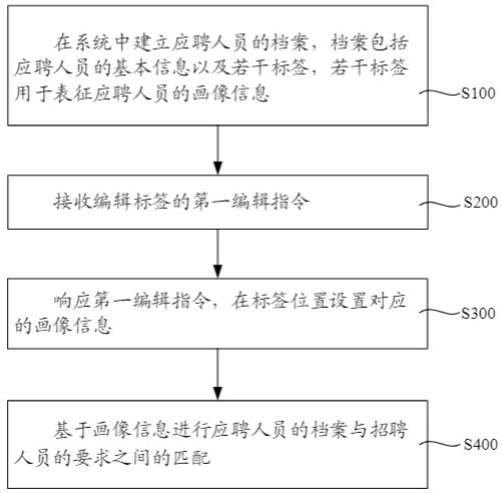
一种tb级增量数据筛选方法和装置
技术领域:
:1.本领域属于大规模计算领域,尤其涉及一种tb级增量数据筛选方法和装置,在开展大规模计算前对大数据进行筛选处理,满足大规模计算的要求。
背景技术:
::2.在大规模超级计算机实施科学计算前,需要对采集的海量数据进行清洗筛选处理,如何从采集的海量数据中筛选得到用户所述的数据集,是十分重要的。由于处理数据量在tb量级以上,传统的数据加工筛选大多是在大规模计算机或者分布式服务器上进行处理,由于该数据清洗筛选操作是io密集型,浪费了cpu计算能力和宝贵的计算资源。传统的数据筛选如希尔排序、索引分类等方法对数据处理规模均有限制。按照现有的技术手段对数据进行筛选,每次都需要占用cpu大量的计算空间,效率较低,处理的数据规模达不到tb量级,无法满足实施科学计算前筛选数据的要求。3.如果能在数据采集前端利用服务器对数据进行筛选处理,将数据处理在前端完成,在目前的现有技术中还没有一种能够满足上述要求的解决方案,因此亟需设计一种能够在服务器上进行tb量级数据处理的方法。技术实现要素:4.针对现有技术不足,本发明提出了一种tb级增量数据筛选方法和装置。5.为实现上述发明目的,本发明是通过以下技术方案来实现的:本发明实施例的第一方面提供了一种tb级增量数据筛选方法,所述方法具体包括以下步骤:(1)原始数据块预处理:将待筛选的原始数据按照文件指针以及测试得到的最优长度的储存块大小分别载入到内存,并标记得到若干原始数据块,再基于数据格式进行数据清洗,将不符合格式要求的数据清洗出去;(2)单区索引排序:将第零原始数据块加载到内存中,并申请索引分类存放区,将第零原始数据块中的全部数据分布到索引分类存放区中对应的类中,再进行索引排序,删除索引排序后的重复数据,并将第零原始数据标记为已处理数据块,根据已处理数据块生成矩阵哈希索引表;(3)块间索引排序去重:对增量数据进行索引排序,将其余的原始数据块通过单区索引排序完成去重排序;通过查询矩阵哈希索引表筛选原始数据块,取一条原始数据块数据查询矩阵哈希索引表,若没有命中,则直接保留,并继续处理原始数据块的下一条数据;若查询命中说明部分相重或可能重复,则继续对原始数据块在已处理数据块中通过起点增量二分法进行查找,若完全相重则丢弃,若不重则保留;(4)非重复结果保留:保留步骤(3)排序后的非重复的已处理数据块,将所有非重复的已处理的数据块作为数据筛选结果。6.作为优选的,所述步骤(1)中还包括对索引排序所需内存进行申请,具体为:将原始数据块经过单区索引去重复后的结果记为已处理数据块,对每个已处理数据块生成一一对应的矩阵哈希索引表;所需申请的内存划分为原始数据存放区、索引分类存放区、已处理数据存放区和矩阵哈希表存放区;将所有原始数据块、已处理数据块、矩阵哈希索引表同时读入到内存中,提前进行内存申请。7.作为优选的,所述步骤(2)中对原始数据块进行分类去重并标记为已处理数据块的过程具体为:(2.1.1)将第零原始数据块加载到内存存储,设数据长度为rawdatalen,索引区为indexarray,索引区的二进制长度为indexlen;(2.1.2)为索引区indexarray申请2indexlen 2的索引分类存放区;(2.1.3)索引分类存放区清零,将第零原始数据块的每一条数据的前二进制长度indexlen的二进制bit位取出,分别统计到索引分类存放区中;(2.1.4)将索引区indexarray的统计数值按分类从起点顺序累加求和,分别得到每一类数据顺序存放的累积起点;(2.1.5)从数据区取出一条数据,取出该条数据的前二进制长度为indexlen的bit位,设定为classnumm,查找分类后的索引分类存放区,找到其在分类后的位置,若该数据在本分区内则直接取下一条数据;若该数据不在本分区内,将该位置中的数据取出,将该数据放入下一数据的位置;(2.1.6)重复步骤(2.1.5)将第零原始数据块中的全部数据分布到相应的类中;(2.1.7)对步骤(2.1.6)分类后得到的全部数据进行排序;(2.1.8)删除步骤(2.1.7)得到的排序数据中的重复数据,并将第零原始数据标记为已处理数据块。8.作为优选的,所述步骤(2.1.5)具体为:所述步骤(2.1.5)具体为:将从第零原始数据块取出的数据设为第一数据,将第一数据前二进制长度indexlen的bit位取出,设定为classnumm,查找索引区表indexarray[classnumm],获得分类classnumm的起始位置,若第一数据就在本分区起始位置则直接取下一条数据,并将分类classnumm的起始位置加一;若第一数据不在分类classnumm的起始位置,将该起始位置中的数据取出,设为第二数据,将第一数据放入第二数据的位置,也就是第二数据所在的类的位置,并将分类classnumm的起始位置加一。[0009]作为优选的,所述步骤(2)中根据已处理数据块生成矩阵哈希索引表的过程具体为:为已处理数据块设置一个哈希函数,初始化矩阵哈希索引表,哈希表清零,将已处理数据块的每一条数据经哈希函数变换生成的哈希二进制长度值的二进制bit位取出,将取出的哈希二进制长度的bit位数据除以数据类型长度,取整部分作为矩阵哈希索引表的地址,将取余部分作为矩阵哈希索引表中对应的bit位上置1,生成矩阵哈希索引表。[0010]作为优选的,所述步骤(3)中块间索引排序的过程具体为:将原始数据块、矩阵哈希索引表和已处理数据块全部加载到内存中,从原始数据块中取出一条数据,从这条数据中通过哈希函数生成哈希二进制长度值的bit位,将取出的哈希二进制长度的bit位数据除以数据类型长度,取整部分作为矩阵哈希索引表的地址,将取余部分作为矩阵哈希索引表中对应的bit位,如果该bit位为0,则没有重复,直接处理下一条原始数据块的数据;如果该bit位为1,则可能有重复,使用起点增量二分查找法继续判定该数据记录是否已存在。[0011]作为优选的,使用起点增量二分查找法继续判定该数据记录是否已存在的过程具体为:一条数据在已处理数据区中进行二分查找,如果小于最小值或者大于最大值,则直接表示没有重复;因原始数据块为有序数据,所以在已处理数据块中查找时,查找的区间累次递减;将原始数据块的数据在对已处理数据块进行筛选后,原始数据在已处理数据块中没有找到重复的数据依然顺序存储在原始数据块中,继续进行下一个已处理数据块的查找;将下一块已处理数据块和矩阵哈希索引表载入到内存存放区,将一轮查找后仍然保留的原始数据块数据继续在新载入的矩阵哈希索引表中进行查找否定,同时未否定数据继续在已处理数据区中进行二分查找,当筛选到原始数据块为0时一个原始数据块筛选结束,载入下一个原始数据块继续筛选;一个原始数据块遍历所有已处理数据块后剩余的数据就是非重复数据,既要保留的数据,当全部原始数据块筛选后剩余的数据就是结果数据。[0012]作为优选的,所述步骤(4)中仅保留排序后的非重复的已处理数据块的过程具体为:如果原始数据块均在已处理数据块中找到了重复,则舍弃该原始数据块,继续取下一个原始数据块进行处理;全部已处理数据块查找结束后,原始数据块中剩余的数据就是非重复的保留数据,保留的数据补充到已处理数据块的尾部,满足定义长度后生成一个新的已处理数据块和一个矩阵哈希索引表,剩余部分生成最后一个不满秩的已处理数据块和一个矩阵哈希索引表;并对补充数据的已处理数据块和不满秩的已处理数据块尾巴重新进行索引分类排序,生成新的已处理数据块。[0013]本发明实施例的第二方面提供了一种tb级增量数据筛选装置,包括一个或多个处理器,用于实现上述的tb级增量数据筛选方法。[0014]本发明实施例的第二方面提供了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,用于实现上述的tb级增量数据筛选方法。[0015]本发明的有益效果是:本发明充分利用了内存资源,预处理若干原始数据块;对原始数据块进行分类去重,并标记为已处理数据块,根据已处理数据块一一对应生成矩阵哈希索引表;对于新增的原始数据块,基于矩阵哈希索引表筛选原始数据块保留不重复数据,实现初步筛选,对部分内容相重的数据,继续采用二分快速查找法进行精确查重筛选,当原始数据块遍历完已处理数据块后,保留排序后的非重复的原始数据作为筛选结果,并记为已处理数据块,全部已处理数据块就是全部结果。上述技术减少了对硬盘存储设备的存取次数和时间,将数据存取和计算相融合,实现了tb量级的大规模数据筛选处理,其处理效率较传统方法有数倍到数十倍的提升。附图说明[0016]图1为本发明方法的流程图;图2为增量数据筛选方法总体流程框图;图3为存储与内存分配策略图;图4为原始数据块单区索引分类去重处理方法原理图;图5为矩阵哈希索引表构造方法原理图;图6为利用矩阵哈希索引表快速筛选原理图示;图7为筛选结果分块索引及尾部处理原理图;图8为本发明实施例提供的一种tb级增量数据筛选装置的结构框图。具体实施方式[0017]为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。在不冲突的情况下,下述的实施例及实施方式中的特征可以相互组合。[0018]如图1和图2所示,本发明提出了一种tb级增量数据筛选方法,通过原始数据块预处理、单区索引排序、块间索引排序和非重复结果保留四大步实现。具体为:(1)原始数据块预处理:将待筛选的原始数据按照文件指针以及测试得到的最优长度的储存块大小分别载入到内存,并标记得到若干原始数据块(rawdatablocks),再基于数据格式进行数据清洗,去除不符合格式要求的非法数据,并对索引排序所需内存进行申请。[0019]具体包括以下子步骤:(1.1)对服务器设备的容量进行最优测试,以不发生内存缺页和系统颠簸为标准,得到最优长度的存储块,将原始数据块rawdatablocks按照内存容量优化切割为最优长度的存储块,每次读取最优长度块大小的原始数据块(即存储块)至内存。经测试,本发明实施例将最优长度的存储块的大小设定在0.5g-2.2g之间为最佳。[0020](1.2)设定原始数据块大小为rawdatalen,将原始数据按文件指针以及最优长度的存储块读入,设定为rawdatablock0,rawdatablock1,……rawdatablockm-1,再进行数据格式检查,如果数据不满足格式要求则清洗掉不符合格式的部分。[0021](1.3)完成数据块切割和数据清洗后,对索引排序所需内存进行申请。[0022]将第零原始数据块rawdatablock0经过单区索引去重复后的结果文件,记为第零已处理数据块processeddatablock0,则后续分别为processeddatablock1,……ꢀprocesseddatablockn-1,为每个已处理文件均生成一一对应的矩阵哈希索引表记为matrixhashtable0,...,matrixhashtablen-1。在进行数据处理的时候,需要申请的内存分别为读取原始数据块rawdatablock的内存、存储rawdatablock索引区的内存indexarray、已处理文件processeddatablock的内存以及矩阵哈希索引表matrixhashtable的内存。若内存申请失败,则应根据系统内存情况调整策略。内存申请逻辑见图3。在单区索引排序过程中,需要将原始数据块、索引区、已处理数据块和矩阵哈希表同时读入到内存中,提前进行内存申请,是为了防止前面已经做完预处理工作,进行块间索引排序的时候内存不足,导致任务失败的情况发生。[0023](2)单区索引排序:将第零原始数据块加载到内存中,并申请索引分类存放区indexarray,将第零原始数据块中的全部数据分布到索引分类存放区indexarray中对应的类中,再进行索引排序,删除索引排序后的重复数据,并将处理后的第零原始数据标记为已处理数据块processeddatablocks,同时根据已处理数据块生成矩阵哈希索引表matrixhashtables。[0024]进一步地,所述矩阵哈希索引表与已处理数据块一一对应,用于增量数据的命中查询。[0025]所述步骤(2)具体包括以下子步骤:(2.1)如图4所示,将原始数据块采用单区索引分类的方法筛选去重,并标记为已处理数据块processeddatablocks,具体包括以下子步骤:(2.1.1)将第零原始数据块rawdatablock0加载到内存存储,设数据长度为rawdatalen,设索引区为indexarray,索引区的二进制长度为indexlen。[0026](2.1.2)为索引区indexarray申请内存长度为2indexlen 2的索引分类存放区。(2.1.3)索引分类存放区清0,将第零原始数据块rawdatablock0的每一条数据的前二进制长度indexlen的二进制bit位取出,分别统计到索引分类存放区中进行分类,indexarray[classnum0],indexarray[classnum1],……,indexarray[classnum2indexlen-1],统计结束后将数据按照二进制长度indexlen的bit位分为了2indexlen类(classnum),每一个单元存放了本类的统计数量。[0027](2.1.4)将索引区indexarray的统计数值按分类从起点顺序累加求和,分别得到每一类数据顺序存放的累积起点。[0028]具体地,将索引区indexarray每个单元的第i项和第i 1项累加存放在第i 1项单元中,i=0,1,…,n;示例性地:0,classnum0,classnum0 classnum1,classnum0 classnum1 classnum2,……。最后得到每一类数据顺序存放的累积起点。[0029](2.1.5)顺序从第零原始数据块rawdatablock0取出数据进行处理,取出的第一条数据记为p,将第一数据p前indexlen的bit位取出,设定为classnumm,查找索引区表indexarray[classnumm],获得分类classnumm的起始位置,若第一数据就在本分区起始位置则直接取下一条数据,并将分类classnumm的起始位置加一,即indexarray[classnumm] 1;若第一数据p不在分类classnumm的起始位置,将该起始位置中的数据取出,设为第二数据q,将第一数据p放入第二数据q的位置,也就是第二数据q所在的类的位置,indexarray[classnumm],并将分类classnumm的起始位置加一,即:indexarray[classnumm] 1。其中本分类操作的时间复杂度为o(n)。[0030](2.1.6)对第二数据q重复步骤(2.1.5)的操作,即将第二数据q前indexlen的bit位取出,查找索引区表indexarray[indexlenbit],找到其在分类后的位置,将该位置中的数据取出,设定为classnumn,查找索引区表indexarray[classnumn],取出该单元数据设为第三数据s,将第二数据q放入第三数据s的位置,也就是第三数据s所在的类的位置,indexarray[classnumn],并将分类classnumn的起始位置加一,即:indexarray[classnumn] 1,直至全部数据处理完毕。所有操作完成后按照前indexlen的bit位的索引已经全部将数据分布到相应的类中。[0031](2.1.7)对步骤(2.1.6)分类后得到的全部数据进行传统排序操作,如冒泡排序,shell排序等均可,由于类间已经有序,所以计算量会大幅减少,分类越多,数据越均匀,计算量将大幅下降。原工程量为o(rawdatalen*log2rawdatalen),分类索引后的工程量如下式所示:。[0032](2.1.8)对步骤(2.1.7)得到的索引排序数据进行去重;所有操作在第零原始数据块rawdatablock0内完成,取出数据rawdatablock0[i]到寄存器register,若rawdatablock0[i 1]与register相重,则舍去取下一个数据继续比较,若不同,则将rawdatablock0[i 1]存入register,继续循环操作,直至数据处理结束得到了无重复的有序数据块,保持数据块有序是保证二分查找的必要条件。将第零原始数据块处理结束后作为第零块已处理数据块。[0033](2.2)如图5所示,根据已处理数据块生成矩阵哈希索引表。[0034]为已处理数据块设置一个哈希函数,生成矩阵哈希索引表,哈希函数构造要满足的要求包括哈希函数的耗费时间要小,尽量使用逻辑运算和加减运算,已处理数据块要哈希的关键字选取尽量要全,哈希值分布均匀,哈希表的大小要适中,不应过多占用内存空间,如哈希函数生成的数据为22bit位,则需要64位无符号长整形存储空间65536单元(222=8388608/64)。关键字的分布要均匀等。每一个已处理数据块都要生成一个矩阵哈希索引表,当已处理数据块发生变化时,矩阵哈希索引表也需要重新生成。[0035]具体包括以下子步骤:(2.2.1)设已处理数据块为processeddatablock,数据长度为processeddatalen,设矩阵哈希索引表为matrixhashtable,索引的哈希二进制长度值为matrixlen。[0036](2.2.2)为矩阵哈希索引表matrixhashtable申请矩阵索引区,矩阵索引区的长度为matrixarray=2matrixlen/数据类型长度(按照长整型64位/整形32位)。[0037](2.2.5)初始化矩阵哈希索引表matrixhashtable(即将矩阵哈希索引表matrixhashtable清0),将第零已处理数据块processeddatablock0的每一条数据经过hash函数变换生成的哈希二进制长度值matrixlen的二进制bit位取出(也可以从头部或者尾部任意bit位直接选取,以已处理数据区processeddatablock数据块中最大值和最小值的差别决定),将截取的哈希二进制长度值matrixlen的bit数据除以数据类型长度,取整部分作为矩阵哈希索引表matrixhashtable的地址,将取余部分在矩阵哈希索引表matrixhashtable中对应的bit位上设置1。已处理数据块processeddatablock的全部数据都要在对应的矩阵哈希索引表matrixhashtable的相应位置上设置上1的信息,生成矩阵哈希索引表,所述矩阵哈希索引表是已处理数据块processeddatablock的索引文件,形成一个数据块对,保存文件。详见图5。矩阵哈希索引表实现搜索空间的极大压缩。[0038](3)块间索引排序:对增量数据进行索引排序,将其余的原始数据块通过单区索引排序完成去重排序;通过查询矩阵哈希索引表筛选原始数据块,取一条原始数据块数据查询矩阵哈希索引表,若没有命中,则直接保留,并继续处理原始数据块的下一条数据;若查询命中说明部分相重或可能重复,则继续对原始数据块在已处理数据块中通过起点增量二分法进行查找,若完全相重则丢弃,若不重则保留。[0039]具体为:基于矩阵哈希索引表筛选原始数据块和已处理数据块,进行块间索引排序。对于增量数据,用于第二块原始数据块开始的增量数据的索引排序,首先采用单区索引排序完成增量数据块自身的去重排序;分别载入矩阵哈希索引表和已处理数据块,首先查询矩阵哈希索引表,若没有重复即bit位为0,则该数据不是重复数据,直接保留,继续换下一条数据进行处理;若重复即bit位为1,则采用起点递增二分查找方法在已处理数据块继续进行查找,若不重复,则保留,若完全重复,删除重复数据。所述二分查找法实现搜索空间的极大压缩,由于原始数据块是有序的,所以当在已处理数据块中找到一个重复后,原始数据块在已处理数据块中的查找起点变为从找到重复的点为起点,这样大幅降低检索的空间,因在筛选的过程中数据在逐步减少,所以没有在已处理块中找到重复的原始数据块的数据仍然依次保存在原始数据块中,继续载入下一个已处理数据块和矩阵哈希索引表,重复上述操作,直到原始数据块和全部已处理数据块比较完毕。最终完成全部数据的索引排序去重。[0040]所述原始数据块和已处理数据块通过矩阵哈希索引表筛选的过程具体为:将原始数据块rawdatablock,矩阵哈希索引表matrixhashtable和已处理数据块processeddatablock全部加载到内存中,首先将原始数据块按照单区索引排序方法进行预处理,实现有序无重复,分别从原始数据块中取出一条数据,从这条数据中通过运行与生成矩阵哈希索引表步骤中相同的哈希函数生成matrixlen的bit位,将生成的matrixlen的bit数据除以数据类型长度,取整部分作为矩阵哈希索引表matrixhashtable的地址,将取余部分作为matrixhashtable中对应的bit位,查看该bit位是否为1,如果为0,证明肯定没有重复,直接保留该结果,继续取下一条原始数据块的数据处理。如果该bit位为1,则可能有重复,使用起点递增二分法查找算法继续判定该数据记录是否已存在,具体见图6。[0041]所述原始数据块和已处理数据块通过起点增量二分查找筛选,具体为:(a)从原始数据块rawdatablock取出的一条数据经矩阵哈希索引后,没有否定掉,则继续采用二分查找法进行查找。[0042](b)一条数据在已处理数据块processeddatablock中进行二分查找,如果小于已处理数据的最小值或者大于已处理数据的最大值,则直接表示没有重复。[0043](c)设定初次查找processeddatablock的区间为0ꢀ–ꢀprocesseddatablocklen-1,因为原始数据块rawdatablock已经经过了排序去重是有序数据,所以当第一个数据在已处理数据块processeddatablock的相应位置(设为processeddatablockmid)找到重复后,此后的查找空间变为了processeddatablockmidꢀ–ꢀprocesseddatablocklen-1,以此类推每次找到重复后,搜索空间均呈现递减式缩小。[0044](d)将原始数据块rawdatablock的数据对已处理数据块processeddatablock进行筛选后,原始数据块rawdatablock中没有找到重复的数据依然顺序存储在rawdatablock中,因为保留不重复数据相比原始数据呈减少趋势,所以存储空间可以复用同一空间,继续进行下一个已处理数据块processeddatablock块的查找。[0045](e)将一轮查找后仍然保留的rawdatablock数据继续在矩阵哈希索引表matrixhashtable1……ꢀmatrixhashtablen-1中进行查找否定,同时未否定数据继续在已处理数据块processeddatablock1,……ꢀprocesseddatablockn-1中进行查找,当筛选到原始数据块为0时一个原始数据块筛选结束,载入下一个原始数据块继续筛选。当全部筛选后仍保留有未重复的数据,剩余的数据就是结果数据,根据重复数量的长度,随着数量的减少,筛选速度将越来越快。[0046](4)非重复结果保留:保留步骤(3)排序后的非重复的已处理数据块,将所有非重复的已处理的数据块作为数据筛选结果。[0047]如果第二原始数据块均在已处理数据块中找到了重复,则舍弃该原始数据块,继续取下一个原始数据块进行处理。全部已处理数据块查找结束后,原始数据块中剩余的数据就是非重复的保留数据,保留的数据要追加到已处理数据块的尾部,满足定义长度后成为了一个新的数据块对于新生成的数据块进行单区索引排序(已经没有重复,无需去重),成为一个满秩已处理数据块,同时要重新生成矩阵哈希索引表替换掉原来的技侦哈希索引表。如图7所示,超过定义长度的剩余尾部部分生成最后一个不满秩的已处理数据块(已经有序且没有重复),同样也需要生成一个矩阵哈希索引表。需要对补充了数据的已处理数据块和不满秩的已处理数据块尾巴重新进行索引分类排序(无需去重)。具体包括以下子步骤:(4.1)若筛选结果为零则将继续加载原始数据块直到处理结束。[0048](4.2)经过筛选后保留下的结果存入到已处理数据块processeddatablockn-1的尾部,当满足blocklen时,生成一个新的已处理数据块processeddatablock块,对新生成的已处理数据块进行一次单区索引排序处理(无需去重),同时生成一个矩阵哈希索引表matrixhashtable,已处理数据块和矩阵哈希索引表相对应,分别保存成数据文件,已处理数据块的个数blocklen的总数量加1。[0049](4.3)对剩余的尾部按照步骤(4.2)进行处理,最后生成不满秩的已处理数据块processeddatablockn-1和矩阵哈希索引表matrixhashtablen-1,已处理数据块的统计数量blocklen总数量加1,其算法时间复杂度为o(n)函数。[0050]需要进一步说明的是:本发明方法对设备的内存容量敏感,当设备的内存空间太小时,不能满足本发明的有效操作或者影响本发明方法的效率。其次,本发明对矩阵哈希索引表的空间需求同样比较敏感,当矩阵哈希索引表空间太小时,将会存在大部分bit位为1的情况发生,达不到初级粗粒度筛选的目的。最后本发明具有明显的i/o密集型存取特征,若设备配置更高性能i/o存取设备,如固态硬盘ssd,则可以大幅提升筛选的效率。[0051]与前述tb级增量数据筛选方法的实施例相对应,本发明还提供了tb级增量数据筛选装置的实施例。[0052]参见图8,本发明实施例提供的一种tb级增量数据筛选装置,包括一个或多个处理器,用于实现上述实施例中的tb级增量数据筛选方法。[0053]本发明tb级增量数据筛选装置的实施例可以应用在任意具备数据处理能力的设备上,该任意具备数据处理能力的设备可以为诸如计算机等设备或装置。装置实施例可以通过软件实现,也可以通过硬件或者软硬件结合的方式实现。以软件实现为例,作为一个逻辑意义上的装置,是通过其所在任意具备数据处理能力的设备的处理器将非易失性存储器中对应的计算机程序指令读取到内存中运行形成的。从硬件层面而言,如图8所示,为本发明tb级增量数据筛选装置所在任意具备数据处理能力的设备的一种硬件结构图,除了图8所示的处理器、内存、网络接口、以及非易失性存储器,i/o存储接口之外,实施例中装置所在的任意具备数据处理能力的设备通常根据该任意具备数据处理能力的设备的实际功能,还可以包括其他硬件,对此不再赘述。[0054]上述装置中各个单元的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。[0055]对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本发明方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。[0056]本发明实施例还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述实施例中的tb级增量数据筛选方法。[0057]所述计算机可读存储介质可以是前述任一实施例所述的任意具备数据处理能力的设备的内部存储单元,例如硬盘或内存。所述计算机可读存储介质也可以是任意具备数据处理能力的设备,例如所述设备上配备的插接式硬盘、智能存储卡(smartmediacard,smc)、sd卡、闪存卡(flashcard)等。进一步的,所述计算机可读存储介质还可以既包括任意具备数据处理能力的设备的内部存储单元也包括外部存储设备。所述计算机可读存储介质用于存储所述计算机程序以及所述任意具备数据处理能力的设备所需的其他程序和数据,还可以用于暂时地存储已经输出或者将要输出的数据。[0058]以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。当前第1页12当前第1页12
技术领域:
:1.本领域属于大规模计算领域,尤其涉及一种tb级增量数据筛选方法和装置,在开展大规模计算前对大数据进行筛选处理,满足大规模计算的要求。
背景技术:
::2.在大规模超级计算机实施科学计算前,需要对采集的海量数据进行清洗筛选处理,如何从采集的海量数据中筛选得到用户所述的数据集,是十分重要的。由于处理数据量在tb量级以上,传统的数据加工筛选大多是在大规模计算机或者分布式服务器上进行处理,由于该数据清洗筛选操作是io密集型,浪费了cpu计算能力和宝贵的计算资源。传统的数据筛选如希尔排序、索引分类等方法对数据处理规模均有限制。按照现有的技术手段对数据进行筛选,每次都需要占用cpu大量的计算空间,效率较低,处理的数据规模达不到tb量级,无法满足实施科学计算前筛选数据的要求。3.如果能在数据采集前端利用服务器对数据进行筛选处理,将数据处理在前端完成,在目前的现有技术中还没有一种能够满足上述要求的解决方案,因此亟需设计一种能够在服务器上进行tb量级数据处理的方法。技术实现要素:4.针对现有技术不足,本发明提出了一种tb级增量数据筛选方法和装置。5.为实现上述发明目的,本发明是通过以下技术方案来实现的:本发明实施例的第一方面提供了一种tb级增量数据筛选方法,所述方法具体包括以下步骤:(1)原始数据块预处理:将待筛选的原始数据按照文件指针以及测试得到的最优长度的储存块大小分别载入到内存,并标记得到若干原始数据块,再基于数据格式进行数据清洗,将不符合格式要求的数据清洗出去;(2)单区索引排序:将第零原始数据块加载到内存中,并申请索引分类存放区,将第零原始数据块中的全部数据分布到索引分类存放区中对应的类中,再进行索引排序,删除索引排序后的重复数据,并将第零原始数据标记为已处理数据块,根据已处理数据块生成矩阵哈希索引表;(3)块间索引排序去重:对增量数据进行索引排序,将其余的原始数据块通过单区索引排序完成去重排序;通过查询矩阵哈希索引表筛选原始数据块,取一条原始数据块数据查询矩阵哈希索引表,若没有命中,则直接保留,并继续处理原始数据块的下一条数据;若查询命中说明部分相重或可能重复,则继续对原始数据块在已处理数据块中通过起点增量二分法进行查找,若完全相重则丢弃,若不重则保留;(4)非重复结果保留:保留步骤(3)排序后的非重复的已处理数据块,将所有非重复的已处理的数据块作为数据筛选结果。6.作为优选的,所述步骤(1)中还包括对索引排序所需内存进行申请,具体为:将原始数据块经过单区索引去重复后的结果记为已处理数据块,对每个已处理数据块生成一一对应的矩阵哈希索引表;所需申请的内存划分为原始数据存放区、索引分类存放区、已处理数据存放区和矩阵哈希表存放区;将所有原始数据块、已处理数据块、矩阵哈希索引表同时读入到内存中,提前进行内存申请。7.作为优选的,所述步骤(2)中对原始数据块进行分类去重并标记为已处理数据块的过程具体为:(2.1.1)将第零原始数据块加载到内存存储,设数据长度为rawdatalen,索引区为indexarray,索引区的二进制长度为indexlen;(2.1.2)为索引区indexarray申请2indexlen 2的索引分类存放区;(2.1.3)索引分类存放区清零,将第零原始数据块的每一条数据的前二进制长度indexlen的二进制bit位取出,分别统计到索引分类存放区中;(2.1.4)将索引区indexarray的统计数值按分类从起点顺序累加求和,分别得到每一类数据顺序存放的累积起点;(2.1.5)从数据区取出一条数据,取出该条数据的前二进制长度为indexlen的bit位,设定为classnumm,查找分类后的索引分类存放区,找到其在分类后的位置,若该数据在本分区内则直接取下一条数据;若该数据不在本分区内,将该位置中的数据取出,将该数据放入下一数据的位置;(2.1.6)重复步骤(2.1.5)将第零原始数据块中的全部数据分布到相应的类中;(2.1.7)对步骤(2.1.6)分类后得到的全部数据进行排序;(2.1.8)删除步骤(2.1.7)得到的排序数据中的重复数据,并将第零原始数据标记为已处理数据块。8.作为优选的,所述步骤(2.1.5)具体为:所述步骤(2.1.5)具体为:将从第零原始数据块取出的数据设为第一数据,将第一数据前二进制长度indexlen的bit位取出,设定为classnumm,查找索引区表indexarray[classnumm],获得分类classnumm的起始位置,若第一数据就在本分区起始位置则直接取下一条数据,并将分类classnumm的起始位置加一;若第一数据不在分类classnumm的起始位置,将该起始位置中的数据取出,设为第二数据,将第一数据放入第二数据的位置,也就是第二数据所在的类的位置,并将分类classnumm的起始位置加一。[0009]作为优选的,所述步骤(2)中根据已处理数据块生成矩阵哈希索引表的过程具体为:为已处理数据块设置一个哈希函数,初始化矩阵哈希索引表,哈希表清零,将已处理数据块的每一条数据经哈希函数变换生成的哈希二进制长度值的二进制bit位取出,将取出的哈希二进制长度的bit位数据除以数据类型长度,取整部分作为矩阵哈希索引表的地址,将取余部分作为矩阵哈希索引表中对应的bit位上置1,生成矩阵哈希索引表。[0010]作为优选的,所述步骤(3)中块间索引排序的过程具体为:将原始数据块、矩阵哈希索引表和已处理数据块全部加载到内存中,从原始数据块中取出一条数据,从这条数据中通过哈希函数生成哈希二进制长度值的bit位,将取出的哈希二进制长度的bit位数据除以数据类型长度,取整部分作为矩阵哈希索引表的地址,将取余部分作为矩阵哈希索引表中对应的bit位,如果该bit位为0,则没有重复,直接处理下一条原始数据块的数据;如果该bit位为1,则可能有重复,使用起点增量二分查找法继续判定该数据记录是否已存在。[0011]作为优选的,使用起点增量二分查找法继续判定该数据记录是否已存在的过程具体为:一条数据在已处理数据区中进行二分查找,如果小于最小值或者大于最大值,则直接表示没有重复;因原始数据块为有序数据,所以在已处理数据块中查找时,查找的区间累次递减;将原始数据块的数据在对已处理数据块进行筛选后,原始数据在已处理数据块中没有找到重复的数据依然顺序存储在原始数据块中,继续进行下一个已处理数据块的查找;将下一块已处理数据块和矩阵哈希索引表载入到内存存放区,将一轮查找后仍然保留的原始数据块数据继续在新载入的矩阵哈希索引表中进行查找否定,同时未否定数据继续在已处理数据区中进行二分查找,当筛选到原始数据块为0时一个原始数据块筛选结束,载入下一个原始数据块继续筛选;一个原始数据块遍历所有已处理数据块后剩余的数据就是非重复数据,既要保留的数据,当全部原始数据块筛选后剩余的数据就是结果数据。[0012]作为优选的,所述步骤(4)中仅保留排序后的非重复的已处理数据块的过程具体为:如果原始数据块均在已处理数据块中找到了重复,则舍弃该原始数据块,继续取下一个原始数据块进行处理;全部已处理数据块查找结束后,原始数据块中剩余的数据就是非重复的保留数据,保留的数据补充到已处理数据块的尾部,满足定义长度后生成一个新的已处理数据块和一个矩阵哈希索引表,剩余部分生成最后一个不满秩的已处理数据块和一个矩阵哈希索引表;并对补充数据的已处理数据块和不满秩的已处理数据块尾巴重新进行索引分类排序,生成新的已处理数据块。[0013]本发明实施例的第二方面提供了一种tb级增量数据筛选装置,包括一个或多个处理器,用于实现上述的tb级增量数据筛选方法。[0014]本发明实施例的第二方面提供了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,用于实现上述的tb级增量数据筛选方法。[0015]本发明的有益效果是:本发明充分利用了内存资源,预处理若干原始数据块;对原始数据块进行分类去重,并标记为已处理数据块,根据已处理数据块一一对应生成矩阵哈希索引表;对于新增的原始数据块,基于矩阵哈希索引表筛选原始数据块保留不重复数据,实现初步筛选,对部分内容相重的数据,继续采用二分快速查找法进行精确查重筛选,当原始数据块遍历完已处理数据块后,保留排序后的非重复的原始数据作为筛选结果,并记为已处理数据块,全部已处理数据块就是全部结果。上述技术减少了对硬盘存储设备的存取次数和时间,将数据存取和计算相融合,实现了tb量级的大规模数据筛选处理,其处理效率较传统方法有数倍到数十倍的提升。附图说明[0016]图1为本发明方法的流程图;图2为增量数据筛选方法总体流程框图;图3为存储与内存分配策略图;图4为原始数据块单区索引分类去重处理方法原理图;图5为矩阵哈希索引表构造方法原理图;图6为利用矩阵哈希索引表快速筛选原理图示;图7为筛选结果分块索引及尾部处理原理图;图8为本发明实施例提供的一种tb级增量数据筛选装置的结构框图。具体实施方式[0017]为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。在不冲突的情况下,下述的实施例及实施方式中的特征可以相互组合。[0018]如图1和图2所示,本发明提出了一种tb级增量数据筛选方法,通过原始数据块预处理、单区索引排序、块间索引排序和非重复结果保留四大步实现。具体为:(1)原始数据块预处理:将待筛选的原始数据按照文件指针以及测试得到的最优长度的储存块大小分别载入到内存,并标记得到若干原始数据块(rawdatablocks),再基于数据格式进行数据清洗,去除不符合格式要求的非法数据,并对索引排序所需内存进行申请。[0019]具体包括以下子步骤:(1.1)对服务器设备的容量进行最优测试,以不发生内存缺页和系统颠簸为标准,得到最优长度的存储块,将原始数据块rawdatablocks按照内存容量优化切割为最优长度的存储块,每次读取最优长度块大小的原始数据块(即存储块)至内存。经测试,本发明实施例将最优长度的存储块的大小设定在0.5g-2.2g之间为最佳。[0020](1.2)设定原始数据块大小为rawdatalen,将原始数据按文件指针以及最优长度的存储块读入,设定为rawdatablock0,rawdatablock1,……rawdatablockm-1,再进行数据格式检查,如果数据不满足格式要求则清洗掉不符合格式的部分。[0021](1.3)完成数据块切割和数据清洗后,对索引排序所需内存进行申请。[0022]将第零原始数据块rawdatablock0经过单区索引去重复后的结果文件,记为第零已处理数据块processeddatablock0,则后续分别为processeddatablock1,……ꢀprocesseddatablockn-1,为每个已处理文件均生成一一对应的矩阵哈希索引表记为matrixhashtable0,...,matrixhashtablen-1。在进行数据处理的时候,需要申请的内存分别为读取原始数据块rawdatablock的内存、存储rawdatablock索引区的内存indexarray、已处理文件processeddatablock的内存以及矩阵哈希索引表matrixhashtable的内存。若内存申请失败,则应根据系统内存情况调整策略。内存申请逻辑见图3。在单区索引排序过程中,需要将原始数据块、索引区、已处理数据块和矩阵哈希表同时读入到内存中,提前进行内存申请,是为了防止前面已经做完预处理工作,进行块间索引排序的时候内存不足,导致任务失败的情况发生。[0023](2)单区索引排序:将第零原始数据块加载到内存中,并申请索引分类存放区indexarray,将第零原始数据块中的全部数据分布到索引分类存放区indexarray中对应的类中,再进行索引排序,删除索引排序后的重复数据,并将处理后的第零原始数据标记为已处理数据块processeddatablocks,同时根据已处理数据块生成矩阵哈希索引表matrixhashtables。[0024]进一步地,所述矩阵哈希索引表与已处理数据块一一对应,用于增量数据的命中查询。[0025]所述步骤(2)具体包括以下子步骤:(2.1)如图4所示,将原始数据块采用单区索引分类的方法筛选去重,并标记为已处理数据块processeddatablocks,具体包括以下子步骤:(2.1.1)将第零原始数据块rawdatablock0加载到内存存储,设数据长度为rawdatalen,设索引区为indexarray,索引区的二进制长度为indexlen。[0026](2.1.2)为索引区indexarray申请内存长度为2indexlen 2的索引分类存放区。(2.1.3)索引分类存放区清0,将第零原始数据块rawdatablock0的每一条数据的前二进制长度indexlen的二进制bit位取出,分别统计到索引分类存放区中进行分类,indexarray[classnum0],indexarray[classnum1],……,indexarray[classnum2indexlen-1],统计结束后将数据按照二进制长度indexlen的bit位分为了2indexlen类(classnum),每一个单元存放了本类的统计数量。[0027](2.1.4)将索引区indexarray的统计数值按分类从起点顺序累加求和,分别得到每一类数据顺序存放的累积起点。[0028]具体地,将索引区indexarray每个单元的第i项和第i 1项累加存放在第i 1项单元中,i=0,1,…,n;示例性地:0,classnum0,classnum0 classnum1,classnum0 classnum1 classnum2,……。最后得到每一类数据顺序存放的累积起点。[0029](2.1.5)顺序从第零原始数据块rawdatablock0取出数据进行处理,取出的第一条数据记为p,将第一数据p前indexlen的bit位取出,设定为classnumm,查找索引区表indexarray[classnumm],获得分类classnumm的起始位置,若第一数据就在本分区起始位置则直接取下一条数据,并将分类classnumm的起始位置加一,即indexarray[classnumm] 1;若第一数据p不在分类classnumm的起始位置,将该起始位置中的数据取出,设为第二数据q,将第一数据p放入第二数据q的位置,也就是第二数据q所在的类的位置,indexarray[classnumm],并将分类classnumm的起始位置加一,即:indexarray[classnumm] 1。其中本分类操作的时间复杂度为o(n)。[0030](2.1.6)对第二数据q重复步骤(2.1.5)的操作,即将第二数据q前indexlen的bit位取出,查找索引区表indexarray[indexlenbit],找到其在分类后的位置,将该位置中的数据取出,设定为classnumn,查找索引区表indexarray[classnumn],取出该单元数据设为第三数据s,将第二数据q放入第三数据s的位置,也就是第三数据s所在的类的位置,indexarray[classnumn],并将分类classnumn的起始位置加一,即:indexarray[classnumn] 1,直至全部数据处理完毕。所有操作完成后按照前indexlen的bit位的索引已经全部将数据分布到相应的类中。[0031](2.1.7)对步骤(2.1.6)分类后得到的全部数据进行传统排序操作,如冒泡排序,shell排序等均可,由于类间已经有序,所以计算量会大幅减少,分类越多,数据越均匀,计算量将大幅下降。原工程量为o(rawdatalen*log2rawdatalen),分类索引后的工程量如下式所示:。[0032](2.1.8)对步骤(2.1.7)得到的索引排序数据进行去重;所有操作在第零原始数据块rawdatablock0内完成,取出数据rawdatablock0[i]到寄存器register,若rawdatablock0[i 1]与register相重,则舍去取下一个数据继续比较,若不同,则将rawdatablock0[i 1]存入register,继续循环操作,直至数据处理结束得到了无重复的有序数据块,保持数据块有序是保证二分查找的必要条件。将第零原始数据块处理结束后作为第零块已处理数据块。[0033](2.2)如图5所示,根据已处理数据块生成矩阵哈希索引表。[0034]为已处理数据块设置一个哈希函数,生成矩阵哈希索引表,哈希函数构造要满足的要求包括哈希函数的耗费时间要小,尽量使用逻辑运算和加减运算,已处理数据块要哈希的关键字选取尽量要全,哈希值分布均匀,哈希表的大小要适中,不应过多占用内存空间,如哈希函数生成的数据为22bit位,则需要64位无符号长整形存储空间65536单元(222=8388608/64)。关键字的分布要均匀等。每一个已处理数据块都要生成一个矩阵哈希索引表,当已处理数据块发生变化时,矩阵哈希索引表也需要重新生成。[0035]具体包括以下子步骤:(2.2.1)设已处理数据块为processeddatablock,数据长度为processeddatalen,设矩阵哈希索引表为matrixhashtable,索引的哈希二进制长度值为matrixlen。[0036](2.2.2)为矩阵哈希索引表matrixhashtable申请矩阵索引区,矩阵索引区的长度为matrixarray=2matrixlen/数据类型长度(按照长整型64位/整形32位)。[0037](2.2.5)初始化矩阵哈希索引表matrixhashtable(即将矩阵哈希索引表matrixhashtable清0),将第零已处理数据块processeddatablock0的每一条数据经过hash函数变换生成的哈希二进制长度值matrixlen的二进制bit位取出(也可以从头部或者尾部任意bit位直接选取,以已处理数据区processeddatablock数据块中最大值和最小值的差别决定),将截取的哈希二进制长度值matrixlen的bit数据除以数据类型长度,取整部分作为矩阵哈希索引表matrixhashtable的地址,将取余部分在矩阵哈希索引表matrixhashtable中对应的bit位上设置1。已处理数据块processeddatablock的全部数据都要在对应的矩阵哈希索引表matrixhashtable的相应位置上设置上1的信息,生成矩阵哈希索引表,所述矩阵哈希索引表是已处理数据块processeddatablock的索引文件,形成一个数据块对,保存文件。详见图5。矩阵哈希索引表实现搜索空间的极大压缩。[0038](3)块间索引排序:对增量数据进行索引排序,将其余的原始数据块通过单区索引排序完成去重排序;通过查询矩阵哈希索引表筛选原始数据块,取一条原始数据块数据查询矩阵哈希索引表,若没有命中,则直接保留,并继续处理原始数据块的下一条数据;若查询命中说明部分相重或可能重复,则继续对原始数据块在已处理数据块中通过起点增量二分法进行查找,若完全相重则丢弃,若不重则保留。[0039]具体为:基于矩阵哈希索引表筛选原始数据块和已处理数据块,进行块间索引排序。对于增量数据,用于第二块原始数据块开始的增量数据的索引排序,首先采用单区索引排序完成增量数据块自身的去重排序;分别载入矩阵哈希索引表和已处理数据块,首先查询矩阵哈希索引表,若没有重复即bit位为0,则该数据不是重复数据,直接保留,继续换下一条数据进行处理;若重复即bit位为1,则采用起点递增二分查找方法在已处理数据块继续进行查找,若不重复,则保留,若完全重复,删除重复数据。所述二分查找法实现搜索空间的极大压缩,由于原始数据块是有序的,所以当在已处理数据块中找到一个重复后,原始数据块在已处理数据块中的查找起点变为从找到重复的点为起点,这样大幅降低检索的空间,因在筛选的过程中数据在逐步减少,所以没有在已处理块中找到重复的原始数据块的数据仍然依次保存在原始数据块中,继续载入下一个已处理数据块和矩阵哈希索引表,重复上述操作,直到原始数据块和全部已处理数据块比较完毕。最终完成全部数据的索引排序去重。[0040]所述原始数据块和已处理数据块通过矩阵哈希索引表筛选的过程具体为:将原始数据块rawdatablock,矩阵哈希索引表matrixhashtable和已处理数据块processeddatablock全部加载到内存中,首先将原始数据块按照单区索引排序方法进行预处理,实现有序无重复,分别从原始数据块中取出一条数据,从这条数据中通过运行与生成矩阵哈希索引表步骤中相同的哈希函数生成matrixlen的bit位,将生成的matrixlen的bit数据除以数据类型长度,取整部分作为矩阵哈希索引表matrixhashtable的地址,将取余部分作为matrixhashtable中对应的bit位,查看该bit位是否为1,如果为0,证明肯定没有重复,直接保留该结果,继续取下一条原始数据块的数据处理。如果该bit位为1,则可能有重复,使用起点递增二分法查找算法继续判定该数据记录是否已存在,具体见图6。[0041]所述原始数据块和已处理数据块通过起点增量二分查找筛选,具体为:(a)从原始数据块rawdatablock取出的一条数据经矩阵哈希索引后,没有否定掉,则继续采用二分查找法进行查找。[0042](b)一条数据在已处理数据块processeddatablock中进行二分查找,如果小于已处理数据的最小值或者大于已处理数据的最大值,则直接表示没有重复。[0043](c)设定初次查找processeddatablock的区间为0ꢀ–ꢀprocesseddatablocklen-1,因为原始数据块rawdatablock已经经过了排序去重是有序数据,所以当第一个数据在已处理数据块processeddatablock的相应位置(设为processeddatablockmid)找到重复后,此后的查找空间变为了processeddatablockmidꢀ–ꢀprocesseddatablocklen-1,以此类推每次找到重复后,搜索空间均呈现递减式缩小。[0044](d)将原始数据块rawdatablock的数据对已处理数据块processeddatablock进行筛选后,原始数据块rawdatablock中没有找到重复的数据依然顺序存储在rawdatablock中,因为保留不重复数据相比原始数据呈减少趋势,所以存储空间可以复用同一空间,继续进行下一个已处理数据块processeddatablock块的查找。[0045](e)将一轮查找后仍然保留的rawdatablock数据继续在矩阵哈希索引表matrixhashtable1……ꢀmatrixhashtablen-1中进行查找否定,同时未否定数据继续在已处理数据块processeddatablock1,……ꢀprocesseddatablockn-1中进行查找,当筛选到原始数据块为0时一个原始数据块筛选结束,载入下一个原始数据块继续筛选。当全部筛选后仍保留有未重复的数据,剩余的数据就是结果数据,根据重复数量的长度,随着数量的减少,筛选速度将越来越快。[0046](4)非重复结果保留:保留步骤(3)排序后的非重复的已处理数据块,将所有非重复的已处理的数据块作为数据筛选结果。[0047]如果第二原始数据块均在已处理数据块中找到了重复,则舍弃该原始数据块,继续取下一个原始数据块进行处理。全部已处理数据块查找结束后,原始数据块中剩余的数据就是非重复的保留数据,保留的数据要追加到已处理数据块的尾部,满足定义长度后成为了一个新的数据块对于新生成的数据块进行单区索引排序(已经没有重复,无需去重),成为一个满秩已处理数据块,同时要重新生成矩阵哈希索引表替换掉原来的技侦哈希索引表。如图7所示,超过定义长度的剩余尾部部分生成最后一个不满秩的已处理数据块(已经有序且没有重复),同样也需要生成一个矩阵哈希索引表。需要对补充了数据的已处理数据块和不满秩的已处理数据块尾巴重新进行索引分类排序(无需去重)。具体包括以下子步骤:(4.1)若筛选结果为零则将继续加载原始数据块直到处理结束。[0048](4.2)经过筛选后保留下的结果存入到已处理数据块processeddatablockn-1的尾部,当满足blocklen时,生成一个新的已处理数据块processeddatablock块,对新生成的已处理数据块进行一次单区索引排序处理(无需去重),同时生成一个矩阵哈希索引表matrixhashtable,已处理数据块和矩阵哈希索引表相对应,分别保存成数据文件,已处理数据块的个数blocklen的总数量加1。[0049](4.3)对剩余的尾部按照步骤(4.2)进行处理,最后生成不满秩的已处理数据块processeddatablockn-1和矩阵哈希索引表matrixhashtablen-1,已处理数据块的统计数量blocklen总数量加1,其算法时间复杂度为o(n)函数。[0050]需要进一步说明的是:本发明方法对设备的内存容量敏感,当设备的内存空间太小时,不能满足本发明的有效操作或者影响本发明方法的效率。其次,本发明对矩阵哈希索引表的空间需求同样比较敏感,当矩阵哈希索引表空间太小时,将会存在大部分bit位为1的情况发生,达不到初级粗粒度筛选的目的。最后本发明具有明显的i/o密集型存取特征,若设备配置更高性能i/o存取设备,如固态硬盘ssd,则可以大幅提升筛选的效率。[0051]与前述tb级增量数据筛选方法的实施例相对应,本发明还提供了tb级增量数据筛选装置的实施例。[0052]参见图8,本发明实施例提供的一种tb级增量数据筛选装置,包括一个或多个处理器,用于实现上述实施例中的tb级增量数据筛选方法。[0053]本发明tb级增量数据筛选装置的实施例可以应用在任意具备数据处理能力的设备上,该任意具备数据处理能力的设备可以为诸如计算机等设备或装置。装置实施例可以通过软件实现,也可以通过硬件或者软硬件结合的方式实现。以软件实现为例,作为一个逻辑意义上的装置,是通过其所在任意具备数据处理能力的设备的处理器将非易失性存储器中对应的计算机程序指令读取到内存中运行形成的。从硬件层面而言,如图8所示,为本发明tb级增量数据筛选装置所在任意具备数据处理能力的设备的一种硬件结构图,除了图8所示的处理器、内存、网络接口、以及非易失性存储器,i/o存储接口之外,实施例中装置所在的任意具备数据处理能力的设备通常根据该任意具备数据处理能力的设备的实际功能,还可以包括其他硬件,对此不再赘述。[0054]上述装置中各个单元的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。[0055]对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本发明方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。[0056]本发明实施例还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述实施例中的tb级增量数据筛选方法。[0057]所述计算机可读存储介质可以是前述任一实施例所述的任意具备数据处理能力的设备的内部存储单元,例如硬盘或内存。所述计算机可读存储介质也可以是任意具备数据处理能力的设备,例如所述设备上配备的插接式硬盘、智能存储卡(smartmediacard,smc)、sd卡、闪存卡(flashcard)等。进一步的,所述计算机可读存储介质还可以既包括任意具备数据处理能力的设备的内部存储单元也包括外部存储设备。所述计算机可读存储介质用于存储所述计算机程序以及所述任意具备数据处理能力的设备所需的其他程序和数据,还可以用于暂时地存储已经输出或者将要输出的数据。[0058]以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。