1.本发明属于计算机视觉、手势识别、人机交互领域,具体涉及到一种基于多视角渲染的姿态估计方法和装置,适用于人体整体或局部(如人体、人手、人脸等)、动物、机器人、一般刚性或非刚性对象。
背景技术:
2.姿态估计尤其是人手姿态估计是计算机视觉和人机交互领域的热点问题,在虚拟现实,智能控制和终端设备上具有广泛的应用。人手姿态估计任务主要是从图像中检测出人手位置并估计所有关节点三维坐标。人手姿态估计分为基于rgb图像的姿态估计方法和基于深度图像的姿态估计方法。相比于基于rgb图像的姿态估计方法,基于深度图像的姿态估计方法的输入包含更多深度信息,可以更为精准地给出三维人手关节坐标。
3.目前基于深度图像的姿态估计方法主要对深度图像直接提取特征,姿态估计的精度依赖于提取特征的大小。提取过多的特征虽然可以提高精度,但会带来参数量的大幅增加和速度下降。由于深度图像中包含2.5d信息而非3d信息,常用作特征提取的二维卷积不能完整地提取出图像中的深度信息。因此,如何平衡人手姿态估计任务中速度与精度、在保证实时性的情况下提升人手姿态估计的精度是人手姿态估计问题中的关键难点。
技术实现要素:
4.为了解决上述问题,本发明提供了一种基于多视角渲染的姿态估计方法和装置,适用于人体整体或局部(如人体、人手、人脸等)、动物、机器人、一般刚性或非刚性对象。
5.本发明提供一种基于多视角渲染的姿态估计方法,所述方法包括以下步骤:
6.在深度图像中检测出对象区域;
7.从深度图像的对象区域中提取出对象的三维点云;
8.在以对象的三维点云为中心的球面上均匀设置多个虚拟相机;
9.通过神经网络从设置的多个虚拟相机中选择少量适合进行对象姿态估计的虚拟相机;
10.将对象的三维点云投影到选择的虚拟相机上,渲染出多个视角的对象的深度图像;
11.通过三维姿态估计网络,对多个视角的对象的深度图像进行三维姿态估计,得到多个视角的三维对象姿态;
12.融合多个视角的三维对象姿态,得到最终的三维对象姿态。
13.其中,“对象”是指进行姿态估计的对象,如人体整体或局部(如人体、人手、人脸等)、动物、机器人、其他一般刚性或非刚性对象等。
14.进一步地,所述在深度图像中检测出对象区域,包括:对深度图像进行对象检测或分割,获得消除背景的对象图像区域。
15.进一步地,所述从深度图像的对象区域中提取出对象的三维点云,所使用的提取
对象的三维点云的公式如下:
[0016][0017]
其中,u,v,d为深度图像中对象的前景区域上图像点p的图像坐标和深度;k是相机的内部参数矩阵;m是相机的外部参数矩阵,表示相机坐标系和世界坐标系的旋转和平移,表达式为其中r表示相机的旋转矩阵,t表示相机的平移向量;pw=(xw,yw,zw)是图像点p转换到世界坐标系后的三维坐标;将所有位于对象的前景区域的图像点变换到世界坐标系下的点云pw。
[0018]
进一步地,所述在以对象的三维点云为中心的球面上均匀设置多个虚拟相机,是将虚拟相机设置在以对象的三维点云的质心为球心的球面上。
[0019]
进一步地,所述通过神经网络从设置的多个虚拟相机中选择适合进行对象姿态估计的虚拟相机,是使用视角置信度网络选择虚拟相机;所述视角置信度网络从对象的深度图像提取图像特征,并将图像特征映射成预设多个虚拟相机的置信度,选择视角置信度最高的k个虚拟相机进行后续操作。
[0020]
进一步地,所述渲染出多个视角的对象的深度图像,所使用的多视角渲染的公式如下:
[0021][0022]
其中,ik表示第k个虚拟相机渲染的深度图像,ik(u,v)表示渲染深度图像上位于(u,v)位置处的深度值,将世界坐标系下的对象的点云pw投影得到第k个虚拟相机图像上,得到图像点集pk,对于任意点p∈pk,其深度值记为dk(p);公式中s
k,u,v
∈pk表示图像点集pk中像素坐标为(u,v)的点p的集合。
[0023]
进一步地,所述通过三维姿态估计网络,对多个视角的对象的深度图像进行三维姿态估计,得到多个视角的三维对象姿态,是以渲染的深度图作为输入,使用神经网络分别估计k个视角的三维对象姿态。
[0024]
进一步地,所述融合多个视角的三维对象姿态,是对k个视角的关键点(对于人体整体或人手、人脸等局部,关键点可以是关节点;对于非人体对象,可以采用表面特征点或关节旋转中心等作为关键点)坐标进行融合,采用的公式如下:
[0025][0026]
其中,和分别表示第k个视角估计出的三维对象的关键点坐标和融合后的三维对象的关键点坐标,n表示对象的关键点的数量,rk和tk分别为选择的第k个虚拟相机的旋转矩阵和平移向量,ck为置信度权重,通过k个虚拟相机的置信度值执行softmax操作后,得到的第k个视角的置信度权重为ck。
[0027]
本发明还提供一种基于多视角渲染的姿态估计装置,所述装置包括:
[0028]
对象检测模块,用于在深度图像中检测出对象区域;
[0029]
视角选择模块,用于从多个虚拟相机中选择适合进行对象姿态估计的虚拟相机;
[0030]
多视角渲染模块,用于渲染虚拟相机拍摄到的对象的深度图像,即将对象的三维点云投影到选择的虚拟相机上,渲染出多个视角的对象的深度图像;
[0031]
三维对象姿态估计模块,用于通过三维姿态估计网络,从多个视角的对象深度图像中估计三维对象姿态,得到多个视角的三维对象姿态;
[0032]
视角融合模块,用于融合多个视角的三维对象姿态,得到最终的三维对象姿态。
[0033]
本发明的优点和有益效果是:
[0034]
本发明主要解决的问题是保证实时性的情况下提升三维姿态估计任务的精度。本发明提供一种从单张深度图像中提取三维姿态估计的方法和装置。从多个视角进行三维姿态估计,可以有效提高估计精度。从均匀设置的虚拟相机中选择选择少量适合进行姿态估计的虚拟相机,在不损失过多精度的情况下大幅度提高姿态估计的速度。经过实际使用验证,本发明具有自动化程度高、精度高和实时性的优点,可满足专业的或者大众化的应用需求。
[0035]
本发明的姿态估计方法可适用于人体整体、人体局部、动物或机器人、一般刚体或非刚体等;人体局部包括人手、上肢、下肢或人脸等。本姿态估计方法,适用于深度相机、双目相机和激光扫描仪等多种三维视觉传感器的输入数据。
附图说明
[0036]
图1是本发明的整体架构图。
[0037]
图2是本发明的使用多个虚拟相机的示意图。
[0038]
图3是本发明的视角置信度网络的示意图。
[0039]
图4是本发明的三维人手姿态估计与融合的示意图。
具体实施方式
[0040]
下面以人手姿态估计为例,具体说明本发明的方法。
[0041]
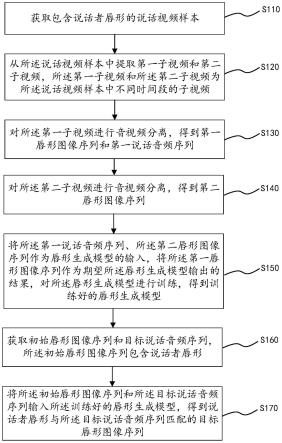
图1概述了本发明的方法。本发明使用单张深度图像作为输入。首先对输入的深度图像进行人手检测,获取人手边界框后从深度图像中裁剪出人手区域的深度图。人手区域的深度图像被输入视角置信度网络,计算出多个预设虚拟相机的置信度,选择其中置信度最高的k个虚拟相机。从人手区域的深度图中提取出人手点云,将其投影到选择的k个虚拟相机上,渲染出k个视角的人手深度图像。通过三维姿态估计网络估计k个视角的三维人手关节点坐标,最后将这些三维人手关节点融合得到最终的三维人手关节点坐标。
[0042]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施例和附图,对本发明做进一步详细说明。
[0043]
步骤1:从深度图像中提取人手点云
[0044]
深度图像中人手前景区域(深度值不为0)上的图像点可以映射成三维世界坐标系。设深度图像中人手前景区域上图像点p坐标为(u,v),深度值为d,其中(u,v)表示图像点在图像坐标系下的坐标。设图像点p对应的世界坐标系下的三维点为pw=(xw,yw,zw),则pw的计算公式为:
[0045][0046]
其中:
[0047][0048][0049]
k是相机的内部参数矩阵,包含f
x
,fy,u0,v0等相机内参参数;m是相机的外部参数矩阵,表示相机坐标系与世界坐标系的旋转和平移,r和t分别的旋转矩阵和平移向量。通过人手检测或人手分割方法检测或分割深度图像中人手的位置,从深度图像中裁剪出人手区域,将人手区域的每个深度非0的图像点转换到世界坐标系下,得到世界坐标系下的人手三维点云pw。
[0050]
步骤2:设置虚拟相机
[0051]
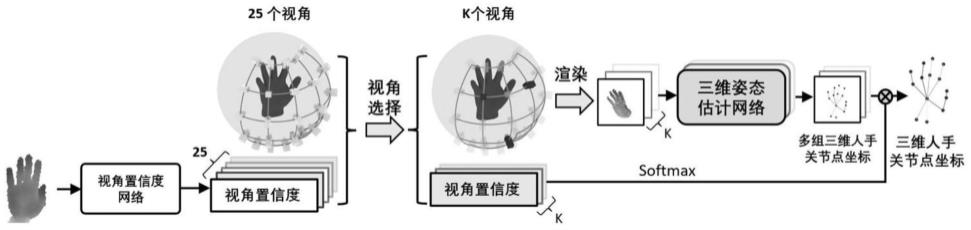
以人手点云的质心为球心构建一个球,半径为质心对应像素坐标系上点的深度值。在球面上预设25个虚拟相机,用相机在球面上的方位角α和高度角β表示相机的位置。方位角和高度角过大会导致渲染出的深度图出现比较严重的遮挡和空洞,所以限制25个预设的虚拟相机在限制的区域上呈5
×
5网格状均匀排布。计算每一个预设的虚拟相机的旋转矩阵r和平移向量t,从而得到每个虚拟相机的外部参数m。虚拟相机效果如图2所示。
[0052]
步骤3:选择虚拟相机
[0053]
将剪裁好人手区域深度图像输入到视角置信度网络中,最后可得到25个预设虚拟相机的置信度。置信度网络如图3所示。网络输入为图像i∈rh×w,h和w是裁剪后的图像的高度和宽度,经过图像特征提取网络(如残差神经网络(resnet18)等)提取得到图像特征,再通过全连接层将特征映射成25个预设虚拟相机的置信度。选取置信度最高的k个虚拟相机视角进行后续操作,其中1≤k≤25,并且k∈z。k为一个超参数,可根据对计算速度的要求选择k的值,k的值越大,计算速度越慢。
[0054]
步骤4:多视角渲染
[0055]
将世界坐标系下的人手点云投影到选择的k个虚拟相机上,即可渲染出k个视角的人手深度图像。设mk表示第k个选择的虚拟相机的外部参数,根据公式(1)可以将世界坐标系下的人手点云pw投影得到第k个虚拟相机图像坐标系下的点集pk,对于任意点p∈pk,其深度值为dk(p)。设s
k,u,v
∈pk表示pk中像素坐标为(u,v)的点p的集合,令第k个虚拟相机渲染出的深度图像为ik,ik(u,v)表示位于(u,v)处图像点的深度值,其计算公式为:
[0056][0057]
步骤5:三维人手姿态估计与融合
[0058]
使用一个三维人手姿态估计网络分别估计k个视角深度图像的三维人手关节点坐标。然后利用步骤4中计算的置信度对k个人手关节点坐标进行融合,得到最终的三维人手
关节点坐标。本发明可以采用a2j网络等作为三维人手姿态估计网络。对步骤4计算得到的k个置信度值执行softmax操作后,得到的第k个视角的置信度权重为ck。设和分别表示第k个视角估计出的三维人手关节点坐标和融合后的三维人手关节点坐标,n表示人手关节点的数量。对k个视角的关节点坐标进行融合的公式为:
[0059][0060]
其中rk和tk分别为选择的第k个虚拟相机的相机坐标系与世界坐标系的旋转矩阵和平移向量。步骤5的流程如图4所示。
[0061]
本发明的方案可以通过软件的方式实现,也可以通过硬件的方式来实现,比如:
[0062]
在一个实施例中,提供一种多视角渲染的人手姿态估计装置,其包括:
[0063]
人手检测模块,用于在深度图像中检测出人手区域;
[0064]
视角选择模块,用于从多个虚拟相机中选择适合进行人手姿态估计的虚拟相机;
[0065]
多视角渲染模块,用于渲染虚拟相机拍摄到的人手深度图像,即将人手三维点云投影到选择的虚拟相机上,渲染出多个视角的人手深度图像;
[0066]
三维人手姿态估计模块,用于通过三维人手姿态估计网络,从多个视角的人手深度图像中估计三维人手姿态,得到多个视角的三维人手姿态;
[0067]
视角融合模块,用于融合多个视角的三维人手姿态,得到最终三维人手姿态。
[0068]
另外,该装置还可包括:
[0069]
1)数据预处理模块,用于对输入的深度图像进行预处理,通过对输入图像的剪裁和缩放与数据增强,使得视角选择与人手姿态估计更加精确;
[0070]
2)网络构建与训练模块,负责构建和训练的视角选择网络与人手姿态估计网络。
[0071]
本发明的方案可以适用于人体整体或局部(如人体、人手、人脸等)、动物、机器人、一般刚性或非刚性对象,也适用于深度相机、双目相机和激光扫描仪等多种三维视觉传感器的输入数据。
[0072]
在另一个实施例中,提供一种电子装置(计算机、服务器、手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
[0073]
在另一个实施例中,提供一种计算机可读存储介质(如rom/ram、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的步骤。
[0074]
本发明中,步骤5中的三维人手姿态估计基本网络并不局限于a2j网络,可以更换为其它类似基本网络。
[0075]
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的原理和范围,本发明的保护范围应以权利要求书所述为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。