1.本发明属于人工智能技术领域,具体涉及一种基于机器学习的多花卉质量分级方法。
背景技术:
2.花卉是具有观赏价值的草本植物,是用来描绘欣赏的织物的统称,通常喜阳且耐寒,具有繁殖功能的短枝。花农或生产商通常将属于同一个品种的花卉栽培在一起,构成花卉丛,而在花卉栽培的过程中则定期检查花卉的生长是否达到质量标准,花农或生产商通常通过目测花瓣的色度来判断花卉的质量,这种通过目测实现质量分级的方式效率极低,其获得的花卉质量分级结果误差大、准确率低。因此,在花卉栽培时对花卉进行质量分级存在一定的困难。
技术实现要素:
3.本发明的目的是提供一种基于机器学习的多花卉质量分级方法,以解决现有技术中所存在的一个或多个技术问题,至少提供一种有益的选择或创造条件。
4.本发明解决其技术问题的解决方案是:提供一种基于机器学习的多花卉质量分级方法,应用于分级系统,所述分级系统包括:设置有图像采集模块、预处理模块、花卉分类模块、花卉分级模块和处理器模块;包括以下步骤:
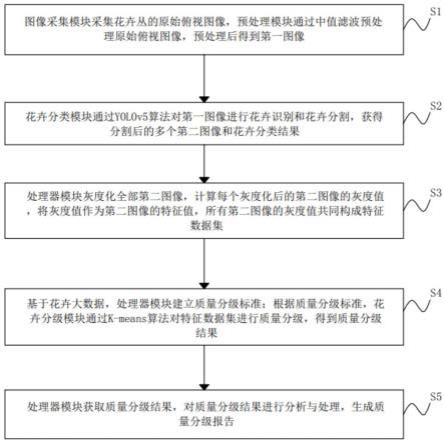
5.s1、图像采集模块采集花卉丛的原始俯视图像,预处理模块通过中值滤波预处理原始俯视图像,预处理后得到第一图像;
6.s2、花卉分类模块通过yolov5算法对第一图像进行花卉识别和花卉分割,获得分割后的多个第二图像和花卉分类结果;
7.s3、处理器模块灰度化全部第二图像,计算每个灰度化后的第二图像的灰度值,将灰度值作为第二图像的特征值,所有第二图像的灰度值共同构成特征数据集;
8.s4、基于花卉大数据,处理器模块建立质量分级标准;根据质量分级标准,花卉分级模块通过k-means算法对特征数据集进行质量分级,得到质量分级结果;
9.s5、处理器模块获取质量分级结果,对质量分级结果进行分析与处理,生成质量分级报告。
10.作为上述技术方案的进一步改进,步骤s1中所述中值滤波满足以下公式:
11.g(x,y)=med{f(x-i,y-j),(i,j∈a)};
12.其中,函数f(x,y)为原始俯视图像,g(x,y)为第一图像,a为二维模板,a选取为3
×
3区域。
13.作为上述技术方案的进一步改进,在所述花卉分类模块通过yolov5算法对第一图像进行花卉识别和花卉分割,获得分割后的多个第二图像和花卉分类结果,该方法还包括:
14.s21、基于花卉大数据,处理器模块收集并编号多个花卉品种的样本图像,构成样本数据集,以7:3的比例关系划分样本数据集为训练集和测试集;
15.s22、通过标注工具标注训练集和测试集中的样本图像的感兴趣区域,每个样本图像具有对应的一个或多个的样本标签,所有样本标签构成标签数据集;
16.s23、处理器模块设定网络模型的超参数和结束阈值;花卉分类模块将训练集的样本图像作为yolov5网络的输入,将训练集的样本标签集作为yolov5网络的输出,花卉分类模块训练yolov5网络模型;
17.s24、当损失函数小于等于结束阈值时,yolov5网络模型训练结束,花卉分类模块输出yolov5网络模型的核参数,并通过测试集评价该网络模型的性能;
18.s25、将第一图像输入至训练好的yolov5网络模型,通过yolov5网络模型对第一图像实现花卉识别和花卉分割,获得分割后多个第二图像,并生成花卉分类结果。
19.作为上述技术方案的进一步改进,步骤s3中处理器模块通过加权平均值法灰度化全部第二图像,其中设定第二图像的r通道、g通道的权值均为40%、其b通道的权值为20%,计算得到的r通道、g通道、b通道任一值为灰度值,将第二图像的灰度值作为其特征值。
20.作为上述技术方案的进一步改进,在所述基于花卉大数据,处理器模块建立质量分级标准;根据质量分级标准,花卉分级模块通过k-means算法对特征数据集进行质量分级,得到质量分级结果,该方法还包括:
21.s41、基于花卉大数据,处理器模块根据花卉的品种建立对应的质量分级标准,并根据花卉分类结果确定特征数据集所属的花卉品种,获取该品种的质量分级标准;
22.s42、处理器模块将特征数据集的数据类型转换为双精度数据类型;花卉分级模块通过优化策略选取特征数据集的初始化质心,初始化质心为聚类中心,特征数据集的初始化质心的数量为3;
23.s43、将特征数据集的特征值作为输入,花卉分级模块计算特征数据集的特征值与特征数据集的三个聚类中心的欧氏距离;
24.s44、花卉分级模块根据距离最近准则将特征数据集的特征值分到距离该特征值最近的聚类中心所对应的类,生成质量分级结果。
25.作为上述技术方案的进一步改进,所述花卉分级模块通过优化策略选取特征数据集的初始化质心,初始化质心为聚类中心,特征数据集的初始化质心的数量为3的步骤为:
26.s411、从特征数据集中随机选择一个特征值作为特征数据集的第i聚类中心(i=1);
27.s412、计算特征数据集的每个特征值与所述第i聚类中心的距离;
28.s413、计算特征数据集的每个特征值被选为特征数据集的第i 1聚类中心的概率;
29.s414、选择概率最大的特征值作为特征数据集的第i 1聚类中心;
30.s415、判断i是否等于3;如果否,则执行步骤s416;
31.s416、i=i 1,循环执行步骤s412至s415;
32.如果i等于3,则执行步骤s417;
33.s417、输出特征数据集的三个聚类中心。
34.作为上述技术方案的进一步改进,所述每个特征值与所述第i聚类中心的距离满足以下公式:
[0035][0036]
其中,xk为特征数据集中的第k个特征值,yi为第i聚类中心,d(xk)表示某特征值xk与所述第i聚类中心yi的距离,i=1,2,3。
[0037]
作为上述技术方案的进一步改进,所述每个特征值被选为第i 1聚类中心的概率满足以下公式:
[0038][0039]
其中,pk为特征数据集中的第k个特征值xk被选为第i聚类中心yi的概率。
[0040]
本发明的有益效果是:本发明公开了一种基于机器学习的多花卉质量分级方法,图像采集模块采集花卉丛的原始俯视图像并通过预处理模块预处理获得第一图像,第一图像中包含同一品种的多朵花朵;花卉分类模块通过深度学习算法对第一图像进行花卉分类和花卉分割,获得分割后的多个第二图像和花卉分类结果,花卉分类结果为全部第二图像所属的花卉品种名称;处理器模块将第二图像灰度化后获得其灰度值,将灰度值作为第二图像的特征值,根据质量分级标准花卉分级模块通过k-means算法对每个第二图像进行质量分级,分为低质量、中质量、高质量三个质量标准,得到更加准确的花卉丛的质量分级结果。本发明能够对花卉丛中多朵花朵进行质量分级,极大地提高了花卉丛质量分级的准确率,并提高了花卉的分级效率。
附图说明
[0041]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单说明。显然,所描述的附图只是本发明的一部分实施例,而不是全部实施例,本领域的技术人员在不付出创造性劳动的前提下,还可以根据这些附图获得其他设计方案和附图。
[0042]
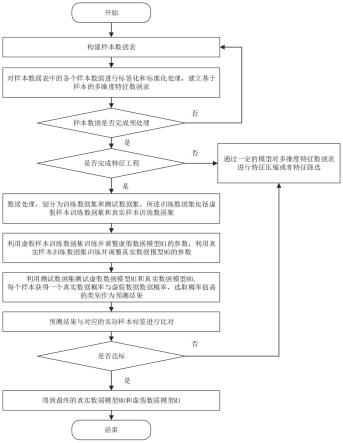
图1是一种基于机器学习的多花卉质量分级方法的工作流程图;
[0043]
图2是一种基于机器学习的多花卉质量分级方法的模块示意图;
[0044]
图3是一种基于机器学习的多花卉质量分级方法的多花卉分类的工作流程图;
[0045]
图4是一种基于机器学习的多花卉质量分级方法的花卉质量分级的工作流程图;
[0046]
图5是一种基于机器学习的多花卉质量分级方法的通过优化策略选取初始化质心的工作流程图。
具体实施方式
[0047]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术。
[0048]
需要说明的是,虽然在系统示意图中进行了功能模块划分,在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于系统中的模块划分,或流程图中的顺序执行所示出或描述的步骤。说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
[0049]
参照图1至图5,一种基于机器学习的多花卉质量分级方法,应用于分级系统,所述分级系统包括:设置有图像采集模块100、预处理模块200、花卉分类模块300、花卉分级模块400和处理器模块500;
[0050]
还包括以下步骤:
[0051]
s1、图像采集模块采集花卉丛的原始俯视图像,预处理模块通过中值滤波预处理原始俯视图像,预处理后得到第一图像;
[0052]
s2、花卉分类模块通过yolov5算法对第一图像进行花卉识别和花卉分割,获得分割后的多个第二图像和花卉分类结果;
[0053]
s3、处理器模块灰度化全部第二图像,计算每个灰度化后的第二图像的灰度值,将灰度值作为第二图像的特征值,所有第二图像的灰度值共同构成特征数据集;
[0054]
s4、基于花卉大数据,处理器模块建立质量分级标准;根据质量分级标准,花卉分级模块通过k-means算法对特征数据集进行质量分级,得到质量分级结果;
[0055]
s5、处理器模块获取质量分级结果,对质量分级结果进行分析与处理,生成质量分级报告。
[0056]
本实施例中步骤s1,图像采集模块100采集花卉丛的原始俯视图像,所述第一图像中包含多朵属于同一品种的花朵;所述中值滤波满足公式1:
[0057]
g(x,y)=med{f(x-i,y-j),(i,j∈a)}
ꢀꢀꢀꢀꢀꢀ
公式1
[0058]
其中,函数f(x,y)为原始俯视图像,g(x,y)为第一图像,a为二维模板,a选取为3
×
3区域。
[0059]
中值滤波法是一种非线性平滑技术,其基本原理为把数字图像或数字序列中一点的值用这个点的一个邻域中各点值的中值进行代替,让周围的像素值接近真实值,进而达到滤除噪声的目的。并且,中值滤波法在滤除噪声的同时能够保护图像的边缘,避免产生边缘模糊。本发明通过图像采集模块100采集的原始俯视图像中含有大量的噪声,预处理模块200使用中值滤波法对原始俯视图像的噪声进行滤除,在滤除噪声的同时也保证了图像边缘的清晰度和完整性,避免了原始俯视图像像素的丢失。
[0060]
优选的,所述二维模板选取为n
×
n区域,其中n≥3且n为奇数,n优选为3。在本技术其他实施例中,n可以为其他大于等于3的奇数值。
[0061]
请参照图3,步骤s2中花卉分类模块300通过yolov5算法对第一图像进行花卉识别和花卉分割,获得分割后的多个第二图像和花卉分类结果,该步骤还可以通过下述步骤实现:
[0062]
s21、基于花卉大数据,处理器模块收集并编号多个花卉品种的样本图像,构成样本数据集,以7:3的比例关系划分样本数据集为训练集和测试集;
[0063]
s22、通过标注工具标注训练集和测试集中的样本图像的感兴趣区域,每个样本图像具有对应的一个或多个的样本标签,所有样本标签构成标签数据集;
[0064]
s23、处理器模块设定网络模型的超参数和结束阈值;花卉分类模块将训练集的样本图像作为yolov5网络的输入,将训练集的样本标签集作为yolov5网络的输出,花卉分类模块训练yolov5网络模型;
[0065]
s24、当损失函数小于等于结束阈值时,yolov5网络模型训练结束,花卉分类模块输出yolov5网络模型的核参数,并通过测试集评价该网络模型的性能;
[0066]
s25、将第一图像输入至训练好的yolov5网络模型,通过yolov5网络模型对第一图像实现花卉识别和花卉分割,获得分割后多个第二图像,并生成花卉分类结果。
[0067]
本实施例中步骤s2,所述花卉分类模块300用于对第一图像进行花卉识别与花卉
分割,获得分割后的多个第二图像,生成花卉分类结果,所述第二图像中只包含有一朵花,所述花卉分类结果定义为全部第二图像所属的花卉品种名称。
[0068]
本实施例中,yolov5算法为一种基于回归的目标检测算法,用于识别与分割图像中的感兴趣区域,并对感兴趣区域进行分类。
[0069]
具体地,在步骤21中处理器模块500选取的样本图像为俯视图像,俯视图像包含多种花卉的多朵花朵,所述样本数据集包含多个样本图像。在这个实施例中,所选取的样本图像的数量为1000张,以7:3的比例关系划分样本数据集为训练集和测试集,其中训练集的数量为700张、测试集的数量为300张。
[0070]
在步骤s22中所述标注工具为labelimg、labelme、bbox-label-tool及yolo_mark中的任一个。定义感兴趣区域为样本图像中的每一朵花朵,所述感兴趣区域的数量与样本图像中的花朵的数量相等。根据每一朵花朵所属的品种通过标注工具标注样本标签,每个样本图像具有对应的一个或多个的样本标签,所述样本标签为单一花朵所属的品种信息和该花朵在样本图像上的位置坐标信息,所有样本标签共同构成样本标签集。
[0071]
在步骤s23中所述网络模型的超参数包括初始学习率、迭代次数、批量大小、迭代次数、损失函数及激活函数,当网络模型的超参数不同时最终训练获得的模型也不同,在训练网络模型前设定其超参数尤为重要。本实施例中,设定初始学习率为0.01、批量大小为24、激活函数为leaky relu,通过公式2计算迭代次数,通过公式3计算训练过程中的损失函数:
[0072][0073][0074]
其中,epoch表示迭代次数,n为训练集中的样本图像的数量值,batch_size表示批量大小,loss表示损失函数,其中yi表示yolov5网络模型预测的某个品种的花朵的位置坐标信息,表示实际某个品种的花朵的位置坐标信息。
[0075]
优选的,在神经网络训练过程中,合适的学习率能够使网络模型在合适的时间内收敛到局部最优值,学习率过小时容易导致训练时间过长,学习率过高时容易出现网络模型无法收敛,损失函数的值不断上下震荡,因此选取合适的学习率至关重要。本实施例中通过学习率衰减函数对yolov5网络模型进行训练,目的是使得学习率随着迭代次数的增加而减小,以保证损失函数在离最优值比较近的区域内摆动,所述学习率衰减函数满足公式4:
[0076]
α=r
epoch
·
α0ꢀꢀꢀꢀꢀꢀ
公式4
[0077]
其中,epoch表示迭代次数,r表示衰减率,α0表示初始学习率;本实施例中设定r的值为0.9。
[0078]
在处理器模块500设定yolov5网络模型的超参数和结束阈值后,花卉分类模块300将训练集中的样本图像作为yolov5网络模型的输入,将训练集对应的样本标签集作为yolov5网络模型的输出,训练yolov5网络模型。
[0079]
在步骤s24中当损失函数下降到结束阈值时,yolov5网络模型训练结束,输出yolov5网络模型的核参数,并通过测试集评价该网络模型的性能。
[0080]
所述通过测试集评价该网络模型的性能的步骤为:
[0081]
通过表1对所述测试集进行分类:
[0082]
表1测试集中的样本图像的分类
[0083] 预测为真预测为假真实为真tpfn真实为假fptn
[0084]
其中,tp表示实际为真并且被已训练好的网络模型划分为真的样本数;fp表示实际为假但被已训练好的网络模型划分为真的样本数;fn表示实际为真但被已训练好的网络模型划分为假的样本数;tn表示实际为假并且被已训练好的网络模型划分为假的样本数;
[0085]
花卉分类模块300将测试集输入至已训练好的网络模型中,通过公式5和表1计算已训练好的网络模型的准确率:
[0086][0087]
其中,β表示已训练好的网络模型的准确率。
[0088]
优选的,在上述通过测试集评价该网络模型的性能,如果准确率未达到80%,则重新设定yolov5网络模型的超参数,并循环步骤s23-s24。
[0089]
在步骤s25中,花卉分类模块300将第一图像输入至训练好的yolov5网络模型,通过yolov5网络模型对第一图像实现花卉识别和花卉分割,获得分割后多个第二图像,所述第二图像为单朵花朵,并生成花卉分类结果,所述花卉分类结果定义为全部第二图像所属的花卉品种名称。
[0090]
本实施例中步骤s3,处理器模块500通过加权平均值法灰度化全部第二图像,其中设定第二图像的r通道、g通道的权值均为40%、其b通道的权值为20%;计算得到的r通道、g通道、b通道任一值为灰度值,将第二图像的灰度值作为其特征值,所述特征值在后续进行花卉质量分级时将作为输入,所有第二图像的灰度值共同构成特征数据集。在这个实施例中,花朵的花瓣的颜色的深浅程度可以作为其质量评价标准,将第二图像转化为灰度图像并计算其灰度值,能够更好地反映花瓣的颜色的深浅程度,方便后续进行花卉质量分级。
[0091]
基于上述实施例,请参考图4,步骤s4中基于花卉大数据,处理器模块500建立质量分级标准;根据质量分级标准,花卉分级模块400通过k-means算法对特征数据集进行质量分级,得到质量分级结果,该方法还包括:
[0092]
s41、基于花卉大数据,处理器模块根据花卉的品种建立对应的质量分级标准,并根据花卉分类结果确定特征数据集所属的花卉品种,获取该品种的质量分级标准;
[0093]
s42、处理器模块将特征数据集的数据类型转换为双精度数据类型;花卉分级模块通过优化策略选取特征数据集的初始化质心,初始化质心为聚类中心,特征数据集的初始化质心的数量为3;
[0094]
s43、将特征数据集的特征值作为输入,花卉分级模块计算特征数据集的特征值与特征数据集的三个聚类中心的欧氏距离;
[0095]
s44、花卉分级模块根据距离最近准则将特征数据集的特征值分到距离该特征值最近的聚类中心所对应的类,生成质量分级结果。
[0096]
本实施例中步骤s41,基于花卉大数据,处理器模块500根据花卉的品种建立对应的质量分级标准,所述质量分级标准分为低质量、中质量、高质量三个质量等级,质量标准
通过灰度值来衡量;根据步骤s2中获得的花卉分类结果确定步骤s3中的特征数据集所属的花卉品种,获取对应的质量分级标准。
[0097]
本实施例中步骤s42,处理器模块500将特征数据集中的所有特征值转换为双精度数据类型,其目的是在进行k-means算法花卉质量分级之前统一所有数据的数据类型,以避免在进行质量分级时出现时出现错误。该步骤还设定了特征数据集的初始化质心的数量为3,分别对应低质量、中质量、高质量三个质量等级。
[0098]
请参考图5,步骤s42中花卉分级模块400通过优化策略选取特征数据集的初始化质心,初始化质心为聚类中心,特征数据集的初始化质心的数量为3的步骤为:
[0099]
s411、从特征数据集中随机选择一个特征值作为特征数据集的第i聚类中心(i=1);
[0100]
s412、通过公式6计算特征数据集的每个特征值与所述第i聚类中心的距离:
[0101][0102]
其中,xk为特征数据集中的第k个特征值,yi为第i聚类中心,d(xk)表示某特征值xk与所述第i聚类中心yi的距离,i=1,2;
[0103]
s413、通过公式7计算特征数据集的每个特征值被选为特征数据集的第i 1聚类中心的概率:
[0104][0105]
其中,pk为特征数据集中的第k个特征值xk被选为第i聚类中心yi的概率;
[0106]
s414、选择概率最大的特征值作为特征数据集的第i 1聚类中心;
[0107]
s415、判断i是否等于3;如果否,则执行步骤s416;
[0108]
s416、i=i 1,循环执行步骤s412至s415;
[0109]
如果i等于3,则执行步骤s417;
[0110]
s417、输出特征数据集的三个聚类中心。
[0111]
本实施例中步骤s411,k-means算法在进行前需要选择k个初始质心,最常用的方法为随机选取初始质心,但随机选取初始质心容易造成通过k-means算法获得的最终结果存在极大的误差,因此在k-means算法进行前选取合适的初始质心至关重要。本实施例中通过优化策略选取特征数据集的初始化质心,特征数据集的初始化质心的数量为3,分别对应低质量、中质量、高质量三类表示,以达到选取合适的质点的效果,有效地减小了k-means算法中产生的误差。
[0112]
本实施例中步骤s44,根据距离最近原则将特征数据集的特征值分到距离该特征值最近的聚类中心所对应的类,所述距离最近原则为特征值与某个聚类中心的欧氏距离越小,特征值与该聚类中心的相似度越高,特征值与聚类中心属于同一个类的可能性越高。
[0113]
本实施例中步骤s5,处理器模块500获取质量分级结果,对质量分级结果进行分析与处理,生成质量分级报告,并发送至客户端,用户可通过客户端查看质量分级报告。
[0114]
以上对本发明的较佳实施方式进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可作出种种的等同变型或替换,这些等同的变型或替换均包含在本技术权利要求所限定的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。