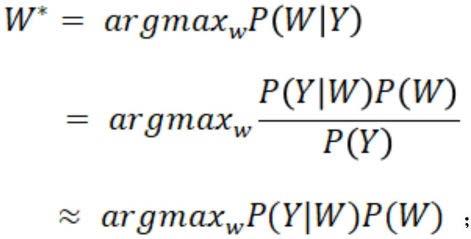
1.本发明属于语音识别技术领域,更具体地说,涉及一种用于盲人图书馆中文书籍检索的语音输入方法、设备及计算机可读介质。
背景技术:
2.目前,盲人图书馆的文献检索输入方式一般是使用盲文点显器,将其通过蓝牙与电脑相连接,然后把电脑上的文字信息通过读屏软件显示出来。然后用户再通过鼠标进行操作。因为使用的用户属于特殊群体,在图书馆这种使用场景下,通过用户手动点击鼠标,然后进行操作,费时费力。
3.针对上述问题也进行了相应的改进。如中国专利申请号cn202010485180.2,公开日为2021年12月07日,该专利公开了一种语音识别方法、语音识别系统和电器设备,所述的语音识别方法包括:获取语音信息和唇语信息,根据语音信息生成第一语句;根据唇语信息生成第二语句;根据第一语句和第二语句生成最终语句。通过分别根据获取的语音信息和唇语信息生成第一语句和第二语句,然后根据第一语句和第二语句生成最终语句,将该最终语句所表达的意思视为用户的真实意图,即通过语音信息和唇语信息来共同判断用户的真实意图,通过语音信息与唇语信息之间相互印证和比较,能够显著提高判断的准确性,从而能够更准确地获取用户的真实意图;中国专利申请号cn201810113879.9,公开日为2018年07月31日,该专利公开了一种语音识别方法、装置、设备及存储介质。所述的方法包括:当发声事件被触发时,接收麦克风发送的用户在执行发声事件过程中采集的语音信号和包含唇部的图像信号;对语音信号进行特征提取生成语音特征信号,以及对包含唇部的图像信号进行特征提取生成唇语特征信号;将语音特征信号和唇语特征信号发送给服务端,以指示服务端将语音特征信号与预设语音信号进行匹配分析生成语音识别结果以及将唇语特征信号与预设唇语信号进行匹配分析生成唇语识别结果,如果语音识别结果与唇语识别结果的相似度大于等于相似度阈值,则根据语音识别结果生成识别反馈结果并将所述识别反馈结果发送给终端。本发明实施例实现了提高语音识别率。但上述方法均存在以下不足:上述方法均是从如何更准确地获取用户的真实意图的角度对方案进行改进,而在更准确地获取用户的真实意图的基础上,如何能够对应检索出用户需要的书籍是一个亟需解决的技术问题。
技术实现要素:
4.1、要解决的问题
5.针对现有技术中存在的问题,本发明提供一种用于盲人图书馆中文书籍检索的语音输入方法、设备及计算机可读介质,首先通过对说话人的声纹进行识别,实现用户身份的辨认;然后通过语音识别的方式,将语音特征数据输入到声学模型,然后通过神经网络计算出每一帧语音数据所对应的文本序列的状态后验概率,输出语音识别的结果;最后再通过文本匹配的方式,预先围绕各种盲文书籍建立训练库,然后将语音识别技术和文本匹配技
术结合,使得整个语音输入系统更加智能和准确,进而能够更准确和高效地检索出盲人用户需要的书籍。
6.2、技术方案
7.为解决上述问题,本发明采用如下的技术方案。
8.本技术的第一个方面提供一种用于盲人图书馆中文书籍检索的语音输入方法,包括以下步骤;
9.通过声纹识别,辨别用户的身份信息;
10.采集用户的查询语音并进行解析,得到对应的语音识别文本;
11.根据所述语音识别文本进行语义相似度的计算;
12.按照语义相似度的计算结果,对问题库中的问题匹配结果进行召回和排序操作,输出最佳匹配结果。
13.更进一步地,所述通过声纹识别,辨别用户的身份信息,具体包括:
14.接收用户的语音信号,对所述语音信号进行特征提取;
15.将提取得到的声学特征输入到训练好的声纹识别模型中进行声纹识别;
16.根据声纹识别结果,判断当前用户是否为预设目标用户;若是,则进行下一步;反之则不进行操作。
17.更进一步地,所述采集用户的查询语音并进行解析,得到对应的语音识别文本,具体包括:
18.对用户的查询语音进行预处理;
19.对预处理后的查询语音进行特征提取;
20.将提取得到的声学特征输入到训练好的语音识别模型中进行语音识别;
21.根据语音识别结果,在判定所述查询语音与预存的语音识别文本匹配时,向用户提示所述查询语音的语音识别结果。
22.更进一步地,所述将提取得到的声学特征输入到训练好的语音识别模型中进行语音识别,具体包括:
23.根据提取得到的声学特征,结合预设的文本数据库,使用如下的公式对所述语音识别模型进行训练:
[0024][0025]
上式中,w*为解码输出的最佳匹配文字序列,w为文字序列,y为输入的语音信号,p(y|w)是给定这段文字序列后为这段语音信号的概率,p(w)是为这段序列的概率。
[0026]
更进一步地,所述将提取得到的声学特征输入到训练好的语音识别模型中进行语音识别,还包括:
[0027]
根据提取得到的声学特征,调用与所述声学特征对应的语音识别模型。
[0028]
更进一步地,所述根据所述语音识别文本进行语义相似度的计算,具体包括:
[0029]
预设问题库,所述问题库中包含多个与书籍名称相关的检索语句;
[0030]
将所述语音识别文本与问题库中的检索语句逐句进行相似度匹配。
[0031]
更进一步地,所述按照语义相似度的计算结果,对问题库中的问题匹配结果进行召回和排序操作,输出最佳匹配结果,具体包括:
[0032]
缓存和所述问题库中的每一个问题相似度计算之后得到的相似度值,根据相似度数值的大小进行排序,选择相似度值最高的问题文本作为最佳匹配结果输出。
[0033]
本技术的第二个方面提供一种用于盲人图书馆中文书籍检索的语音输入设备,包括:
[0034]
声纹识别模块,用于通过声纹识别,辨别用户的身份信息;
[0035]
解析模块,用于采集用户的查询语音并进行解析,得到对应的语音识别文本;
[0036]
语义相似度计算模块,用于根据解析模块解析得到的语音识别文本,进行语义相似度的计算
[0037]
以及输出模块,用于按照语义相似度计算模块的语义相似度的计算结果,对问题库中的问题匹配结果进行召回和排序操作,输出最佳匹配结果。
[0038]
本技术的第三个方面提供一种计算机可读介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现如上任一项所述的方法。
[0039]
3、有益效果
[0040]
相比于现有技术,本发明的有益效果为:
[0041]
本发明的,一种用于盲人图书馆中文书籍检索的语音输入方法、设备及计算机可读介质,首先通过对说话人的声纹进行识别,实现用户身份的辨认;然后通过语音识别的方式,将语音特征数据输入到声学模型,然后通过神经网络计算出每一帧语音数据所对应的文本序列的状态后验概率,输出语音识别的结果;最后再通过文本匹配的方式,预先围绕各种盲文书籍建立训练库,然后将语音识别技术和文本匹配技术结合,使得整个语音输入系统更加智能和准确,进而能够更准确和高效地检索出盲人用户需要的书籍。
附图说明
[0042]
图1为本技术一个方面的一种用于盲人图书馆中文书籍检索的语音输入方法的流程图;
[0043]
图2为本发明一个方面的语义相似度计算流程图;
[0044]
图3为本发明一个方面的一种用于盲人图书馆中文书籍检索的语音输入设备的结构示意图;
[0045]
图中:100、声纹识别模块;200、解析模块;300、语义相似度计算模块;400、输出模块。
具体实施方式
[0046]
下面结合具体实施例和附图对本发明进一步进行描述。
[0047]
在本技术一个典型的配置中,终端、服务网络的设备均包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
[0048]
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
[0049]
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体,可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的装置或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。
[0050]
为更进一步阐述本技术所采取的技术手段及取得的效果,下面结合附图及优选实施例,对本技术的技术方案,进行清楚和完整的描述。
[0051]
图1示出本技术一个方面的一种用于盲人图书馆中文书籍检索的语音输入方法的流程图,其中,一个实施例的方法包括步骤s100~步骤s400。在步骤s100中,通过声纹识别,辨别用户的身份信息;在步骤s200中,采集用户的查询语音并进行解析,得到对应的语音识别文本;在步骤s300中,根据所述语音识别文本进行语义相似度的计算;在步骤s400中,按照语义相似度的计算结果,对问题库中的问题匹配结果进行召回和排序操作,输出最佳匹配结果。
[0052]
具体地,在步骤s100中,通过声纹识别,辨别用户的身份信息;所述身份信息是指能够表征用户唯一身份的信息,用户与其身份身份信息之间应该是一一对应的关系。在本技术一实施例中,通过声纹识别,辨别用户的身份信息,具体可以先接收用户的语音信号,对所述语音信号进行特征提取。例如,可以在设备中先设置一个唤醒词“你好”,再通过声音录制设备获取用户的语音信号;再将用户的语音信号输入一个特征提取网络进行特征提取,得到一个声纹信号,最后再将提取得到的声学特征输入到训练好的声纹识别模型中进行声纹识别;根据声纹识别结果,判断当前用户是否为预设目标用户;判断当前用户是否为预设目标用户的方法,可以通过打分的方法完成,每次待测语音特征输入声纹识别模型时进行判决打分,判断是否为预设目标用户,若是,则进行下一步,用户可以继续语音进行输入;反之则不进行操作,或者让有需求的用户前往人工登记处注册信息。在此,本领域技术人员应能理解,本实施例中所述的声纹识别模型为现有的卷积神经网络模型,其网络架构、实现原理与现有方案类似,在此不再赘述。声纹识别模型在进行训练时,可以按照常规的方法,先构建一个训练样本集,输入至声纹识别模型,然后不断调整声纹识别模型的参数,直至满足训练终止条件,获得训练好的声纹识别模型。可以理解地,具体的训练方法与现有进行模型训练的方法类似,在此不再赘述。
[0053]
在此,通过声纹识别,辨别用户的身份信息主要是考虑到用户是特殊群体,通过对说话人的声纹进行识别,能够实现身份的辨认
[0054]
具体地,在步骤s200中,采集用户的查询语音并进行解析,得到对应的语音识别文本。在一实施例中,可以先对用户的查询语音进行预处理,其中预处理的方法包括但不限于预加重、加窗分帧等操作;再对预处理后的查询语音进行特征提取;再将提取得到的声学特征输入到训练好的语音识别模型中进行语音识别;最后再根据语音识别结果,在判定所述
查询语音与预存的语音识别文本匹配时,向用户提示所述查询语音的语音识别结果。另外值得说明的是,在训练语音识别模型时,可以根据提取得到的声学特征,结合预设的文本数据库,使用如下的公式对所述语音识别模型进行训练:
[0055][0056]
上式中,w*为解码输出的最佳匹配文字序列,w为文字序列,y为输入的语音信号,p(y|w)是给定这段文字序列后为这段语音信号的概率,p(w)是为这段序列的概率。
[0057]
具体地,在步骤s300中,根据所述语音识别文本进行语义相似度的计算;在语音识别的过程中,先将特征数据输入到声学模型,然后通过神经网络计算出每一帧语音数据所对应的文本序列的状态后验概率,即输出模型预测结果。在进行语义相似度的计算时,具体包括:
[0058]
预设问题库,所述问题库中包含多个与书籍名称相关的检索语句;
[0059]
将所述语音识别文本与问题库中的检索语句逐句进行相似度匹配。
[0060]
如图2所示,文本匹配的过程中假如输入的两段文本分别是s1和s2,可以将bert模型和主题模型结合使用,bert模型这边将文本输入到模型之后使用cls输出向量c:bert(s1,s2)。主题模型这边提取得到句子中的单词主题,然后和输出向量c结合输入到神经网络中进行相似度的计算。
[0061]
步骤s400、按照语义相似度的计算结果,对问题库中的问题匹配结果进行召回和排序操作,输出最佳匹配结果。其中,所述按照语义相似度的计算结果,对问题库中的问题匹配结果进行召回和排序操作,输出最佳匹配结果,具体包括:
[0062]
在上述文中的相似度计算之后,系统会缓存和问题库中的每一个问题相似度计算之后得到的相似度值,并根据相似度数值的大小进行排序,然后通过神经网络的计算选择出相似度值最高的问题文本,最终完成本次的文本匹配。
[0063]
综上所述,本技术所述的一种用于盲人图书馆中文书籍检索的语音输入方法首先通过对说话人的声纹进行识别,实现用户身份的辨认;然后通过语音识别的方式,将语音特征数据输入到声学模型,然后通过神经网络计算出每一帧语音数据所对应的文本序列的状态后验概率,输出语音识别的结果;最后再通过文本匹配的方式,预先围绕各种盲文书籍建立训练库,然后将语音识别技术和文本匹配技术结合,使得整个语音输入系统更加智能和准确,进而能够更准确和高效地检索出盲人用户需要的书籍。
[0064]
图3示出根据本技术又一个方面的一种用于盲人图书馆中文书籍检索的语音输入设备结构示意图;所述设备包括:声纹识别模块100、解析模块200、语义相似度计算模块300以及输出模块400。其中,所述声纹识别模块100用于通过声纹识别,辨别用户的身份信息;所述解析模块200用于采集用户的查询语音并进行解析,得到对应的语音识别文本;所述语义相似度计算模块300用于根据解析模块解析得到的语音识别文本,进行语义相似度的计
算;所述输出模块400用于按照语义相似度计算模块的语义相似度的计算结果,对问题库中的问题匹配结果进行召回和排序操作,输出最佳匹配结果。具体地,所述声纹识别模块可以通过设置唤醒词“你好”,利用声纹识别判断用户是否为图书馆用户库中的成员,若判断结果为否,则需要用户前往人工登记处注册信息。若判断结果为是,则用户可以语音进行输入。当用户完成语音输入时,系统会将识别结果存放在计算机内存中,然后与问题库中的问题逐次进行语义相似度的计算,然后根据相似度进行一个排序,选择出最佳匹配结果。最后一步是用户进行一个匹配结果的确认,完成用户的身份信息的辨识。
[0065]
具体地,所述解析模块主要用于采集用户的查询语音并进行解析,得到对应的语音识别文本。在一个优选的实施例中,解析模块首先语音数据首先通过预加重、加窗分帧等操作对语音数据进行预处理,再通过特征提取,提取出特征向量,输入到声学模型并进行训练;再使用文本数据库对语音模型进行训练。其中文本数据库可以在图书馆场景下,围绕各种盲文书籍建立。
[0066]
具体地,所述语义相似度计算模块用于根据解析模块解析得到的语音识别文本,进行语义相似度的计算。相似度的计算可以使用字典和搜索算法找到发音和文本之间的映射关系。这在上文中已有说明,这里不再赘述。
[0067]
一个优选的实施例中,所述输出模块用于按照语义相似度计算模块的语义相似度的计算结果,对问题库中的问题匹配结果进行召回和排序操作,输出最佳匹配结果。一个优选的实施例中,可以首先建立一个问题库,问题库中包含多个用户可能会问到的问题,如问题:你搜索的是《极端之美》吗?问题库中问题的格式可进行预先的设置;再将语音识别结果与问题库中的问题逐次进行相似度计算,按照相似度计算结果进行召回和排序操作。
[0068]
需要注意的是,本技术可在软件和/或软件与硬件的组合体中被实施,例如,可采用专用集成电路(asic)、通用目的计算机或任何其他类似硬件设备来实现。在一个实施例中,本技术的软件程序可以通过处理器执行以实现上文所述步骤或功能。同样地,本技术的软件程序(包括相关的数据结构)可以被存储到计算机可读记录介质中,例如,ram存储器,磁或光驱动器或软磁盘及类似设备。另外,本技术的一些步骤或功能可采用硬件来实现,例如,作为与处理器配合从而执行各个步骤或功能的电路。
[0069]
另外,本技术的一部分可被应用为计算机程序产品,例如计算机程序指令,当其被计算机执行时,通过该计算机的操作,可以调用或提供根据本技术的方法和/或技术方案。而调用本技术的方法的程序指令,可能被存储在固定的或可移动的记录介质中,和/或通过广播或其他信号承载媒体中的数据流而被传输,和/或被存储在根据所述程序指令运行的计算机设备的工作存储器中。在此,根据本技术的一个实施例包括一个装置,该装置包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当该计算机程序指令被该处理器执行时,触发该装置运行基于前述根据本技术的多个实施例的方法和/或技术方案。
[0070]
对于本领域技术人员而言,显然本技术不限于上述示范性实施例的细节,而且在不背离本技术的精神或基本特征的情况下,能够以其他的具体形式实现本技术。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本技术的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化涵括在本技术内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。此
外,显然“包括”一词不排除其他单元或步骤,单数不排除复数。装置权利要求中陈述的多个单元或装置也可以由一个单元或装置通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
[0071]
本发明所述实例仅仅是对本发明的优选实施方式进行描述,并非对本发明构思和范围进行限定,在不脱离本发明设计思想的前提下,本领域工程技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。