技术特征:
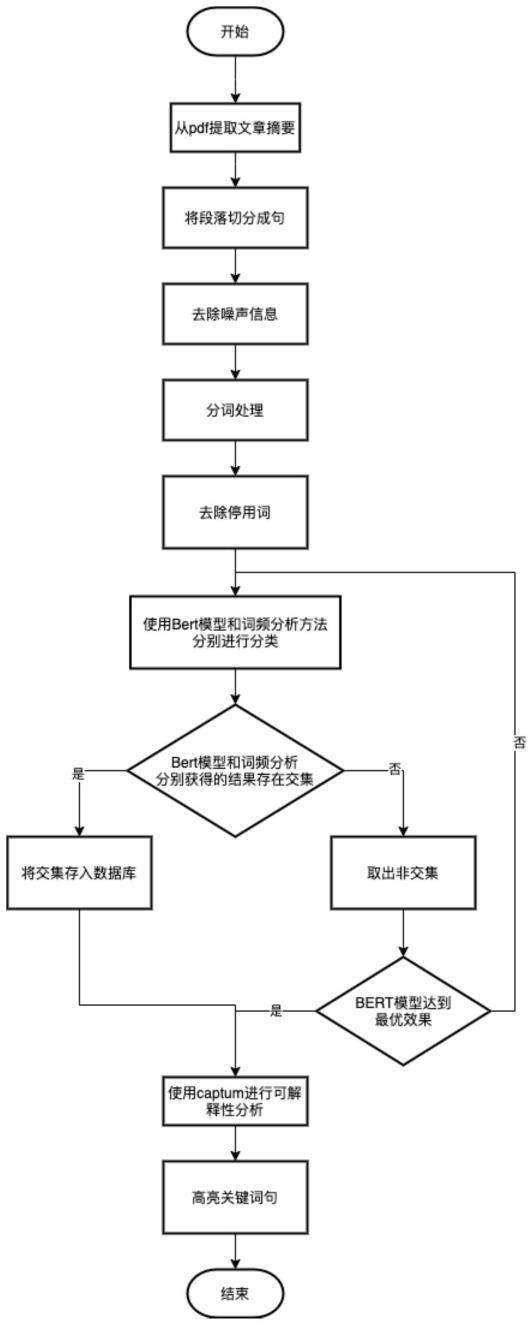
1.一种基于中文仿生文献摘要的句子分类方法,其特征在于,包括以下步骤:s1:对中文仿生科技文献摘要去噪处理后进行句子划分和分词处理,获取句子数据库和词语向量库;s2:以多领域科技文献摘要的要素作为句子类别,采用标注句子类别的多领域科技文献摘要数据集训练bert模型,得到初始bert模型;s3:提取句子数据库中部分句子进行人工标注句子类别,采用词频分析方法,在词语向量库中获取判断句子分类的关键词语;s4:基于关键词语和句子类别,对句子数据库中未进行人工标注句子类别的句子分别采用词频分析方法和输入初始bert模型中进行分类,获取第一分类结果集dataset1和第二分类结果集dataset2;s5:将dataset1和dataset2中分类结果一致的句子存入分类数据库dataset3;s6:将当前迭代作为上次迭代,其中,每次迭代完成对bert模型的一次训练,且词频分析方法采用较上次迭代更小的分词粒度;s7:在dataset1中剔除dataset3中的句子,若dataset1为上次迭代前的bert模型获取,则采用较上次迭代更小的分词粒度的词频分析方法对dataset1再次分类并更新,且采用上次迭代后的bert模型对dataset2再次分类并更新;反之,采用上次迭代后的bert模型对dataset1再次分类并更新,且采用较上次迭代更小的分词粒度的词频分析方法对dataset2再次分类并更新;s8:转至s6,直至bert模型达到最好训练效果时停止句子分类,dataset3作为最终的分类结果。2.根据权利要求1所述的句子分类方法,其特征在于,在s8后还包括s9,s9为:使用可解释性工具captum对训练完成的bert模型进行解释性分析,使用captum insights对分析结果进行可视化,高亮出每个句子中判别句子分类的关键信息。3.根据权利要求1所述的句子分类方法,其特征在于,s1具体包括以下步骤:s1.1:从pdf和caj格式的仿生科技文献中提取摘要数据;s1.2:对摘要数据中不清晰的数据或含有的水印采用图像处理方法进行去雾去噪,并对摘要数据中的噪声信息采用正则表达式过滤;s1.3:利用分段换行符从去噪后的摘要数据中取出各段落,存入段落数据库中;s1.4:采用正则表达式,对各段落以句子为单位进行拆分创建句子数据库;s1.5:使用jieba分词工具将句子数据库中的句子转换为分词后对应的分词向量;分词粒度包括:句子级别、短语级别、单词级别和字符级别;其中,各个分词向量构建为词语向量库。4.根据权利要求1至3任一所述的句子分类方法,其特征在于,所述词频分析方法为:对句子数据库中的部分句子进行人工标注句子类别,采用词频分析方法在词语向量库中筛选出各句子类别下句子中出现频率为前十的词语作为判断句子分类的关键词语,用以表征句子类别;对句子数据库中未进行人工标注句子类别的每一个句子进行词频统计,利用句子中出现频率最高的词语与判断句子分类的关键词语进行对比判断句子的类型,获取仿生领域文献摘要中句子的分类。
5.根据权利要求1所述的句子分类方法,其特征在于,所述仿生科技文献摘要的要素类别包括:研究背景、研究意义、研究过程、研究内容和实验结果。6.根据权利要求3所述的句子分类方法,其特征在于,s1.5之后还包括:采用停用词的集合包,对词语向量库中的各词语与停用词比对,在词语向量库中剔除与停用词一致的词语。7.一种基于中文仿生文献摘要的句子分类系统,其特征在于,包括:预处理模块,用于对中文仿生科技文献摘要去噪处理后进行句子划分和分词处理,获取句子数据库和词语向量库;模型预训练模块,用于以多领域科技文献摘要的要素作为句子类别,采用标注句子类别的多领域科技文献摘要数据集训练bert模型,得到初始bert模型;关键词语获取模块,用于提取句子数据库中部分句子进行人工标注句子类别,采用词频分析方法,在词语向量库中获取判断句子分类的关键词语;词频分析模块,用于基于判断句子分类的关键词语和句子类别,对句子数据库中未进行人工标注句子类别的句子或通过上次迭代前bert模型获取的分类结果集采用词频分析方法进行分类,获取分类结果集;bert模块,其内设置bert模型,用于将句子数据库中未进行人工标注句子类别的句子或通过词频分析方法获取的分类结果集输入到上次迭代后的bert模型中,获取分类结果集;其中,对句子数据库中的句子每分类一次,完成对bert模型的一次训练;交集计算模块,用于将通过词频分析方法获取的分类结果集与通过上次迭代前的bert模型获取的分类结果集取交集,获取分类数据库;其中,对句子数据库中的句子分类一次,词频分析方法采用较上次分类更小的分词粒度;数据剔除模块,用于在通过词频分析方法获取的分类结果集与通过上次迭代前的bert模型获取的分类结果集中剔除分类数据库中的句子,更新通过词频分析方法获取的分类结果集与通过上次迭代前的bert模型获取的分类结果集,分别输入至上次迭代后的bert模块和词频分析模块中进行上次迭代后bert模型的句子分类和词频分析方法的句子分类;判断模块,用于判断bert模型是否达到最好训练效果,若是则停止句子分类,将分类数据库作为最终的分类结果;否则驱动词频分析模块和bert模块运行。8.根据权利要求7所述的句子分类系统,其特征在于,还包括可解释性工具captum,用于训练完成的bert模型进行解释性分析,使用captum insights对分析结果进行可视化,高亮出每个句子中判别句子分类的关键信息。9.根据权利要求7或8所述的句子分类系统,其特征在于,所述词频分析方法为:对句子数据库中的部分句子进行人工标注句子类别,采用词频分析方法在词语向量库中筛选出各句子类别下句子中出现频率为前十的词语作为判断句子分类的关键词语,用以表征句子类别;对句子数据库中未进行人工标注句子类别的每一个句子进行词频统计,利用句子中出现频率最高的词语与判断句子分类的关键词语进行对比判断句子的类型,获取仿生领域文献摘要中句子的分类。10.根据权利要求7所述的句子分类系统,其特征在于,所述预处理模块包括:数据提取单元、去噪单元、段落划分单元、句子拆分单元、jieba分词工具和停用词剔除单元;所述数据提取单元用于从pdf和caj格式的仿生科技文献中提取摘要数据;
所述去噪单元用于对摘要数据中不清晰的数据或含有的水印采用图像处理方法进行去雾去噪,并对摘要数据中的噪声信息采用正则表达式过滤;所述段落划分单元用于利用分段换行符从去噪后的摘要数据中取出各段落,存入段落数据库中;所述句子拆分单元用于采用正则表达式,对各段落以句子为单位进行拆分创建句子数据库;所述jieba分词工具用于将句子数据库中的句子转换为分词后对应的分词向量;分词粒度包括:句子级别、短语级别、单词级别和字符级别;其中,各个分词向量构建为词语向量库;所述停用词剔除单元用于采用停用词的集合包,对词语向量库中的各词语与停用词比对,在词语向量库中剔除与停用词一致的词语。
技术总结
本发明提供了一种基于中文仿生文献摘要的句子分类方法及系统,属于文本分类领域,方法为:对句子数据库中未进行人工标注句子类别的句子分别采用词频分析方法和输入初始Bert模型中进行分类;将第一分类结果集和第二分类结果集中分类结果一致的句子存入分类数据库;在第一分类结果集中剔除分类数据库中的句子,采用本次迭代后的Bert模型对第一分类结果集再次分类,更新第一分类结果集;采用较上次迭代更小的分词粒度的词频分析方法对第二分类结果集再次分类,更新第二分类结果集;依次类推,实现句子分类。本发明减少实体抽取和关系抽取中的人工标注,可减少人力和时间的成本。可减少人力和时间的成本。可减少人力和时间的成本。
技术研发人员:谢夏 杨子硕 陈丽君 胡月明
受保护的技术使用者:海南大学
技术研发日:2022.05.17
技术公布日:2022/8/5
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。