1.本发明涉及医疗信息技术领域,特别涉及一种基于内容包含度的数据字典检索系统及方法。
背景技术:
2.数据字典是一组关于《编码、值》键值对的集合,数据字典作为信息系统的一类重要元数据,定义描述了信息系统数据字段的值域与编码,对信息化建设与信息系统维护起着至关重要的作用。为了更好的实现跨信息系统的数据集成与共享,需要对信息系统使用的数据字典进行治理,使各信息系统使用的本地数据字典与数据字典库中的标准字典保持一致,确保各信息系统采用一套统一的数据字典。
3.具体的,为了实现数据字典的治理目标,需要以本地数据字典为检索条件,通过检索数据字典库,然后参照标准数据字典对本地数据字典进行扩展,从而使得本地数据字典与标准数据字典保持一致。然而,现有的数据字典的检索方法仅支持以简单的字符串作为检索条件参数,通过简单的字符串匹配对数据字典相关的描述性信息比如字典名称、字典说明等进行匹配检索,无法实现基于数据字典内容的检索,检索的准确度和效率都较低,无法满足检索需求。
技术实现要素:
4.为解决上述问题,本发明提供了一种基于内容包含度的数据字典检索系统及方法。
5.本发明采用以下技术方案:
6.一种基于内容包含度的数据字典检索系统,包括输入模块、字典检索模块、标准字典库和输出模块;
7.所述输入模块用于输入检索条件字典;
8.所述标准字典库用于存储标准字典;
9.所述字典检索模块分别根据所述检索条件字典和标准字典生成对应的检索项值集合和标准项值集合,计算所述检索项值集合和标准项值集合之间的包含度,根据所述包含度对所述标准字典进行排序;
10.所述输出模块用于输出包含度的绝对值大于0的标准字典作为检索结果。
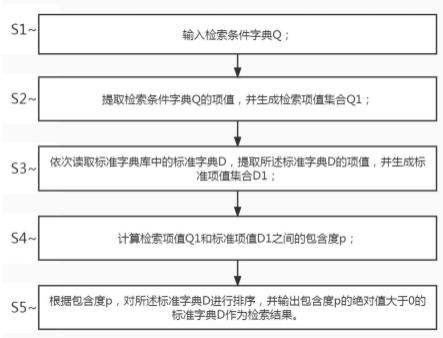
11.一种基于内容包含度的数据字典检索方法,所述检索方法基于上述检索系统实现,所述方法包括如下步骤:
12.s1、输入检索条件字典q;
13.s2、提取检索条件字典q的项值,并生成检索项值集合q1;
14.s3、依次读取标准字典库中的标准字典d,提取所述标准字典d的项值,并生成标准项值集合d1;
15.s4、计算检索项值q1和标准项值d1之间的包含度p;
16.s5、根据包含度p,对所述标准字典d进行排序,并输出包含度p的绝对值大于0的标准字典d作为检索结果。
17.进一步地,所述包含度p的计算公式如下:
[0018][0019]
其中,sim
dict
(d1,q1)的值范围为[-1,1]。
[0020]
进一步地,所述sim
dict
(d1,q1)的取值含义如下:
[0021]
当sim
dict
(d1,q1)为1时,表示标准项值集合d1完全包含检索项值集合q1,即检索项值集合q1为标准项值集合d1的一个子集;
[0022]
当sim
dict
(d1,q1)为-1时,表示标准项值集合d1完全被检索项值集合q1包含,也即标准项值集合d1为检索项值集合q1的一个子集;
[0023]
当sim
dict
(d1,q1)为(-1,1)且sim
dict
(d1,q1)≠0时,表示标准项值集合d1与检索项值集合q1之间存在部分包含,即部分字典的项值是相同的;
[0024]
当sim
dict
(d1,q1)=0时,表示标准项值集合d1与检索项值集合q1之间不存在任何项值相同的字典项。
[0025]
采用上述技术方案后,本发明与背景技术相比,具有如下优点:
[0026]
1、本发明提供了一种基于内容包含度的数据字典检索系统及方法,其支持直接以数据字典作为检索条件输入参数,自动提取待检索的数据字典的项值,并根据项值计算数据字典库中每个标准数据字典与作为检索条件的数据字典之间的匹配程度,最后根据匹配程度输出匹配度最高的表示数据字典;
[0027]
2、与传统的仅进行字符串匹配的检索方法不同,本发明采用提取数据字典项值和包含度计算相结合的方法,对标准字典进行查询检索,返回尽可能包含检索条件字典或尽可能被减速条件字典包含的标准字典,大大提高检索的精确度和效率,从而更好地满足数据字典治理过程中基于字典内容的数据字典的检索需求。
附图说明
[0028]
图1为本发明的检索方法流程图。
具体实施方式
[0029]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0030]
实施例一
[0031]
一种基于内容包含度的数据字典检索系统,包括输入模块、字典检索模块、标准字典库和输出模块;
[0032]
所述输入模块用于输入检索条件字典;
[0033]
所述标准字典库用于存储标准字典;
[0034]
所述字典检索模块分别根据所述检索条件字典和标准字典生成对应的检索项值集合和标准项值集合,计算所述检索项值集合和标准项值集合之间的包含度,根据所述包
含度对所述标准字典进行排序;
[0035]
所述输出模块用于输出包含度的绝对值大于0的标准字典作为检索结果。
[0036]
实施例二
[0037]
如图1所示,一种基于内容包含度的数据字典检索方法,所述检索方法基于实施例一所述的检索系统实现,本实施例以医疗信息系统建设为例,某医疗信息系统中存在名称为“治愈效果”的数据字典,该字段用于记录患者进行临床治疗后的病情变化情况,信息系统中该数据字段使用的本地数据字典如下表1所示:
[0038]
表1医疗信息系统中名称为“治愈效果”的数据字典;
[0039]
编码值说明2好转达到好转标准或症状减轻、功能部分恢复、体征改善3稳定病情无明显变化或加重4恶化病情加重
[0040]
以表1中信息系统的本地数据字典为例,找到尽可能包含查询条件字典或者尽可能被查询条件字典包含的数据标准字典,具体包括如下步骤:
[0041]
s1、输入检索条件字典q,如输入“治愈效果”;
[0042]
s2、提取检索条件字典q的项值,并生成检索项值集合q1:{好转、稳定、恶化};
[0043]
s3、依次读取标准字典库中的标准字典d,标准字典d如下表2所示,提取所述标准字典d的项值,并生成标准项值集合d1:{治愈、好转、稳定、恶化、死亡、其他};
[0044]
表2标准字典库中的标准字典
[0045][0046][0047]
s4、计算检索项值q1和标准项值d1之间的包含度p;
[0048]
s5、根据包含度p,对所述标准字典d进行排序,并输出包含度p的绝对值大于0的标准字典d作为检索结果。
[0049]
所述包含度p的计算公式如下:
[0050][0051]
其中,sim
dict
(d1,q1)的值范围为[-1,1]。
[0052]
当sim
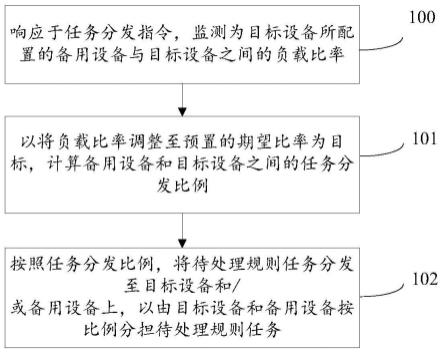
dict
(d1,q1)为1时,表示标准项值集合d1完全包含检索项值集合q1,即检索
项值集合q1为标准项值集合d1的一个子集;
[0053]
当sim
dict
(d1,q1)为-1时,表示标准项值集合d1完全被检索项值集合q1包含,也即标准项值集合d1为检索项值集合q1的一个子集;
[0054]
当sim
dict
(d1,q1)为(-1,1)且sim
dict
(d1,q1)≠0时,表示标准项值集合d1与检索项值集合q1之间存在部分包含,即部分字典的项值是相同的;
[0055]
当sim
dict
(d1,q1)=0时,表示标准项值集合d1与检索项值集合q1之间不存在任何项值相同的字典项。
[0056]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。