1.本发明涉及知识图谱构建技术领域,具体涉及一种企业基本信息知识图谱的构建方法及系统。
背景技术:
2.由于无处不在的商业风险,所以企业在进行项目合作、挑选合作伙伴时需要了解合作方的运营状况、失信记录、企业资产、专利申请情况、经营规模、财务信息、高管信息、违规记录等企业全方位的信息,并将其作为是否合作的参考依据。同时,如果一个企业对自身各种信息了如指掌,在企业决策方面也可以作为重要依据。对于国家而言,了解全面企业的各方面信息有利于对企业的监管,比如企业的缴税情况。以企业基本信息为主要内容所构建的领域类知识图谱可以将这些信息高效完整的保存下来,并依托知识图谱进行知识推理等其他工作。
3.国外学者hook对知识图谱进行了以下的应用总结:认为知识图谱有四个目的(发现、理解、交流、教育)和六方面的应用(特定领域微观展示、学科宏观可视化、协助教育者课程教学、协调保存文献知识、便于利用数字图书馆、展示知识传播)。虽然近年来知识图谱理论和实践不断发展进步,各种知识图谱应用层出不穷,但大多数公开的研究主要是理论或总结性地说明知识图谱构建中的一个环节或方面,企业知识图谱方面研究较少。
技术实现要素:
4.本技术的目的在于克服上述问题或者至少部分地解决或缓减解决上述问题。
5.根据本发明的一方面,提供一种企业基本信息知识图谱的构建方法,该方法包括以下步骤:
6.构建包含多个企业的企业信息、企业学术论文信息、企业专利信息的数据集;
7.在所述数据集中选择知识图谱架构中的实体、属性及实体间的关系;
8.对实体、关系、属性集合进行知识融合,完成实体—关系—实体或实体—属性—属性值的三元组建立过程,完成企业基本信息知识图谱的构建。
9.进一步地,还包括:利用构建完成的知识图谱,将三元组转换成谓词表示,并与马尔可夫逻辑网结构结合,完成知识推理。
10.进一步地,在所述数据集中选择企业、企业高管、持股信息记录、基金、机构、企业学术论文、企业专利信息作为知识图谱的实体,所述持股信息记录包括基金持股信息记录和机构持股信息记录;在所述数据集中选择各个实体的属性确定如下:
11.a.企业:公司名称、英文名称、董事长、主要股东、成立日期、主营业务、公司简介、员工人数、管理层人数、上市日期、发行量、发行价格、交易市场、联系电话、邮政编码、传真、电子邮箱、公司网址、注册地址、办公地址;
12.b.企业高管:高管姓名、高管职务、高管薪酬、高管年薪货币单位;
13.c.基金持股信息记录或机构持股信息记录:日期、持有者、持有份额、持股比例、变
化率、份额变化、变化金额、占组合比;
14.d.企业学术论文:学术论文编号、学术论文标题、学术论文作者、论文摘要、公布日期;
15.e.企业专利信息:专利标题、专利申请编号、专利申请日期、专利公布日期、专利申请人。
16.进一步地,不同实体间的关系具体确定如下:企业和企业高管之间的关系为管理人员;企业和企业学术论文之间的关系为持有学术论文;企业和企业专利信息之间的关系为持有专利信息;企业和基金持股信息记录之间的关系为基金持股;企业和机构持股信息记录之间的关系为机构持股;基金和基金持股信息记录之间的关系为基金持股;机构和机构持股信息记录之间的关系为机构持股。
17.进一步地,所述马尔可夫逻辑网结构的学习流程为:
18.获取子句集合;
19.初始化学习权重和最优期望值;设置标志位等于0;
20.寻找最优子句,如果最优子句为空,则标志位加1,继续寻找;如果最优子句不为空,则添加最优子句到马尔可夫逻辑网中,并计算最优期望;
21.判断标志位的值是否等于2,等于2则结束,若不等于2则继续寻找最优子句;
22.其中,所述最优子句为子句与谓词连接后得到的最优子句;所述最优期望为评判子句与谓词连接的结果的评价标准,影响最终得出子句的权值大小。
23.根据本发明的另一方面,提供一种企业基本信息知识图谱的构建系统,该系统包括:
24.数据集获取模块,其配置成构建包含多个企业的企业信息、企业学术论文信息、企业专利信息的数据集;
25.知识图谱构建模块,其配置成在所述数据集中选择知识图谱架构中的实体、属性及实体间的关系;对实体、关系、属性集合进行知识融合,完成实体-关系-实体或实体-属性-属性值的三元组建立过程,完成企业基本信息知识图谱的构建。
26.进一步地,还包括知识推理模块,其配置成利用构建完成的知识图谱,将三元组转换成谓词表示,并与马尔可夫逻辑网结构结合,完成知识推理。
27.进一步地,所述知识图谱构建模块中在所述数据集中选择企业、企业高管、持股信息记录、基金、机构、企业学术论文、企业专利信息作为知识图谱的实体,所述持股信息记录包括基金持股信息记录和机构持股信息记录;在所述数据集中选择各个实体的属性确定如下:
28.a.企业:公司名称、英文名称、董事长、主要股东、成立日期、主营业务、公司简介、员工人数、管理层人数、上市日期、发行量、发行价格、交易市场、联系电话、邮政编码、传真、电子邮箱、公司网址、注册地址、办公地址;
29.b.企业高管:高管姓名、高管职务、高管薪酬、高管年薪货币单位;
30.c.基金持股信息记录或机构持股信息记录:日期、持有者、持有份额、持股比例、变化率、份额变化、变化金额、占组合比;
31.d.企业学术论文:学术论文编号、学术论文标题、学术论文作者、论文摘要、公布日期;
32.e.企业专利信息:专利标题、专利申请编号、专利申请日期、专利公布日期、专利申请人。
33.进一步地,所述知识图谱构建模块中不同实体间的关系具体确定如下:企业和企业高管之间的关系为管理人员;企业和企业学术论文之间的关系为持有学术论文;企业和企业专利信息之间的关系为持有专利信息;企业和基金持股信息记录之间的关系为基金持股;企业和机构持股信息记录之间的关系为机构持股;基金和基金持股信息记录之间的关系为基金持股;机构和机构持股信息记录之间的关系为机构持股。
34.进一步地,所述知识推理模块中所述马尔可夫逻辑网结构的学习流程为:
35.获取子句集合;
36.初始化学习权重和最优期望值;设置标志位等于0;
37.寻找最优子句,如果最优子句为空,则标志位加1,继续寻找;如果最优子句不为空,则添加最优子句到马尔可夫逻辑网中,并计算最优期望;
38.判断标志位的值是否等于2,等于2则结束,若不等于2则继续寻找最优子句;
39.其中,所述最优子句为子句与谓词连接后得到的最优子句;所述最优期望为评判子句与谓词连接的结果的评价标准,影响最终得出子句的权值大小。
40.本发明的有益技术效果是:
41.本发明将收集不同企业的基本信息作为数据集,构建完成一个知识图谱并基于图谱进行简单分析,包括:基于网络爬虫获取企业基本信息构建数据集;根据数据集实际情况进行知识抽取,确立实体、关系、属性并设计企业基本信息知识图谱schema;按照schema将数据保存图数据库完成知识图谱的构建。本发明完成了一个小型知识图谱的搭建,不仅制作了一个包含企业信息的“百科知识库”,并且利用谓词表示以及马尔可夫逻辑网对知识图谱缺失关系的节点进行了权重计算,这样对于新加入的缺失信息的企业,还可以利用计算结果对其各方面信息进行较为准确的预测。
附图说明
42.本发明可以通过参考下文中结合附图所给出的描述而得到更好的理解,所述附图连同下面的详细说明一起包含在本说明书中并且形成本说明书的一部分,而且用来进一步举例说明本发明的优选实施例和解释本发明的原理和优点。
43.图1是本发明实施例一种企业基本信息知识图谱的构建方法的流程示意图;
44.图2是本发明实施例中企业信息数据量分布示例图;
45.图3是本发明实施例中马尔可夫逻辑网结构学习算法的流程图。
具体实施方式
46.为了使本技术领域的人员更好地理解本发明方案,在下文中将结合附图对本发明的示范性实施方式或实施例进行描述。显然,所描述的实施方式或实施例仅仅是本发明一部分的实施方式或实施例,而不是全部的。基于本发明中的实施方式或实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式或实施例,都应当属于本发明保护的范围。
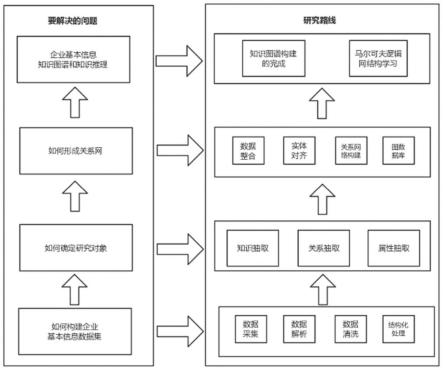
47.本发明主要研究基于企业基本信息所构建的知识图谱,整体设计方案就是知识图
谱的构建过程。首先,对于包含公司基本信息的网站进行数据爬虫,采集完成知识图谱所需的相关数据;其次,对构建完成的数据集进行知识抽取(实体抽取、关系抽取、属性抽取),从复杂的数据集中明确研究对象;然后,对得到的实体、关系、属性集合进行知识融合和知识合并,完成实体—关系—实体或者是实体—属性—属性值的三元组建立过程;最后,将得到的三元组关系存入图数据库中,完成知识图谱的本体构建过程,并利用构建完成的知识图谱与马尔可夫逻辑网结构学习结合,完成知识推理等其他工作。
48.本发明实施例提供一种企业基本信息知识图谱的构建方法,如图1所示,该方法包括以下步骤:
49.步骤一、知识图谱数据集的构建;
50.根据本发明实施例,通过爬虫程序对财经网站、学术论文及发明专利、维基百科,三种类型的网站进行数据采集并保存到关系型数据库管理系统-mysql,完成企业基本信息数据集的构建。
51.具体地,通过爬虫程序访问财经网站网页表格源数据,将网页上json格式的源数据在不进行解析的情况下直接保存到mysql,在保存之后,再编写java程序将爬取的数据进行解析并重新保存到mysql。本实施例中,总计完成了对418家公司13个页面基本信息的采集入库,累计爬取页面5434个,保存到mysql数据库数据16万余条,数据量分布如图2所示。
52.运用requests框架获得学术论文及发明专利网站数据,通过beautifulsoup包处理并提取学术论文及发明专利网站数据。在学术论文及发明专利网站上以公司名称作为关键词进行搜索,并将搜索结果作为公司学术论文及发明专利保存到数据库中。由于学术论文及发明专利的作者一般是多个人,除此之外,引用文献等内容同样为复数内容。因此,在公司学术论文及发明专利的储存上选择了mongodb数据库,将所有数据保存到同一个collection中,在爬取完成后,再实现从mongodb到mysql的迁移,以统一数据库的保存。
53.通过爬虫程序运用requests框架获得维基百科网页数据,通过beautifulsoup包处理并提取网站数据。通过修改对于不同公司对url中的query_txt内容进行修改完成对不同公司的专利信息爬虫url的构造,通过修改上述url中的p=1完成对不同页面的爬取,进而得到每个专利的url。将企业专利信息直接保存到关系数据库mysql中,将url、专利发明人、专利详情分别保存在数据表中。
54.步骤二、对mysql中的数据集进行筛选优化操作,让数据更容易进行接下来步骤的操作,包括数据表的分割与合并,数据字段的写入与修改等。
55.步骤三、知识图谱中实体-关系-属性的确立;对实体、关系、属性集合进行知识融合,完成实体-关系-实体或实体-属性-属性值的三元组建立过程,完成企业基本信息知识图谱的构建。
56.根据本发明实施例,将获得的公司简介、公司高管、持股信息、动态关键指标、公司收入、增长率、现金流状态、财务健康指标、资产周转率指标、分红派息、资产负债表、综合损益表以及现金流量表等信息作为数据源。选择上述数据源中的企业、企业高管、持股信息记录,基金以及机构作为知识图谱的实体类型;在数据集中,企业学术论文和企业专利信息拥有单独的数据表,学术论文也包括作者,标题等其他属性,所以在知识图谱中也应作为实体存在;其余数据将作为这些实体类型的属性在知识图谱中出现。
57.实体确立之后,需要对实体和实体之间添加关系,根据上一段中确立的实体为不
同实体之间添加关系,它们之间的关系具体如下:
58.企业—管理人员—企业高管;
59.企业—持有学术论文—企业学术论文;
60.企业—持有专利信息—企业专利信息;
61.企业—基金持股—基金持股记录;
62.基金持股记录—基金持股—基金;
63.企业—机构持股—机构持股记录;
64.机构持股记录—机构持股—机构。
65.具体实体类型的属性确立如下:
66.a.企业:公司名称、英文名称、董事长、主要股东、成立日期、主营业务、公司简介、员工人数、管理层人数、上市日期、发行量、发行价格、交易市场、联系电话、邮政编码、传真、电子邮箱、公司网址、注册地址、办公地址;
67.b.企业高管:高管姓名、高管职务、高管薪酬、高管年薪货币单位;
68.c.基金&机构持股信息记录:日期、持有者、持有份额、持股比例、变化率、份额变化、变化金额、占组合比;
69.d.企业专利信息:专利标题、专利申请编号、专利申请日期、专利公布日期、专利申请人;
70.e.企业学术论文:学术论文编号、学术论文标题、学术论文作者、论文摘要、公布日期。
71.根据数据集对实体类型、关系、属性进行确立之后,可以得出一个知识图谱schema,进一步按照设计将数据保存到图数据库。
72.知识在图数据库中的存储:在明确实体、关系、属性之后,将保存在关系数据库mysql中的相关知识转存到图数据库(janus graph)中,将实体作为图数据库的点存储,实体间关系则是以边的形式保存,属性则是作为点的属性保存。
73.步骤四、利用知识图谱的数据得到谓词逻辑,并结合马尔可夫逻辑网完成知识推理的过程。
74.根据本发明实施例,谓词逻辑又称谓词演算,其允许量化陈述的公式,是使用于数学、哲学、语言学及计算机科学中的一种形式系统。在谓词逻辑中,原子命题分解成个体词和谓词。个体词是可以独立存在的事或物,谓词则是用来刻画个体词的性质的词,即刻画事物之间的某种关系表现。在知识图谱产生知识的过程中,谓词演算是最好的表现形式。知识图谱可以提取到很多有价值的谓词。
75.谓词的表示形式在通常情况下如下:
“…
是
…”
,
“…
做
…”
,
“…
有
…
性质”,
“…
与
…
有
…
关系”等表示事物的性质或者动作或者属性或者关系的短语叫做谓词。而在知识图谱中,存在大量的三元组信息,基本上分为“实体—关系—实体”和“实体—属性—属性值”两种。这两种情况都可以转换成谓词表示。比如实体a“蒂姆
·
库克”和实体b“苹果公司”,已知在实体a与实体b间建立了关系manager,由实体a指向实体b。综合以上内容,便可以得到一个谓词表示manager(a,b),表示的具体内容则是“蒂姆
·
库克是苹果公司的管理者”。类似的,对于“实体—属性—属性值”也有同样的谓词表示,同样以蒂姆
·
库克为例,可以得到谓词表示position(a,c),其中实体a为“蒂姆
·
库克”,属性值c为“首席执行官”,表示的具体
内容则是“蒂姆
·
库克的职位是首席执行官”。
76.对于知识图谱中保存的知识,均可以通过相同的形式完成从知识图谱到谓词表示的转换。由于“实体—属性—属性值”类型的谓词表示在知识图谱中数量太多,这里只列举出所有“实体—关系—实体”类型的谓词表示,具体如下:
77.manager(a,b),实体类型a“企业高管”,实体类型b“企业”;
78.hold_paper(b,c),实体类型b“企业”,实体类型c“企业学术论文”;
79.hold_papent(b,d),实体类型b“企业”,实体类型d“企业专利信息”;
80.fund_holding(e,b),实体类型e“基金持股记录”,实体类型b“企业”;
81.institution_holding(f,b),实体类型f“机构持股记录”,实体类型b“企业”;
82.fund_holding(g,e),实体类型g“基金”,实体类型e“基金持股记录”;
83.institution_holding(h,f),实体类型h“机构”,实体类型f“机构持股记录”;
84.author(i,c),实体类型i“学术论文作者”,实体类型c“企业学术论文”;
85.inventor(j,d),实体类型j“专利发明人”,实体类型d“企业专利信息”。
86.马尔可夫逻辑网是将马尔可夫网络与一阶逻辑相结合的统计关系学习模型,是一种基于概率图模型的马尔可夫网。它的基本思想是在结合一阶逻辑规则的同时,让其中硬性规则有所松弛,即针对一个特定问题,当违反了其中的一条规则时,其存在的可能性将降低,但可能性不会降为0。而当一个问题违反的规则很少时,这个问题存在的可能性则会变大。而对于所描述的约束程度,理论上可以用权值表示,为所制定规则加上一个特定的权值并用此权值反映其对满足该规则问题的约束力。如果一个规则的权重越大,对于不同问题而言,满足和不满足该规则所导致它们之间的差异就越大。在权值无限大后,通过马尔可夫逻辑网得出的结果会向通过一阶逻辑知识得出的结果靠拢。马尔科夫逻辑网中的所有权重都表示了满足知识库的所有事件的一个均匀分布,所有蕴含问题可以通过计算问题规则的概率是否为1来判断。
87.马尔可夫逻辑网结构学习的具体算法流程图如图3所示,具体为:
88.获取子句集合;
89.初始化学习权重和最优期望值;设置标志位等于0;
90.寻找最优子句,如果最优子句为空,则标志位加1,继续寻找;如果最优子句不为空,则添加最优子句到马尔可夫逻辑网中,并计算最优期望;
91.判断标志位的值是否等于2,等于2则结束,若不等于2则继续寻找最优子句。
92.其中,所述最优子句(bestclause)为子句与谓词连接后得到的最优子句;所述最优期望(bestscore)为评判子句与谓词连接的结果的评价标准,影响最终得出子句的权值大小。
93.子句集合clauses表示马尔可夫逻辑网mln和谓词逻辑p中的全部子句。
94.马尔可夫逻辑网结构学习算法的伪代码如下:
95.输入:谓词集合p,马尔可夫逻辑网mln,企业知识库ekb
96.输出:马尔可夫逻辑网mln
[0097][0098]
利用由知识图谱得到的谓词集合p,马尔可夫逻辑网mln,企业知识库ekb,通过马尔可夫逻辑网结构学习算法便可以完成从知识图谱中推理获取知识的过程。下面列举几个结果。
[0099]
1)某企业与该企业所持某专利发明人的关系:
[0100]
企业专利是企业的重要基本信息,但是专利有可能是企业conpany从专利发明人inventor购买得到,也有可能是专利发明人inventor是企业员工employee发明的专利patent作为企业财富所属于企业。这一问题模型符合马尔可夫逻辑网模型,利用知识图谱,可以得出某专利发明人是其专利所属企业的职员这一事件的权重为3.3,其子句表示形式为:
[0101][0102]
2)某企业员工发明专利的关键词与企业研究方向的关系:
[0103]
某企业company雇佣员工employee,且该员工发明专利patent,patent的关键词keyword,利用马尔可夫逻辑网结构学习和知识图谱即可推出公司的研究方向跟关键词keyword有关这一事件的权重为2.9,其子句表示形式为:
[0104][0105]
3)某企业员工发表学术论文的关键词与企业研究方向的关系:
[0106]
某企业company雇佣员工employee,且该员工发表论文paper,paper的关键词keyword,利用马尔可夫逻辑网结构学习和知识图谱即可推出公司的研究方向跟关键词keyword有关这一事件的权重为5.6,其子句表示形式为:
[0107][0108]
企业基本信息作为一个企业最重要的信息,不仅可以给企业提供合作伙伴的详细信息运营状况、失信记录、企业资产、专利申请情况、经营规模、财务信息、高管信息、违规记录等企业全方位的信息,还可以作为自身的知识库,了解自身的运营和科研状况,为自身制定发展规划。
[0109]
本发明通过对400余家美国大型企业的基本信息的采集,通过知识抽取,保存图数据库等步骤完成了一个小型知识图谱的搭建,不仅制作了一个包含企业信息的“百科知识库”,并且利用谓词表示以及马尔可夫逻辑网对知识图谱缺失关系的节点进行了权重计算,这样对于新加入的缺失信息的企业,可以利用计算结果对其各方面信息进行较为准确的预测。
[0110]
本发明另一实施例提供一种企业基本信息知识图谱的构建系统,该系统包括:
[0111]
数据集获取模块,其配置成构建包含多个企业的企业信息、企业学术论文信息、企业专利信息的数据集;
[0112]
知识图谱构建模块,其配置成在数据集中选择知识图谱架构中的实体、属性及实体间的关系;对实体、关系、属性集合进行知识融合,完成实体-关系-实体或实体-属性-属性值的三元组建立过程,完成企业基本信息知识图谱的构建。
[0113]
本实施例中,可选地,还包括知识推理模块,其配置成利用构建完成的知识图谱,将三元组转换成谓词表示,并与马尔可夫逻辑网结构结合,完成知识推理。
[0114]
本实施例中,可选地,知识图谱构建模块中在数据集中选择企业、企业高管、持股信息记录、基金、机构、企业学术论文、企业专利信息作为知识图谱的实体,持股信息记录包括基金持股信息记录和机构持股信息记录;在数据集中选择各个实体的属性确定如下:
[0115]
a.企业:公司名称、英文名称、董事长、主要股东、成立日期、主营业务、公司简介、员工人数、管理层人数、上市日期、发行量、发行价格、交易市场、联系电话、邮政编码、传真、电子邮箱、公司网址、注册地址、办公地址;
[0116]
b.企业高管:高管姓名、高管职务、高管薪酬、高管年薪货币单位;
[0117]
c.基金持股信息记录或机构持股信息记录:日期、持有者、持有份额、持股比例、变化率、份额变化、变化金额、占组合比;
[0118]
d.企业学术论文:学术论文编号、学术论文标题、学术论文作者、论文摘要、公布日期;
[0119]
e.企业专利信息:专利标题、专利申请编号、专利申请日期、专利公布日期、专利申请人。
[0120]
本实施例中,可选地,知识图谱构建模块中不同实体间的关系具体确定如下:企业和企业高管之间的关系为管理人员;企业和企业学术论文之间的关系为持有学术论文;企业和企业专利信息之间的关系为持有专利信息;企业和基金持股信息记录之间的关系为基金持股;企业和机构持股信息记录之间的关系为机构持股;基金和基金持股信息记录之间的关系为基金持股;机构和机构持股信息记录之间的关系为机构持股。
[0121]
本实施例中,可选地,知识推理模块中马尔可夫逻辑网结构的学习流程为:
[0122]
获取子句集合;
[0123]
初始化学习权重和最优期望值;设置标志位等于0;
[0124]
寻找最优子句,如果最优子句为空,则标志位加1,继续寻找;如果最优子句不为空,则添加最优子句到马尔可夫逻辑网中,并计算最优期望;
[0125]
判断标志位的值是否等于2,等于2则结束,若不等于2则继续寻找最优子句;
[0126]
其中,最优子句为子句与谓词连接后得到的最优子句;最优期望为评判子句与谓词连接的结果的评价标准,影响最终得出子句的权值大小。
[0127]
本发明实施例所述一种企业基本信息知识图谱的构建系统的功能可以由前述一种企业基本信息知识图谱的构建方法说明,因此本实施例未详述部分,可参见以上方法实施例,在此不再赘述。
[0128]
尽管根据有限数量的实施例描述了本发明,但是受益于上面的描述,本技术领域内的技术人员明白,在由此描述的本发明的范围内,可以设想其它实施例。对于本发明的范围,对本发明所做的公开是说明性的,而非限制性的,本发明的范围由所附权利要求书限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。