1.本技术涉及腐蚀监测领域,具体涉及一种数据驱动的设备腐蚀预测方法。
背景技术:
2.腐蚀是指金属等材料在周围介质的作用下产生的损伤破坏过程。尤其对于石油和天然气行业而言,设备的腐蚀往往会引发严重的负面影响,包括设备结构的失效、有毒物质的泄漏以及相应的火灾爆炸事故等,从而产生重大的生命和财产损失。因此,开展炼化设备的腐蚀防护,消除潜在腐蚀威胁对石油和天然气行业的发展和工艺设备的安全运行具有重要意义。腐蚀诊断是开展腐蚀防护的第一步,通过诊断识别设备腐蚀安全状态也是评估设备完整性和安全性的重要依据。
3.目前,工程上的腐蚀诊断通常需要有经验的人员对设备进行腐蚀机理识别判断,随后采用宏观目测或其他检测仪器进行腐蚀检查,从而对设备腐蚀状态进行诊断。然而,此类依赖于专家经验的诊断评估方法效率低且受人为因素影响大,无法全面有效的提供设备腐蚀状态信息。随着人工神经网络(artificialneural network,ann)、支持向量机(support vector machine,svm)、随机森林(random forest,rf)等数据预测模型在图像识别、医疗健康评估、故障诊断等多个领域的成功应用,以及长期积累下来的大量设备检测状态数据,为研究设备腐蚀规律和预测方法提供了新思路。其中,rf算法的操作简单、泛化能力较好、分类精度高、善于处理大样本数据并且可以在一定程度上抑制类别不平衡数据影响等特点,恰好满足数据量大且各参数关系复杂的设备腐蚀检测数据集的应用,也为开展腐蚀诊断研究提供了一定启发。
技术实现要素:
4.针对上述技术问题,本技术实施例提供一种数据驱动的设备腐蚀预测方法,能够至少解决上述技术问题之一。
5.本技术采用的技术方案为:
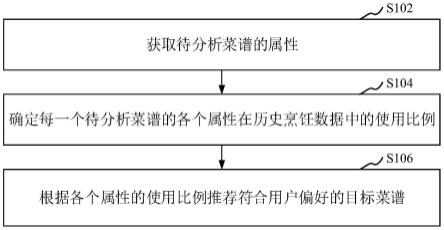
6.本技术提供一种数据驱动的设备腐蚀预测方法,用于对设备的关键部位的腐蚀状态进行预测,所述方法包括以下步骤:
7.s1,获取设备基础数据,所述设备基础数据包括第一参数信息和第二参数信息,所述第一参数信息包括(a1,a2,
…
,a9),所述第二参数信息包括(b1,b2,b3)其中,a1,a2,
…
,a9分别表示设备名称、设备关键部位、设备材质、设备投用日期、设备检测日期、设备运行时间、设置工艺介质、设备工作温度和设备工作压力,b1、b2和b3分别表示腐蚀机理、腐蚀类型和腐蚀程度;
8.s2,基于获取的基础数据构建腐蚀机理预测数据集、腐蚀类型预测数据集和腐蚀程度预测数据集;所述腐蚀机理预测数据集包括m1组样本数据,每组样本数据包括(a1,a2,
…
,a9,b1);腐蚀类型预测数据集包括m2组样本数据,每组样本数据包括(a2,a6,a8,a9,b2);腐蚀程度预测数据集包括m3组样本数据,每组样本数据包括(a2,a6,a8,a9,b3);
9.s3,对构建的每个数据集中的数据进行预处理,使得所有数据转换为全数值型数据并得到平衡数据集;
10.s4,将预处理后的每个数据集分别划分为训练集和测试集;
11.s5,构建rf预测模型和优化超参数;
12.s6,对于每个数据集,执行如下步骤:
13.s61,将对应的训练集输入到构建的rf预测模型中,利用pso对随机森林预测模型中的两个超参数n_estimators和max_depth进行优化;
14.s62,将优化后的n_estimators和max_depth代入到rf预测模型中,并利用对应的测试集进行测试,得到对应的腐蚀预测模型;
15.s7,基于s6,分别得到腐蚀机理预测模型、腐蚀类型预测模型和腐蚀程度预测模型;
16.s8,获取待预测设备的设备基础信息和设备工艺参数信息,分别利用腐蚀机理预测模型、腐蚀类型预测模型和腐蚀程度预测模型对待预测设备的关键部位的腐蚀机理、腐蚀类型和腐蚀程度进行预测。
17.本技术实施例提供的数据驱动的设备腐蚀预测方法,基于大量设备腐蚀检测历史数据和gb/t 30579-2014等相关标准信息构建腐蚀机理预测数据集、腐蚀类型预测数据集和腐蚀程度预测数据集,然后应用过采样算法解决数据集的样本不平衡问题,最终建立rf模型并采用pso智能优化算法调参,该方法能够对设备的腐蚀机理、腐蚀类型以及腐蚀程度进行有效预测,能够提高腐蚀预测的准确性和效率。
附图说明
18.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
19.图1为本技术实施例提供的数据驱动的设备腐蚀预测方法的流程图;
20.图2为本技术实施例的腐蚀机理分类预测示意图;
21.图3和图4为本技术实施例的数据样本分布情况示意图;
22.图5和图6为经过数据平衡前后的腐蚀类型预测的混淆矩阵示意图;
23.图7和图8为经过数据处理前后的腐蚀程度预测的混淆矩阵示意图;
24.图9和图10为设备腐蚀类型预测的优化情况示意图;
25.图11和图12为设备腐蚀程度预测的优化情况示意图。
具体实施方式
26.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
27.本技术的技术思想在于提出以数据驱动的方式建立包含模式识别、程度评估等内
容的腐蚀损伤预测方法,并以收集的炼油设备腐蚀检测评估的大量历史数据为基础,采用borderline-smote过采样算法对数据样本不平衡问题进行调节,最后基于pso-rf模型建立设备关键部位的腐蚀综合分类诊断模型,为设备腐蚀管理提供支持,弥补腐蚀评估应用不充分现状。
28.本技术实施例提供的数据驱动的设备腐蚀预测方法基于大量设备腐蚀检测历史数据和gb/t 30579-2014等相关标准信息,提出将传统诊断识别方法与数据预测模型相结合,建立针对设备腐蚀综合预测的方法,用于对设备的关键部位的腐蚀状态进行预测,包括对设备不同部位腐蚀机理、腐蚀类型以及腐蚀程度的识别预测。在本技术实施例中,设备的关键部位的具体位置基于实际情况确定。
29.如图1所示,本技术实施例提供的数据驱动的设备腐蚀预测方法可包括以下步骤:
30.s1,获取设备基础数据,所述设备基础数据包括第一参数信息和第二参数信息,所述第一参数信息包括(a1,a2,
…
,a9),所述第二参数信息包括(b1,b2,b3)其中,a1,a2,
…
,a9分别表示设备名称、设备关键部位、设备材质、设备投用日期、设备检测日期、设备运行时间、设置工艺介质、设备工作温度和设备工作压力,b1、b2和b3分别表示腐蚀机理、腐蚀类型和腐蚀程度。
31.在本技术实施例中,通过设备设计说明书、设备工艺流程图、设备腐蚀检测及其评估报告等多种数据来源对设备基本结构参数、加工工艺流程、检测评估结果信息进行收集,从而获取设备基础数据。
32.s2,基于获取的基础数据构建腐蚀机理预测数据集、腐蚀类型预测数据集和腐蚀程度预测数据集;所述腐蚀机理预测数据集包括m1组样本数据,每组样本数据包括(a1,a2,
…
,a9,b1);腐蚀类型预测数据集包括m2组样本数据,每组样本数据包括(a2,a6,a8,a9,b2);腐蚀程度预测数据集包括m3组样本数据,每组样本数据包括(a2,a6,a8,a9,b3)。
33.在本技术实施例中,由于样本数据名称一样,m2可等于m3。
34.s3,对构建的每个数据集中的数据进行预处理,使得所有数据转换为全数值型数据并得到平衡数据集。
35.s3进一步包括:
36.s31,将每个数据集中的第一参数信息中的文字型描述转换为数值型描述。
37.例如,对于设备名称、设备关键部位、设备材质、设备工艺材质等文字型描述信息可以数字进行替换,具体替换方式可自定义设置,只要能够实现转换即可。
38.s32,将每个数据集中的第二参数信息中的文字型描述以数字0~9作为标签进行替换。
39.即将腐蚀机理、腐蚀类型和腐蚀程度的文字型描述以数字0~9作为标签进行替换,例如,将hcl-h2s-h2o腐蚀、环烷酸腐蚀、硫化物腐蚀、环烷酸和硫化物的耦合腐蚀四种腐蚀机理分别以1、2、3、4进行类别编号替换,其他参数也以此类推,最终得到全数值型数据集。
40.s33,获取每个数据集中的第二参数信息中的标签分布,如果标签比例差异大于预设值,执行s34,否则,执行s35。
41.在本技术实施例中,预设值可自定义设置,优选地,预设值可为10。以腐蚀机理和腐蚀类型为例,分别统计预测数据集中腐蚀机理和腐蚀类型对应一列的标签数据量,其中,
腐蚀机理标签对应的比例约为hcl-h2s-h2o腐蚀:环烷酸腐蚀:硫化物腐蚀:环烷酸:硫化物耦合腐蚀=1.5:1:1.5:1,则说明这四种标签差异较小,即无明显不平衡现象,可不作非平衡处理。而腐蚀类型标签对应的比例约为均匀腐蚀:点蚀:开裂=20:5:1,则说明这三种标签比例差异较大,表明存在明显样本不平衡现象,故需要进行非平衡调节处理。
42.s34,利用设定的过采样算法对该列标签数据进行过采样,使得标签比例趋于一致;执行s35。
43.在本技术实施例中,设定的过采样算法可为borderline-smote算法,通过该算法对少数类样本进行过采样,使少数类样本和多数类样本比例趋于一致,具体流程可包括:
44.(1)计算每个少数类样本x与全体样本的欧式距离。
45.本领域技术人员知晓,计算每个少数类样本x与全体样本的欧式距离的方法可为现有方法,例如将每个数据样本转化为n维空间下某一点的值,计算每个点之间的距离。
46.(2)基于每个样本之间的欧式距离的计算结果得到少数类样本在整个数据集中的位置分布情况,并基于该分布情况确定样本x的k个近邻。
47.本技术实施例中,根据位置分布情况,选取与当前样本距离最小的k个近邻样本,为避免k选取的值过大过小对后续识别合成新样本的影响,优选,k=5。
48.(3)识别边界样本。
49.假定k个近邻中有t个多数类样本(0≤t≤k):
50.当t=k时,判定样本x为噪声样本;
51.当时,判定样本x为边界样本,将x归类至danger集合中;
52.当0≤t<(k/2)时,判定样本x为安全样本。
53.(4)合成少数样本。
54.从找到的集合danger中的样本x的k个少数类近邻,随机选择其中一个近邻xi,根据下述公式(1),合成新的少数类样本x
new
,其中λ为0到1的随机数。
55.x
new
=x λ
×
(x
i-x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
56.s35,对所有数据进行归一化处理,得到归一化处理后的平衡数据集。
57.在本技术实施例中,可通过下述公式(2)对数据进行归一化处理,使得数值映射到区间[0,1]之间:
[0058][0059]
x
*
为归一化后的值,x为每个参数信息对应列中的每个数据的值,max(x)为每个参数信息对应列中的最大值,min(x)为每个参数信息对应列中的最小值。
[0060]
s4,将预处理后的每个数据集分别划分为训练集和测试集。
[0061]
在本技术实施例中,按照8:2的比例,随机抽取平衡数据集中20%的数据作为测试集用于模型最终的验证,其余80%数据作为训练集用于后续的模型优化训练。
[0062]
s5,构建rf预测模型和优化超参数。
[0063]
在本技术实施例中,基于前述预处理后的结果,应用rf算法构建针对设备腐蚀机理、腐蚀类型和腐蚀程度三方面的预测模型,
[0064]
s6,对于每个数据集,即对于腐蚀机理预测数据集、腐蚀类型预测数据集和腐蚀程
度预测数据集,分别执行如下步骤:
[0065]
s61,将对应的训练集输入到构建的rf预测模型中,利用pso对随机森林预测模型中的两个超参数n_estimators和max_depth进行优化。
[0066]
pso算法旨在模拟粒子在搜索空间中飞行移动的过程,通过迭代得到粒子飞行的最优位置,即为最优解。其中每个粒子位置都采用向量形式表示,即xi={x
i1
,x
i2
,
…
,x
id
}},其中i=1,2,
…
,n代表粒子数量,d为个体属性维数,向量内数值依次代表要求解的参数。本技术通过pso算法对rf预测模型的两个重要超参数n_estimators和max_depth进行优化,能够提高模型的预测准确率。
[0067]
s61进一步包括:
[0068]
s601,设置pso的部分基本参数,包括粒子数量n1、迭代次数n2、局部粒子加速度因子c1、全局粒子加速度因子c2、惯性权重因子ω;由于需要优化的变量个数为2,因此对应属性维数d=2,故粒子i的向量表达形式为xi={x
i1
,x
i2
},x
i1
,x
i2
分别对应n_estimators和max_depth的值,xi为粒子i的位置,x
i1
,x
i2
分别为粒子i的空间位置坐标,i的取值为1到n1。
[0069]
在一个示意性实施例中,n1=30,n2=50,c1=2,c2=2,ω=0.4。
[0070]
s602,设置粒子群的二维搜索空间,即设置n_estimators和max_depth的取值范围。
[0071]
在本技术实施例中,参数n_estimators和max_depth的取值范围分别为[u
1min
,u
1max
]=[1,200]和[u
2min
,u
2max
]=[1,20]。
[0072]
s603,基于设置的取值范围生成n1个粒子的随机初始位置(x
11
,x
12
,
…
,x
1n1
)和飞行移动速度(v
11
,v
12
,
…
,v
1n1
),其中,x
1i
为粒子i的初始位置,v
1i
为粒子i的初始飞行移动速度。
[0073]
在本技术实施例中,可基于如下条件(3)和(4)生成n1个粒子的随机初始位置和飞行移动速度:
[0074]
x
1i
={r1(u
1max-u
1min
) u
1min
,r2(u
2max-u
2min
) u
2min
}
ꢀꢀ
(3)
[0075]v1i
=r3ꢀꢀ
(4)
[0076]
其中,u
1min
和u
1max
分别为n_estimators的最小值和最大值,u
2min
和u
2max
分别为max_depth的最小值和最大值,r1、r2和r3分别为[0,1]上的随机数。
[0077]
s604,对于每个粒子i,基于对应的训练集和rf预测模型获取粒子i的初始适应度f(x
1i
)。
[0078]
在本技术实施例中,适应度是评价粒子优劣的指标,主要根据所求问题的适应度函数计算得出。适应度可基于rf预测模型的5折交叉验证的平均准确率确定,即采用rf模型5折交叉验证结果作为适应度指标,即将前述得到的训练集数据随机等分为5份,轮流取4份训练模型,1份验证模型,最后取5次测试的平均准确率进行评价,所得平均准确率越高则表明该粒子所代表的值越好。
[0079]
s605,设置pbest
1i
=x
1i
,并gbest1=pbest
b1
,pbest
1i
为xi的初始最优位置,gbest1为粒子群的初始最优位置,pbest
b1
为初始状态下的粒子群中的适应度最高的粒子的最优位置;启动计数器c,执行s606;c的初始值为0。
[0080]
在本技术实施例中,计数器可设置在执行本发明的方法的处理器中。
[0081]
s606,设置c=c 1,如果c小于n2,执行s607,否则,执行s611。
[0082]
s607,基于pbest
ni
、gbestn、x
ni
、c1、c2和ω获取v
n 1i
,以及基于x
ni
和v
n 1i
获取x
n 1i
,x
n 1i
和v
n 1i
分别表示第n 1次迭代时的粒子i的位置和速度,n的取值为1到n2。
[0083]
在本技术实施例中,v
n 1i
和x
n 1i
可基于如下条件获取:
[0084]vn 1i
=ω*v
ni
c1*r4(pbest
ni-x
ni
) c1*r5(gbest
n-x
ni
)
ꢀꢀ
(5)
[0085]
x
n 1i
=x
ni
v
n 1i
ꢀꢀ
(6)
[0086]
r4和r5分别为[0,1]上的随机数。
[0087]
s608,对于每个粒子i,基于对应的训练集和rf预测模型获取粒子i的f(x
n 1i
)。
[0088]
f(x
n 1i
)的获取方式与前述的f(x
1i
)的获取方式相同。
[0089]
s609,如果f(x
n 1i
)>f(x
ni
),设置pbest
n 1i
=x
n 1i
,否则,pbest
n 1i
=pbest
ni
;
[0090]
s610,如果f(pbest
bn 1
)=max(f(x
n 11
),f(x
n 12
),
…
,f(x
n 1n1
))>f(gbestn),设置gbest
n 1
=pbest
bn 1
,否则,设置gbest
n 1
=gbestn;返回s606;
[0091]
s611,结束程序,将输出当前得到的粒子群的最优位置对应的n_estimators和max_depth的值。
[0092]
s62,将优化后的n_estimators和max_depth代入到rf预测模型中,并利用对应的测试集进行测试,得到对应的腐蚀预测模型。
[0093]
s7,基于s6,分别得到腐蚀机理预测模型、腐蚀类型预测模型和腐蚀程度预测模型。
[0094]
s8,获取待预测设备的设备基础信息和设备工艺参数信息,分别利用腐蚀机理预测模型、腐蚀类型预测模型和腐蚀程度预测模型对待预测设备的关键部位的腐蚀机理、腐蚀类型和腐蚀程度进行预测。
[0095]
(实施例)
[0096]
本实施例中,以炼油过程中典型的常减压装置为例,收集长期多套常减压装置的基础数据、腐蚀检测和评估报告数据等,得到共计1014台设备的腐蚀数据构建腐蚀数据集,进行综合设备腐蚀诊断模型应用研究,共包括腐蚀机理识别、腐蚀程度识别和腐蚀类型识别三方面。
[0097]
本实施例中,主要选取混淆矩阵、准确率(accuracy,acc)、精确度(precision)、召回率(recall)、f1值以及kappa系数共六项指标来对模型的预测结果进行评估。其中,混淆矩阵可以清晰展示模型对各标签数据的分类识别情况,同时对数据集的不平衡现象进行判定。准确率可以直观反映各类数据样本被正确分类的情况。精确度(precision)、召回率(recall)、f1值则分别用于进一步解释每类标签样本的分类预测情况。kappa系数则用来表征模型预测结果与实际值的一致性问题,该系数取值范围为[-1,1],通常系数值越高代表模型实现的分类性能越好。
[0098]
(腐蚀机理识别)
[0099]
由于设备腐蚀机理复杂,类型广泛,为简化运算过程,仅选取1014台设备中的三大塔类设备数据(包括常压塔、减压塔、初馏塔共计93组)进行rf模型的腐蚀模式识别验证,涉及的特征参数包括设备名称、设备关键部位、设备材质、工艺介质、温度、压力、投用日期、检测日期、运行时间等。通过查阅常减压装置工艺流程、相关腐蚀回路分析以及标准推荐(即前期的数据获取过程),将塔类设备主要腐蚀机理划分为hcl-h2s-h2o腐蚀、环烷酸腐蚀、硫化物腐蚀,以及硫化物腐蚀和环烷酸腐蚀的耦合腐蚀共四类。
[0100]
进一步数据整理划分后发现,塔类设备的腐蚀检测数据对应的腐蚀机理(即hcl-h2s-h2o腐蚀:环烷酸腐蚀:硫化物腐蚀:环烷酸和硫化物耦合腐蚀)比例约为1.5:1:1.5:1,四种机理样本数量差异较小,无明显的不平衡现象,因此仅对93组数据进行结构转换和归一化处理步骤。随后,应用rf模型对以上数据进行腐蚀模式识别预测,图2为rf模型对测试集的分类预测评估报告,其中class 1~class 4依次对应前面提到的四种腐蚀机理,括号中的数值表示测试集包含的各类腐蚀的实际样本数量。根据显示的各类腐蚀评价指数结果表明,该模型对hcl-h2s-h2o腐蚀的识别情况最好,其精确率、召回率以及f1值均可达到100%。而环烷酸腐蚀和硫化物腐蚀的耦合腐蚀情况对应class4的召回率和f1值分别有67%和73%,表明测试集里class 4的6个真实样本中约有4个可以被准确归类,相对于其他类别样本的识别能力较弱,其次是环烷酸腐蚀对应的class 2。就总体而言,rf模型对四类腐蚀机理模型均有较好的识别能力,其平均准确率可达到86%。
[0101]
(腐蚀类型和腐蚀程度评估)
[0102]
随后,应用1014台设备腐蚀数据分别进行利用腐蚀类型预测模型和腐蚀程度预测模型进行腐蚀类型评估和腐蚀程度评估,通过对部分特征参数进行简化,最终得到的数据参数包括设备工作温度(0℃~450℃)、工作压力(0~4mpa)、设备部位、运行日期(8~20年)、腐蚀类型以及腐蚀程度。其中,设备部位包括塔顶、塔内、塔底、管箱、管板、管束内、管束外、封头以及筒体共9种,腐蚀类型包括均匀腐蚀、点蚀和开裂共3种,腐蚀程度包括轻微、一般、中度以及严重共4种。
[0103]
根据原始数据样本各等级的统计分布进行非平衡调节预处理,结果如图3和图4所示,原始数据集样本对应的腐蚀类型(即均匀腐蚀:点蚀:开裂)比例约为20:5:1,而腐蚀程度(即轻微:中度:严重:一般)比例约为12:1.5:1:1,经过调节后各类别数据达到平衡分布。
[0104]
为验证不平衡数据集对模型预测结果的影响,对比了经过borderline-smote算法过采样前后原始rf模型的预测情况,结果如图5至图8以及表1~2所示。
[0105]
表1.数据处理前后的设备腐蚀类型预测评估结果
[0106][0107][0108]
*精确率,召回率和f1值根据腐蚀类型为点蚀的样本进行计算。
[0109]
表2.数据处理前后的设备腐蚀程度预测评估结果
[0110]
评估指标*未经过平衡处理经过平衡处理
训练集准确率0.9400.970测试集准确率0.8370.919精确率0.5630.954召回率0.5290.849f1值0.5460.899kappa系数0.3960.891
[0111]
*精确率,召回率和f1值根据腐蚀程度为中度的样本进行计算。
[0112]
以设备腐蚀类型预测为例,图5和图6表明经过数据样本调节后,各类样本数据的腐蚀类型均能得到有效识别。由表1可知,经过数据平衡处理后以点蚀为例的少数类样本的各项评估指标均得到大幅度提升。图7、图8和表2的评估结果表明,该平衡方法对设备腐蚀程度预测也同样有效,充分证明了borderline-smote过采样对数据样本识别的有效性,最终腐蚀类型和腐蚀程度预测模型准确率均可达到92%左右。
[0113]
为进一步改善模型分类预测精度,应用pso算法对svm模型中的n_estimators和max_depth两个重要的超参数进行优化,并将rf模型与knn、dt、svm、lr以及adaboost等典型常见的分类模型进行对比。最终以模型的准确率和kappa系数作为指标进行评估,相应的预测结果如图9~12和表3~4所示。
[0114]
表3.设备腐蚀类型评估结果
[0115]
[0116]
表4.设备腐蚀程度预测评估
[0117][0118][0119]
对比可得,除lr和adaboost模型之外,经过pso算法调参后大部分模型的数据预测精度均有显著提高,预测准确率均在85%以上,其中,pso-rf模型的性能最好,设备腐蚀程度的准确率最高可达到94%,kappa系数最高可达到0.923,表现出优异的分类预测水平。
[0120]
综上所述,本技术基于rf算法,应用borderline-smote算法解决球化等级数据集的样本不平衡问题,并采用pso智能优化算法调参,建立的pso-rf模型能够对设备的腐蚀机理、腐蚀类型以及腐蚀程度进行有效预测,三项评估的准确率均在86%以上,表现出较高的设备腐蚀诊断能力。此外,本技术能够较好的应用到工程实践中,为设备腐蚀损伤情况的快速诊断预测以及设备腐蚀防护提供一定技术支撑。
[0121]
本技术的实施例还提供了一种非瞬时性计算机可读存储介质,该存储介质可设置于电子设备之中以保存用于实现方法实施例中一种方法相关的至少一条指令或至少一段程序,该至少一条指令或该至少一段程序由该处理器加载并执行以实现上述实施例提供的方法。
[0122]
本技术的实施例还提供了一种电子设备,包括处理器和前述的非瞬时性计算机可读存储介质。
[0123]
本技术的实施例还提供一种计算机程序产品,其包括程序代码,当所述程序产品在电子设备上运行时,所述程序代码用于使该电子设备执行本说明书上述描述的根据本申
请各种示例性实施方式的方法中的步骤。
[0124]
虽然已经通过示例对本技术的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本技术的范围。本领域的技术人员还应理解,可以对实施例进行多种修改而不脱离本技术的范围和精神。本技术公开的范围由所附权利要求来限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。