1.本发明涉及工业设备故障诊断及边云协同任务卸载技术领域,尤其是涉及一种基于边云协同任务卸载的故障诊断优化方法及电子设备。
背景技术:
2.随着人工智能、物联网及工业互联网技术的发展,工业制造业正走向数字化与智能化,机械设备也朝着日益复杂化、集成化的方向发展。一旦结构复杂的精密关键机械部件发生故障,将严重影响机械设备的正常运转,造成重大损失。因此,对大型机械设备故障的预测诊断和预防,是工业制造业发展的重要课题。
3.设备故障诊断的实时性和能耗开销,直接影响实际生产的效率及安全性,是决定故障诊断服务质量的关键指标。然而目前大多数故障诊断方法的诊断时延与能耗较高,难以提供高质量的诊断服务并满足智能制造场景的需求。针对上述问题,学者们引入边云协同的技术。边云协同主要包含资源协同、数据协同和服务协同三种协同方式。
4.资源协同即靠近数据源的边缘端提供基本的算力、存储资源,能够自主调度本地资源,处理时延敏感型任务,中心云作为资源总调度中心,可以为边缘端提供资源调度决策。文章[wang s,tuor t,salonidis t,et al.when edge meets learning:adaptive control for resource-constrained distributed machine learning[c].ieee infocom 2018-ieee conference on computer communications.ieee,2018:63-71.]提出了一种利用中心参数服务器来进行参数聚合的分布式模型训练算法,该方法将不同分布式节点的本地模型参数上传进行聚合,而不需将原始数据上传到中心云。同时,在本地更新与全局参数聚合之间进行权衡,提出一种最小化给定资源预算的控制算法。文章[li y,shen b,zhang j,et al.offloading in hcns:congestion-aware network selection and user incentive design[j].ieee transactions on wireless communications,2017,16(10):6479-6492.]针对云边缘场景中资源的异构性而导致协同的多跳性问题,设计了拥塞处理及信任感知下的资源调度机制,在保证网络稳定性及负载均衡性的前提下,实现了高效任务调度及全局资源共享。
[0005]
数据协同即边缘端对采集的数据进行原始处理,然后将相应的数据及处理结果发送至中心云,中心云汇集海量数据,进行数据挖掘、模型训练,并将模型下沉至边缘节点。对于边云数据协同的研究,文章[zhang x,qiao m,liu l,et al.collaborative cloud-edge computation for personalized driving behavior modeling[c].proceedings of the 4th acm/ieee symposium on edge computing.2019:209-221.]提出了一种基于云边协同的个性化驾驶行为分析方法,云端根据各边缘端上传的数据训练一个通用的模型,模型经过裁剪后迁移至边缘端,边缘端模型根据汽车行驶时的加速度、角速度等数据对司机驾驶行为是否异常做出判断。实验证明,该方法可以满足实时性需求。
[0006]
服务协同即中心云作为管理中心,为边缘节点提供应用部署、开启服务、结束服务等生命周期的管理方案;拥有丰富资源的中心云负责模型训练,并将模型下沉至边缘节点
进行识别分类。对于边云服务协同的研究,文章[ma x,zhang s,li w,et al.cost-efficient workload scheduling in cloud assisted mobile edge computing[c].2017ieee/acm 25th international symposium on quality of service(iwqos).ieee,2017:1-10.]设计一种云边缘协同(came)架构,同时提出一种负载均衡与云外包策略,由came架构建模分析系统时延,并构建为服务质量最大化问题,以平衡时延与成本花销,提高服务质量。结果表明,该框架可以按需降低时延。文章[kang y,hauswald j,gao c,et al.neurosurgeon:collaborative intelligence between the cloud and mobile edge[j].acm sigarch computer architecture news,2017,45(1):615-629.]设计了neurosurgeon框架,根据dnn(deep learning neural network,深度神经网络)模型各层的类型,以层为粒度,该框架在移动设备与中心云之间进行模型划分,最终返回最佳模型划分点以降低延迟,提供实时高效的服务。
[0007]
边云协同技术的发展为智慧工厂等场景的落地带来了契机。在智慧工厂场景中,存在大量传感器实时采集设备生产状态数据,而设备故障诊断对诊断实时性、数据安全性及资源管理效率有较高的要求,传统的设备故障诊断方法已经难以满足工业生产的需求。面向设备故障诊断场景,云计算是实现基于深度学习设备故障诊断方法的重要支撑技术,利用中心云丰富的算力与存储资源,对海量数据进行特征提取和数据挖掘。然而,物联网技术的快速发展,使设备产生的数据呈指数爆炸型增长,海量数据的上传导致巨大的网络传输资源开销,且中心云远离数据源,无法保证故障诊断的实时性。而在边缘计算模式中,数据在靠近数据源的边缘节点进行存储与预处理,不需要直接上传至远程云端,极大地降低了诊断响应时间,并有利于数据的隐私保护。文章[qian g,lu s,pan d,et al.edge computing:a promising framework for real-time fault diagnosis and dynamic control of rotating machines using multi-sensor data[j].ieee sensors journal,2019,19(11):4211-4220.]提出基于边缘计算的旋转机械故障诊断方法,首先,边缘端采集电机的原始信号数据,接着对振动信号数据进行特征提取与融合,最终实现分类诊断,实验结果证明了边缘端可以实现高精度故障诊断,并制定有效的故障应对措施;文章[tharmakulasingam s,lu s,phung b t,et al.sustainable deep learning at grid edge for real-time high impedance fault detection[j].ieee transactions on sustainable computing,2018,2879960:1-12.]提出了基于dnn神经网络与边缘计算的高压电设备故障诊断方法,用于降低高压电线高阻抗故障诊断的时延。上述文献都取得了较好的效果,但是中心云未参与到故障诊断场景中,导致上述方法无法适用于拥有海量异构状态数据的智慧工厂场景。文章[wang y,gao l,zheng p,et al.a smart surface inspection system using faster r-cnn in cloud-edge computing environment[j].advanced engineering informatics,2020,43:101037-101049.]基于边云协同计算环境,根据设备表面状态数据,提出基于r-cnn的设备表面检测方法。张文龙等人基于边云协同架构,结合迁移学习技术,提高了故障诊断方法对个性化数据的适配能力并降低了故障诊断的时延。然而上述文献并未对诊断任务进行细粒度的分解,导致诊断任务并未得到最优的边云部署方案,仍然存在诊断时延偏高的问题。
技术实现要素:
[0008]
本发明的目的在于提供一种基于边云协同任务卸载的故障诊断优化方法及电子设备,缓解了现有技术存在诊断时延偏高的问题。
[0009]
第一方面,本发明提供一种基于边云协同任务卸载的故障诊断优化方法,包括:
[0010]
针对各诊断任务不同的容忍时延,建立边云dnn多分支的故障诊断模型;其中,故障诊断模型包括多个故障诊断模型分支,每个故障诊断模型分支由相应的dnn网络层组成;
[0011]
按照诊断模型结构,以层为粒度,根据每秒浮点运算次数flops将故障诊断模型分为多个部分,每一个部分构成一个诊断任务,并建模为一个有向无环图(direct acyclic graph,简称dag)以表示各部分之间的执行顺序;
[0012]
对故障诊断模型的诊断任务的卸载时延与卸载能耗进行分析,并确立任务卸载的多目标优化函数;
[0013]
利用基于注意力机制的平均网络参数的drqn算法,求出多目标优化函数的最小解。
[0014]
第二方面,本发明还提供一种电子设备,包括存储器、处理器,所述存储器中存储有可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
[0015]
第三方面,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有机器可运行指令,所述计算机可运行指令在被处理器调用和运行时,所述计算机可运行指令促使所述处理器运行上述方法。
[0016]
本发明提供的基于边云协同任务卸载的故障诊断优化方法,首先针对drqn(deep recurrent q-network,基于改进深度循环q网络)算法使用ε-贪婪策略导致环境探索效率较低的问题,提出一种基于平均网络参数的drqn算法进行多目标寻优,提供最优的故障诊断边云任务卸载方案,降低了故障诊断的时延与能耗,缓解了现有技术存在诊断时延偏高的问题,提高诊断服务质量。
附图说明
[0017]
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0018]
图1为本发明实施例提供的基于边云协同任务卸载的故障诊断优化方法的流程图;
[0019]
图2为本发明实施例设备故障诊断分支模型结构图;
[0020]
图3为本发明实施例第一分支模型dag图;
[0021]
图4为本发明实施例第二分支模型dag图;
[0022]
图5为本发明实施例第三分支模型dag图;
[0023]
图6为本发明实施例apam-drqn算法流程图;
[0024]
图7为本发明实施例dqn、drqn和apam-drqn算法的长期平均累积奖励值对比图;
[0025]
图8为不同任务数量下5种算法时延与能耗加权和的对比图;
[0026]
图9为云服务器不同计算能力下5种算法时延与能耗加权和的对比图;
[0027]
图10为不同任务数据量下5种算法时延与能耗加权和的对比图;
[0028]
图11为不同算法下任务执行的平均时延图;
[0029]
图12为不同算法下总能耗的平均开销图。
具体实施方式
[0030]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0031]
本发明实施例中所提到的术语“包括”和“具有”以及它们的任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括其他没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
[0032]
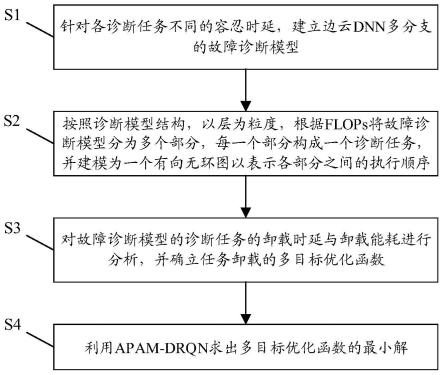
如图1所示,本发明实施例提供一种基于边云协同任务卸载的故障诊断优化方法(fault diagnosis optimization method based on edge-cloud collaborative task offloading,简称fdbecto方法),包括:
[0033]
s1:针对各诊断任务不同的容忍时延,建立边云dnn多分支的故障诊断模型。
[0034]
其中,故障诊断模型包括多个故障诊断模型分支,以及两个全连接层(fully connected layers,简称fc),每个故障诊断模型分支由相应的dnn网络层组成。各分支模型的复杂程度逐步上升,模型的泛化性与诊断时延依次上升。故障诊断时,根据诊断任务的容忍时延,选择合适的分支,设备故障诊断模型分支结构如图2所示。多个故障诊断模型分支中的第一故障诊断模型分支包括4层卷积层和1层池化层;第二故障诊断模型分支包括5层卷积层和1层池化层;第三故障诊断模型分支包括3层卷积层、3层长短期记忆网络层(long short-term memory,简称lstm)和1层池化层。
[0035]
卷积层从输入样本数据中提取局部特征,池化层对上述特征进行降采样处理,两种网络层构成一组故障特征提取模块。通过多组特征提取模块的串联,实现对故障特征由浅到深的提取。最后由全连接层进行故障映射,实现分类诊断。其中,分支1模型的第一层cnn网络采用较大尺寸的卷积核,其余cnn层网络采用较小尺寸的卷积核来获取局部特征以提高诊断精度;分支2模型增加一层cnn网络及一层池化层等隐藏层,使诊断模型的诊断精度提高;分支3包含三层卷积层与三层池化层等隐藏层及3层lstm网络。由卷积层进行特征提取,对故障信号数据进行抽象识别,其次由lstm层对时序性故障诊断数据进行识别处理,从而提高诊断模型的泛化性与诊断精度。三个分支的故障诊断精度与执行时延依次升高。
[0036]
分支1故障诊断模型第一层cnn网络为64*1的大卷积核,后面的卷积层为3*1的小卷积核。大卷积层可以获得足够大的感受野,其余小卷积层可以保证网络的参数较少,分支2故障诊断模型增加了一层cnn层与一层池化层等隐藏层。分支1故障诊断模型为四层cnn及四层池化层等隐藏层,分支2故障诊断模型为五层cnn及五层池化层等隐藏层。分支1故障诊断模型的结构参数如表1所示,分支2故障诊断模型的结构参数如表2所示。
[0037]
表1分支1模型网络结构参数
[0038][0039]
表2分支2模型网络结构参数
[0040][0041]
lstm网络适合处理时序性关联的数据,然而训练速度较慢。cnn层与池化层等隐藏层首先对故障信号数据进行抽象特征提取,cnn层提取振动信号特征,池化层进行降维处理,从而降低模型训练时间,提高模型诊断精度,分支3的诊断模型结构参数如表3所示。
[0042]
关键参数项:
[0043]
conv(卷积)层和pooling(池化)层:卷积核大小/步长
[0044]
lstm层:隐层单元数
[0045]
表3分支3模型网络结构参数
[0046][0047]
s2:按照诊断模型结构,以层为粒度,根据每秒浮点运算次数(floating point operations per second,简称flops)将故障诊断模型分为多个部分,每一个部分构成一个诊断任务,并建模为一个有向无环图以表示各部分之间的执行顺序。
[0048]
本发明建立故障诊断模型dag有向无环图的过程描述如下:
[0049]
对于dnn结构的设备故障诊断模型,由于模型各层的类型、输入数据和计算特性不同,诊断模型不同层的运行时间具有很大的异构性。可以通过计算浮点运算次数(flops)对dnn诊断模型的执行时间进行估计。其中,卷积层与全连接层是flops较高的层,其它种类神经网络层的flops较低。
[0050]
按照诊断模型结构,以层为粒度,根据flops将神经网络分为多部分,每一部分构成一个诊断任务,并建模为一个dag有向无环图以表示各部分之间的先后执行顺序,dag由g=(v,e)来表示。其中,v=(v1,v2,
…
,vn)表示节点集合,每个顶点为模型的一部分并作为一个诊断任务,只能在云端或边缘端其中的一个计算资源上进行处理。e表示有向边集合,有向边e=(vi,vj)∈e,表示诊断模型诊断任务vj在vi任务执行完成后才能执行。
[0051]
基于dnn的故障诊断分支模型建立dag图,分别如图3至图5所示。每个任务节点vi∈v的定义如式(1)所示:
[0052]
vi=(ωi,datasizei,ini,outi)
ꢀꢀꢀ
(1)
[0053]
其中,ωi表示诊断任务taski的计算量大小,包含taski任务自身执行的运算量及其前驱任务节点输出的计算量大小;datasizei表示任务taski的数据量大小,包含taski任务自身的数据量及其前驱任务节点输出的数据量大小;ini表示任务taski的前驱任务节点集合,只有当taski的所有前驱任务执行完毕,任务taski才可以执行;outi表示任务taski的后继任务节点集合,只有当任务taski执行完毕,其后继任务节点才可以执行。
[0054]
为了描述诊断任务之间的前后依赖关系,建立任务dag图,确立了任务间的优先级列表。定义task类与taskslist类:
[0055]
task类的成员变量用于描述任务task的相关属性。
[0056]
class task:{
[0057]
taskid;//任务所属id
[0058]
index;//任务在优先级列表中索引
[0059]
flops://任务的浮点运算次数,反映任务计算量
[0060]
datasize://任务的数据量
[0061]
prelist;//任务的前驱任务列表
[0062]
postlist;//任务的后继任务列表
[0063]
status;//任务的执行状态,1表示任务执行完毕;0表示任务准备就绪,待执行。
[0064]
}
[0065]
taskslist类的成员变量为一个包含map键值对的数组,数组已进行了任务优先级降序排序,任务task的优先级低于其前驱任务,高于其后继任务,每个map元素key为taskid,value为任务task。
[0066]
class taskslist:{
[0067]
array<map<taskid,task>>(sorted);//进行优先级降序排序,
[0068]
}
[0069]
任务优先级列表构建完毕后,在执行dag中的任务时,会按照优先级顺序执行,优先级较高的任务先被执行,接着执行后继任务,确保任务可以正确执行。
[0070]
s3:对故障诊断模型的诊断任务的卸载时延与卸载能耗进行分析,并确立任务卸载的多目标优化函数。具体步骤如下:
[0071]
1-1)将诊断任务的卸载时间分为计算时间和传输时间,并进行诊断任务卸载时间分析,获得总运行时间t。
[0072]
将诊断模型的每部分作为诊断任务进行云边任务卸载,总时间包含任务的计算时间与任务在云边资源环境中的传输时间。
[0073]
(1)计算时间
[0074]
诊断模型的结构确定之后,可以通过计算flops得出诊断任务ei的负载wi,并可以统计出该部分模型的输出数据大小outi。当任务ei分配到资源ri时,ei的计算时间由式(2)表示:
[0075][0076]
在式(2)中,由该任务的卸载决策决定,任务可以被放置到云端或边缘端执行。ri∈r
cloud
表示任务被放置到云端执行,f
icloud
表示任务ei在中心云的执行速度;ri∈r
edge
表示任务被放置到边缘端执行,f
iedge
表示任务ei在边缘端的执行速度;ri∈r
end
表示任务在设备端执行,f
iend
表示任务ei在设备端的执行速度。
[0077]
(2)传输时间
[0078]
(ei,ej)表示任务ei与ej的前后执行关系,即任务ei为任务ej的前置层诊断任务。传输时间由式(3)表示。
[0079][0080]
其中,outi为任务ei的输出数据,同时是任务ej的输入数据。b
upload
与b
download
分别表示从边缘端至云端的上传网络带宽和云端至边缘端的回传网络带宽。当相邻两个任务被放置到同一计算资源时,即均被放置在云端、边缘端或设备端,此时任务ei的输出结果直接输入到任务ej,不需要经过网络传输;当任务ei被放置到设备端,任务ej被卸载到边缘端,任务ei的输出结果需要经过网络上传至边缘端,作为任务ej的输入,此时网络带宽为b
upload
;当任务ei被卸载到边缘端,任务ej被放置到设备端,任务ei的输出结果需要经过网络回传至边缘端,作为任务ej的输入,此时网络带宽为b
download
;当任务ei被放置到边缘端,任务ej被卸载到云端,任务ei的输出结果需要经过网络上传至云端,作为任务ej的输入,此时网络带宽为b
upload
;当任务ei被卸载到云端,任务ej被放置到边缘端,任务ei的输出结果需要经过网络回传至云端,作为任务ej的输入,此时网络带宽为b
download
。
[0081]
(3)总运行时间
[0082]
总运行时间t包含任务的计算时间与任务在云边资源环境中的传输时间,如式(4)所示。
[0083][0084]
其中,n表示dnn诊断模型被划分的任务总个数,总运行时间等于每个任务的计算时间与网络传输时间的累加和。
[0085]
1-2)将诊断任务的卸载能耗分为计算能耗和传输能耗,并进行诊断任务卸载能耗分析,获得总能耗e。
[0086]
终端设备的总能耗e包含设备端的任务执行能耗、任务数据上传到云服务器的能耗及任务执行结果回传到设备端的接收能耗,总能耗如式(5)所示。
[0087][0088]
其中,p
comp
、p
upload
、p
download
分别表示设备端任务执行功率、数据上传功率及数据接收功率;t
comp
、t
upload
、t
download
分别表示任务执行时间、数据上传时间及数据接收时间。
[0089][0090][0091][0092]
其中,在式(6)~式(8)中,任务ei被放置在设备端,若ej被卸载至边缘端,设备端为数据发送方;若任务ei被放置在边缘端,ej被放置在设备端,设备端为数据接收方;若ej被卸载至云端,设备端为数据发送方;若任务ei被放置在云端,ej被放置在设备端,设备端为数据
接收方。
[0093]
1-3)确立任务时延的权重因子α和任务能耗的权重因子β,建立任务卸载的多目标优化函数g=α*t β*e,使问题转为对目标函数值的最小化。
[0094]
本发明的目标是在云边缘架构下,为dnn故障诊断模型拆分的诊断任务提供好的卸载决策与资源分配方案,最终使诊断任务的时间与能耗开销的加权和最小化。所以目标函数g为所有诊断任务的时间与能耗的加权和。
[0095]
g=α*t β*e
ꢀꢀꢀ
(9)
[0096]
其中,α β=1,α表示针对任务时延的权重因子,而β表示针对任务在云边架构下能耗的权重因子。t表示诊断模型每部分在边云架构下的时延累加和,e表示诊断模型每部分在边云架构下的能耗累加和。
[0097]
在云边缘系统的资源约束条件下,将dnn诊断模型作为诊断任务,进行任务卸载与资源分配。根据前文对问题的建模,问题转为对目标函数值的最小化,目标函数表示为:
[0098]
min(α*t β*e)
ꢀꢀꢀ
(10)
[0099]
若任务taski被卸载到边缘节点edgej上,目标函数的约束条件为:
[0100][0101]
在式(11)中,rf
ij
表示任务taski分配的资源,该式表示卸载至边缘节点edgej上任务分配的资源之和需小于等于边缘节点edgej的资源之和。
[0102]
若任务taski被卸载到云端cloud上,目标函数的约束条件为:
[0103][0104]
在式(12)中,rf
ij
表示任务taski分配的资源,该式表示卸载至云端cloud上任务分配的资源之和需小于等于云端cloud的资源之和。
[0105]
s4:利用基于注意力机制的平均网络参数的drqn算法(average network parameters drqn based on attention mechanism,apam-drqn),求出多目标优化函数的最小解。
[0106]
利用apam-drqn求解问题的最优解,使目标函数值g最小,具体步骤为:
[0107]
2-1)设置三个重要元素,即状态(state)、动作(action)、奖励(reward)三个参数:
[0108]
(1)状态
[0109]
t时刻的状态s
t
定义为:
[0110]st
=[taski,ra,rf]
ꢀꢀꢀ
(13)
[0111]
其中,taski表示第i个dag任务的执行优先级、数据量、负载等相关信息;向量ra=[ra0,ra1,
…
,ran],rai∈(0,1),0代表任务在边缘端执行,1代表任务在云端执行。n为任务的总个数;向量rf=[rf0,rf1,
…
,rfn],rfi代表第i个诊断任务被分配的计算资源。
[0112]
(2)动作
[0113]
动作action决定当前任务的卸载决策及分配的计算资源,从而调整系统状态。动作action由三部分构成,分别为设备端到最佳边缘节点的卸载决策,边缘节点至云端的卸载决策及当前任务分配的计算资源。
[0114]
actioni=[rxi,ryi,rfi]
ꢀꢀꢀ
(14)
[0115]
其中,rxi表示任务taski从设备端至边缘节点的卸载方案向量,
[0116]
rxi=(x
i,1
,x
i,2
,x
i,3
,...,x
i,n
)
ꢀꢀꢀ
(15)
[0117]
x
i,j
∈{0,1},0代表任务taski在本地设备端执行,1代表任务taski在边缘节点j执行。ryi表示任务taski从边缘节点至云端的卸载方案向量,ryi∈{0,1},0代表任务taski在当前边缘节点执行,1代表任务taski被进一步卸载至云端执行。
[0118]
rfi表示任务taski的资源分配方案。
[0119]
(3)奖励
[0120]
奖励值reward可以评估在当前状态下执行动作所得方案的优劣程度,drqn算法的目标是得到最大的reward值,与目标函数寻优获取最小值g相关联。
[0121]
reward=(g
t-g
t-1
)/g
edge
ꢀꢀꢀ
(16)
[0122]
其中,g
t
表示t时刻的目标值,g
t 1
表示采取动作action
t
后状态由s
t
变为s
t 1
后的目标值,g
edge
为所有任务在边缘端执行的目标函数值。由于需要寻找最小的目标值,因此目标值g越小,得到的奖励越高。当g
t-g
t 1
>0时,可以获得正奖励,表明采取动作action
t
后状态由s
t
变为s
t 1
后可以获得更优的目标函数值;否则,获得负奖励。
[0123]
2-2)将状态、动作、奖励输入故障诊断模型,利用注意力机制的平均网络参数的drqn算法,经过迭代计算出使多目标优化函数g得到最小解的任务时延的权重因子α和任务能耗的权重因子β。
[0124]
本发明实施例对drqn算法进行了改进,提出了一种基于注意力机制的平均网络参数的drqn算法(apam-drqn)。与原始drqn算法相比,本发明所提算法主要在两部分进行了改进。首先,针对drqn算法使用ε-贪婪策略导致环境探索效率较低的问题,提出一种基于平均网络参数的drqn算法;其次,对drqn算法中神经网络结构和网络q值的输出部分进行了改进。
[0125]
与原始drqn算法相比,本发明所提算法主要在两部分进行了改进。首先,针对drqn算法使用ε-贪婪策略导致环境探索效率较低的问题,提出一种基于平均网络参数的drqn算法;其次,对drqn算法中神经网络结构和网络q值的输出部分进行了改进。
[0126]
(1)基于平均网络参数的drqn算法
[0127]
与drqn算法相比,本发明提出的apam-drqn算法在每一轮次训练开始时,需要对智能体在前面学习的多个值网络参数做平均化处理,进而得到一个平均扰动网络参数,如式(17)和式(18)所示。根据该参数做出的动作选择策略,从而提高算法对环境的探索效率。
[0128][0129]
[0130]
其中,k表示值网络的数量,表示第k个值网络的第i层神经网络权重值矩阵,表示第k个值网络的第i层神经网络偏置值矩阵,w表示平均扰动网络q
p
的权重值矩阵,b表示平均扰动网络参数q
p
的偏置值矩阵。接着,由平均扰动网络使用贪婪策略筛选最佳动作。
[0131]
不同时期的网络参数有较大差异,通过平均处理,得到一个新的网络参数。由于网络中参数的微小变动使未来多个时间步内产生连锁变化,上述变化会影响apam-drqn算法下一阶段的动作选择策略,进而提高apam-drqn算法的探索能力。由于apam-drqn算法得到的平均扰动网络具有高效探索能力,因此采用贪婪策略代替ε-贪婪策略。
[0132]
(2)改进drqn算法的网络结构与输出部分
[0133]
图6展示了amap-drqn的算法流程,首先将环境与智能体交互所得的样本(z
t
,a
t
,r
t
,z
t 1
)存储至经验回放单元,随后对样本随机取样并拆分,拆分后的两部分分别用来对当前值网络和目标值网络进行训练。2个网络拥有相同的结构,均由1个lstm层与2个全连接层构成,每隔c轮迭代,目标值网络将拷贝当前值网络的参数进行模型优化。2个网络首先由lstm层对当前状态s
t
和下一个状态s
t 1
进行计算推导,最后根据梯度值对当前值网络的权值进行反向更新。
[0134]
对drqn算法的神经网络结构进行了改进设计。首先引入注意力机制,使系统自适应地将注意力集中于能最大降低加权和的目标优化指标,进而做出更加准确的决策,其输出与智能体上一状态的动作进行串联作为下一层的输入。接着加入lstm层,使模型对时序型数据具有记忆能力,可以对之前的状态信息进行存储,更有利于状态的时序推理,使模型具有更好的学习效果,lstm层的单元数为边缘节点数n与边缘节点服务器资源数f的乘积。最后,引入两层全连接层,第一层全连接层的单元数为256,而第二层全连接层的单元数为边缘节点数n与边缘节点资源数f的乘积。经过多轮迭代不断调整模型学习权重,从而得出最优解。
[0135]
drqn模型的输出为每个动作对应的q值,然后由贪婪算法计算出网络预测的q值,该模型结构较为复杂,运算量大。针对上述问题,本发明对drqn模型的输出部分进行改进,模型直接输出对应状态空间和动作空间的q值标量,进而降低计算量,并使mse损失的反向传播更加便利。drqn模型输出的全部q值与当前状态下选择的动作空间a
t
作点乘,得到估计值q(s,a),该值通过式(19)bellman方程得到长期回报。
[0136]
q(s,a)=q(s,a) k(r(s,a) γmaxq
′
(s
′
,a
′
)-q(s,a))
ꢀꢀꢀ
(19)
[0137]
其中,q(s,a)表示网络的预测q值,r(s,a) γmaxq
′
(s
′
,a
′
)表示目标q值。根据上述描述,本发明提出的apam-drqn算法的流程如算法1所示。
[0138][0139][0140]
先对拆分后的dnn诊断模型分支各部分建立dag图,确立各任务之间的前后依赖关系,得到dag图g的任务优先级列表tasks。将任务优先级列表tasks输入到apam-drqn任务卸载与资源分配算法中,得到相应的卸载与资源分配方案,从而降低任务执行时延与能耗,算法流程如算法2所示。
[0141][0142][0143]
drqn算法仅适合处理离散的动作,因此本发明在进行边云任务卸载与资源分配时,每轮迭代分配的动作空间值一定是离散值。对于边云任务卸载,卸载向量x与y的取值为0或1的离散值,分别代表任务本地执行或卸载;而对于边云资源分配,计算资源的分配值理论上为连续实数值,因此资源分配向量rfi的取值需要进行离散化处理。
[0144]
若边缘节点edgei的资源总值为以整数1为精度将其离散化处理,资源分
配向量rfi取值范围为
[0145]
基于上述步骤,在本发明所提供的fdbecto方法中,首先在边云任务卸载的故障诊断多目标优化模块中,根据诊断模型各层的特性,以层为粒度进行划分,并建立dag有向无环图,确保模型各部分之间的前后依赖关系。同时,明确故障诊断优化指标,并确定多目标优化函数,为故障诊断边云任务卸载方案的提出提供理论依据;接着,在基于改进drqn的故障诊断边云任务卸载模块中,由提出的apam-drqn算法进行多目标寻优,提供最优的故障诊断边云任务卸载方案,进一步降低故障诊断的时延与能耗,提高诊断服务质量。
[0146]
本发明基于边云协同任务卸载的故障诊断优化方法的试验验证:
[0147]
滚动轴承是一种关键而易损坏的精密机械部件,以滚动轴承为研究对象,对本发明提出的基于边云协同任务卸载的故障诊断优化方法进行试验论证。
[0148]
1、试验环境
[0149]
在apam-drqn算法的对比实验中,仿真实验程序由python语言编写,根据dnn诊断模型结构得到模型层的输出数据大小及模型各部分的任务负载。设置边缘端cpu计算能力为0.5ghz/s,云端服务器计算能力为5ghz/s,边缘端计算功率、数据上传功率及数据接收功率分别为0.8w、0.1w和0.025w,云端到边缘端上行与下行网络带宽分别为10mbps和8mbps,各dnn故障诊断模型诊断任务的数据量为unif(300,500)kbits,各边缘节点与中心云的距离为unif(200,2000)km。
[0150]
apam-drqn算法的超参数如表4所示。
[0151]
表4 apam-drqn算法的超参数
[0152][0153]
试验一:apam-drqn模型训练
[0154]
奖励值可以评估当前策略的优劣程度,本发明采用平均累积奖励值评估算法的有效性。
[0155][0156]
其中,表示第i轮迭代获得的平均累积奖励值,r(i)表示第i轮迭代获得的累积奖励值,的计算公式如式(20)所示。
[0157]
为验证本发明所提apam-drqn算法的有效性,本发明选择dqn(deep q-network,深
度循环q网络)算法与drqn算法作为基线算法,由三种算法为dnn诊断模型任务提供边云卸载与资源分配方案,得到的平均累积奖励值如图7所示。其中,dqn算法在训练280轮左右时,获得的奖励值显著下降,算法稳定性较差;drqn算法在训练300轮后,模型趋于收敛;相比上述两种算法,本发明提出的apam-drqn算法一方面收敛速度更快,并且在模型收敛后,奖励值的波动较小,算法的稳定性较好。另一方面,该算法获得的平均累计奖励值高于dqn和drqn算法。验证了本发明所提apam-drqn算法的有效性。
[0158]
试验二:故障诊断多目标优化对比实验
[0159]
apam-drqn算法可以为设备故障诊断模型的各部分提供边云卸载策略与资源分配方案,从而提高诊断实时性并降低能耗。本节从任务数量、云服务器cpu计算能力及任务数据量三方面对5种任务卸载及资源分配算法进行对比。5种算法包括基于边缘端不卸载算法(ale)、基于云端的完全卸载算法(alc)、dqn算法、drqn算法及本发明提出的apam-drqn算法。其中,dqn算法、drqn算法及本发明提出的apam-drqn算法为dnn诊断模型任务提供边云卸载与资源分配方案。
[0160]
设置中心云服务器计算能力为5ghz/s,dnn诊断模型诊断任务数量不断增加。图8展示了随着任务数量的不断增加,5种算法下诊断任务执行时延与能耗的平均加权和值。由该图可得,在边云架构下随着任务数量的不断增加,5种算法对应的加权和值呈上升趋势。这是由于在边云架构下,任务数量的增多导致边缘端与云端处理各自任务的时延与能耗增多,加权和不断增大。另外,在相同数量的任务下,ale算法对应的加权和最大,而本发明提出的apam-drqn算法对应时延与能耗的加权和最小。这是由于当采用ale算法时,边缘端负责执行所有任务,此时边缘端的计算能耗较大,导致加权和较大。而当采用alc算法时,所有任务需由边缘端上传至云端,导致时延增加,加权和仍较高。而本发明提出的apam-drqn算法,将任务在边云之间进行调度,在不同数量的任务下所得的加权和均优于前两种算法,并优于dqn和drqn边云协同卸载算法。
[0161]
将dnn诊断模型诊断任务划分为5部分,使中心云服务器计算能力不断提高。图9展示了随着云服务器计算能力的增加,5种算法下诊断任务执行时延与能耗的平均加权和值。由该图可得,在边云架构下随着云服务器计算能力的不断增加,ale算法下对应的加权和基本保持不变,而另外4种算法所对应的加权和值呈下降趋势。这是由于当采用ale算法时,所有任务均在边缘端执行,云服务器计算能力的增强并不会改变执行任务的时延与能耗;对于卸载到云端的任务,云服务器计算能力的增强使任务的计算时延大幅降低,从而使加权和呈下降趋势。另外,随着云服务器计算能力的增强,本发明提出的apam-drqn边云协同卸载算法所得的加权和优于另外4种算法。
[0162]
将dnn诊断模型诊断任务划分为5部分,设置中心云服务器计算能力为5ghz/s,dnn诊断模型诊断任务的输入数据量不断上升。图10展示了随着任务数据量的不断增加,5种算法下诊断任务执行时延与能耗的平均加权和值。由该图可得,在边云架构下随着任务数据量的不断增加,5种算法所对应的加权和值呈上升趋势。这是由于任务的数据量越大,任务处理的时延与能耗越大。经过对比,本发明提出的apam-drqn边云协同卸载算法,在不同任务数据量下所得的加权和均优于另外4种算法。
[0163]
综上所述,通过从任务数量、云服务器cpu计算能力及任务数据量三方面对5种算法进行对比,可以得出本发明提出的apam-drqn边云协同卸载算法所得的时延与能耗的加
权和均优于其它4种算法,证明了该算法在降低诊断时延与能耗方面的有效性。
[0164]
试验三:诊断时延和能耗开销对比实验
[0165]
将诊断模型诊断任务划分为5部分,设置中心云服务器计算能力为5ghz/s。在5种任务卸载及资源分配算法下,本节从故障诊断任务执行的平均时延和能耗开销两方面进行对比。5种算法包括基于边缘端的不卸载算法(all locate on the edge,简称ale)、基于云端的完全卸载算法(all locate on the cloud,简称alc)、dqn(deep q-learning,指深度q学习)算法、drqn算法及本发明提出的apam-drqn算法。其中,dqn算法、drqn算法及本发明提出的apam-drqn算法为dnn诊断模型任务提供边云卸载与资源分配方案。由于云端拥有海量的算力与存储资源,因此实验中忽略任务在云端的处理能耗开销。
[0166]
图11展示了不同算法下诊断任务执行的平均时延,总时延包含任务的执行时延和网络传输时延。在总时延开销方面,由大到小依次为:alc算法、ale算法、dqn算法、drqn算法及本发明提出的apam-drqn算法。其中,ale算法总时延仅包含任务执行时延,由于任务不需要卸载至中心云,因此不需要对任务进行网络传输;而在alc算法、dqn算法、drqn算法及本发明提出的apam-drqn算法中,任务在网络中传输时延占总时延的比例分别为:82.52%、63.45%、64.16%和62.13%。
[0167]
图12展示了不同算法下总能耗的平均开销,总能耗开销包含任务的执行能耗和网络传输能耗。在总能耗开销方面,由大到小依次为:ale算法、alc算法、dqn算法、drqn算法和本发明提出的apam-drqn算法。其中,ale算法总能耗仅包含任务执行能耗,由于任务不需要卸载至中心云,因此不需要对任务进行网络传输;alc算法总能耗开销仅包含任务传输能耗,由于任务全部卸载至中心云,云端具有海量的计算资源,任务在云端的执行能耗忽略不计;而在dqn算法、drqn算法及本发明提出的apam-drqn算法中,任务在网络中传输能耗占总能耗开销的比例分别为:58.80%、58.75%和59.43%。实验结果表明本发明提出的apam-drqn边云协同卸载算法所得的时延与能耗均优于其它4种算法,证明了该算法在降低诊断时延与能耗方面的有效性。
[0168]
结论
[0169]
本发明提出了一种基于边云协同任务卸载的故障诊断优化方法。首先,在边云任务卸载的故障诊断多目标优化模块中,根据诊断模型各层的特性,以层为粒度进行划分,并建立dag有向无环图,确保模型各部分之间的前后依赖关系。同时,明确故障诊断优化指标,并确定多目标优化函数,为故障诊断边云任务卸载方案的提出提供理论依据;接着,在基于改进drqn的故障诊断边云任务卸载模块中,由提出的apam-drqn算法进行多目标寻优,提供最优的故障诊断边云任务卸载方案,进一步降低故障诊断的时延与能耗,提高诊断服务质量。
[0170]
实验结果表明:从任务数量、云服务器cpu计算能力及任务数据量三方面对5种任务卸载及资源分配算法进行对比,可以得出本发明提出的改进drqn算法所得的时延与能耗加权和均低于其它4种算法,验证了算法在降低诊断时延与能耗开销方面的有效性。未来工作将进一步考虑成本、负载均衡等指标,提升诊断服务的可靠性和稳定性。
[0171]
本发明还提供一种电子设备,包括存储器、处理器,所述存储器中存储有可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
[0172]
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以
存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,简称rom)、随机存取存储器(random access memory,简称ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0173]
最后应说明的是:以上所述实施例,仅为本发明的具体实施方式,用以说明本发明的技术方案,而非对其限制,本发明的保护范围并不局限于此,尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
