1.本发明涉及目标识别的复制粘贴增强方法、自适应调节、图像识别、人工智能领域,尤其涉及一种基于类别不平衡的自适应数据增强方法。
背景技术:
2.在目标识别领域中,数据集对于深度卷积网络模型的训练来说是至关重要的。制作优质的数据集是一项非常复杂的工程,需要耗费许多资源。例如,在现实生活中每个类别出现的频率是不一样的。这在样本采集上存在很多困难。因此数据集容易出现类别不平衡的问题。而数据增强算法通过合成数据使数据集中数据的形式更加多样,增强模型的鲁棒性,是解决类别不平衡的常用方法之一。对于数据集中的类别不平衡问题,复制粘贴增强通过合成物体和背景生成新的数据来扩充模型需要的类别信息。但这些方法都是过于依赖人的直观想法。这存在一定偏差和误导。
技术实现要素:
3.针对现有技术中存在的问题,本发明的目的在于提供一种基于类别不平衡的自适应数据增强方法。
4.为解决上述问题,本发明采用如下的技术方案。
5.一种基于类别不平衡的自适应数据增强方法,基于基于类别不平衡的自适应数据增强方法包括五个模块:
6.模型预处理模块,模型用原始的数据集进预训练,其预训练的训练量是根据实际需求而定的,预训练完成后用预训练模型提取出模型对数据集的评估值;
7.数据集类别不平衡信息统计模块,用数据集的标签对数据集的不平衡问题进行统计和估量;
8.偏好因子p的计算,模型对每个类别的偏好是通过模型的预训练和数据集的类别不平衡问题而得到的,在这个过程中,通过引入了微调系数t来调节模型对每个类别的偏好程度;
9.类间差异的扩增与增强判定,在自适应算法中通过引入偏好增强系数e来突出类别间偏好因子p的差异,防止因偏好因子p过小导致模型在对类别信息进行操作时失效。在训练中存在模型对某些类别过于优化或者某些类别不存在信息过少的情况,通过引入增强判定式来判断类别是否需要进行复制粘贴增强的操作;
10.数据与标签的更新,模型根据偏好因子来适度调整对目标信息的复制和粘贴,将生成的数据加入训练集中并同步更新对应的标签。
11.一种基于类别不平衡的自适应数据增强方法,其包括以下步骤:
12.步骤一、对模型进行预训练和统计数据集的类别不平衡信息;
13.步骤二、根据根据预训练的结果和统计信息计算模型对每个类别的偏好程度;
14.步骤三、在偏好因子中引入微调系数t与偏好增强系数e;
15.步骤四、构建自适应复制粘贴增强表达式;
16.步骤五、根据表达式生成新的数据与更新对应的标签,用新的数据集进行训练。
17.所述步骤一的模型预训练,模型用原始的数据集进行预训练,该预训练的训练量并不是固定的,当训练到某一个阶段时,就提取出该阶段训练权重来得出模型在前状态下对数据集的评估。
18.所述步骤一的数据集统计方法,该统计方法主要是评估数据集的类别不平衡问题,该方法通过使用数据集的标签文件进行统计,统计的主要内容包括每个类别物体的个数以及对目标面积大小的归类。
19.所述步骤二的偏好程度计算,模型对每个类别的偏好程度是通过预训练的评估值和类别的统计信息共同计算而得的,其种用的评估值主要是map和每个类别的ap值。
20.步骤三的偏好增强因子e,为了防止每个类别的偏好程度过于相似,引入了偏好增强因子e来扩大类别之间偏好因子的差异性。
21.所述步骤三的微调因子t,以用于适当地调节模型对每个类别的偏好程度,如下式所示:
22.pi=(map-api t)*niꢀꢀ
(1),
23.api是指每个类别的评估值。i是每个类别对应的序号。map是ap的均值。用均值map与各类的ap值相减,该结果反映了模型对数据集中每个类别的学习情况。t是微调系数。通过对t的适当调整来干预模型的偏好。模型是否易于掌握某个类别,除了受到该类别自身的特征信息影响外,还受到数据集中含有该类别的信息量的影响,ni表示的是数据集中每个类别的目标数量。用pi反映模型对每个类别的学习情况。
24.其特征在于步骤四的表达式构建,其表达式如下所示:
25.n
′i=p
ie
*f(map-api t)
ꢀꢀ
(2),
26.因为有部分类别的ap值与map值相差不大,导致相减之后的结果十分的小,虽然有ni的影响,但从数值上很难反映pi之间的差距,因此我们引入一个增强系数e来扩大它们之间的差距。同时,存在一些类别由于自身特征的结构或者数据集中有充足的特征信息进行学习,使得模型能准确地分辨它们,这部分类别是不需要进行数据扩增的。引入判别式f(ap
i-map)决定当前该类是否进行复制,粘贴的操作。该式子的详细表达如下:
[0027][0028]
在判别式中,也加入了微调系数t,通过对t的适当调整来增加或减少扩增的类别,只有当map-api t大于零时,公式(2)才有效,否则不会对该类别进行数据扩增。n
′i是该类别通过复制,粘贴算法扩增到的数据量。为了防止某些类别的偏好因子过高或者过低导致n
′i偏离了整体,我们通过加入归一化对其整体的结果进行了修正,其归一化公式如下:
[0029][0030]
其中归一化的范围是(s1,s2),n
′
是n
′i的集合。y是最终自适应增强算法的输出值。
[0031]
所述步骤五的数据更新,根据表达式生成新的数据并同步更新对应的标签,生成的新数据式以覆盖原数据的方式加入到数据集中,即新的数据集在数据量上是和原来的数据集保持一致。
[0032]
所述自适应数据增强方法除了能应用于复制粘贴,还能应用于旋转、翻转、颜色变换、随机遮挡、非线性变化算法等数据增强方法。
[0033]
本发明的有益效果
[0034]
相比于现有技术,本发明的优点在于:
[0035]
本发明通过网络模型来判断各类别是否进行数据增强和决定增强的其程度来形成具有模型训练偏好的数据集,然后通过分阶段训练对不同特性的数据集进行训练。每个阶段都采用具有不同特性的数据集进行训练,使得模型的训练变得有序,最终模型的性能得到了提升。
附图说明
[0036]
图1是本发明的步骤流程图;
[0037]
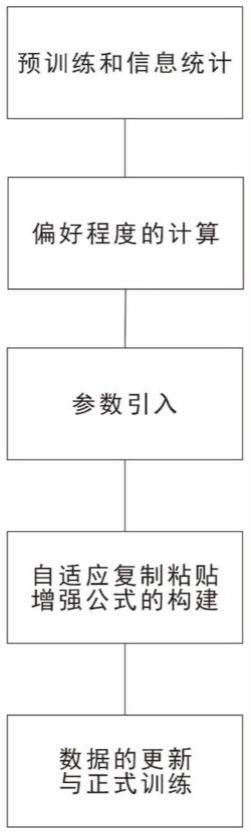
图2是本方法的流程框图。
具体实施方式
[0038]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述;显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0039]
一种基于类别不平衡的自适应数据增强方法,该方法通过自适应的复制粘贴增强方法改善了数据集中的类别不平衡问题,让数据集的特征分布更加适合模型的训练,从而达到提高模型性能的目的。基于类别不平衡的自适应数据增强方法包括五个模块:
[0040]
模型预处理模块,模型用原始的数据集进预训练,其预训练的训练量是随意的,预训练完成后用对应的权重文件提取出模型对数据集的评估值;
[0041]
数据集类别不平衡信息统计模块,用数据集的标签对数据集的不平衡问题进行统计和估量;
[0042]
偏好因子p的计算,模型对每个类别的偏好是通过模型的预训练和数据集的类别不平衡问题而得到的,在这个过程中,通过引入了微调系数t来调节模型对每个类别的偏好程度;
[0043]
类间差异的扩增与增强判定,在自适应算法中通过引入偏好增强系数e来突出类别间偏好因子p的差异,防止因偏好因子p过小导致模型在对类别信息进行操作时失效。在训练中存在模型对某些类别过于优化或者某些类别不存在信息过少的情况,通过引入增强判定式来判断类别是否需要进行复制粘贴增强的操作;
[0044]
数据与标签的更新,模型根据偏好因子来适度调整对目标信息的复制和粘贴,将生成的数据加入训练集中并同步更新对应的标签。
[0045]
本方法包括以下步骤:
[0046]
步骤一、对模型进行预训练和统计数据集的类别不平衡信息;
[0047]
步骤二、根据根据预训练的结果和统计信息计算模型对每个类别的偏好程度;
[0048]
步骤三、在偏好因子中引入微调系数t与偏好增强系数e;
[0049]
步骤四、构建自适应复制粘贴增强表达式;
[0050]
步骤五、根据表达式生成新的数据与更新对应的标签,用新的数据集进行训练。
[0051]
步骤一的具体步骤如下:统计数据集的类别不平衡信息需要用到数据集的标签信息,统计的主要内容包括每个类别目标在数据集中的数量以及每个目标面积的大小。模型的预训练是采用原数据,模型的预训练是采用原数据,其训练量可以按不同的阶段进行划分,不同阶段计算的偏好因子会略有不同。
[0052]
步骤二的具体步骤如下:计算模型对每个类别的偏好程度需要用到预训练的评估值和类别不平衡的统计信息。主要用到的评估值是map和每个类别的ap值,将map分别和每个类别的ap相减得出每个类别和均值的差距,然后将该结果与类别的目标相乘得出得出偏好因子。
[0053]
步骤三的具体步骤如下:在自适应算法中引入了增强系数e来增强类别之间的偏好差异,同时,为了防止算法过于依赖模型的抉择,我们也引入了微调系数t来做适当地调节。
[0054]
步骤四的具体步骤如下:在偏好因子的基础上加入了判别式,在数据集中存在某些类别能很好地被模型识别出来,而且这些类别的目标数量含量也很高,因此这些类别不需要进行复制粘贴的操作,这就是判别式的作用。判别式主要的功能是判断该类别的偏好因子是否有效,其形式如下所示:
[0055][0056]
t是微调系数,通过对t的调整能适当地增多或减少进行复制粘贴增强的类别数量。当map-api t大于等于0时,该类被别的偏好因子才有效,反之则说明该类别不需要进行数据扩增的操作。其最终的自适应复制粘贴增强表达式如下所示:
[0057]n′i=p
ie
*f(map-api t)
[0058]
其中f(map-api t)为判别式,n
′i是偏好因子。此时得出的结果确实能指导复制粘贴的操作,但存在某些类别的结果较小或者较大,偏离的主体的范围,因此,我们将最终的结果归化到一定的范围中,其具体的表达式如下:
[0059][0060]
其中,yi是最终该类别输出的结果,(s1,s2)是归化的范围。
[0061]
步骤五的具体步骤如下:根据自适应增强表达式的输出来调节目标的复制和粘贴,首先用数据集的标签将图片中的目标裁切下来,然后在数据集中随机选取图片作为目标粘贴的背景,将裁切下来的目标类别的数量通过复制扩增到对应的y值,然后将这些目标随机且均衡地粘贴到被选取出来的图片上,将生成出来的新图片取代原来数据集中的图片同时生成新的标签文件。最后用新的数据集进行模型的正式训练。
[0062]
图2是交通数据集增强的实施例子,模型会先用原始的数据集进行预训练并提取对应的评估值,然后通过对数据集的类别不平衡问题进行类别信息统计,将评估值与类别的统计信息进行计算得到偏好因子。接着用训练集的标签将图片上的类别目标裁切下来并根据偏好因子的大小对这些类别进行复制。在训练集中随机抽取相应的图片,这些图片就是目标粘贴的背景图片。目标粘贴的原则是尽可能的随机和均衡。将生成的新图片覆盖到
原来的训练集中并同步更新对应的标签,最后用新的训练集对模型进行正式的训练。
[0063]
以上所述,仅为本发明较佳的具体实施方式;但本发明的保护范围并不局限于此。任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其改进构思加以等同替换或改变,都应涵盖在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。