1.本发明涉及数据采集领域,特别是涉及一种社交数据采集方法及装置。
背景技术:
2.随着移动通讯技术的飞速发展,社交网络平台由于具有开放性、共享性和互动性的特点以及丰富多彩、方便实用的应用形式使其日益成为反映社情民意的重要手段,因而社交网络平台上的热点也层出不穷。但网络和群体性事件的结合增加了热点事件更多的不稳定性、辐射性和危害性。特别是针对近年来频发的网络群体性事件,有必要趋利避害,实时掌握事件话题演变方向,才能及时的采取应对措施,更好的让社会生态向有序健康的方向发展。
3.而网络群体性事件的发展通常遵循潜伏和酝酿、爆发、高潮、平息和善后这几个必经阶段。因此,研究事件发生机理和规律可以为此类事件的有效应对做好准备。但是网络具有匿名性、交互性、低成本操作以及参与的平等性等特性,导致社交网络中群体行为的观察在技术层面上存在各种各样需要解决的技术障碍。
4.如从管理者角度来看待群体事件:监测分布式社交网络中每个参与者的行为是一件很困难的事情。特别是当群体性事件的参与者范围不明确,且数量较多的情况。并且社交网络中的管理员缺乏多维度的准确数据作为事件依据,因而无法判定群体性事件中每个参与者扮演的角色类型以及参与程度的依据。
5.或从参与者角度来看待群体事件:由于人类是社会化的生物,人们的每个行为都受到其他人的行为的影响。每个事件中参与者的行为和信任状态都受到社交网络中其他参与者的行为和信任状态的影响,也就是社交网络中所谓的同质性。如在社交网络中若一个参与者周围的所有其他参与者的行为都是可信的,那么这个参与者的行为将倾向于可信。所以在不同的时间段,群体事件的特征、参与者扮演的角色类型以及参与程度都将发生动态变化。因而无法实现对群体事件的参与者进行有效的追踪和分析。
技术实现要素:
6.本发明所要解决的技术问题是:提供一种社交数据采集方法及装置,能够实现对群体事件发展的动态监控。
7.为了解决上述技术问题,本发明采用的技术方案为:
8.一种社交数据采集方法,包括步骤:
9.获取待观察的主社区中所有第一社交账号的关系型数据;
10.获取所述主社区对应的特征词语组集合;
11.根据所述关系型数据获取与每一所述第一社交账号对应的第二社交账号,根据所述第二社交账号生成与所述第一社交账号对应的子社区;
12.获取所述子社区中所有所述第二社交账号的信息;
13.根据所述第二社交账号的信息生成与所述第二社交账号一一对应的特征词语组;
14.判断所述特征词语组与所述特征词语组集合是否有交集,若是,则将所述特征词语组对应的第二社交账号加入所述主社区。
15.为了解决上述技术问题,本发明采用的另一种技术方案为:
16.一种社交数据采集终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述的一种社交数据采集方法中的各个步骤。
17.本发明的有益效果在于:通过获取待观察的主社区中所有第一社交账号的关系型数据和与主社区对应的特征词语组集合,并根据关系型数据获取与每一第一社交账号对应的第二社交账号生成对应的子社区,再获取子社区中第二社交账号的信息生成特征词语组,通过特征词语组与特征词语组集合之间的关系判断第二社交账号与主社区之间的关系,即能够追踪到当前时间段内与主社区群体事件相关的第二社交账号,并将第二社交账号加入主社区内进行监测,从而能够有效的将群体事件的参与者们进行关联并采集对应的事件信息;并且将第二社交账号加入主社区,还实现对主社区的动态扩展,从而实现对群体事件发展的动态监控。
附图说明
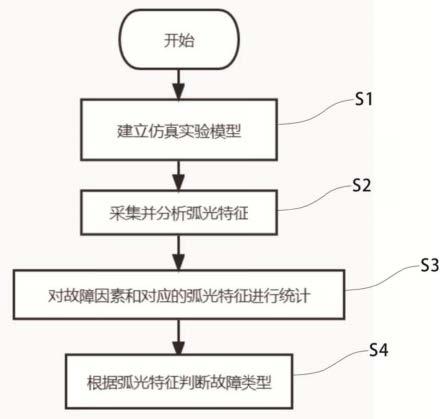
18.图1为本发明实施例的一种社交数据采集方法的步骤流程图;
19.图2为本发明实施例的一种社交数据采集装置的一种结构示意图;
20.图3为本发明实施例的一种社交数据采集方法的另一步骤流程图;
21.图4为本发明实施例的一种社交数据采集方法的另一步骤流程图。
具体实施方式
22.为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
23.请参照图1,一种社交数据采集方法,包括步骤:
24.获取待观察的主社区中所有第一社交账号的关系型数据;
25.获取所述主社区对应的特征词语组集合;
26.根据所述关系型数据获取与每一所述第一社交账号对应的第二社交账号,根据所述第二社交账号生成与所述第一社交账号对应的子社区;
27.获取所述子社区中所有所述第二社交账号的信息;
28.根据所述第二社交账号的信息生成与所述第二社交账号一一对应的特征词语组;
29.判断所述特征词语组与所述特征词语组集合是否有交集,若是,则将所述特征词语组对应的第二社交账号加入所述主社区。
30.由上述描述可知,本发明的有益效果在于:通过获取待观察的主社区中所有第一社交账号的关系型数据和与主社区对应的特征词语组集合,并根据关系型数据获取与每一第一社交账号对应的第二社交账号生成对应的子社区,再获取子社区中第二社交账号的信息生成特征词语组,通过特征词语组与特征词语组集合之间的关系判断第二社交账号与主社区之间的关系,即能够追踪到当前时间段内与主社区群体事件相关的第二社交账号,并将第二社交账号加入主社区内进行监测,从而能够有效的将群体事件的参与者们进行关联
并采集对应的事件信息;并且将第二社交账号加入主社区,还实现对主社区的动态扩展,从而实现对群体事件发展的动态监控。
31.进一步地,所述获取所述主社区对应的特征词语组集合包括:
32.获取所述主社区中所有所述第一社交账号的文本数据;
33.根据所述文本数据生成与每一所述第一社交账号对应的特征词语组,并生成与所述主社区对应的特征词语组集合。
34.由上述描述可知,通过获取主社区中所有所述第一社交账号的文本数据,并根据文本数据生成第一社交账号对应的特征词语组以及主社区对应的特征词语组集合,从而系统能够获取主社区中所有第一社交账号所关注的群体事件的特征词语。
35.进一步地,所述获取所述主社区对应的特征词语组集合包括:
36.设置预监测的文本数据;
37.根据所述预监测的文本数据生成与所述主社区对应的特征词语组集合。
38.由上述描述可知,通过设置预监测的文本数据,从而能够主动根据当前的热点群体事件设置对应的待监测文本数据,进而能够获取到与当前热点群体事件最相关的第一社交账号以及对应的特征词语组和特征词语组集合,实现对主社区的动态监控。
39.进一步地,所述生成与所述主社区对应的特征词语组集合包括:
40.清洗所述文本数据,得到所述文本数据的主干语段;
41.抽取所述主干语段中的关键词;
42.标注所述关键词,得到关键词集合;
43.通过加权计数计算所述关键词集合的热度排名,得到所述特征词语组集合。
44.由上述描述可知,通过对文本数据进行清洗、抽取和标注等步骤,能够精确的抽取出文本数据中的关键词,并通过加权计数计算对关键词集合进行热度排名,进一步挑选出主社区内最热点的群体事件,实现对热点群体事件的精确监控。
45.进一步地,所述根据所述关系型数据获取与每一所述第一社交账号对应的第二社交账号,根据所述第二社交账号生成与所述第一社交账号对应的子社区包括:
46.根据所述关系型数据计算与所述第一社交账号有关联的所有社交账号的亲密度排序;
47.根据所述亲密度排序获取所述第二社交账号,并根据所述第二社交账号生成与所述第一社交账号对应的所述子社区。
48.由上述描述可知,通过计算得到与第一社交账号有关联的社交账号的亲密度排序,从而能够将亲密度较低的账号排除,不仅提高了对相关账号追踪的精确度,同时也降低了计算量,提高处理速度。
49.进一步地,所述获取待观察的主社区中所有第一社交账号的关系型数据包括:
50.根据所述关系型数据生成所有所述第一社交账号之间的亲密关系,并生成亲密关系集合;
51.根据所述亲密关系集合迭代计算得到强关联账号集合。
52.由上述描述可知,通过建立所有第一社交账号之间的亲密关系集合,并通过迭代计算得到强关联账号集合,从而能够将与热点事件相关最具有相关性的第一社交账号进行集合,使热点事件与其相对应的第一社交账号群体之间建立对应关系,提高对群体事件监
控的方便性。
53.进一步地,所述获取待观察的主社区中所有第一社交账号的关系型数据之前包括:
54.获取所有所述第一社交账号的全量数据;
55.所述全量数据包括所述关系型数据;
56.将所述全量数据分类,并对实时文件进行存储。
57.由上述描述可知,通过获取第一社交账号的全量数据,并对全量数据进行分类和实时存储,从而提高了数据的可靠性。
58.进一步地,将所述全量数据分类,并对实时文件进行存储包括:
59.将所述全量数据分类并存入一个分布式的搜索和分析引擎中。
60.由上述描述可知,通过将全量数据分类并存入分布式搜索和分析引擎中,从而方便有关人员对数据的搜索和分析,提高监控效率。
61.进一步地,所述将所述全量数据分类,并进行分布式实时文件存储包括:
62.将所述全量数据对应的字段生成索引,并与所述实时文件对应。
63.由上述描述可知,通过将全量数据对应的字段生成索引,并与所示实时文件存储对应,从而能够通过对应的索引字段更快速的搜索到对应的数据,提高对数据搜索的效率。
64.请参照图2,本发明还提供了一种社交数据采集装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述的一种社交数据采集方法中的各个步骤。
65.本发明上述一种社交数据采集方法及装置适用于各种网络社区的数据采集,如微博、论坛等社交网站或社交软件,以下通过具体实施方式进行说明:
66.实施例一
67.请参照图1和图3,一种社交数据采集方法,包括步骤:
68.s1、获取所有所述第一社交账号的全量数据,全量数据包括文本数据和关系型数据;
69.通过数据挖掘技术获取待观察的社区全量数据作为基础数据,所述全量数据包括个人信息、好友信息、粉丝信息、贴文信息、评论、点赞、转发等社区相关信息;其中如个人信息、贴文信息和评论为文本数据,好友信息、粉丝信息、点赞和转发为关系型数据;并将所述全量数据分类存入一个分布式的开源搜索与分析引擎如elasticsearch,分布式实时文件存储,并将所述全量数据的每一个字段都编入索引,使其可以被搜索,可以扩展到上百台服务器,处理pb级别的结构化或非结构化数据;
70.s2、获取所述主社区对应的特征词语组集合;
71.根据所述文本数据生成与每一所述第一社交账号对应的特征词语组,并生成与所述主社区对应的特征词语组集合;通过python spark的组合使用,实现对所述第一社交账号的文本数据分批快速清洗和规范化;具体的,包括步骤:
72.s201、对所述文本数据进行清洗,去除标点等停用词及无意义符号;选择主干语段,通过文本分词技术抽取关键词,排除字符级的噪声,包括非中文字符以及常见中文停用词等;
73.s202、使用分词工具对清洗后的关键词进行词性标注,获得具有不同词性的关键
词集合;
74.s203、通过加权计数的统计方式获得关键词集合的热度排行,提取热度排行靠前的若干个关键词作为特征词语,形成每一所述第一社交账号对应的特征词语组集合组,并将该特征词语组集合组合并生成所述主社区对应的特征词语组集合;
75.s3、根据所述关系型数据获取与每一所述第一社交账号对应的第二社交账号,根据所述第二社交账号生成与所述第一社交账号对应的子社区;
76.具体的,根据所述关系型数据计算与所述第一社交账号有关联的所有社交账号的亲密度排序;通过所述亲密度排序获取所述第二社交账号,并根据所述第二社交账号生成与所述第一社交账号对应的所述子社区;
77.具体的,获取亲密度排序中前预设位的社交账号标记为第二社交账号;
78.s4、获取所述子社区中所有所述第二社交账号的信息;
79.s5、根据所述第二社交账号的信息生成与所述第二社交账号一一对应的特征词语组;
80.s6、判断所述特征词语组与所述特征词语组集合是否有交集,若是,则将所述特征词语组对应的第二社交账号加入所述主社区;
81.请参照图3,在一具体的实施场景中:定义待观察的网络环境为主社区c,c={v,u};其中,v={v1,v2,
…
,vi,
…
,vn}表示所述社交网络c中所有账号的集合,vi表示第i个账号;n为账号的总数;u={u1,u2,
…
,ui,
…
,un}表示所述社交网络c的特征词语组集合;ui表示所述群体行为集合u中第i个账号vi的特征词语组;定义子社区为ci,ci={w,x};其中,w={w1,w2,
…
,wi,
…
,wk}表示所述社交网络ci中所有账号的集合,wi表示子社区ci的第i个账号;k为账号的总数;x={x1,x2,
…
,xi,
…
,xk}表示子社区ci的特征词语组集合;xi表示所述群体行为集合u中第i个账号xi的特征词语组;
82.步骤s1、获取主社区c中所有社交账号vi的文本数据和关系型数据,并生成账号集合v;
83.步骤s2、根据每一社交账号vi对应的文本数据得到每一社交账号vi对应的特征词语组ui,合并生成主社区c对应的特征词语组集合u;
84.步骤s3、根据关系型数据获取与每一社交账号vi对应的社交账号wi,并将社交账号wi集合得到子社区为ci;以v1为例,对账号集合v中的账号v1进行亲密度计算,得到账号v1对应的亲密度排行前k个参与者对应的社交账号wk,并将社交账号wk生成对应子社区c1,并得到对应的账号集合w;
85.步骤s4、获取子社区c1对应的账号集合w中所有社交账号wk的信息;
86.步骤s5、根据社交账号wk的信息生成与社交账号wk一一对应的特征词语组xk;
87.步骤s6、判断社交账号wk对应的特征词语组xk是否与主社区c对应的特征词语组集合u有交集,若是,则将社交账号wk加入主社区c;
88.同理,对账号集合v中的每一账号vi对应的账号集合w中的每一账号wk进行计算同样的计算;
89.在一个可选的实施方式中,进一步对子社区内与主社区相关的账号集合进行亲密度计算,即二次迭代计算;迭代计算的次数可以根据具体的需求进行适应性的调整;从而能够实现监控范围的智能花扩展,实现群体行为的全方位、纵深化的检测;同时,通过在文本
聚类分析的基础上,加入对参与者行为特征分析比如:点赞、评论、转发、评论支持比例、转发支持比例等,从多维度量化分析群体行为的同时,实现跟随群体行为演变的动态监测。
90.实施例二
91.本实施例与实施例一的不同在于,采用主动调整主社区的特征词语组集合对社区进行监控;
92.所述步骤s2包括另一可选的方式,具体的:
93.设置预监测的文本数据;根据所述预监测的文本数据生成与所述主社区对应的特征词语组集合;如监测人员采用自定义的方式设定关键词,或提供事件超话等批量的文本数据;即获取批量事件超话的文本数据后,根据上述步骤s201-s203将所述文本数据生成对应的特征词语组集合y;若采用自定义的方式设定关键词,则根据关键词进行同义词转化等处理,扩大关键词覆盖的账号数量,并生成对应的特征词语组集合y;
94.在另一可选的实施方式中,还能够根据所述特征词语组集合y与主社区c中的特征词语组集合u进行比对,判断主社区c每一社交账号vi对应的特征词语组集合ui是否与特征词语组集合y之间存在交集,若存在,则表示社交账号vi与预监测的群体事件之间存在关联,将对应的账号vi加入强关联账号集合中进行监控,并进行对应的迭代计算等步骤;
95.其中,步骤s3还包括:根据所述关系型数据生成所有所述第一社交账号之间的亲密关系,并生成亲密关系集合;根据所述亲密关系集合迭代计算得到强关联账号集合;亲密度的计算模块是基于账号的好友关系、粉丝关系、以及相关帖文的点赞数目、评论数目、转发数目、评论支持比例以及转发支持比例等相关内容按照预设的指标体系和指标计算方法综合得出;
96.定义待观察的网络环境为主社区c,c={v,e,u};e={eij|i=1,2,
…
,n;j=1,2,
…
,n}表示任意两个账号之间的亲密关系集合;eij表示第i个账号vi与第j个账号vj之间的亲密关系;若第i个账号vi与第j个账号vj之间存在亲密关系,则eij=1;否则,eij=0;
97.具体的,根据关系型数据获取主社区c内每一社交账号vi与另一社交账号vj之间的对应关系,并生成亲密关系集合e;根据亲密关系集合e对主社区c内的社交账号vi进行亲密度排序,将预设次序之后的社交账号从主社区c中排除;通过动态调整主社区的特征词语组集合u,以及动态调整主社区内的相关账号,能够有针对性的对社区环境进行监控,保障观察区域内参与者与群体事件的强关联性,为相关部门了解社交网络中特定人物群体或群体事件动态提供有效的信息支撑。
98.实施例三
99.请参照图2,一种社交数据采集终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如实施例一或实施例二中任一所述的一种社交数据采集方法中的各个步骤。
100.综上所述,本发明提供的一种社交数据采集方法及装置,通过获取待观察的主社区中所有第一社交账号的关系型数据和文本数据,对文本数据进行对应的处理生成特征词语组集合或采用预监测的文本数据生成特征词语组集合,而根据关系型数据获取与每一第一社交账号对应的第二社交账号生成对应的子社区,再获取子社区中第二社交账号的信息生成特征词语组,通过特征词语组与特征词语组集合之间的关系判断第二社交账号与主社区之间的关系,即能够追踪到当前时间段内与主社区群体事件相关的第二社交账号,并将
第二社交账号加入主社区内进行监测,并且通过对第二社交账号进行多次的迭代计算,从而能够有效的将群体事件的参与者们进行关联并采集对应的事件信息,将第二社交账号以及其迭代计算出的账号加入主社区,实现对主社区的动态扩展,同时通过动态调整主社区的特征词语组集合u,有针对性的对社区环境进行监控,从而保障观察区域内参与者与群体事件的强关联性,为相关部门了解社交网络中特定人物群体或群体事件动态提供有效的信息支撑。
101.以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。