1.本发明涉及计算机技术中的推荐系统领域,具体涉及一种基于学习者偏好与群体偏好的学习资源推荐方法及系统。
背景技术:
2.学习资源推荐过程中,准确地学习者个性化偏好建模与学习资源建模是高质量推荐的前提和基础。传统的学习资源推荐方法未考虑过教师在推荐过程的作用,且传统的学习者个性化偏好建模通常将学习者整个信息作为用户偏好配置文件,在学习者个性化偏好建模过程中没有考虑学习者的偏好是动态地随着时间发生变化。学习者进行学习时,历史交互学习资源也在不断发生变化,如何获取用户短期内的偏好并将其与长期偏好结合到一起成为学习者个性化建模的的关键所在,同时,如何使用教师特征提高推荐精度也是一个需要思考的问题。
技术实现要素:
3.为了解决上述问题,本发明提供一种基于学习者偏好与群体偏好的学习资源推荐方法,通过对学习者进行个性化偏好建模,结合学习者喜欢的教师的特征,推荐更加适合学习者的学习资源,最终实现提高学习者的学习质量的目的。
4.为了达到上述目的,本发明所采用的技术方案为:一种基于学习者偏好与群体偏好的学习资源推荐方法,包括以下步骤:
5.步骤1,获取学习者信息、教师信息以及学习资源特征信息;
6.步骤2,根据学习者信息,使用基于时间的注意力机制捕捉学习者长期偏好,构建学习者长期偏好模型
7.步骤3,根据学习者信息,使用长短期记忆神经网络,从学习者信息中学习者的短期历史交互学习资源的行为序列中提取用户短期兴趣偏好,构建学习者短期偏好模型
8.步骤4,通过注意力机制,得到学习者长期偏好与短期偏好所占权重,融合学习者的长期偏好模型与短期偏好模型得到学习者的个人偏好模型如下:
[0009][0010]
其中,tanh为激活函数,w
t
、w为偏执矩阵;
[0011]
步骤5,通过狄利克雷概率聚类算法,将所有学习者划分为不同的群体,将学习者所属不同群体构建成为学习者群体偏好模型
[0012]
步骤6,基于注意力机制,将学习者个人偏好模型与学习者群体偏好模型融合,得到学习者模型;使用注意力机制为学习者个人偏好模型与学习者群体偏好模型分配不同的权重,将两者融合,得到最终的学习者模型pu,如下:
[0013]
[0014]
其中,tanh为激活函数,w
t
、w为偏执矩阵;
[0015]
步骤7,学习资源特征信息包括生成性信息和特征信息将学习资源的生成性信息和特征信息相加得到目标学习资源特征信息模型
[0016]
步骤8,根据学习资源特征信息中的学习资源知识点信息,使用基于注意力机制的图卷积神经注意网络构建学习资源领域知识模型
[0017]
步骤9,基于注意力机制,将步骤7得到的学习资源特征信息模型与步骤8得到学习资源领域知识模型融合,得到学习资源模型pr,具体的,使用注意力机制为学习资源特征信息模型和领域知识模型分配不同的权重,将两者融合,得到学习资源模型pr,方法如下:
[0018][0019]
其中,tanh为激活函数,w
t
、w为偏执矩阵;
[0020]
步骤10,将学习者模型pu与学习资源模型pr连接,使用多层深度神经网络,获取学习者与学习资源的交互特征,将学习者与学习资源的交互特征作为第一目标学习资源的推荐分数y
ur
,计算过程如下:
[0021][0022]
其中,为权重矩阵,b
l
是神经网络第l层的偏差,[pu,pr]为学习者模型pu和学习资源模型pr的连接,l为神经网络模型的层数;
[0023]
步骤11,根据收集的学习者信息和教师信息,对目标学习者和老师使用余弦相似度算法进行相似度计算,得到与学习者相似度最高的教师;
[0024]
步骤12,使用卷积神经网络,将相似度最高的教师与目标学习资源进行匹配,得到第二目标学习资源的推荐分数y
tr
;
[0025]
步骤13,将第一目标学习资源的推荐分数y
ur
与第二目标学习资源推荐分数y
tr
相加,得到目标学习资源最终的推荐分数yr;
[0026]
步骤14,按照推荐分数yr高低将其排序,将分数最高的前n个学习资源依次推荐给学习者。
[0027]
步骤1中,所述学习者信息指学习者描述信息、学习者与学习资源的交互信息,学习资源特征信息包括学习资源描述信息、学习资源特征信息;教师信息指教师的性别、语速快慢以及课堂节奏;步骤7中,生成性信息包括学习资源的使用记录与评分反馈;特征信息包括学习资源的难易程度、应用场景、内容主题、格式信息、学科类别、资源类型、资源id以及资源标题,将学习资源的生成性信息与特征信息相加得到目标学习资源特征信息模型
[0028]
步骤2具体如下:
[0029]
步骤2.1,由学习者信息得到学习者和学习资源的交互矩阵以及交互时间矩阵间矩阵m为学习者的总数,n为学习资源的总数,交互矩阵r的行作为学习者偏好向量
[0030]
步骤2.2,使用线性嵌入将目标学习资源的高维一热向量转换为低维实值向量,如
下:
[0031][0032]
其中,uj为项目j的交互向量,对应于r的第j列;wu是项目编码矩阵;使用相同的嵌入方法,得到目标学习资源的时间嵌入向量,如下:
[0033][0034]
其中,w
t
是时间编码矩阵,tsj是项目j的交互时间与当前时间的时间间隔,计算方法如下:
[0035]
tsj=t-tj[0036]
其中,tj是学习者与项目j的交互时间戳,t是当前时间戳;tj和t都来自交互时间矩阵t;
[0037]
步骤2.3,通过步骤2.2得到目标学习资源、历史交互学习资源及其交互时间,将三者连接到一起作为深度神经网络模型的输入,计算每个历史交互学习资源初阶注意力权重;使用两层神经网络作为注意机制网络,初阶注意力分数计算如下:
[0038][0039]
其中,w
11
、w
12
、w
13
和b1、b2是注意网络的权重矩阵和偏差;tanh为激活函数;
[0040]
通过softmax函数归一化得到历史交互学习资源的最终注意权重a(j),计算如下:
[0041][0042]
其中,rk(u)是用户u历史交互的k个学习资源;
[0043]
步骤2.4,将学习资源的注意力分数作为学习资源的权重,使用历史交互学习资源的嵌入向量的加权和作为长期用户偏好模型
[0044][0045]
a(j)是历史交互学习资源j的初阶注意力分数,为历史交互学习资源j的嵌入向量。
[0046]
步骤3中,根据学习者信息,得到学习者短期交互的学习资源行为序列u={u1,u2,...,u
t
},t为短期内交互的学习资源数量,将序列u作为长短期神经网络的嵌入,长短期神经网络的核心部分是单元状态传递,经过单元状态更q新后,再计算得到当前时刻的隐藏层h
t
和输出值o
t
,通过长短期记忆神经网络在当前t时刻获取之前任意时刻的历史信息,将得到的最后时刻的输出作为用户的短期偏好模型
[0047]
步骤5具体为:
[0048]
学习者集合u={u1,u2,...,un},类型集合c={c1,c2,...,ck},集合u中的每个u看作一个单词序列wi表示第i个单词,设u有n个单词,u中涉及的所有不同单词组成一个大集合t,t={t1,t2,...,tj},
[0049]
学习者集合u作为聚类算法的输入,聚类成k个类型,t中共包含j个单词:
[0050]
①
对每个u中的学习者un,对应到不同群体的概率其中表示un对应c中第k个类型的概率,计算过程如下:
[0051][0052]
其中表示un中对应c中第ck个类型的词的数目,n是un中所有词的总数,
[0053]
②
对每个c中的群体ck,生成不同单词的概率其中,表示ck生成t中第j个单词的概率,
[0054][0055]
其中表示群体ck含有t中第j个单词的数目,n表示ck中的所有单词在t中的数目,lda的核心公式如下:
[0056][0057]
最终训练得到两个结果向量和通过当前的和给出学习者un中出现单词w的概率,其中,p(t|un)利用计算得到,利用计算得到,通过当前的和计算学习者un描述中的一个单词对应任意一个群体ck时的p(t|un),然后根据单词的和更新这个词对应的群体;
[0058]
通过上述的狄利克雷聚类算法得到学习者un包含的学习者类别,如下:
[0059][0060]
是学习者包含的不同的学习者类别,pi指所属不同类别的概率权重,得到学习者群体偏好模型
[0061]
步骤8具体如下:
[0062]
在知识图谱上使用图卷积神经网络,经过传播过程和聚合过程,将知识点特征汇集于目标学习资源;在传播过程中,学习资源从相连相邻的知识点节点中获得它们的特征信息,在聚合过程中,将所有相邻知识点节点的特征信息汇聚到一起,得到目标学习资源节点的领域知识嵌入特征;
[0063]
上述过程为一层卷积运算,在第一层卷积运算结束后就能将目标学习资源节点的所有相连相邻知识点节点的特征信息整合到一起,在第二层卷积运算结束后,将相邻的相邻知识点节点的特征信息继续融合到目标学习资源节点中;
[0064]
知识图谱中,通过对不同关系的节点赋予不同的权重值,区分不同关系的节点对学习资源的重要性赋值,具体如下:
[0065]
聚合具有相同关系的相邻节点,
[0066]
运用注意力机制,通过两层神经网络计算不同关系类型的相邻知识点节点的注意力分数,获得权重βr,
[0067]
将目标学习资源节点的不同关系的相邻节点聚合,得到目标学习资源的领域知识模型
[0068]
步骤12中,卷积神经网络包含输入层、卷积层、池化层、全局平局池化层以及输出
层,
[0069]
在输入层,根据所收集的教师信息,使用大规模word2vec向量计算教师的三个特征与待选学习资源之间的语义相似度,构成三层输入相似度特征矩阵f,
[0070]
在卷积层,采用三个大小为2*2*3的滤波器单步长对输入层的相似度矩阵进行三通道卷积扫描,将每个滤波器中的每层元素与每层输入矩阵感受野中对应位置的元素相乘求和,最后将三层卷积结果总和作为卷积输出矩阵和
[0071]
在池化层,将卷积层中得到的特征矩阵f1,作为池化层的输入,通过最大池化操作,将卷积层中每个特征矩阵感受野中最大的相似度元素作为池化的输出特征,对三个输入特征矩阵进行池化操作,构成池化输出矩阵和
[0072]
在全局平均池化层,对池化后的每一层特征矩阵进行全局平均池化,整合全局信息,得到三个特征矩阵的平均值a、b和c;
[0073]
在输出层,将所得特征值的加权和作为教师与待选学习资源的匹配得分yr。
[0074]
另一方面,本发明提供一种学习资源推荐系统,包括信息获取模块、学习者模型构建模块、学习资源模型构建模块、学习资源模型构建模块、推荐分数获取模块以及推荐模块;
[0075]
信息获取模块用于获取学习者信息、教师信息以及学习资源特征信息;
[0076]
学习者模型构建模块用于根据学习者信息,使用基于时间的注意力机制捕捉学习者长期偏好,构建学习者长期偏好模型
[0077]
根据学习者信息,使用长短期记忆神经网络,从学习者信息中学习者的短期历史交互学习资源的行为序列中提取用户短期兴趣偏好,构建学习者短期偏好模型
[0078]
通过注意力机制,得到学习者长期偏好与短期偏好所占权重,融合学习者的长期偏好模型与短期偏好模型得到学习者的个人偏好模型如下:
[0079][0080]
其中,tanh为激活函数,w
t
、w为偏执矩阵;
[0081]
通过狄利克雷概率聚类算法,将所有学习者划分为不同的群体,将学习者所属不同群体构建成为学习者群体偏好模型
[0082]
基于注意力机制,将学习者个人偏好模型与学习者群体偏好模型融合,得到学习者模型;使用注意力机制为学习者个人偏好模型与学习者群体偏好模型分配不同的权重,将两者融合,得到最终的学习者模型pu,如下:
[0083][0084]
其中,tanh为激活函数,w
t
、w为偏执矩阵;
[0085]
学习资源模型构建模块用于将学习资源的生成性信息和特征信息相加得到目标学习资源特征信息模型
[0086]
根据学习资源特征信息中的学习资源知识点信息,使用基于注意力机制的图卷积神经注意网络构建学习资源领域知识模型
[0087]
基于注意力机制,将学习资源特征信息模型与学习资源领域知识模型融合,得到学习资源模型pr,具体的,使用注意力机制为学习资源特征信息模型和领域知识模型分配不同的权重,将两者融合,得到学习资源模型pr,如下:
[0088][0089]
其中,tanh为激活函数,w
t
、w为偏执矩阵;
[0090]
推荐分数获取模块用于将学习者模型pu与学习资源模型pr连接,使用多层深度神经网络,获取学习者与学习资源的交互特征,将学习者与学习资源的交互特征作为第一目标学习资源的推荐分数y
ur
,计算过程如下:
[0091][0092]
其中,为权重矩阵,b
l
是神经网络第l层的偏差,[pu,pr]为学习者模型pu和学习资源模型pr的连接,l为神经网络模型的层数;
[0093]
根据收集的学习者信息和教师信息,对目标学习者和老师使用余弦相似度算法进行相似度计算,得到与学习者相似度最高的教师;
[0094]
使用卷积神经网络,将相似度最高的教师与目标学习资源进行匹配,得到第二目标学习资源的推荐分数y
tr
;
[0095]
将第一目标学习资源的推荐分数y
ur
与第二目标学习资源推荐分数y
tr
相加,得到目标学习资源最终的推荐分数yr;
[0096]
推荐模块用于按照推荐分数yr高低将其排序,将分数最高的前n个学习资源依次推荐给学习者。
[0097]
另外提供一种计算机设备,包括处理器和存储器,存储器中存储可执行程序,处理器执行所述可执行程序时,能执行本发明所述的学习资源推荐方法。
[0098]
本发明同时提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时,能实现本发明所述的学习资源推荐方法。
[0099]
与现有学习资源推荐方法相比,本发明至少具有以下优点:
[0100]
本发明在学习资源推荐上,兼顾学习者与学习资源的特征建模,实现了个性化推荐;将教师的特征融入推荐方法中,提高推荐的精度;在学习者建模中,考虑了学习者偏好不断变化的情况,同时考虑学习者的群体偏好,实现学习者个性化偏好的精准建模;在学习资源建模中,通过知识图谱,融合学习资源的多种知识点特征,实现学习资源特征的精准建模;在学习者模型以及学习资源模型的融合过程中,采用注意力机制,赋予不同模型不同的权重,一定程度缓解了因为模型权重分配不均带来的推荐精准性下降的问题。
附图说明
[0101]
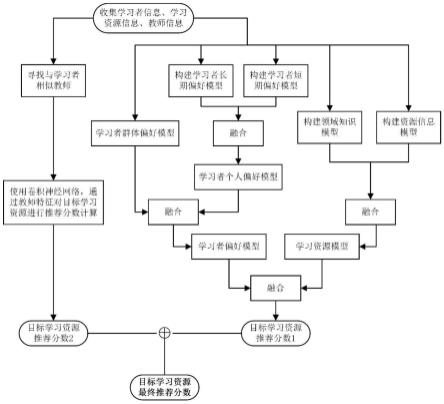
图1是基于学习者个人偏好与群体偏好推荐流程图。
具体实施方式
[0102]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施
例,都属于本发明保护的范围。
[0103]
在本发明的描述中,需要理解的是,术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
[0104]
图1是基于学习者个人偏好与群体偏好推荐流程图,现对本发明的实施方式进行详细说明。
[0105]
步骤1,收集学习者信息、学习资源特征信息、教师信息,学习者信息指学习者描述信息、学习者与学习资源的交互信息,学习资源特征信息包括学习资源描述信息、学习资源特征信息;教师信息指教师的性别、语速快慢、课堂节奏三个信息。
[0106]
步骤2,根据收集的学习者信息,使用基于时间的注意力机制捕捉学习者长期偏好,构建学习者长期偏好模型步骤如下:
[0107]
步骤2.1,由学习者信息得到学习者和学习资源的交互矩阵以及交互时间矩阵间矩阵m代表学习者的总数,n代表学习资源的总数,交互矩阵r的行作为学习者偏好向量
[0108]
步骤2.2,使用线性嵌入将目标学习资源的高维一热向量转换为低维实值向量,如下:
[0109][0110]
其中,uj为项目j的交互向量,对应于r的第j列;wu是项目编码矩阵。使用相同的嵌入方法,得到目标学习资源的时间嵌入向量,如下:
[0111][0112]
其中,w
t
是时间编码矩阵,tsj是项目j的交互时间与当前时间的时间间隔,计算方法如下:
[0113]
tsj=t-tj[0114]
其中,tj是学习者与项目j的交互时间戳,t是当前时间戳。tj和t都来自交互时间矩阵t。
[0115]
步骤2.3,通过步骤2.2得到目标学习资源、历史交互学习资源及其交互时间,将三者连接到一起作为深度神经网络模型的输入,计算每个历史交互学习资源初阶注意力权重。本发明使用两层神经网络作为注意机制网络,初阶注意力分数计算如下:
[0116][0117]
其中,w
11
、w
12
、w
13
和b1、b2是注意网络的权重矩阵和偏差;tanh为激活函数。
[0118]
通过softmax函数归一化得到历史交互学习资源的最终注意权重,计算如下:
[0119][0120]
其中,rk(u)是用户u历史交互的k个学习资源。
[0121]
步骤2.4,将学习资源的注意力分数作为学习资源的权重,使用历史交互学习资源的嵌入向量的加权和作为长期用户偏好模型
[0122][0123]
a(j)是历史交互学习资源j的初阶注意力分数,为历史交互学习资源j的嵌入向量。
[0124]
步骤3,根据收集的学习者信息,使用长短期记忆神经网络,从学习者的短期历史交互学习资源的行为序列中,提取用户短期兴趣偏好,构建学习者短期偏好模型根据学习者信息,得到学习者短期交互的学习资源行为序列u={u1,u2,...,u
t
},t为短期内交互的学习资源数量。将序列u作为长短期神经网络的嵌入,长短期神经网络的核心部分是单元状态传递,单元状态更新的计算过程如下:
[0125][0126]
其中,f
t
是遗忘门,c
t-1
代表前一单元状态,r
t
是记忆门,是当前单元的候选状态。遗忘门f
t
的作用是决定前一单元c
t-1
中哪些不重要的特征将被遗忘,r
t
作用是决定当前候选单元中哪些重要的特征被留下,遗忘门f
t
、记忆门r
t
以及的当前候选单元状态计算过程如下:
[0127]ft
=σ(wf[h
t-1
,u
t
] bf)
[0128]rt
=σ(wr[h
t
,u
t
] br)
[0129][0130]
在t时刻,将学习资源向量u
t
,前一时刻的单元状态c
t-1
和前一时刻的隐藏层h
t-1
作为输入,带入上述公式。其中,wf、wr、wc分别代表遗忘门,记忆门,当前候选单元状态的偏执矩阵,bf、bj、b
x
为对应的偏执项。遗忘门权重参数中的σ代表sigimoid神经网络层,函数将结果映射到[0,1],其结果代表信息的留存程度,0代表信息全部丢弃,1代表信息全部留存。经过单元状态更q新后,再由下面两个公式得到当前时刻的隐藏层h
t
和输出值o
t
,计算过程如下:
[0131]ot
=σ(wo[h
t-1
,u
t
] bo)
[0132]ht
=o
t
*tanh(c
t
)
[0133][0134]
通过上述方法,长短期记忆神经网络便可以在当前t时刻获取之前任意时刻的历史信息。最终将得到的最后时刻的输出作为用户的短期兴趣特征
[0135]
步骤4,通过注意力机制,得到学习者长期偏好与短期偏好所占权重,融合学习者的长期偏好模型与短期偏好模型得到学习者的个人偏好模型方法如下:
[0136][0137]
其中,tanh为激活函数,w
t
、w为偏执矩阵。
[0138]
步骤5,学习者的偏好与其所处群体也具有一定关系,通过狄利克雷概率聚类算法,得到学习者所属群体,学习者所属群体便代表学习者的群体偏好,其中,一个学习者可能属于多个不同的群体,将学习者所属不同群体构建成为学习者群体偏好模型学习者
集合u={u1,u2,...,un},类型集合c={c1,c2,...,ck}。集合u中的每个u看作一个单词序列}。集合u中的每个u看作一个单词序列wi表示第i个单词,设u有n个单词。u中涉及的所有不同单词组成一个大集合t,t={t1,t2,...,tj}。
[0139]
学习者集合u作为聚类算法的输入(假设聚类成k个类型,t中共包含j个单词):
[0140]
①
对每个u中的学习者un,对应到不同群体的概率其中表示un对应c中第k个类型的概率,计算过程如下:
[0141][0142]
其中表示un中对应c中第ck个类型的词的数目,n是un中所有词的总数。
[0143]
②
对每个c中的群体ck,生成不同单词的概率其中,表示ck生成t中第j个单词的概率,
[0144][0145]
其中表示群体ck含有t中第j个单词的数目,n表示ck中的所有单词在t中的数目。lda的核心公式如下:
[0146][0147]
最终训练得到两个结果向量和通过当前的和给出了学习者un中出现单词w的概率。其中,p(t|un)利用计算得到,利用计算得到。通过当前的和可计算学习者un描述中的一个单词对应任意一个群体ck时的p(t|un),然后根据单词的和来更新这个词对应的群体。同时,如果更新改变了单词所对应的群体ck,也会反过来影响θu和φc。
[0148]
通过上述的狄利克雷聚类算法得到学习者un包含的学习者类别,如下:
[0149][0150]
是学习者包含的不同的学习者类别,pi指所属不同类别的概率权重。得到学习者群体偏好模型
[0151]
步骤6,基于注意力机制,将步骤4得到的学习者个人偏好模型与步骤5得到学习者群体偏好模型融合,得到学习者模型。构建学习者偏好模型采用与步骤4相同的方法,即使用注意力机制为学习者个人偏好模型与学习者群体偏好模型分配不同的权重,从而将两者融合,得到最终的学习者模型,方法如下:
[0152][0153]
其中,tanh为激活函数,w
t
、w为偏执矩阵。
[0154]
步骤7,根据收集到的学习资源特征信息,建立学习资源特征信息模型。学习资源特征信息模型包括两个方面,分别是生成性信息和特征信息生成性信息包括学习资源的使用记录与评分反馈;特征信息包括学习资源的难易程度、应用场景、内容主题、格式信息、学科类别、资源类型、资源id、资源标
题。将学习资源的生成性信息与特征信息相加得到目标学习资源特征信息模型
[0155]
步骤8,根据收集到的学习资源知识点信息,使用基于注意力机制的图卷积神经注意网络构建学习资源领域知识模型步骤如下:
[0156]
步骤8.1,根据学习资源知识点信息建立知识图谱。知识图谱由三元组学习资源—关系—知识点(h,r,t)构成。其中,h是头节点,代表目标学习资源的id;t是尾节点,代表学习资源所含知识点的id,r代表学习资源与知识点之间的关系类型,关系类型包括教材大纲、专家经验、学科、学段、领域五种类型。
[0157]
步骤8.2,在知识图谱上使用图卷积神经网络,将知识点特征汇集于目标学习资源。卷积神经网络主要包含传播和聚合两个操作。在传播过程中,学习资源可以从相连相邻的知识点节点中获得它们的特征信息。在聚合过程中,将所有相邻知识点节点的特征信息汇聚到一起,得到目标学习资源节点的领域知识嵌入特征。上述过程仅代表一层卷积运算,在第一层卷积运算结束后就能将目标学习资源节点的所有相连相邻知识点节点的特征信息整合到一起,在第二层卷积运算结束后,可以把相邻的相邻知识点节点的特征信息继续融合到目标学习资源节点中。
[0158]
知识图谱中,目标学习资源与相连知识点有不同的关系,通过对不同关系的节点赋予不同的权重值,区分不同关系的节点对学习资源的重要性。赋值步骤如下:
[0159]
步骤8.2.1,聚合具有相同关系的相邻节点,聚合过程如下:
[0160][0161]
其中,tr表示关系r的相邻向量的平均值,w
1(ι)
为权重矩阵。ni(r)是关系类型为r的相邻节点的集合,c
i,r
=|ni(r)|,是关系类型为r的相邻节点的数量。
[0162]
步骤8.2.2,运用注意力机制,通过两层神经网络计算不同关系类型的相邻知识点节点的注意力分数,获得权重βr,计算过程如下:
[0163][0164]
其中,是关系类型r的相邻节点的注意力得分。w1为权重矩阵。是一个连接算子,b1和b2是偏差。指目标学习资源节点在l层知识图网络中的模型,σ为sigimoid激活函数。
[0165]
通过softmax函数归一化得到不同关系类型的相邻知识点节点的最终注意力分数,计算过程如下:
[0166][0167]
步骤8.2.3,将目标学习资源节点的不同关系的相邻节点聚合,计算过程如下:
[0168][0169]
其中,为目标学习资源节点在l 1层知识图网络中的模型。给定图卷积网络
的层数为3层,经过3层图卷积网络的传播和聚合,得到目标学习资源的领域知识模型
[0170]
步骤9,基于注意力机制,将步骤7得到的学习资源特征信息模型与步骤8得到学习资源领域知识模型融合,得到学习资源模型pr。使用注意力机制为学习资源特征信息模型和领域知识模型分配不同的权重,从而将两者融合,得到学习资源模型,方法如下:
[0171][0172]
其中,tanh为激活函数,w
t
、w为偏执矩阵。
[0173]
步骤10,将步骤6中的学习者模型与步骤9中的学习资源模型连接,使用多层深度神经网络,获取学习者与学习资源的交互特征,计算过程如下:
[0174][0175]
其中,为权重矩阵,b
l
是神经网络第l层的偏差,[pu,pr]为学习者模型pu和学习资源模型pr的连接,l为神经网络模型的层数。
[0176]
步骤11,根据收集的学习者信息和教师信息,对目标学习者和老师使用余弦相似度算法进行相似度计算,得到与学习者相似度最高的教师,计算过程如下:
[0177][0178]
其中,u代表目标学习者,t代表教师。
[0179]
步骤12,使用卷积神经网络,将相似度最高的教师与目标学习资源进行匹配,得到目标学习资源的推荐分数y
tr
。卷积神经网络主要包含五层,分别是输入层、卷积层、池化层、全局平局池化层以及输出层。
[0180]
步骤12.1,在输入层,根据所收集的教师信息,使用大规模word2vec向量计算教师的三个特征与待选学习资源之间的语义相似度,构成三层输入相似度特征矩阵f。
[0181]
步骤12.2,在卷积层,采用三个大小为2*2*3的滤波器单步长对输入层的相似度矩阵进行三通道卷积扫描,将每个滤波器中的每层元素与每层输入矩阵感受野中对应位置的元素相乘求和,最后将三层卷积结果总和作为卷积输出矩阵
[0182]
步骤12.3,在池化层,将卷积层中得到的特征矩阵f1,作为池化层的输入。通过最大池化操作,将卷积层中每个特征矩阵感受野中最大的相似度元素作为池化的输出特征,对三个输入特征矩阵进行池化操作,构成池化输出矩阵
[0183]
步骤12.4,在全局平均池化层,对池化后的每一层特征矩阵进行全局平均池化,整合全局信息,得到三个特征矩阵的平均值a、b、c。
[0184]
步骤12.5,在输出层,将所得特征值的加权和作为教师与待选学习资源的匹配得分yr。
[0185]
步骤13,将步骤10得到的目标学习资源的推荐分数y
ur
与步骤12得到的目标学习资源推荐分数y
tr
相加,得到最终的目标学习资源推荐分数yr;
[0186]
步骤14,将分数最高的前n个学习资源依次推荐给学习者。
[0187]
同时,本发明提供一种学习资源推荐系统,包括信息获取模块、学习者模型构建模块、学习资源模型构建模块、学习资源模型构建模块、推荐分数获取模块以及推荐模块;
[0188]
信息获取模块用于获取学习者信息、教师信息以及学习资源特征信息;
[0189]
学习者模型构建模块用于根据学习者信息,使用基于时间的注意力机制捕捉学习者长期偏好,构建学习者长期偏好模型
[0190]
根据学习者信息,使用长短期记忆神经网络,从学习者信息中学习者的短期历史交互学习资源的行为序列中提取用户短期兴趣偏好,构建学习者短期偏好模型
[0191]
通过注意力机制,得到学习者长期偏好与短期偏好所占权重,融合学习者的长期偏好模型与短期偏好模型得到学习者的个人偏好模型如下:
[0192][0193]
其中,tanh为激活函数,w
t
、w为偏执矩阵;
[0194]
通过狄利克雷概率聚类算法,将所有学习者划分为不同的群体,将学习者所属不同群体构建成为学习者群体偏好模型
[0195]
基于注意力机制,将学习者个人偏好模型与学习者群体偏好模型融合,得到学习者模型;使用注意力机制为学习者个人偏好模型与学习者群体偏好模型分配不同的权重,将两者融合,得到最终的学习者模型pu,如下:
[0196][0197]
其中,tanh为激活函数,w
t
、w为偏执矩阵;
[0198]
学习资源模型构建模块用于将学习资源的生成性信息和特征信息相加得到目标学习资源特征信息模型
[0199]
根据学习资源特征信息中的学习资源知识点信息,使用基于注意力机制的图卷积神经注意网络构建学习资源领域知识模型
[0200]
基于注意力机制,将学习资源特征信息模型与学习资源领域知识模型融合,得到学习资源模型pr,具体的,使用注意力机制为学习资源特征信息模型和领域知识模型分配不同的权重,将两者融合,得到学习资源模型pr,如下:
[0201][0202]
其中,tanh为激活函数,w
t
、w为偏执矩阵;
[0203]
推荐分数获取模块用于将学习者模型pu与学习资源模型pr连接,使用多层深度神经网络,获取学习者与学习资源的交互特征,将学习者与学习资源的交互特征作为第一目标学习资源的推荐分数y
ur
,计算过程如下:
[0204][0205]
其中,为权重矩阵,b
l
是神经网络第l层的偏差,[pu,pr]为学习者模型pu和学习资源模型pr的连接,l为神经网络模型的层数;
[0206]
根据收集的学习者信息和教师信息,对目标学习者和老师使用余弦相似度算法进行相似度计算,得到与学习者相似度最高的教师;
[0207]
使用卷积神经网络,将相似度最高的教师与目标学习资源进行匹配,得到第二目标学习资源的推荐分数y
tr
;
[0208]
将第一目标学习资源的推荐分数y
ur
与第二目标学习资源推荐分数y
tr
相加,得到
目标学习资源最终的推荐分数yr;
[0209]
推荐模块用于按照推荐分数yr高低将其排序,将分数最高的前n个学习资源依次推荐给学习者。
[0210]
另外,本发明还可以提供一种计算机设备,包括处理器以及存储器,存储器用于存储计算机可执行程序,处理器从存储器中读取部分或全部所述计算机可执行程序并执行,处理器执行部分或全部计算可执行程序时能实现本发明所述基于学习者偏好与群体偏好的学习资源推荐方法。
[0211]
另一方面,本发明提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时,能实现本发明所述的基于学习者偏好与群体偏好的学习资源推荐方法。
[0212]
所述计算机设备可以采用笔记本电脑、桌面型计算机或工作站。
[0213]
处理器可以是中央处理器(cpu)、图形处理器(gpu)、数字信号处理器(dsp)、专用集成电路(asic)或现成可编程门阵列(fpga)。
[0214]
对于本发明所述存储器,可以是笔记本电脑、桌面型计算机或工作站的内部存储单元,如内存、硬盘;也可以采用外部存储单元,如移动硬盘、闪存卡。
[0215]
计算机可读存储介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机可读存储介质可以包括:只读存储器(rom,read only memory)、随机存取记忆体(ram,random access memory)、固态硬盘(ssd,solid state drives)或光盘等。其中,随机存取记忆体可以包括电阻式随机存取记忆体(reram,resistance random access memory)和动态随机存取存储器(dram,dynamic random access memory)。
[0216]
以上所述,仅为本发明创造较佳的具体实施方式,但本发明创造的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明创造披露的技术范围内,根据本发明创造的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明创造的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。