1.本发明涉及智能交通技术领域,特别是涉及一种用于交通流预测的双模式图卷积循环神经网络。
背景技术:
2.在智慧城市的建设过程中,交通拥堵是当前各国城市面临的巨大挑战之一。交通流量情况的预测对新时代智慧城市的交通管理来说具有重要的意义。然而,目前交通流的预测越来越具有挑战性。首先,交通流从时间的纬度上来说是具有极强的不确定性和不稳定性,例如在一个小时内的的出行变化,这是无法确定的,要是在交通事故、特殊事件等突发事件的情况下,将有更多的未知,不确定性;但在特定的时间范围内也具有周期性的规律,例如每天上下班的出行轨迹、每个节假日商圈景区的出行量,所以预测模型很难快速适应交通流飞速变化的情况。其次,在空间维度上道路与车辆、行人行为的复杂关系等也对交通流的预测产生了关键性的影响,例如在一条道路上发生的交通事故所引起的大堵车,随着时间的推移,交通流也在逐渐的降低。此外道路交叉、车道的复杂性也会影响预测交通流的去向。
3.尽管现在已有很多预测未来交通流量的杰出网络模型,但大多数模型在序列相关性、时间相关性以及空间相关性存在一定的局限性。因此亟需一种网络模型,可以同时捕获到序列特征相关性、时间相关性和空间相关性进而准确实现交通流预测。
技术实现要素:
4.针对以上技术问题,本发明提供一种用于交通流预测的双模式图卷积循环神经网络。
5.本发明解决其技术问题采用的技术方案是:
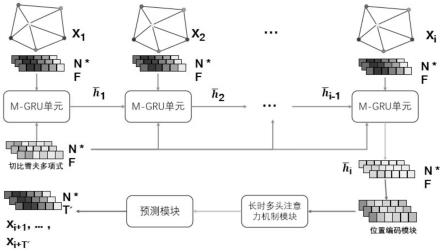
6.一种用于交通流预测的双模式图卷积循环神经网络,包括m-gru模块、位置编码模块、长时多头注意力机制模块和预测模块,m-gru模块包括若干个串联的m-gru单元,最后一个m-gru单元连接位置编码模块,位置编码模块连接长时多头注意力机制模块,长时多头注意力机制模块连接预测模块;
7.获取交通网络中每个节点记录的一时间段内所有时刻的交通流序列特征,将对应时刻的交通流特征序列值xi和切比雪夫多项式依次输入至对应的m-gru单元得到最后一个m-gru单元输出的结果x,位置编码模块用于对x进行正余弦位置编码得到编码后的x;长时多头注意力机制模块用于根据接收的编码后的x得到长时多头注意力机制模块的结果;预测模块用于根据接收的长时多头注意力机制模块的结果和预设的损失函数得到损失值,根据损失值进行反向传播并更新网络的网络参数,记录迭代次数,直至迭代次数达到预设的要求,得到训练好的双模式图卷积循环神经网络。
8.优选地,m-gru单元包括m-reset模块和m-update模块,m-reset模块包括cdsg模块、序列特征多头注意力模块、拼接模块和残差融合模块,cdsg模块和序列特征多头注意力
模块分别连接拼接模块,拼接模块连接残差融合模块;
9.将xi和切比雪夫多项式输入到cdsg模块,将xi输入到序列特征多头注意力模块,得到第一结果和第二结果,拼接模块将第一结果和第二结果拼装组装得到拼接结果,残差融合模块将拼接结果与xi进行残差融合,最后将残差融合的结果输出。
10.优选地,cdsg模块包括动态学习与特定节点的图卷积模块、空间多头注意力模块、切比雪夫图卷积模块和空间融合模块,动态学习与特定节点的图卷积模块连接空间融合模块,空间多头注意力模块连接切比雪夫图卷积模块,切比雪夫图卷积模块连接空间融合模块;
11.将xi和切比雪夫多项式输入到动态学习与特定节点的图卷积模块进行图卷积得到第一图卷积结果,将xi输入到空间多头注意力模块得到空间注意力模块的结果,切比雪夫图卷积模块对空间注意力模块的结果进行图卷积得到第二图卷积结果,融合模块将第一图卷积结果和第二图卷积结果进行融合得到第一结果并输出。
12.优选地,将xi输入到空间多头注意力模块得到空间注意力模块的结果,具体为:
[0013][0014]
attention=[a'
·
v:xi]
[0015][0016][0017]
其中,为模型可学习参数,表示空间注意力模块的结果,果,表示缩放因子,表示缩放点积注意力机制计算的结果,c表示节点的序号,c表示节点总数,b为批次大小,n为节点个数,f为特征通道,表示实数集。
[0018]
优选地,切比雪夫图卷积模块对空间注意力模块的结果进行图卷积得到第二图卷积结果,具体为:
[0019][0020]
其中,*g表示一个图的卷积运算,
⊙
表示哈达玛积,θ'∈rk是切比雪夫系数的向量,表示空间注意力模块的结果,l为拉普拉斯矩阵,in表示单位矩阵,λ
max
是l的最大特征值,ti为切比雪夫多项式,而ti(xi)=2xit
i-1
(xi)-t
i-2
(xi),其中,t0(x)=1,t1(x)=x,表示第二图卷积结果。
[0021]
优选地,空间融合模块将第一图卷积结果和第二图卷积结果进行融合得到第一结果并输出,具体为:
[0022]
x
bd
=xbconv xdconv
[0023]
其中,表示第一结果,表示第一图卷积结果,表示第二图卷积结果。
[0024]
优选地,将xi输入到序列特征多头注意力模块,得到第二结果,具体为:
[0025][0026][0027]
attention=[a'
·
v:xi]
[0028][0029][0030]
其中,relu为激活函数,为模型可学习参数,表示第二结果,attentionf表示序列特征多头注意力模块的结果,表示序列特征多头注意力模块的结果,表示缩放因子,表示缩放点积注意力机制计算的结果,c表示节点的序号,c表示节点总数。
[0031]
优选地,拼接模块将第一结果和第二结果拼装组装得到拼接结果,残差融合模块将拼接结果与xi进行残差融合,最后将残差融合的结果输出,具体为:
[0032]
x
bdf
=[xf:x
bd
]
[0033]
x=x
bdf
xc[0034]
其中,表示拼接结果,表示第二结果,表示第一结果,xc是将序列特征进行普通卷积操作后的结果,x表示残差融合的结果,其中relu为激活函数。
[0035]
优选地,长时多头注意力机制模块用于根据接收的编码后的x得到长时多头注意力机制模块的结果,具体为:
[0036]
x
l
=(x attention
l
) relu(x attention
l
)
[0037][0038]
attention=[a'
·
v:x]
[0039]
[0040][0041]
其中,,其中relu为激活函数,为模型可学习参数,表示长时多头注意力模块的结果,attention
l
表示初始长时多头注意力模块的结果,表示初始长时多头注意力模块的结果,表示缩放因子,x为编码后的x,t为总步长。
[0042]
优选地,预设的损失函数具体为:
[0043][0044]
其中,y'是真实值,yi为时间步长i时所有节点的预测值。
[0045]
上述一种用于交通流预测的双模式图卷积循环神经网络,从三个角度分别出发设计,分别解决序列特征相关性、时间相关性和空间相关性的问题,可以同时捕获到序列特征相关性、时间相关性和空间相关性进而准确实现交通流预测。
附图说明
[0046]
图1为本发明一实施例提供的一种用于交通流预测的双模式图卷积循环神经网络的网络结构图;
[0047]
图2为本发明一实施例中m-gru模块的框架图;
[0048]
图3为本发明一实施例中m-reset模块的框架图;
[0049]
图4为本发明一实施例中cdsg模块的框架图。
具体实施方式
[0050]
为了使本技术领域的人员更好地理解本发明的技术方案,下面结合附图对本发明作进一步的详细说明。
[0051]
在一个实施例中,如图1所示,一种用于交通流预测的双模式图卷积循环神经网络,包括m-gru模块、位置编码模块、长时多头注意力机制模块和预测模块,m-gru模块包括若干个串联的m-gru单元,最后一个m-gru单元连接位置编码模块,位置编码模块连接长时多头注意力机制模块,长时多头注意力机制模块连接预测模块;获取交通网络中每个节点记录的一时间段内所有时刻的交通流序列特征,将对应时刻的交通流特征序列值xi和切比雪夫多项式依次输入至对应的m-gru单元得到最后一个m-gru单元输出的结果x,位置编码模块用于对x进行正余弦位置编码得到编码后的x;长时多头注意力机制模块用于根据接收的编码后的x得到长时多头注意力机制模块的结果;预测模块用于根据接收的长时多头注意力机制模块的结果和预设的损失函数得到损失值,根据损失值进行反向传播并更新网络的网络参数,记录迭代次数,直至迭代次数达到预设的要求,得到训练好的双模式图卷积循环神经网络。
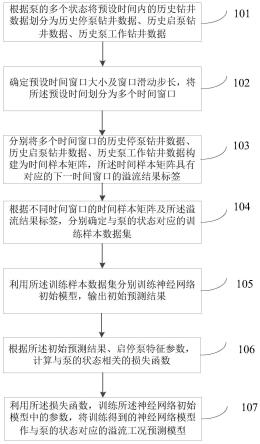
[0052]
具体地,多头注意力机制是transformer模型最突出的贡献,也是其核心重要组成部件。多头注意力机制模型是分为多个头,形成多个子空间,可以让模型去关注不同方面的
信息,其实质就是将scaleddot-productattention(缩放点积注意力机制)过程即做p次,再把输出合并起来。
[0053]
scaleddot-productattention的表达式如下:
[0054][0055]
其中表示缩放因子,当dk很小时,dot-productattention(点积注意力机制)的效果不明显,但当dk很大时,点乘的值就很大,会使得softmax函数之后的梯度变小,不利于反向传播,如果不做scaling(缩放),效果就不是很好。
[0056]
而muti-headattention(多头注意力)的表达式如下:
[0057]
qi=qw
iq
,ki=kw
ik
,vi=vw
iv
,i=1,...,p
[0058]
headi=attention(qi,ki,vi),i=1,...,p
[0059]
mutihead(q,k,v)=concact(head1,...,head
p
)wo[0060]
gru(gate recurrentunit)是循环神经网络(recurrentneuralnetwork,rnn)的一种,和lstm(long-short term memory)同类型模型,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的模型。gru的输入输出结构与普通的rnn相同,输入结构包含一个当前输入x
t
,和上一个节点传递下来的隐藏状态h
t-1
;结合两个输入信息,gru会得到当前隐藏节点的输出和传递给下一个节点的隐藏状态h
t
,其主要表达式如下:
[0061]zt
=σ(wz·
[h
t-1
,x
t
])
[0062]rt
=σ(wr·
[h
t-1
,x
t
])
[0063][0064][0065]
传统的卷积可以有效地提取标准的网格数据中的局部特征信息,但对非网格数据则没有很好的效果,为此近年来出现了用图卷积来处理数据,而图卷积主要分为空间方法和谱方法。
[0066]
受建设智慧城市的启发,本发明提出了一种用于交通流预测的双模式图卷积循环神经网络,该模型从三个角度分别出发设计,一是提出了特征多头注意力机制的方案用以捕获同一传感器采集到的序列特征相关性,二是提出了修改循环神经网络(m-gru)和长时多头注意力机制的方案分别从局部和全局捕获时间相关性,三是提出了动静结合图卷积(convolution ofdynamic and static graphs,cdsg)模块,用以预定义图形和动态学习特定与节点两种模式进行图卷积的方法捕获空间相关性,分别解决序列特征相关性、时间相关性和空间相关性的问题,从多个角度出发,解决各自对应问题,将其各自的计算结果融合到一起,同时捕获到序列特征相关性、时间相关性和空间相关性进而准确实现交通流预测。
[0067]
在一个实施例中,m-gru单元包括m-reset模块和m-update模块,m-reset模块包括cdsg模块、序列特征多头注意力模块、拼接模块和残差融合模块,cdsg模块和feature multi-head attention模块分别连接拼接模块,拼接模块连接残差融合模块;
[0068]
将xi和切比雪夫多项式输入到cdsg模块,将xi输入到序列特征多头注意力模块,得到第一结果和第二结果,拼接模块将第一结果和第二结果拼装组装得到拼接结果,残差融
合模块将拼接结果与xi进行残差融合,最后将残差融合的结果输出。
[0069]
具体地,m-gru(modified gate recurrent unit)模块的框架如图2所示,本发明对原始gru的主体框架结构进行了保留,利用传统gru的记忆传递特性来完成对交通流局部时间相关性的捕获,只对mlp层的更新门和重置门进行了调整,通过使用m-reset和m-update分别替换原始gru的更新门与重置门。具体公式表达如下:
[0070][0071][0072][0073]
其中,是上一个m-gru单元输出的隐藏状态,x
t
和h
t
分别是在时间t步长时的输入和输出值,[
·
]表示变量拼接操作,z
t
和r
t
都是重置门的输出值,同时r
t
也是更新门的输入值。
[0074]
具体地,m-reset(modified reset gate)与m-update(modified update gate)的框架结构相同,其主要结构是由本发明提出的cdsg模块和提出利用特征多头注意力机制的方案两部分组成,如图3所示。该模块主要负责进行空间相关性和序列特征相关性的处理,其主要工作原理如下:将xi和切比雪夫多项式输入到cdsg模块,将xi输入到序列特征多头注意力模块,然后将其二者的结果进行拼接组装,最后将拼接结果与原xi进行残差融合,最后将残差融合的结果输出。
[0075]
在一个实施例中,cdsg模块包括动态学习与特定节点的图卷积模块、空间多头注意力模块、切比雪夫图卷积模块和空间融合模块,动态学习与特定节点的图卷积模块连接空间融合模块,空间多头注意力模块连接切比雪夫图卷积模块,切比雪夫图卷积模块连接空间融合模块;
[0076]
将xi和切比雪夫多项式输入到动态学习与特定节点的图卷积模块进行图卷积得到第一图卷积结果,将xi输入到空间多头注意力模块得到空间注意力模块的结果,切比雪夫图卷积模块对空间注意力模块的结果进行图卷积得到第二图卷积结果,融合模块将第一图卷积结果和第二图卷积结果进行融合得到第一结果并输出。
[0077]
具体地,本发明提出的cdsg模块主要结构是由切比雪夫图卷积、动态学习与特定节点的图卷积和空间多头注意力三个主要部分组成,如图4所示。cdsg的工作原理是通过将xi分别输入到以动态学习特定与节点的模式、空间多头注意力和序列特征多头注意力,其中,动态学习特定与节点的模式(即动态学习与特定节点的图卷积)是进行图卷积,而空间多头注意力产生的结果输入以预定义的图形转化为切比雪夫多项式的模式(即切比雪夫图卷积)进行图卷积,之后将两个图卷积的结果进行融合输出,三个主要部分共同协作从而实现空间相关性的捕获和处理。
[0078]
在一个实施例中,将xi输入到空间多头注意力模块得到空间注意力模块的结果,具体为:
[0079][0080]
attention=[a'
·
v:xi]
[0081][0082][0083]
其中,为模型可学习参数,表示空间注意力模块的结果,果,表示缩放因子,表示缩放点积注意力机制计算的结果,c表示节点的序号,c表示节点总数,b为批次大小,n为节点个数,f为特征通道,表示实数集。
[0084]
具体地,在空间纬度上,同一个交通网络里的不同地点的交通状况相互依存,相互影响,因此我们采用空间多头注意力机制去捕获其空间相关性,序列特征输入该注意力机制,设主要计算过程如下表达式:
[0085][0086][0087]
其中,为缩放因子,表示scaled dot-product attention计算的结果。
[0088]
attention=[a'
·
v:x]
[0089][0090]
其中,为模型可学习参数,表示最后步骤归一化处理后的结果,即空间注意力模块的结果。
[0091]
在一个实施例中,切比雪夫图卷积模块对空间注意力模块的结果进行图卷积得到第二图卷积结果,具体为:
[0092][0093]
其中,*g表示一个图的卷积运算,
⊙
表示哈达玛积,θ'∈rk是切比雪夫系数的向量,表示空间注意力模块的结果,l为拉普拉斯矩阵,in表示单位矩阵,λ
max
是l的最大特征值,ti为切比雪夫多项式,而ti(xi)=2xit
i-1
(xi)-t
i-2
(xi),其中,t0(x)=1,t1(x)=x,表示第二图卷积结果。
[0094]
具体地,切比雪夫图卷积即基于谱方法,图拉普拉斯l=d-a,其中d表示顶点的度
矩阵,进一步地,拉普拉斯矩阵可以归一化为in表示单位矩阵。拉普拉斯矩阵的特征值分解可以得到其特征向量矩阵u和特征值矩阵a,拉普拉斯矩阵可以表示为l=u∧u
t
,其中∧∈rn×n表示一个对角矩阵,u∈rn×n表示傅里叶基础。而图卷积过滤器g
θ
=diag(θ)是由θ=rn参数化,因此x的图卷积定义在傅里叶域中:
[0095]gθ
*gx=ug
θut
x
[0096]
其中,*g表示一个图的卷积运算,u
t
x表示x的图傅里叶变换。
[0097]
当图的结构非常复杂时,用式g
θ
*gx=ug
θut
x计算l的特征向量矩阵所需要的计算资源消耗和时间都较大,为此有学者使用切比雪夫(chebyshev)多项式逼近来优化了该方法,式g
θ
*gx=ug
θut
x可以进一步定义为:
[0098][0099]
其中,θ'∈rk是切比雪夫系数的向量,λ
max
是l的最大特征值,而ti(x)=2xt
i-1
(x)-t
i-2
(x),其中t0(x)=1,t1(x)=x。
[0100]
为了动态调整节点之间的相关性,对于切比雪夫多项式的每个项,我们将空间注意力矩阵结果与一起使用,即其中
⊙
是hadamard product。因此本发明的图卷积将变为:
[0101][0102]
将前面计算得到的空间注意力结果attentions输入进切比雪夫图卷积,得到第一图卷积结果
[0103]
进一步地,这里的动态学习与特定节点的图卷积是指动态学习特定与节点模式的图卷积,本文中指出预定义的图不能包含关于空间依赖性的完整信息,并且与预测任务没有直接关系,可能导致相当大的偏差,所以设计了dagg(data adaptive graph generation),该处本发明将序列特征输入dagg得到第二图卷积结果
[0104]
在一个实施例中,空间融合模块将第一图卷积结果和第二图卷积结果进行融合得到融合结果并输出,具体为:
[0105]
x
bd
=xbconv xdconv
[0106]
其中,表示第一结果,表示第一图卷积结果,表示第二图卷积结果。
[0107]
在一个实施例中,将xi输入到序列特征多头注意力模块,得到第二结果,具体为:
[0108]
[0109][0110]
attention=[a'
·
v:xi]
[0111][0112][0113]
其中,relu为激活函数,为模型可学习参数,表示第二结果,attentionf表示序列特征多头注意力模块的结果,表示序列特征多头注意力模块的结果,表示缩放因子,表示缩放点积注意力机制计算的结果,c表示节点的序号,c表示节点总数;
[0114]
具体地,序列特征多头注意力是指使用多头注意力去捕获序列特征。
[0115]
在一个实施例中,拼接模块将第一结果和第二结果拼装组装得到拼接结果,残差融合模块将拼接结果与xi进行残差融合,最后将残差融合的结果输出,具体为:
[0116]
x
bdf
=[xf:x
bd
]
[0117]
x=x
bdf
xc[0118]
其中,表示拼接结果,表示第二结果,表示第一结果,xc是将序列特征进行普通卷积操作后的结果,x表示残差融合的结果,其中relu为激活函数。
[0119]
具体地,门控融合处的操作则是将feature和xbdconv进行拼接成一个多维矩阵,最后进行残差操作。
[0120]
在一个实施例中,长时多头注意力机制模块用于根据接收的编码后的x得到长时多头注意力机制模块的结果,具体为:
[0121]
x
l
=(x attention
l
) relu(x attention
l
)
[0122][0123]
attention=[a'
·
v:x]
[0124][0125][0126]
其中,relu为激活函数,为模型可学习参数,表示长时多头
注意力模块的结果,注意力模块的结果,表示缩放因子,x为编码后的x。
[0127]
具体地,在m-gru处理过后输出的结果首先进行常规处理操作,即position encoding(位置编码)具体过程如下:
[0128]
x=xi e
t
[0129]
其中e
t
表示正余弦编码,i对应的是10维position的不同维度的数,d代表的是position编码维度,model表示d的维度数,待有了结果之后继续送入长时多头注意力从全局进行捕获其时间相关性。此处的多头注意力框架也是和前面的大体一致,但还是会有不同的地方,只是这里的最后得到的结果就为长时多头注意力模块的输出结果。
[0130]
在一个实施例中,预设的损失函数具体为:
[0131][0132]
其中,y'是真实值,yi为时间步长i时所有节点的预测值。
[0133]
具体地,为了实现多步流量预测,本发明将单层ad-stgcrn网络作为编码器,用以捕获序列特征中潜藏的各种相关性,并将输入(即历史数据)通过应用线性变换来投影表示,从而直接获得所有节点的下一个t
p
步的流量预测。
[0134]
本发明选择l1损失作为我们的训练目标,并优化损失进行多步预测。
[0135]
本发明在2个真实流量数据集上验证了ad-stgcrn的效果,即pemsd04和pemsd08,这两个数据集是由caltrans性能测量系统(pemsd)每30秒实时采集一次,采集到的交通数据被聚合成了5分钟间隔的数据形式,那么一天的交通流量就表示为288个时间步长。该系统在加州主要大都市地区的告诉公路上部署了超过39000个探测器,这些探测器的地理信息也记录在了数据集中。原数据集中包含了三种交通测量值,分别为交通流量、平均速度和平均占用率。此外,pemsd04采集的是在2018年1月1日至2018年2月28日期间选择的307个环路检测器,pemsd08采集的是从2016年7月1日至2016年8月31日从圣贝纳迪诺地区的170个环路检测器收集的交通流量信息。
[0136]
对于多步流量预测,我们使用一小时的历史数据来预测下一小时的数据,即将12步的历史数据作为输入,将后面12步的数据作为输出。本发明将数据集拆分为训练集、验证集和测试集,其拆分比都为6:2:2。
[0137]
采用均方根误差root mean square error(rmse)、平均绝对误差mean absolute errors(mae)和平均绝对误差百分比错误absolute percentage errors(mape)三个指标用于评估网络模型的性能。其公式分别如下所示,其中y'是真实值,yi为时间步长i时所有节点的预测值。
[0138]
[0139][0140][0141]
本发明提出了一种新的基于注意力的双模式图卷积循环神经网络来用于交通流预测。其中本发明提出了m-gru模块,用于利用传统gru的记忆传递的特性来捕获交通流的局部时间相关性,该模块是在传统gru的基础上对其更新门和重置门进行了调整,从而形成了m-update/m-reset模块,该模块主要是用于对交通流的空间相关性和序列特性相关性的捕获,其主要结构是由两个部分组成,一是本发明提出的动静结合图卷积(convolution of dynamic and static graphs,cdsg)模块,用于以预定义图形和动态学习特定与节点两种模式进行捕获空间相关性;二是提出利用特征多头注意力机制来捕获序列特征相关性的方案。m-update/m-reset模块的功能作用是由cdsg模块的功能特性与feature multi-head attention(特征多头注意力机制)的功能特性进行拼接融合共同完成的结果。
[0142]
此外,本发明也提出了利用长时(全局)时间多头注意力机制的方案用以将m-gru模块的结果再一次进行全局性的时间相关性捕获,从而完成对交通流信息的提取,进一步为预测性能的提升奠定了基础。
[0143]
最后本发明在pemsd04真实数据集和pemsd08真实数据集上进行了相关的验证性实验和消融实验,根据试验结果进行对比分析,结果证实了本发明提出的网络模型的有效性。
[0144]
以上对本发明所提供的一种用于交通流预测的双模式图卷积循环神经网络进行了详细介绍。本发明中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。