一种基于dm-dqn的移动机器人路径规划方法
技术领域
1.本发明涉及dqn算法技术领域,尤其涉及一种基于dm-dqn的移动机器人路径规划方法。
背景技术:
2.随着人工智能的发展潮流,机器人工业也朝着自主学习、自主探索的智能化方向发展,而移动机器人的路径规划是机器人运动中的核心问题,其目的在于能够找到一条从起点到终点无碰撞的最优或者次优路径;随着科技的不断发展,机器人所面临的环境越来越复杂,而且在未知环境中,我们无法获知整个环境的信息,因此传统的路径规划算法已经不能满足人们的需求,例如:人工势场算法、蚁群算法、遗传算法、粒子群算法等。针对这种情况,提出了深度强化学习,将深度学习与强化学习相结合,其中深度学习主要通过神经网络对输入的未知环境状态提取特征,实现环境状态到动作值函数的拟合;强化学习则根据深度神经网络的输出和探索策略完成决策,从而实现状态到动作的映射。深度学习与强化学习的结合解决了状态到动作映射所带来的维数灾难问题,能更好满足复杂环境下的机器人运动需求。
技术实现要素:
3.针对现有算法的不足,本发明引入了竞争网络结构,将网络结构分解为价值函数和优势函数,从而将动作选择和动作评估进行解耦,使得状态不再完全依赖于动作的价值来进行判断,可以进行单独的价值预测,解决了其收敛速度慢的问题;并通过设计基于人工势场的奖励函数,解决了机器人过于靠近障碍物边缘的问题。
4.本发明所采用的技术方案是:一种基于dm-dqn的移动机器人路径规划方法包括以下步骤:
5.步骤一、建立基于dm-dqn的移动机器人路径规划模型;
6.步骤二、设计dm-dqn算法的状态空间、动作空间、dm-dqn网络模型和奖励函数;
7.进一步的,dm-dqn网络模型的结构分为价值函数v(s,ω,α)和优势函数a(s,a,ω,β),dm-dqn网络模型的输出表示为:
8.q(s,a,ω,α,β)=v(s,ω,α) a(s,a,ω,β)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
9.其中,s表示状态,a表示动作,ω为v和a的公共参数,α和β分别为v和a的参数,v值可以看成是s状态下q值的平均数,a值是有平均数为0的限制,v值与a值的和就是原来的q值。
10.进一步的,将优势函数进行集中化,dm-dqn网络模型的输出表示为:
[0011][0012]
其中,s表示状态,a表示动作,a'表示下一个动作,a是可供选择的动作,ω为v和a的公共参数,α和β分别为v和a的参数。
[0013]
进一步的,奖励函数分为位置奖励函数和方向奖励函数,并根据位置奖励函数和
方向奖励函数计算得到总的奖励函数。
[0014]
进一步的,位置奖励函数中,首先使用引力势场函数构建目标引导奖励函数:
[0015][0016]
其中,ζ表示引力奖励函数常数,d
goal
表示当前位置到目标点之间的距离;
[0017]
其次,使用斥力势场函数构建避障奖励函数,该奖励为负奖励,随着机器人与障碍物的距离减小而减小:
[0018][0019]
其中,η表示斥力奖励函数常数,d
obs
表示当前位置到障碍物之间的距离,d
max
表示障碍物的最大影响距离。
[0020]
进一步的,方向奖励函数是根据机器人预期方向和实际方向之间的角度差表示,公式为:
[0021][0022]
其中,fq表示预期方向,fa表示实际方向,表示预期方向与实际方向的夹角;
[0023]
方向奖励函数可以表示为:
[0024][0025]
进一步的,移动机器人的总的奖励函数表示为:
[0026][0027]
其中,r
goal
表示以目标点为中心的目标区域半径,r
obs
表示以障碍物为中心的碰撞区域半径;
[0028]
步骤三、对dm-dqn算法进行训练,获得了经验奖励值,完成机器人无碰撞的路径规划。
[0029]
本发明的有益效果:
[0030]
1、通过引入竞争网络结构,将网络结构分解为价值函数和优势函数,从而将动作选择和动作评估进行解耦,使得状态不再完全依赖于动作的价值来进行判断,可以进行单独的价值预测,解决了其收敛速度慢的问题,使其具有更好的泛化性能。
[0031]
2、通过设计基于人工势场的奖励函数,解决了机器人过于靠近障碍物边缘的问题;在动态未知环境中的学习效率更高、收敛速度更快,并且能够规划出远离障碍物的无碰撞路径。
附图说明
[0032]
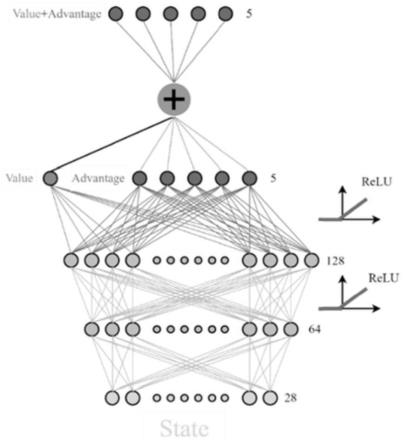
图1是本发明的dm-dqn网络结构图;
[0033]
图2(a)、(b)分别是本发明的静态环境图和动静态环境图;
[0034]
图3(a)、(b)是本发明的dm-dqn算法的静态环境和动态环境的奖励值图;
[0035]
图4(a)、(b)是本发明的静态环境生成路径图和动静态环境生成路径图。
具体实施方式
[0036]
下面结合附图和实施例对本发明作进一步说明,此图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
[0037]
针对m-dqn收敛速度慢的问题进行改进,引入了竞争网络结构,将网络结构分解为价值函数和优势函数;并针对机器人的运动轨迹过于靠近障碍物边缘的问题,设计人工势场方法的奖励函数,使机器人的运动轨迹远离障碍物周围。
[0038]
如图1所示,一种基于dm-dqn的移动机器人路径规划方法包括以下步骤:
[0039]
步骤一、建立基于dm-dqn的移动机器人路径规划模型,将移动机器人路径规划问题,描述为马尔科夫决策过程;
[0040]
首先,通过权重为θ的online dueling q-network来估计q值,并且在每经过c步权重θ被复制到权重为的目标网络中;
[0041]
其次,通过使用ε-greedy策略与环境进行交互,根据设计的基于人工势场的奖励函数,机器人获得奖励以及下一个状态,最后将transitions(s
t
,a
t
,r
t
,s
t 1
)被存储在固定大小的fifo重放缓冲区,并且每经过f步,dm-dqn从重放缓冲区d中随机抽取一批d
t
,并根据以下公式:
[0042][0043]
回归目标,将损失降至最低;
[0044]
式中,s表示状态,a表示动作,r表示奖励值,γ表示折扣因子。满足τ是超参数,用于控制熵的权重,a'表示t 1时刻的动作,α为超参数设置为1,表示该状态下选择的策略,是可供选择的动作。
[0045]
步骤二、设计dm-dqn算法的状态空间、动作空间、dm-dqn网络模型及奖励函数;
[0046]
状态空间包括:激光雷达数据、移动机器人当前的控制指令、移动机器人上一时刻的控制指令、目标点的方位和距离;
[0047]
动作空间包括:移动机器人的角速度和线速度;
[0048]
将机器人的动作空间离散为5个动作,固定线速度v为0.15m/s,给定角速度值,控制量的输出选择角速度而非直接给定转角,更符合移动机器人运动学特性,角速度给定按照如下公式:
[0049][0050]
其中,action_size表示动作空间离散为5个动作,action[5]表示动作的取值为:0~4,max_angel
vel
表示机器人转向的最大角速度值为1.5rad/s,5个动作按公式(2)计算,如式(3)所示,其中线速度v单位m/s,角速度ω单位rad/s。
[0051][0052]
进一步的,dm-dqn网络模型将网络结构划分为两部分,如图1所示,第一部分仅与状态s相关,称为价值函数,表示为v(s,ω,α);另一部分与状态s和动作a有关,称为优势函数,表示为a(s,a,ω,β),因此,网络的输出可以表示为:
[0053]
q(s,a,ω,α,β)=v(s,ω,α) a(s,a,ω,β)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0054]
其中s表示状态,a表示动作,ω为v和a的公共参数,α和β分别为v和a的参数,v值可以看成是s状态下q值的平均数,a值是有平均数为0的限制,v值与a值的和就是原来的q值;
[0055]
由于有a值之和必须为0的限制,所以网络会优先更新v值,v值是q值的平均数,平均数的调整相当于一次性更新该状态下的所有q值,所以网络在更新的时候,不但更新某个动作的q值,而是把这个状态下,所有动作的q值都调整一次。
[0056]
进一步的,在机器人路径规划中,价值函数是学习机器人没有检测到障碍物的情况,而优势函数是了解机器人检测障碍物,为了解决可识别性问题,将优势函数集中化:
[0057][0058]
其中s表示状态,a表示动作,a'表示下一个动作,a是可供选择的动作,ω为v和a的公共参数,α和β分别为v和a的参数。
[0059]
进一步的,奖励函数根据人工势场方法设计,将奖励函数分解为两部分:第一部分是位置奖励函数,包括目标引导奖励函数和避障奖励函数,目标奖励函数是引导机器人快速到达目标点,避障奖励函数是使机器人与障碍物保持一定的距离;
[0060]
第二部分是方向奖励函数,机器人当前朝向对合理导航起着关键作用,鉴于人工势场中机器人所受合力的方向可以很好地契合机器人的运动方向,所以设计方向奖励函数,引导机器人朝着目标点运动。
[0061]
进一步的,在位置奖励函数中,首先使用引力势场函数构建目标引导奖励函数:
[0062][0063]
其中,ζ表示引力奖励函数常数,d
goal
表示当前位置到目标点之间的距离;
[0064]
其次,使用斥力势场函数构建避障奖励函数,该奖励为负奖励,随着机器人与障碍物的距离减小而减小:
[0065][0066]
其中,η表示斥力奖励函数常数,d
obs
表示当前位置到障碍物之间的距离,d
max
表示障碍物的最大影响距离。
[0067]
进一步的,方向奖励函数中,机器人预期方向和实际方向之间的角度差表示为:
[0068][0069]
其中,fq表示预期方向,fa表示实际方向,表示预期方向与实际方向的夹角;
[0070]
因此,方向奖励函数可以表示为:
[0071][0072]
进一步的,总的奖励函数可以表示为:
[0073][0074]
移动机器人的总的奖励函数表示为:
[0075][0076]
其中,r
goal
表示以目标点为中心的目标区域半径,r
obs
表示以障碍物为中心的碰撞区域半径。
[0077]
设计仿真环境,移动机器人与环境进行交互,获取训练数据,采样训练数据对移动机器人进行仿真训练,完成无碰撞的路径规划;
[0078]
步骤三、对dm-dqn算法进行训练,获得了经验奖励值,完成机器人无碰撞的路径规划。
[0079]
具体实验步骤如下:
[0080]
通过gazebo模拟器来创建虚拟仿真环境,并通过gazebo建立机器人模型来实现路径规划任务,仿真环境包括静态环境和动静态环境如图2所示,图2(a)为静态环境、图2(b)为动态环境;
[0081]
采用python语言来实现路径规划算法并调用内置的gazebo模拟器来控制机器人运动并获取机器人感知信息。
[0082]
dm-dqn算法经过320次的仿真训练,获得了经验奖励值,如图3所示,图3(a)和(b)分别表示dm-dqn算法在静态环境下和动静态环境下记录了每个回合的累计奖励和智能体的平均奖励,其中每一个点表示一个回合,黑色曲线表示平均奖励,说明dm-dqn采取了竞争网络结构,将动作选择和动作评估进行解耦使得其具有更快的学习速率,因此可以更充分地利用前期对环境探索的经验,从而获得更大的奖励。
[0083]
对机器人指定7个点进行导航,机器人在未知环境下自主地从1号位置无碰撞地依次到达2~7号位置并再回到1号位置,实现了无碰撞的路径规划,如图4所示。
[0084]
如表1所示,同等训练条件下,对比本发明dm-dqn算法与现有算法,分别比较300回合下到达一个目标点的平均移动次数和成功到达目标点的次数,从表中可以发现dm-dqn的平均移动次数最少,在成功次数上相比于dqn算法增加50%;相比于dueling dqn增加23.6%;相比于m-dqn增加19.3%。
[0085]
表1
[0086][0087]
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。