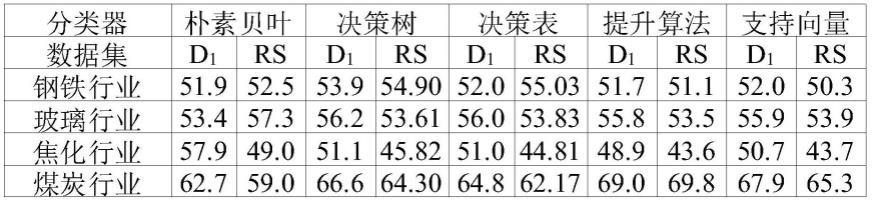
技术特征:
1.一种基于类别平衡的数据清洗方法,其特征在于包括以下步骤:a、用户输入需要抽取关键数据的数据集d以及需要的关键数据的个数n,将数据集d在每个类别中按照2:1的比例划分训练集d1和测试集;b、计算每个类别中应选出关键数据的个数;c、对数据集d进行含缺失值样本的删除、按类别对异常样本进行删除,并进行归一化操作,消除因量纲不同带来的影响,并按类别划分子集;d、对每个子集进行数据清洗操作,选取规定数量的关键数据,构成最终关键数据集;e、对关键数据进行补全。2.根据权利要求1所述的基于类别平衡的数据清洗方法,其特征在于:步骤b中,计算每个类别中应选出关键数据的个数包括以下步骤,l
i
=[x
i
*n/n0],其中l
i
为第i个类别中关键据数,x
i
为第i个类别的样本数,n0为训练集d1中的样本数;当∑l
i
>n时,及每个类别应选的关键数据数的总和大于既定的关键数n,t=∑l
i-n,将不同类别按照关键数据个数降序排列,对前t个类别进行每个类别减少一个关键数据的操作;当∑l
i
<n时,及每个类别应选的关键数据数的总和小于既定的关键数n,t=n-∑l
i
,将不同类别按照关键数据个数降序排列,对前t个类别进行每个类别增加一个关键数据的操作;当存在某一类别关键数据个数为0时,则增加一个关键数据,同时将当前关键数据最多的类别减少一个关键数据。3.根据权利要求2所述的基于类别平衡的数据清洗方法,其特征在于:步骤d中,对每个子集进行数据清洗操作包括以下步骤,d1、当l
i
小于子集中关键数据的特征类别数量,且子集中关键数据数量大于关键数据的特征类别数量时,使用关键数据的特征构造特征矩阵,对特征矩阵进行正交变换,然后将特征矩阵的协方差矩阵进行特征分解,得到投影坐标系,使用投影坐标系对特征矩阵进行投影降维,然后选取贡献率大于设定阈值的主成分作为清洗后的关键数据;当子集中关键数据数量小于关键数据的特征类别数量时,对关键数据进行若干次聚类处理,每次聚类选取若干个特征类别,选取的特征类别数量小于关键数据数量,根据选取的特征类别与关键数据的关联度进行聚类,记录每次聚类处理产生的孤立关键数据,最后按照记录次数对关键数据进行降序排列,从记录次数最多的关键数据开始删除,直至达到预设的清洗比例;d2、当l
i
大于子集中关键数据包含的特征类别数量时,在每一个特征中提取一个关键数据,特征选择顺序随机生成,循环若干次,直至l
i
小于子集中关键数据包含的特征类别数量后,转至步骤d1进行处理。4.根据权利要求3所述的基于类别平衡的数据清洗方法,其特征在于:步骤e中,对关键数据进行补全包括以下步骤,e1、当特征类别大于关键数据数量时,在数据清洗之后生成的最终关键数据集中包含数据量最大的若干个特征类别中选取关键数据进行补全;e2、当特征类别小于关键数据数量时,按照预设标准选取关键数据进行补全。5.根据权利要求4所述的基于类别平衡的数据清洗方法,其特征在于:步骤e1中,使用
的特征类别的数量的确定原则为,将特征类别按照数据量的多少降序排列,在保证选取关键数据的相关性小于设定阈值且使用的特征类别最少的前提下,从数据量最多的特征类别开始提取关键数据。6.根据权利要求4所述的基于类别平衡的数据清洗方法,其特征在于:步骤e2中,所述预设标准为,选取的关键数据之间的相关性小于设定阈值,且选取的关键数据与现有关键数据之间的相关性小于选取的关键数据之间的相关性。
技术总结
本发明公开了一种基于类别平衡的数据清洗方法,包括以下步骤:A、用户输入需要抽取关键数据的数据集D以及需要的关键数据的个数N,将数据集D在每个类别中按照2:1的比例划分训练集和测试集;B、计算每个类别中应选出关键数据的个数;C、对数据集D进行含缺失值样本的删除、按类别对异常样本进行删除,并进行归一化操作,消除因量纲不同带来的影响,并按类别划分子集;D、对每个子集进行数据清洗操作,选取规定数量的关键数据,构成最终关键数据集;E、对关键数据进行补全。本发明能够改进现有技术的不足,能够实现精确清洗并得到关键数据,对于人工智能和机器学习技术有着重要意义。义。义。
技术研发人员:周海波 王占立 唱立斌 吴宗培 于宁宁 褚立明
受保护的技术使用者:东方联信科技有限公司
技术研发日:2022.06.14
技术公布日:2022/9/2
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。