1.本发明涉及视频压缩编码技术领域,具体地,涉及一种基于分类的内容自适应下采样视频编码优化方法。
背景技术:
2.随着短视频应用的兴起和视频通信的需求增加,待处理的视频数据急剧增加,视频编码的性能要求达到更高的水平。每一代视频编码标准在提高编码效率的同时,也大幅增加了计算的复杂度。并且,实际应用中所能节省的最大码率尚未达到每代编码标准提出的理论值。因此,除了开发新的编码工具来更新编码标准,在不改动编解码器内部结构的前提下最大化当下编码标准的压缩效率,是视频编码优化的重要研究方向。
3.在编码前对视频进行下采样,解码后对视频进行上采样恢复至原始分辨率,是有效提高编码效率的预处理手段。但下采样的方法主要适用于低码率范围,并且具有视频内容选择性。一部分方法通过失真类型分析调整下采样的倍数来扩大码率适用范围,但仍有视频即使处于高码率也无法通过下采样后编码获得性能优化。一部分方法通过对下采样后编码与直接编码的率失真分析来进一步分析视频内容特征,从而判断视频适合哪种编码方式,但二次编码的方法十分耗时。
4.目前,基于机器学习的方法被广泛应用于自适应参数调整从而实现编码优化。
技术实现要素:
5.针对现有技术中的缺陷,本发明的目的是提供一种基于分类的内容自适应下采样视频编码优化方法。
6.根据本发明的一个方面,提供一种基于分类的内容自适应下采样视频编码优化方法,包括:
7.对视频序列重复编码后进行率失真性能比较,标记其适用于原分辨率直接编码或下采样后编码的标签;
8.将完成标记的所述视频序列分为训练视频序列和测试视频序列;
9.提取所述训练视频序列和所述测试视频序列的空间特征、时间特征以及同时包含空间信息和时间信息的空时特征;
10.采用支持向量机对所述训练视频序列按标签进行二分类,获得训练模型;
11.采用所述训练模型对所述测试视频序列进行标签预测,获得测试模型;
12.将待编码视频序列输入所述训练模型进行预测,判断视频是否需要进行下采样处理。
13.优选地,所述对视频序列重复编码后进行率失真性能比较,标记其适用于原分辨率直接编码或下采样后编码的标签,包括:
14.选择五个量化参数,对所述视频序列按原分辨率直接进行编码,计算其基于psnr(peak signal-to-noise ratio)和vmaf(video multimethod assessment fusion)的编码
质量,并绘制其率失真曲线;
15.选择五个量化参数,对所述视频序列进行2倍下采样后进行编码,在解码后将视频上采样至原始分辨率,并计算其基于psnr和vmaf的编码质量,并绘制其率失真曲线;
16.比较直接编码和下采样后编码的率失真曲线,分别标记所述视频序列的标签,将直接编码获得更优质量的视频标记为直接编码de(direct encoding),将下采样后编码获得更优质量的视频标记为下采样编码dse(downsample encoding)。
17.优选地,所述选择五个量化参数,包括:
18.在直接编码的过程中,量化参数集选取为{36,37,38,39,40},共五个量化参数;
19.在下采样后编码的过程中,量化参数集选取为{28,29,30,31,32},共五个量化参数。
20.优选地,所述对视频序列进行2倍下采样后编码与解码后将视频上采样至原始分辨率,包括:
21.使用lanczos滤波器对所述视频序列进行2倍下采样;
22.采用支持libx265类库的ffmpeg工具对完成下采样的视频序列进行编解码;
23.使用lanczos滤波器对完成编解码的视频序列上采样。
24.优选地,所述空间特征,包括:归一化的空间信息s、空间掩蔽效应sp和视频空间分辨率re;
25.所述归一化后的空间信息s:
[0026][0027]
其中,br0是待编码视频序列的码率,si是空间信息:
[0028]
si=median{std(sobel(fn))}
[0029]
其中,fn表示视频序列的第n帧,sobel表示索贝尔算子,std表示对滤波后的视频帧进行标准差计算,median表示对每一个视频帧的标准差选取中值;
[0030]
所述空间掩蔽效应sp:
[0031][0032]
其中,w表示视频帧的宽度,h表示视频帧的高度,s(i,j)表示坐标(i,j)处的像素级空间掩蔽效应:
[0033][0034]
其中,y(i,j)表示视频帧的一个像素,x(i,j)表示y(i,j)邻近像素的向量,c
yx
表示局部区域像素集ys和向量集xs的互相关矩阵,表示自相关矩阵c
x
的伪逆矩阵。其中,视频帧内m个像素点的相关矩阵c
yx
、c
x
可计算为:
[0035][0036]
[0037]
所述时间特征,包括:归一化的时间信息t和视频的帧率fr;
[0038]
所述归一化的时间信息t:
[0039][0040]
其中,ti是时间信息:
[0041]
ti=median{std(f
n-f
n-1
)}
[0042]
所述同时包含空间和时间信息的空时特征,包括:待编码视频序列的码率br0和场景临界cri;
[0043]
所述场景临界cri:
[0044]
cri=log
10
{∑(sin×
tin)/l}
[0045]
其中,sin和tin分别表示第n帧的si和ti,l表示视频序列的总帧数。
[0046]
优选地,所述将完成标记的所述视频序列分为训练视频序列和测试视频序列,包括:
[0047]
将完成标记的所述视频序列随机划分出80%序列作为训练视频序列;
[0048]
将所述视频序列中剩余的20%序列作为测试视频序列。
[0049]
优选地,所述采用支持向量机对训练视频序列按标签进行二分类,获得训练模型,包括:
[0050]
提取所述训练视频序列的归一化的空间信息s、空间掩蔽效应sp、视频空间分辨率re、归一化的时间信息t、视频的帧率fr、待编码视频序列的码率br0和场景临界cri,共计七种视频内容特征;
[0051]
将所述训练视频序列的标签和所述七种视频内容特征作为训练数据,输入支持向量机,并选择高斯核函数进行二分类训练,获得训练模型。
[0052]
优选地,所述采用所述训练模型对测试视频序列进行标签预测,获得测试模型,包括:
[0053]
提取所述测试视频序列的所述七种视频内容特征;
[0054]
将所述测试视频序列的标签和所述七种视频内容特征作为测试数据;
[0055]
输入训练得到的所述训练模型进行二分类测试,获得测试模型。
[0056]
优选地,所述将待编码视频序列输入所述训练模型进行预测,判断视频是否需要进行下采样处理,包括:
[0057]
将所述待编码视频序列输入所述训练模型;
[0058]
所述训练模型输出对应分标签;
[0059]
若所述标签为dse,则表示需要下采样处理;
[0060]
若所述标签为de,则表示不需要下采样处理。
[0061]
优选地,所述训练模型包括两种分类器,其中:
[0062]
第一种分类器是针对多种分辨率的通用模型;该模型的训练视频序列包括4种分辨率的视频序列,测试视频序列同样包括4种分辨率的视频序列,经过训练测试得到1个适用于多种分辨率的分类模型;
[0063]
第二种分类器是针对单个分辨率的特定分辨率模型;该模型的训练视频序列与测试视频训练均仅包括1种分辨率的视频序列,经过测试训练得到4个针对不同分辨率的分类
模型;第二种分类器在训练与测试过程中,所使用的空间特征可省略视频空间分辨率re。
[0064]
与现有技术相比,本发明具有如下的有益效果:
[0065]
本发明实施例中的一种基于分类的内容自适应下采样视频编码优化方法,结合支持向量机与下采样后编码的处理方法,实现了提取视频内容特征进行训练、预测的分类方法,提供了针对低码率环境下,低时间复杂度的编码方案选择。
[0066]
本发明实施例中的一种基于分类的内容自适应下采样视频编码优化方法,在提供高准确性的视频编码方案预测的同时,节省了可观的码率资源,对于挖掘当代编码标准的潜在压缩效率具有重要的参考价值。
附图说明
[0067]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
[0068]
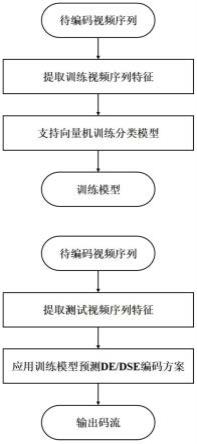
图1为本发明提供的一个优选实施例的基于分类的内容自适应下采样视频编码优化方法流程图。
[0069]
图2为本发明提供的一个实施例中特征提取像素点选取示例图。
具体实施方式
[0070]
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
[0071]
本发明提供一个实施例,一种基于分类的内容自适应下采样视频编码优化方法,参照图1,包括:
[0072]
s1、对视频序列重复编码后进行率失真性能比较,标记其适用于原分辨率直接编码或下采样后编码;(此处的重复编码为两次编码,第一次编码以原分辨率编码,第二次编码以下采样后的分辨率编码)
[0073]
s2、将完成标记的所述视频序列分为训练视频序列和测试视频序列;
[0074]
s3、提取所述训练视频序列和所述测试视频序列的空间特征、时间特征以及同时包含空间信息和时间信息的空时特征;
[0075]
s4、采用支持向量机对所述训练视频序列按标签进行二分类,获得训练模型;
[0076]
s5、采用所述训练模型对所述测试视频序列进行标签预测,获得测试模型;
[0077]
s6、通过对所述视频编码方案的预测,自适应判断视频是否需要下采样处理。
[0078]
其中,自适应指的是此方法针对各种视频内容的自适应,即此方法法可根据输入视频的内容,自动调整编码视频序列的分辨率。
[0079]
基于上述实施例,本发明提供一个优选实施例实行s1,包括:
[0080]
s101,选择一个符合编码标准的编码工具;本实施例中选取支持libx265类库的编码工具ffmpeg,软件测试的硬件平台为11th gen intel core i7-11700k,cpu@3.60ghz,内存32gb,windows 10 64位操作系统。
[0081]
s102,选择videoset数据集中量化参数为0的视频序列作为待编码视频序列。本示
例使用了220个不同内容的视频序列,每个序列包含4种分辨率,即640
×
360,960
×
540,1280
×
720,1920
×
1080,一共880个视频序列。
[0082]
s103,为了验证本发明的性能,对880个视频进行原分辨率直接编码和下采样后编码。直接编码的量化参数集选取为{36,37,38,39,40},下采样后编码的量化参数集选取为{28,29,30,31,32}。记录每个量化参数编码下的码率和压缩质量,绘制率失真曲线。
[0083]
s104,通过比较两次编码的率失真曲线,将直接编码质量更优的视频标记为de,将下采样后编码质量更优的视频标记为dse。
[0084]
本发明提供一个优选实施例,基于s1中videoset数据集中完成了标记的880个视频序列,实行s2,将完成标记的880个视频序列随机划分出80%序列作为训练视频序列;将剩余的20%序列作为测试视频序列。为更好地进行视频内容特征提取,本发明提供一个优选实施例以获取视频的空间特征、时间特征以及同时包含空间和时间信息的空时特征,具体的,包括:
[0085]
s301,提取数据集每个视频序列的空间特征:归一化的空间信息s、空间掩蔽效应sp、视频空间分辨率re。其中,归一化的空间信息s的计算公式如下:
[0086][0087]
其中,br0是待编码视频序列的码率,si是空间信息:
[0088]
si=median{std(sobel(fn))}
[0089]
其中,fn表示视频序列的第n帧,sobel表示索贝尔算子,std表示对滤波后的视频帧进行标准差计算,median表示对每一个视频帧的标准差选取中值。
[0090]
空间掩蔽效应sp:
[0091][0092]
其中,w表示视频帧的宽度,h表示视频帧的高度,s(i,j)表示坐标(i,j)处的像素级空间掩蔽效应:
[0093][0094]
其中,y(i,j)表示视频帧的一个像素,x(i,j)表示y(i,j)邻近像素的向量,如图2所示,c
yx
表示局部区域像素集ys和向量集xs的互相关矩阵,表示自相关矩阵c
x
的伪逆矩阵。其中,视频帧内m个像素点的相关矩阵c
yx
、c
x
可计算为:
[0095][0096][0097]
s302,提取数据集每个视频序列的时间特征:归一化的时间信息t、帧率fr。其中归一化的时间信息t的计算公式如下:
[0098]
[0099]
其中,ti是时间信息:
[0100]
ti=median{std(f
n-f
n-1
)}
[0101]
s303,提取数据集每个视频序列同时包含空间与时间信息的特征:待编码视频序列的码率br0,场景临界cri。其中,cri计算公式如下:
[0102]
cri=log
10
{∑(sin×
tin)/l}
[0103]
其中,sin和tin分别表示第n帧的si和ti,l表示视频序列的总帧数。
[0104]
s401,随机选取数据集的80%视频序列作为训练集,并将其通过率失真分析获得的标签与提取的六种视频内容特征作为训练数据,输入支持向量机,选择高斯核函数进行二分类训练,获得训练模型。
[0105]
s501,将剩余20%视频序列作为测试集,并将其通过率失真分析获得的标签与提取的六种视频内容特征作为测试数据,输入s301获得的训练模型,获得测试模型。通过对所述视频编码方法的预测,自适应判断是否需要下采样处理。
[0106]
s601,s401与s501的过程可以迭代1000次来减少训练与测试的误差。
[0107]
在本发明的另一个优选实施例中,根据数据集的划分,本实施例设计了两种不同的分类器。
[0108]
第一种分类器是针对多种分辨率的通用模型。该模型的训练集包括4种分辨率的视频序列,测试集同样包括4种分辨率的视频序列,经过训练测试得到1个适用于多种分辨率的分类模型;
[0109]
第二种分类器是针对单个分辨率的特定分辨率模型。该模型的训练集与测试集均仅包括1种分辨率的视频序列,经过测试训练得到4个针对不同分辨率的分类模型。由于此分类器的训练数据只包含一种分辨率的视频序列,在训练与测试过程中,所使用的空间特征可省略视频空间分辨率re。
[0110]
在880个视频序列下,将使用5个qp重复编码后获得率失真曲线判断视频最佳压缩分辨率的方法,与本实施例提出的方法对比得出,基于psnr的质量评价下,本实施例提出的方法较直接编码平均节省了3.12%的bdbr,基于vmaf的质量评价下,本实施例提出的方法较直接编码平均节省了2.88%的bdbr。
[0111]
分类器的准确性使用混淆矩阵表示,其中通用模型分别在psnr与vmaf下的分类准确度如表1所示。为了说明本实施例的优越性,将本实施例提出的方法与采用原分辨率直接编码的方法进行了性能比较与时间复杂度比较,表2总结了通用模型的bdbr,表3中的结果记录了直接编码与本实施例中特征提取所需要的运行时间,说明本实施例的方法具有较低的时间复杂度。
[0112]
表1
[0113][0114]
表2
[0115][0116]
表3
[0117][0118]
表4
[0119][0120][0121]
表5
[0122][0123]
相似地,表4和表5展示了针对不同分辨率的特定模型的实验结果。此4个分类模型
同样实现了较高的准确率与节省了可观的bdbr。
[0124]
需要说明的是,本发明提供的所述方法中的步骤,可以利用所述系统中对应的模块、装置、单元等予以实现,本领域技术人员可以参照所述系统的技术方案实现所述方法的步骤流程,即,所述系统中的实施例可理解为实现所述方法的优选例,在此不予赘述。
[0125]
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0126]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。