一种基于yolov4的行人检测方法及系统
技术领域
1.本发明属于计算机视觉技术领域,尤其涉及一种基于yolov4的行人检测方法及系统。
背景技术:
2.行人检测方式的发展大概可以分为传统视觉和深度学习两个阶段。传统视觉的方式是通过人为分析行人的特征,提取行人前景,再通过设计分类器进行判别分析,比较典型的有haar行人检测、hog行人检测和dpm行人检测等,这种方式的检测精度、速度以及模型的鲁棒性都存在一定的缺陷;随着计算机芯片算力的不断提升,近些年以卷积神经网络为代表的深度学习算法不断受到研究者的青睐,并在各种图像检测领域获得极佳的成绩,以yolo(you only look once)深度网络为代表的一阶段检测网络,实现了端到端的设计,通过针对特定图像数据的训练,算法在各种应用场景下都表现出良好的检测效果和鲁棒性。
3.发明人发现,现有的yolo深度网络在进行行人检测时,依然存在模型收敛速度较慢问题,以及当两个以上目标在图像中距离较近时,会出现检测目标丢失的现象,造成检测精度降低等问题。
技术实现要素:
4.本发明为了解决上述问题,提出了一种基于yolov4的行人检测方法及系统,本发明通过k-means算法得到行人数据的anchor,改进了目标回归与边界框回归的损失函数,引入了soft-nms算法改善目标遮挡丢失现象。
5.为了实现上述目的,本发明是通过如下的技术方案来实现:
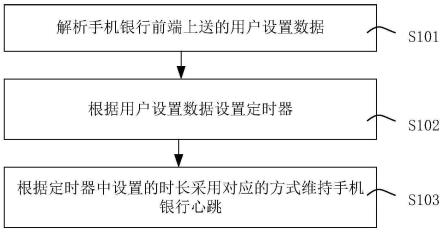
6.第一方面,本发明提供了一种基于yolov4的行人检测方法,包括:
7.获取待检测的图像信息;
8.依据图像信息,以及预设的行人检测网络模型,得到检测结果;
9.其中,所述行人检测网络模型为训练后的yolov4网络模型;yolov4网络模型中,在边界框损失函数中添加一个指数函数作为修正系数,所述指数函数的自变量为预测框与真实框之间宽高比的绝对值之差乘上预设调节参数的积。
10.进一步的,yolov4网络模型训练前,将行人的宽高数据作为离散数据,根据k均值聚类算法将数据划分为多类。
11.进一步的,边界框损失函数为:
[0012][0013]
其中,l
box
表示边界框损失函数;iou(a,b)表示a和b重叠度;ρ2表示预测框与目标框中心点距离平方;c2表示预测框与目标框最小包围矩阵对角线的距离平方;b
pre
表示预测框中心点坐标;b
gt
表示目标真实框中心点坐标;e
αδ
表示修正系数;δ表示预测框与真实框之间宽高比的绝对值之差;α表示预设调节参数。
[0014]
进一步的,在yolov4网络模型的类别损失函数中添加调节系数,调节负样本损失权重的比重。
[0015]
进一步的,调节系数的变化受迭代率影响,根据迭代的进行逐渐恢复至正常状态。
[0016]
进一步的,yolov4网络模型中的类别损失函数为:
[0017][0018]
其中,s2代表网格数;b代表网格中预测框数;代表网格中含有目标;代表网格中没有目标;代表交叉熵损失函数;代表类别概率;ci代表期望值;γ代表添加的调节系数。
[0019]
进一步的,在yolov4网络模型中的检测部分,采用对预范围内的低置信度预测框进行降低分值的策略。
[0020]
第二方面,本发明还提供了一种基于yolov4的行人检测系统,包括:
[0021]
数据采集模块,被配置为:获取待检测的图像信息;
[0022]
检测模块,被配置为:依据图像信息,以及预设的行人检测网络模型,得到检测结果;
[0023]
其中,所述行人检测网络模型为训练后的yolov4网络模型;yolov4网络模型中,在边界框损失函数中添加一个指数函数作为修正系数,所述指数函数的自变量为预测框与真实框之间宽高比的绝对值之差乘上预设调节参数的积。
[0024]
第三方面,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现了第一方面所述的基于yolov4的行人检测方法的步骤。
[0025]
第四方面,本发明还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现了第一方面所述的基于yolov4的行人检测方法的步骤。
[0026]
与现有技术相比,本发明的有益效果为:
[0027]
1、本发明在yolov4网络模型中的边界框损失函数中添加一个指数函数作为修正系数,所述指数函数的自变量为预测框与真实框之间宽高比的绝对值之差乘上预设调节参数的积,通过对预设调节参数的选取来确定修正系数,从而达到提升模型收敛速度的目的;
[0028]
2、本发明在检测部分引入了soft-nms算法,采用对预范围内的低置信度预测框进行降低分值的策略,改善了目标遮挡时检测丢失问题;
[0029]
3、本发明为改善样本不平衡对模型影响,在类别损失函数中增加了可变调节系数,使损失下降更加平滑。
附图说明
[0030]
构成本实施例的一部分的说明书附图用来提供对本实施例的进一步理解,本实施例的示意性实施例及其说明用于解释本实施例,并不构成对本实施例的不当限定。
[0031]
图1为本发明实施例1的yolov4网络模型结构示意图;
[0032]
图2为本发明实施例1的iou交并比;
[0033]
图3为本发明实施例1的不同iou方案效果对比;
[0034]
图4为本发明实施例1的γ曲线图;
[0035]
图5为本发明实施例1的loss曲线变化;
[0036]
图6为本发明实施例1的soft-nms改善效果示意图;
[0037]
图7为本发明实施例1的部分检测效果图;
[0038]
图8为本发明实施例2的卷积过程原理图;
[0039]
图9为本发明实施例2的nms策略处理示意图。
具体实施方式:
[0040]
下面结合附图与实施例对本发明作进一步说明。
[0041]
应该指出,以下详细说明都是示例性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
[0042]
实施例1:
[0043]
行人检测是计算机视觉中的一个重要课题,行人检测在很多方面都具有很高的应用研究价值,比如辅助汽车智能驾驶,在重要场所对行人的安全监控,可以为视频中的行人行为分析,行人数量统计,行人轨迹跟踪等提供基础依据。通过实现计算机对行人的检测功能,在各种实际应用场景下,都极大提高了工作效率,降低人力成本的投入,促进了社会、经济的进步与发展。以yolo深度网络为代表的一阶段检测网络,实现了端到端的设计,通过针对特定图像数据的训练,算法在各种应用场景下都表现出良好的检测效果和鲁棒性;正如背景技术中提到的,现有的yolo深度网络在进行行人检测时,依然存在模型收敛速度较慢问题,严重影响了yolo深度网络在行人检测中的应用。
[0044]
为了解决模型收敛速度较慢问题,本实施例提供了一种基于yolov4的行人检测方法,包括:
[0045]
获取待检测的图像信息;
[0046]
依据图像信息,以及预设的行人检测网络模型,得到检测结果;
[0047]
其中,所述行人检测网络模型为训练后的yolov4网络模型;yolov4网络模型中,在边界框损失函数中添加一个指数函数作为修正系数,所述指数函数的自变量为预测框与真实框之间宽高比的绝对值之差乘上预设调节参数的积。
[0048]
随着第一代yolo算法提出,它的快速性与准确性不断受到研究者的喜爱并应用到各种检测领域,经过多年的探索,各种版本的yolo的衍生结构不断被提出,其中最经典的当属yolov3;本实施例中采用的yolov4算法,是基于yolov3基础上所做的改进,本实施例中的行人检测的算法是在yolov4算法基础上进行的方案设计。
[0049]
如图1所示,本实施例中的yolov4网络模型结构可以分为两个部分,第一部分称为backbone,主要作用是对图像进行特征提取,是网络的根基;第二部分是backbone之后的neck部分,用以其他任务,比如目标分类和语义分割等;其中,backbone部分可以采用的cspdarknet53结构,特点是由多个csp残差块结构的块组成,主要目的是解决网络退化问题;neck部分由一个spp池化模块和panet结构组成,其中spp池化模块采用了5
×
5、9
×
9、13
×
13的池化层进行特征融合,已被证实对模型精度有很好的提升作用,panet模块特点是上
下层特征连接融合,可以准确保留空间信息,帮助定位目标。yolov4网络最终有三个分支输出,分别生成为13
×
13、26
×
26、52
×
52的矩阵网格,针对大中小三种类型的目标提供不同尺寸的感受野,每个格子预测3个预测框,每个预测框包含目标置信度(cofidence),类别(class),位置(x,y,w,h)三类信息,针对本实施例中的单类行人目标,一共3
×
6=18个信息。
[0050]
获取待检测的图像信息时,可以通过相机或其他图像采集传感器实现图像信息的获取,可以理解的,获取的图像信息为静态图像、动态图像、视频信息或者在视频信息中分离出来的图像相信。
[0051]
神经网络训练采用损失函数衡量网络预测值与目标设定值之间的偏离程度,在每次迭代过程中计算损失函数值来反馈修正网络参数使其最小化。本实施例中的损失函数简要分为以下三个:
[0052][0053][0054][0055]
其中,l
box
为边界框损失,表示衡量边界框与真实框的差异;l
obj
为目标损失,表示衡量该位置是环境还是待检测目标,与设定的真实值的差异;l
cls
为类别损失,表示衡量预测类别与设定真实类别值的差异;s2代表网格数;b代表网格中预测框数:代表网格中含有目标;代表网格中没有目标;iou(a
pre
,b
gt
)代表表示ab两框的重叠度,物理意义为ab两框相交面积与相并面积的比值,计算公式为:a
pre
代表预测框;b
gt
代表真实框;表示交叉熵损失函数;表示目标类别的预测概率,在本实施例中预测目标为单类样本,范围即(0,1)之间;p(ci)表示目标的真实概率值,值为0或1,0表示目标不是行人,1表示目标为行人。边界框的损失函数由yolo算法刚提出时的平方差损失函数改为了现在基于anchor的重叠度(intersection over union,iou)交并比损失,从模型精度和收敛速度方面都有很大的提升,目标置信度与类别损失函数统一采用的交叉熵损失函数。
[0056]
bce是交叉熵损失函数,用以衡量训练过程中,预测值与期望值之间的差异,计算公式为
[0057][0058]
其中表示预测值,y表示期望值,在yolov4类别损失中,用类别概率表示,范围在(0,1)之间,y用ci表示,取值为0或1,0代表环境,1表示为有目标。
[0059]
基于anchor的重叠度(intersection over union,iou)交并比损失,对iou的解释同1,设a为预测框,那b为需要拟合的真实框,在此的预测框,不是从面积为0开始,而是从设
定的anchor为初始框;在本实施例中目标框和真实框是同一个对象,统一为真实框,即在图像数据中对行人进行标注的边界框信息,也就是标签里存储的信息,预测框是网络输出的预测的边界框信息,与真实框的数值越接近越好,评价指标即iou重合度。
[0060]
边界框修正采用了调整预设anchor拟合目标框的方法,训练前将采集的行人的宽高数据作为一堆离散数据,根据k-means算法将数据划分为多类,本实施例中为9类,得到9种尺寸的anchor,对应3个分支输出的3种预测框。算法得到的9类尺寸分别为(10
×
24)、(18
×
46)、(27
×
104)、(40
×
64)、(56
×
148)、(85
×
265)、(121
×
174)、(166
×
312)和(303
×
371)。
[0061]
如图2所示为预测框a与目标框b之间的iou交并比效果,计算方式为:
[0062][0063]
该策略的弊端是当两框距离较远时,iou为0,同时iou无法反映两框的远近程度,并造成损失梯度不变的现象。针对此问题,本实施例中,将边界框的损失可以设置为两部分,iou部分和两框距离部分,所用计算公式如下:
[0064][0065][0066]
其中,δ表示预测框与真实框之间宽高比的绝对值之差,范围内;h
pre
表示预测框的高;w
pre
表示预测框的宽;h
gt
表示真实框的高;w
gt
表示真实框的宽;l
box
表示边界框损失函数;iou(a,b)表示表示ab两框的重叠度;损失部分ρ2是预测框与目标框中心点距离平方;c2表示预测框与目标框最小包围矩阵对角线的距离平方;在其比值权重基础上增加了一个e
αδ
作为系数修正,受预设调节参数α和δ影响,当δ
→
0时,e
αδ
→
1,预设调节参数α的选取对模型收敛速度有不同程度影响,b
pre
表示预测框中心点坐标;b
gt
表示目标真实框中心点坐标,图2中左上角为坐标起始点。
[0067]
在本实施例中,预设调节参数设置为α=10,对模型收敛速度有显著提升。本实施例测试了几种不同iou方案在交叉验证集对模型ap(average precision)的变化影响,数据每迭代10次进行一次取样,如图3所示。
[0068]
关于正负样本不平衡,本实施例中,类别损失和置信度损失统一采用的bce损失函数,公式7所示:
[0069][0070]
在实际训练过程中,yolov4将图片分为n
×
n的网格,每个网格预测有无目标,由于在单张图片中行人目标的数量少,造成一种行人与背景样本空间数量不均衡的现象。在计算单张图片的类别损失中,负样本所占比重就会过大,造成过多的损失权重偏向于背景样本,由此本实施例中采用了一种类别损失函数,通过可变的调节系数γ调节负样本损失权重的比重,改变后的损失函数如下:
[0071]
[0072]
本实施例中,考虑了一种更加圆滑变化的γ系数进行损失修正,γ的变化受迭代率x影响,初始时很小,并根据迭代的进行逐渐恢复至正常状态。
[0073][0074]
引入γ系数后,损失收敛更快,曲线变化更加圆滑,如图5所示。
[0075]
非极大值抑制(non-maximum suppression,nms)算法是一种在模型对图像进行检测时常用的算法,由于深度学习网络会对输入图像中的目标产生多个预测框,nms算法会将iou重合度较高的预测框按置信度排序,删除置信度较低的预测框,最终只保留一个预测框;这种算法简单高效,但同时也有一定弊端,当两个以上目标在图像中距离较近时,应用nms算法会出现检测目标丢失的现象,造成检测精度降低。本实施例结合soft-nms算法对该问题进行改善:
[0076][0077]
面对重合度较高的预测框时,与传统nms算法直接删除低置信度预测框方法的不同,soft-nms采用了对低置信度预测框进行降低分值的策略,可以理解的,nms策略是处理多个预测框产生重叠现象的算法,普通nms的处理过程为,首先计算不同边界框之间的iou重合度,当超过一定阈值时,比如阈值为0.3,则认为预测框产生了重叠冗余,在两框之间,将目标概率值较低的框(低置信度预测框)进行删除,如图9所示;soft-nms替代nms的伪代码图如表1所示:
[0078]
表1
[0079][0080]
本实施例中通过引入soft-nms策略,在一定程度上对检测目标丢失现象有所改
善,效果如图7所示。
[0081]
本实施例中,还进行了实验结果与分析,本实施例中所用视频数据采集自木区域内多处位置,包含白天夜晚两种环境,为方便处理数据尺寸按比例统一压缩至720
×
406,训练测试所用图片按视频中每隔3帧进行取样,训练模型时为丰富数据样本引入部分精选pascal voc数据集person类图片,最终训练部分12114张图片,按9:1分为训练集和交叉验证集,测试部分共计1346张作为测试集。训练模型所用设备为i9-9900x cpu,两块rtx2080显卡,显存24g,测试所用设备为i5-9300h cpu,一块gtx1660显卡,显存6g,训练测试所用系统均为ubuntu操作系统。初次训练时以yolov4预训练权重为基础,采用了前30次迭代冻结主干网络后续再解冻的训练策略,最终保留了在交叉验证集上表现最优异的模型。在测试集上的测试结果如表2所示,可以看出yolov4的检测效果相较于传统视觉算法,无论在白天还是夜晚场景下都有更高的检测精度,检测速度也更快可以满足实时性的要求。
[0082]
表2测试结果
[0083]
模型检测精度(白天)检测精度(夜晚)fpsdpm svm80.41%72.81%11.52yolov4(our)92.18%83.46%25.18
[0084]
本实施例以yolov4算法为基础,设计了一套检测行人的设计方案,改进了训练过程中边界框的回归策略并在交叉验证集上表现了良好的效果,为改善样本不平衡对模型影响在损失函数中增加了可变γ系数,使loss下降更加平滑,检测部分引入了soft-nms算法用以改善目标遮挡时检测丢失问题。实验结果表明,以yolo算法为基础的深度学习算法在行人检测上的表现,从精度和速度以及模型的鲁棒性方面,相较于传统视觉算法都有很大提升。诚然深度学习算法在各方面表现优异,但算法也有依赖数据集、训练时间周期长等缺点。相信在未来,深度学习检测模型会朝着兼顾精度与速度的方向发展,并随着数据的丰富在各项任务上发挥越来越重要的作用。
[0085]
实施例2:
[0086]
本实施例对实施例1中的基于yolov4的行人检测方法做进一步说明,本方法采用的深度学习模型算法,依托大量的包含行人数据的图片,数据的数量越多,对模型的泛化能力、鲁棒性提升越好;可以根据实际应用环境采集不同时段的视频,每隔3帧对视频进行抽帧提取图片,对图像中的行人进行人工标注保存为标签;个人数据量不多的情况,也可以增加使用一些公开的数据集,本实施例中在实验时也增添了pascal voc的person类数据样本。标签如下所示:
[0087]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2011_005699.jpg 61,49,372,377,0
[0088]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2008_000403.jpg 180,183,228,265,0
[0089]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2012_001231.jpg 10,87,277,500,0
[0090]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2011_001227.jpg 134,165,194,209,0
[0091]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/
2010_000510.jpg 124,103,252,333,0
[0092]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2008_001709.jpg 174,42,393,313,0
[0093]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2008_001652.jpg 222,217,335,478,0 287,132,335,224,0 1,187,169,405,0 1,110,149,306,0
[0094]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2007_007203.jpg 308,132,429,299,0
[0095]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2010_001645.jpg 84,135,117,197,0 104,87,160,249,0 145,72,213,219,0 205,70,276,216,0 243,115,336,299,0 215,119,374,332,0 361,160,478,332,0 414,126,490,242,0
[0096]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2010_000561.jpg
[0097]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2011_003128.jpg 167,115,331,319,0
[0098]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2012_001098.jpg 253,57,364,245,0
[0099]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2011003758.jpg 171,31,500,375,0
[0100]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2012_002372.jpg 92,22,280,287,0
[0101]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2012_002144.jpg 374,117,460,236,0
[0102]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2011_000435.jpg 199,65,280,279,0 114,24,199,254,0
[0103]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2008_006491.jpg 150,99,240,276,0
[0104]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2008_004966.jpg 1,1,157,292,0
[0105]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2008_004342.jpg 98,76,242,421,0
[0106]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2012_003752.jpg 100,118,480,360,0
[0107]
/home/yh/pycharmprojects/person_detect(yh)/person_data/jpegimages/2008_003493.jpg 272,28,407,360,0 153,36,272,358,0 104,62,173,354,0 1,148,80,321,0
[0108]
以第一行举例,第一行左边数据代表文件所在位置及名称,读取图片后会获得图片的像素尺寸,500
×
377,右边数据61,49,372,377代表目标所在图像位置,以图像左上角
为起始点坐标,往右为x轴,往下为y轴。(61,49)为目标左上角所在位置,(372,377)为目标右下角位置,通过两点可以确定目标所占图像位置0代表类别,本实施例中,只检测一类:行人,也就是0。在其他实施例中,还可以检测不同种类的人,要按不同数字顺序划分,a类人:0,b类人:1,c类人:2等。
[0109]
本实施例中,在yolov4网络结构的基础上,输入为(416,416,3)尺寸的图片,宽和高各为416,可用线性插值的方法改变图片尺寸,方法很多,统一成416,通道是rgb3通道,紧跟着经过一个卷积层,对图像通道升维到32通道,宽高尺寸不变。
[0110]
如图8所示,卷积就是将一个k
×
k(k=3)尺寸的矩阵(卷积核)在一个n
×
n(n=5)的输入矩阵上以步长s(s=1)进行从左到右从上到下进行遍历,遍历过程中将对应位置的数进行乘积,最后求和,变成卷积后对应位置的数值。如果输入矩阵通道为3维,卷积核的通道也要为3维相对应,卷积后的矩阵为单通道,为了卷积后产生32通道的矩阵,就需要32个不同的卷积核。在本网络结构中采用的卷积核尺寸为1
×
1,3
×
3两种:1
×
1卷积不改变输入宽高尺寸,可以用来给通道降维,增加非线性等方面作用;而3
×
3卷积会改变输入宽高尺寸,为了维持输入与输出宽高不变,需要对输入矩阵周围填充0元素,预先增大输入尺寸。
[0111]
网络结构中,经过5个csp block结构的模块,首先第一层为一个下采样卷积:卷积核尺寸k=3,步长s=2,输出宽高为输入宽高的一半,通道是输入的两倍卷积层后跟一个bn(batch normalization)层,这一层作用是标准化,由于我们训练模型时候会同时训练多张图片,以一个batch为单位,batch包含数据大于1需要进行bn操作,对batch中所有数据求得均值和方差,将每个batch中的数进行先减均值再除标准差的操作,用计算机计算时为防止分母为0,可以将标准差σ用(ε为极小数)代替。
[0112]
bn层后跟mish激活函数,对每个数字进行mish运算增加非线性。公式为f(x)=x*tanh(ln(1 e^x))。
[0113]
下采样后分别经两次相同的1
×
1卷积层操作,维持通道不变,分别输出矩阵a1和a2;其中,a1不处理,a2经过残差网处理,残差网结构即对输入x变为x f(x)操作,f(x)即对输入x进行两次卷积,第一次1
×
1,通道减倍,第二次3
×
3,维持宽高不变,通道扩大两倍,两次卷积后整体维度与x相同,所以再进行一次相加运算。在网络结构图中,每个block块后面的数字表示这个块中有几个残差网相连,操作方法一致。
[0114]
处理完之后a1与a2进行以通道为轴进行拼接操作,矩阵通道扩大两倍,再进行一次1
×
1卷积操作,通道减半,作为这个模块的输出。
[0115]
输入图片经过第一个卷积层变为(416,416,32)尺寸的矩阵,后面紧跟5个csp模块,经过第一个模块,变为(208,208,64)尺寸,经过第二个模块,变为(104,104,128)尺寸,经过第三个模块,变为(52,52,256)尺寸,经过第四个模块,变为(26,26,512)尺寸,经过第五个模块,变为(13,13,1024)尺寸。
[0116]
第五个模块输出的(13,13,1024)矩阵,首先经过一个3次卷积,分别为1
×
1卷积,通道减半,3
×
3卷积,通道翻倍,1
×
1卷积,通道减半,此时通道为512。
[0117]
再经过一个spp池化模块,分别经过三个池化层,这里介绍一下池化:池化跟卷积一样在输入矩阵上进行遍历,以图为例,池化核大小为2
×
2,输入矩阵为4
×
4,步长为2,最大池化(平均池化是取平均值)是将遍历矩阵中最大元素提取当做输出,池化作用是对特征图进行压缩,减少数据处理量简化网络计算量的同时保留有用信息。
[0118]
spp中采用的最大池化,三个池化层分别池化核为5
×
5、9
×
9和13
×
13,步长为1。为了保持宽高不变,同样采用了0填充的方法。三个池化层的输出与spp前的输入进行拼接,通道为2048,作用是通过多特征融合的方法来丰富特征图的表达能力,提高检测精度。
[0119]
再经由三次卷积,分别为1
×
1,通道降为512,再3
×
3卷积,通道升高至1024,再1
×
1卷积,通道降为512;无特殊说明时,宽高都保持不变,只改变通道。
[0120]
来到panet部分,从spp出来的特征矩阵,记为p3,由上采样(先1
×
1卷积,通道减半降为256,再通过最近邻插值法将矩阵宽高放大两倍)操作,记为p3_up,第四个模块输出的(26,26,512)矩阵通过1
×
1卷积降为(26,26,256)尺寸,记为p2,此时p3_up、p2两者尺寸一致,进行拼接,通道为512,再经由5次卷积(1
×
1,通道减半,3
×
3,通道翻倍,1
×
1,通道减半,3
×
3,通道翻倍,1
×
1,通道减半),通道为256,覆盖为p2,p2上采样操作,尺寸为(52,52,128),记为p2_up,第三个模块输出的(52,52,256)矩阵,1
×
1卷积通道降为128,记为p1,此时p1与p2_up尺寸一致,进行拼接,通道为256,经由5次卷积(1
×
1,通道减半,3
×
3,通道翻倍,1
×
1,通道减半,3
×
3,通道翻倍,1
×
1,通道减半),通道为128,覆盖为p1,p1经一个下采样(3
×
3卷积,步长为2,宽高减半,通道翻倍),尺寸为(26,26,256),记为p1_d,此时p1_d与p2尺寸一致,进行拼接,经由5次卷积(1
×
1,通道减半,3
×
3,通道翻倍,1
×
1,通道减半,3
×
3,通道翻倍,1
×
1,通道减半),通道为256,覆盖为新的p2,p2下采样(3
×
3卷积,步长为2,宽高减半,通道翻倍),尺寸为(13,13,512),记为p2_d,此时p2_d和p3尺寸一致,进行拼接,经由5次卷积(1
×
1,通道减半,3
×
3,通道翻倍,1
×
1,通道减半,3
×
3,通道翻倍,1
×
1,通道减半),通道为512,覆盖为新的p3。
[0121]
此刻,从panet出来,得到了特征矩阵p1,尺寸为(52,52,128);特征矩阵p2,尺寸为(26,26,256);特征矩阵p3,尺寸为(13,13,512)。再分别经由两次卷积(3
×
3卷积,通道翻倍,1
×
1卷积,通道为18)得到最终整个网络输出,自上而下分别是(52,52,18),(26,26,18),(13,13,18)。这样一个从输入到输出的端到端网络,相当于把输入图片416
×
416的尺寸分割为52
×
52,26
×
26,13
×
13结构,这样做是为了不同结构预测不同尺寸的目标。
[0122]
18通道可以理解为每个小格子有18个信息,每个小格子负责预测3个目标框,每个目标框包含6个信息,分别为目标框位置与宽高(x、y、w和h)以及存在目标概率(0~1),是否为行人(0或1)。所以3*6为18个信息。
[0123]
针对不同的图像,需要将第一部分中目标在图像中信息转化为对应网络输出的格式。通过对网络的训练,计算网络输出与真实值之间的差异,反向修改卷积核的数值,不断的优化,最终达到能够针对新的待检测图片,通过网络计算得到是否包含行人的检测效果。
[0124]
将数据集信息转化为网络输出格式方式如下:
[0125]
首先将图片的目标位置信息由相较于图像左上角位置xy转化为目标中心的位置,x w/2
→
x,y h/2
→
y。将数据集所用的图片中所有目标宽高数据看作一堆离散点,通过k-means算法按从小到大分为(3组,每组3类)=9类的宽高尺寸,也就是9种anchor。之后将每张图片的目标宽高信息先与anchor进行对比,通过iou比较法,找到最匹配的anchor,举例,如果是第一组第二类anchor最匹配,因为是第一组,那就由52
×
52
×
18的分支来预测此目标(第二组由26尺寸的预测,第三组由13尺寸的预测,现在解释了三个分支分别预测不同尺寸的目标),目标xy信息对应在图像整体的百分比位置,转化到52
×
52矩阵网格中,对应到哪一格就由哪一格来预测,因为是第一组第二类anchor最匹配,就由第二个预测框来预测
(因为每个格子预测三个预测框),这个格子的18个真实值信息即为[0,0,0,0,0,0,x,y,w,h,1,1,0,0,0,0,0,0]。其中x、y、w和h是图像的中心位置、宽高位置宽高信息,1为有目标,1为是行人。
[0126]
为了使网络能达到我们希望的输出,训练过程中,需要对网络输出值与我们设定的目标值进行损失计算,即判断二者差异来反馈修正网络。损失函数分为三部分,一是边界框损失,二是目标置信度损失,三是类别损失。
[0127]
目标框损失,网络并不是直接预测目标框xywh信息,而是调整对应输出的anchor来拟合目标框信息:
[0128]bx
=σ(t
x
) c
x
[0129]by
=σ(ty) cy[0130][0131][0132]
其中,t
x
、ty、tw和th表示网络实际输出值;c
x
和cy表示所在网格相较左上角位置;σ表示sigmoid函数,作用主要是把数据转化到0-1之间;pw和ph为对应anchor的宽高,如果是52
×
52的分支,即用第一组的anchor来预测目标边界框信息,其他分支同理。
[0133]
通过公式计算得到b
x
、by、bw和bh即为真正预测得到的目标边界框信息,与真实目标框的损失函数采用的是iou损失,公式为:
[0134][0135]
其中,iou为预测框a与真实框b的重合度,在0-1之间;ρ2(b,b
gt
)表示两个框中心点的距离平方;c2为两框最小包围框的对角线距离平方;实验发现α取10对模型收敛效果最高;为两框高度与宽高相加比值的绝对值差。
[0136]
当两框iou重合度越高,距离越近,宽高比越接近,边界框损失就越小。
[0137]
有无目标损失,每个分支中每个格子都会预测有无目标信息,只有目标中心点落到这个格子时才会有边界框的信息和类别信息,所以这一步的损失很重要。公式如下:
[0138][0139][0140][0141]
其中,s2为网格数(s=52,26,13);b为预测框数(b=3);为网格中有目标;此时ci=1,为无目标,此时ci=0;γ是为了平衡正负样本,因为拿52
×
52分支举例,当
一张图中只有几个行人目标时,部分的loss值会明显小于部分的loss,不平衡性会影响模型的收敛速度与效果,加入受迭代率(从0到1,迭代100次的话,每次增加0.01)变化影响的权重参数γ影响,有一定程度上的改善效果。
[0142]
类别损失为:
[0143][0144]
有行人的格子目标类别概率为1。
[0145]
在每次迭代训练中,图片输入网络计算得到输出值,与目标值计算三类损失函数,求和计算总loss值,通过adam优化器反馈网络修改卷积核参数,从而不断优化网络模型。
[0146]
训练过程为:数据集按8:1:1随机分为训练集、交叉验证集、测试集,其中训练集用来训练模型,每次训练结束后用交叉验证集比较每次模型的好坏,最终选出在交叉验证集表现最好的训练模型,最终拿到测试集上测试模型观察模型效果。
[0147]
初始模型的卷积核参数可以使用yolov4官方提供的预训练权重,可以节省很多训练时间
[0148]
在使用预训练模型的基础上,训练过程中,前30%次训练迭代可以冻结backbone的卷积核权重,只训练neck部分的卷积核权重,之后再解冻,训练整个网络。
[0149]
每个人训练所用设备不同,可以根据电脑内存和显存来分配batch大小,训练学习率以0.001~0.0001之间。
[0150]
检测行人,模型训练完毕后,加载训练好的模型权重,可以针对用以图片、视频流的图像检测。具体的,输入网络的视频帧,会输出得到52
×
52
×
18、26
×
26
×
18、13
×
13
×
18的矩阵,将网格中的18通道信息中,以阈值0.5为界限筛选有目标的网格,以阈值0.5为界限筛选包含行人的网格,再通过soft-nms方法将边界框iou重合度较高的网格中给行人置信度进行降低,最终筛掉行人置信度过低的边界框。
[0151]
最终保留下的信息,解码转到原始图片中,用矩形框将检测到的行人进行描绘显示。
[0152]
实施例3:
[0153]
本实施例提供了一种基于yolov4的行人检测系统,包括:
[0154]
数据采集模块,被配置为:获取待检测的图像信息;
[0155]
检测模块,被配置为:依据图像信息,以及预设的行人检测网络模型,得到检测结果;
[0156]
其中,所述行人检测网络模型为训练后的yolov4网络模型;yolov4网络模型中,在边界框损失函数中添加一个指数函数作为修正系数,所述指数函数的自变量为预测框与真实框之间宽高比的绝对值之差乘上预设调节参数的积。
[0157]
所述系统的工作方法与实施例1的基于yolov4的行人检测方法相同,这里不再赘述。
[0158]
实施例4:
[0159]
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处
理器执行时实现了实施例1所述的基于yolov4的行人检测方法的步骤。
[0160]
实施例5:
[0161]
本实施例提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现了实施例1所述的基于yolov4的行人检测方法的步骤。
[0162]
以上所述仅为本实施例的优选实施例而已,并不用于限制本实施例,对于本领域的技术人员来说,本实施例可以有各种更改和变化。凡在本实施例的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本实施例的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。