以所述第一结果数据集作为第一目标输出来训练自适应共蒸馏模型;在第二训练阶段,以所述输入数据集作为所述输入并且以所述第二结果数据集作为第二目标输出来进一步训练所述自适应共蒸馏模型,其中,所述自适应共蒸馏模型不在所述第一私有数据集或所述第二私有数据集上训练;接收包括多个运行时输入数据条目的运行时数据集;并且对于所述多个运行时输入数据条目中的每一个,输出选自包括所述多个第一分类标签和所述多个第二分类标签的组合分类标签集的运行时分类标签。
技术总结
提供了一种用于与计算设备一起使用的方法。该方法可以包括将输入数据集输入到使用第一私有数据集生成的第一私有人工智能模型和使用第二私有数据集生成的第二私有人工智能模型中。该方法还可以包括从第一私有人工智能模型接收第一结果数据集,以及从第二私有人工智能模型接收第二结果数据集。该方法还可以包括利用输入数据集和第一结果数据集训练自适应共蒸馏模型。该方法还可以包括利用输入数据集和第二结果数据集训练自适应共蒸馏模型。自适应共蒸馏模型可以不在第一私有数据集或第二私有数据集上训练。二私有数据集上训练。二私有数据集上训练。
技术研发人员:米谷竜
受保护的技术使用者:欧姆龙株式会社
技术研发日:2021.02.12
技术公布日:2022/9/14
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。