基于bert预训练模型的链接生成方法
技术领域
1.本发明属于软件缺陷检测技术领域,涉及一种基于bert预训练模型的链接生成方法。
背景技术:
2.在软件开发过程中,通常使用缺陷报告来跟踪软件开发中的各种问题及进行相关讨论,随后开发者针对缺陷报告中所报告的问题对现有软件进行修改,并及时进行代码提交以保证软件质量和软件正常使用。在软件开发过程中通过缺陷报告和代码提交建立用户和开发人员之间的交流,而缺陷报告和代码提交之间的链接可以加强软件的跟踪性,使得软件开发中各个组件紧密连接,从而维护好产品在开发过程中的可查询性,方便代码检查和功能测试,在软件工程中缺陷预测、bug定位等任务中具有重要价值。
3.缺陷报告和代码提交之间的链接通常需要开发人员通过在代码提交日志中手动添加包含issue标识符(如apache大型开源项目)等方式进行链接,然而,在实践中由于链接工作是非强制性的,因而,在软件开发过程中丢失了大量的链接。
4.手工恢复缺陷报告和代码提交之间的链接是一项工作量巨大且容易出错的困难工作,因而研究人员提出了许多自动化链接技术,包括基于启发式方法的技术和基于深度学习的技术。
5.sun等人提出一种基于文件相关性的方法frlink方法来恢复缺陷报告和代码提交之间的链接。该方法利用代码提交中包括代码更改细节的非源文档文件,基于缺陷报告和代码提交及相关文档的文本相似性进行分类,从缺陷报告和代码提交中提取代码特征和文本特征,使用提取的特征和信息检索技术来确定两者之间的相似性,基于训练数据集学习阈值,最后根据相似度和阈值之间的大小关系以确定是否进行链接,然而,该方法主要依赖于文本相似性特征,缺乏捕获缺陷报告和代码提交之间语义关联的能力,同时简单将代码特征与文本特征以同等权重对待,忽略了两者之间的重要性关系,同时在相关文件较少以及代码术语较少的缺陷报告和代码提交之间难以建立关联。
6.ruan等人提出一种基于深度学习的方法deeplink来恢复缺陷报告和代码提交之间的链接。该方法加强了对缺陷报告和代码提交的语义理解能力,使用词嵌入技术和循环神经网络开发了一个神经网络架构来学习缺陷报告和代码提交中自然语言和编程语言的语义表示以及两者之间的语义关联,但是该方法存在训练数据不足以及神经网络速度慢等技术问题,对数据集的质量和规模有较高的要求,难以在训练数据量小的项目以及中小型项目上使用。
7.目前的自动化链接技术为恢复缺陷报告和代码提交之间的链接方面提供了良好的研究基础,但当前对于链接的跟踪方法仍存在进步空间,先前研究存在较多的问题,主要体现在:
8.基于启发式的方法主要根据元数据匹配等信息制定启发式规则,在链接生成过程中准确度较低;基于深度学习的方法主要依赖于文本相似性信息,缺乏对代码语义信息的
理解能力。此外,这些技术存在训练样本不足(尤其是正确链接样本数量不足)、深度神经网络速度太慢等问题,在链接跟踪实践过程中的使用条件苛刻,在语义理解能力上仍有可提升空间。
技术实现要素:
9.本发明的目的在于提出一种基于bert预训练模型的链接生成方法,通过提高对缺陷报告和代码提交的语义理解能力以提高链接的准确率,同时模型能在训练数据较少的情况下也有很好的效果并且提高运行效率,保证了软件质量和软件的可追溯性,降低了软件维护成本。
10.本发明为了实现上述目的,采用如下技术方案:
11.基于bert预训练模型的链接生成方法,包括如下步骤:
12.步骤1.收集缺陷跟踪系统中的缺陷报告和版本控制仓库中的代码提交,按照开发者手动创建的链接来构建正确链接集和错误链接集;
13.对正确链接集和错误链接集中的链接对应的缺陷报告和代码提交中的信息进行提取并进行预处理,得到缺陷报告中的文本和代码数据以及代码提交中的文本和代码数据;
14.对正确链接集和错误链接集中的链接,分别添加分类标签1和0,将正确链接集和错误链接集组成链接数据集,其中添加分类标签后的链接作为链接数据集中的链接样本;
15.步骤2.对于每个链接样本对应的缺陷报告和代码提交,将提取的文本数据和代码数据两两组合并分别输入到四个预训练模型中对预训练模型进行微调;
16.经过微调后的每个预训练模型,均能够根据该预训练模型的两个输入的相似程度或匹配程度,得到相应的cls聚合向量以表征输入之间的关系;
17.每个链接样本输入到微调后的预训练模型中均会得到一组cls聚合向量,每组cls聚合向量包含四个cls聚合向量,各个cls聚合向量分别由一个微调后的预训练模型得到;
18.将各组cls聚合向量与对应的分类标签组合,形成聚合向量数据集;
19.步骤3.将步骤2得到的聚合向量数据集中各组cls聚合向量输入到卷积神经网络中进行卷积和池化操作以提取特征,再输入到全连接层训练,得到卷积神经网络分类模型;
20.步骤4.对于给定的缺陷报告s和代码提交m,将它们输入到经过由微调后的预训练模型以及训练好的卷积神经网络分类模型组成的整体模型中,进而确定缺陷报告s和代码提交m之间是否进行链接,从而实现缺失链接的自动恢复。
21.本发明具有如下优点:
22.如上所述,本发明述及了一种基于bert预训练模型的链接生成方法,该链接生成方法通过使用bert预训练模型,以更好的提取缺陷报告和代码提交中的文本和代码语义信息,从而提高了对缺陷报告和代码提交的语义理解能力,提高了链接的准确率;此外,本发明方法通过选用预训练模型,使得模型能够在训练数据较少的情况下,也能有很好的效果并且提高运行效率,进而保证了软件质量以及软件的可追溯性,降低了软件维护成本。本发明很好地解决了神经网络和机器学习训练数据不足的问题,使得自动链接工作能够有效地应用于中小型软件项目中,同时加快了训练速度,提高了链接跟踪的效率和准确率。
附图说明
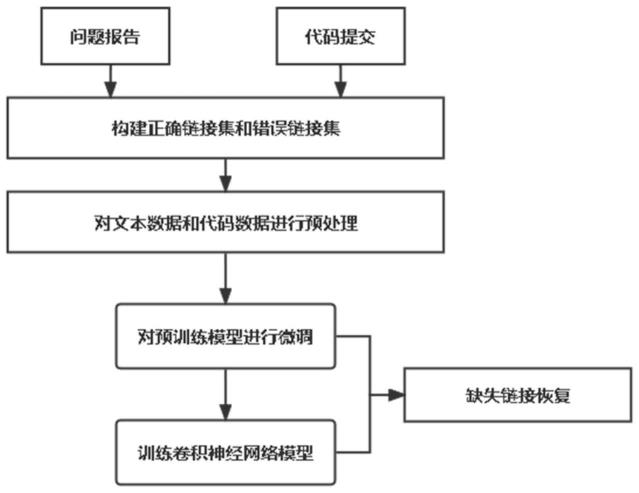
23.图1为本发明实施例中基于bert预训练模型的链接生成方法的流程框图;
24.图2为本发明实施例中基于bert预训练模型的链接生成方法的模型结构图;
25.图3为本发明实施例中卷积神经网络的结构示意图;
26.图4为本发明实施例中卷积核与各个cls聚合向量进行卷积操作的示意图。
具体实施方式
27.软件演化过程中,缺陷报告和代码提交分别反映了软件的使用情况和开发情况,均包含丰富的软件演化信息,而两者之间的链接则连接了两个活动,广泛应用于缺陷预测、提交分析、功能定位等软件维护过程中,本发明通过加强对缺陷报告和代码提交中文本和代码中语义信息的理解,弥合了文本信息与代码信息之间的语义鸿沟,使其能够在较小的数据集或小型项目上出色的完成链接生成任务,以保证软件的可维护性和可追溯性。
28.基于此,本发明提出一种基于bert预训练模型的链接生成方法,利用bert模型以实现缺陷报告和代码提交之间的自动链接,采用一系列有效的预处理技术和方法完成数据收集和处理工作,选取经过预训练的codebert模型进行微调,更好的提取缺陷报告和代码提交中的语义信息,使得模型在熟练数据较少的情况下也能有较好的效果,提高链接生成的准确率;最后通过卷积神经网络完成二分类工作,确定缺陷报告与代码提交之间的链接关系。
29.下面结合附图以及具体实施方式对本发明作进一步详细说明:
30.如图1和图2所示,基于bert预训练模型的链接生成方法,包括如下步骤:
31.步骤1.数据收集及处理。
32.收集缺陷跟踪系统(如bugzilla和jira等)中的缺陷报告(issue)和版本控制仓库(如git和svn等)中的代码提交(commit)信息。
33.按照开发者手动创建的链接来构建正确链接集和错误链接集。
34.对正确链接集和错误链接集中的链接所对应的缺陷报告和代码提交中的信息进行提取并进行预处理,得到缺陷报告中的文本和代码数据以及代码提交中的文本和代码数据。
35.对正确链接集和错误链接集中的链接分别添加分类标签1和0,正确链接集和错误链接集中所有链接一起组成链接数据集,用于后续训练模型(codebert微调和cnn分类))。
36.步骤1.1.根据stars数、commits提交频率及项目开发时间信息筛选出版本控制仓库为git,缺陷跟踪系统为jira,且具有高活跃度的成熟软件系统。
37.步骤1.2.数据过滤,过滤缺陷跟踪系统中无效的缺陷报告,如特征报告、重复缺陷报告以及没有关闭的缺陷报告(这部分缺陷报告没用、甚至可能造成噪声)等。
38.步骤1.3.构建正确链接集ls
t
和错误链接集lsf,作为后续训练模型的链接数据集。
39.对于缺陷报告s和代码提交m,《s,m》即为两者之间的链接。
40.a).正确链接集的构建:根据代码提交信息描述中是否包含缺陷报告标识符及编号方式,将开发者手动完成的链接,加入到正确链接集ls
t
中。
41.b).错误链接集的构建:对于每个代码提交m,根据提交日期,选取在该代码提交m提交日期前后7天内的缺陷报告s加入集合s中;选取在代码提交的提交时间前后7天内的所
有缺陷报告,这些缺陷报告与给定的代码提交组成潜在链接。
42.对于集合s中每个缺陷报告s,将其与代码提交m组成潜在链接《s,m》。
43.若链接《s,m》不在正确链接集ls
t
中,但是存在一个缺陷报告s1与该代码提交m的链接《s1,m》在正确链接集ls
t
中,则认为该链接《s,m》为错误链接,加入错误链接集lsf中。
44.步骤1.4.对步骤1.3中收集的正确链接集和错误链接集中的链接所对应的缺陷报告和代码提交中的信息进行提取以及预处理,提取以及预处理过程包括:
45.对缺陷报告中的标题、描述进行拼接,组成issue text文本数据;
46.将缺陷报告描述中的代码提取为issue code代码数据;
47.将代码提交信息中的描述信息标记为commit text文本数据;
48.将代码提交信息中的代码更改信息标记为commit code代码数据;
49.并对缺陷报告和代码提交中的issue text文本数据和commit text文本数据删除超链接信息、移除标签,删除代码信息,并采用分词、提取词干和去除停用词技术进行处理。
50.步骤1.5.将正确链接集和错误链接集中的链接分别添加分类标签1和0,并作为链接数据集中的链接样本;其中错误链接样本与正确链接样本数量相等,以构建平衡的链接数据集。
51.步骤2.微调预训练模型。
52.对于每个链接样本所对应的缺陷报告和代码提交,将提取的文本数据和代码数据两两组合并分别输入到四个预训练模型中对四个预训练模型进行微调。本步骤利用目前在自然语言处理(natural language processing,nlp)领域具有出色表现的bert作为底层语言模型,该模型使用预训练和微调的方式来进行训练,以完成下游任务。根据下游任务进行微调后的预训练模型,将根据两个输入的相似程度或匹配程度输出相应的cls聚合向量。
53.步骤2.1.选用微软提供的codebert模型作为预训练模型。该模型使用基于多层transformer的神经架构构建而成,在大量自然语言和编程语言上进行训练得到预训练模型,能够捕捉自然语言和编程语言之间的语义连接,有效对自然语言和编程语言进行处理。
54.步骤2.2.为了充分利用缺陷报告和代码提交中的信息,将每个链接样本所对应的缺陷报告和代码提交中的文本数据和代码数据两两组合,即分别将issue text-commit text对、issue code-commit code对、commit code-issue text对、issue text-commit code对作为四个codebert模型的输入,分别对四个codebert模型进行微调,通过对原预训练模型的参数进行更新,使微调后得到的codebert模型更符合下游任务,微调后的每个codebert模型可以将两个文本/代码片段作为输入,输出[cls]的向量表示作为聚合序列表示以及每个token的向量表示。
[0055]
步骤2.3.将每个链接样本输入微调后的codebert模型后,均会得到一组cls聚合向量,每组cls聚合向量包括四个cls聚合向量。
[0056]
各个cls聚合向量分别是由一个微调后的codebert模型输出得到的,这四个cls聚合向量分别定义为聚合向量cls1、cls2、cls3、cls4,每个聚合向量的维度为d。
[0057]
将由每个链接样本所对应的缺陷报告和代码提交得到的一组cls聚合向量与对应的分类标签进行组合,得到用于卷积神经网络分类模型训练的聚合向量数据集。
[0058]
本发明使用预训练模型以解决神经网络和机器学习训练数据不足的问题,使得自动链接能够有效地应用于中小型软件项目中,同时加快训练速度,提高链接跟踪的效率和
准确率。
[0059]
步骤3.卷积神经网络分类模型训练。
[0060]
将步骤2得到的聚合向量数据集输入到卷积神经网络用于训练分类模型,聚合向量数据集中每组cls聚合向量都是由四个cls聚合向量进行拼接。
[0061]
卷积神经网络分类模型训练首先需要对分类模型中的参数进行初始化,主要包括前向传播和反向传播两个阶段,其中,前向传播过程如图3所示,将各组cls聚合向量输入到卷积神经网络中进行卷积和池化操作以提取特征,再输入全连接层训练分类模型。
[0062]
步骤3.1.初始化卷积神经网络的权重参数,包括卷积层和全连接层中的权重参数。
[0063]
步骤3.2.卷积神经网络的前向传播过程,具体包括:
[0064]
步骤3.2.1.卷积层的前向传播过程:对于聚合向量数据集中各组cls聚合向量,分别以多个相同尺寸的卷积核进行卷积操作,然后通过激活函数relu得到输出的特征图。
[0065]
其中,卷积核的高度为1,宽度与cls聚合向量的维度d相同。
[0066]
步骤3.2.2.池化层的前向传播过程:对步骤3.2.1激活处理后的对应每组cls聚合向量的结果分别进行最大池化操作,然后将池化后的结果进行级联,得到用于分类的特征向量;
[0067]
步骤3.2.3.全连接的前向传播过程:将步骤3.2.2中的特征向量输入到全连接层进行分类,通过softmax激活函数完成二分类;其中,softmax激活函数的计算公式如下:
[0068][0069]
其中xi为神经网络中第i个节点的输出值,c为分类类别数量,此处为二分类,则c=2。
[0070]
本实施例中以六个卷积核为例,对本实施例中卷积运算的过程作进一步详细说明(每个卷积核的大小为1*d,实际上不止六个卷积核,此处只是示例说明):
[0071]
如图4所示,对于一组cls聚合向量,使用每个1*d的卷积核进行卷积操作,并经过relu激活函数进行激活处理,一组cls聚合向量与每个卷积核进行卷积操作后会得到一个4*1的特征图,从而得到6个4*1的特征图,然后进行最大池化操作,选出每个特征图中最大的特征,并级联拼成特征向量输入全连接层以完成二分类。
[0072]
步骤3.3.卷积神经网络的反向传播过程。
[0073]
根据神经网络输出的结果进行反向传播过程,求出神经网络的输出结果与期望值之间的误差,当误差等于或小于预设的阈值时,即得到最终的卷积神经网络分类模型。
[0074]
否则,将误差一层层返回,对全连接层和卷积层的参数进行权重更新。
[0075]
步骤4.对于给定的缺陷报告s和代码提交m,输入到最终训练好的分类模型中,确定缺陷报告s和代码提交m之间是否进行链接,实现缺失链接的自动恢复。
[0076]
对于给定的缺陷报告s和代码提交m,将其输入到经过微调后的codebert模型及训练好的卷积神经网络分类模型组成的整体模型中,并进行自动化链接的过程如下:
[0077]
codebert模型将根据输入相似程度或匹配程度输出相应的cls聚合向量。
[0078]
对于潜在链接《s,m》,得到一组cls聚合向量。
[0079]
取该组cls聚合向量中多个cls聚合向量传入训练好的神经网络分类模型进行处
理。
[0080]
在经过卷积层、relu激活函数、池化层后,经过全连接层进行二分类,以确定给定的缺陷报告s和代码提交m之间是否应该进行链接,实现缺失链接的自动恢复。
[0081]
本发明通过缺陷报告和代码提交之间多个聚合向量挖掘缺陷报告和代码提交之间的文本和代码关联关系,并借助卷积神经网络对聚合向量提取有效信息以完成进一步分类。
[0082]
当然,以上说明仅仅为本发明的较佳实施例,本发明并不限于列举上述实施例,应当说明的是,任何熟悉本领域的技术人员在本说明书的教导下,所做出的所有等同替代、明显变形形式,均落在本说明书的实质范围之内,理应受到本发明的保护。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。