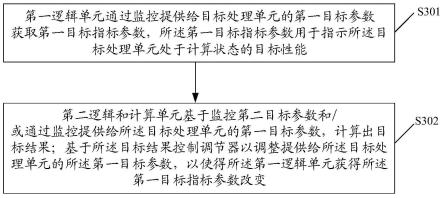
1.本发明涉及计算机视觉和模式识别领域,特别是指融合语义相似性嵌入和度量学习的跨模态图文检索方法。
背景技术:
2.随着多模态数据的爆炸式增长,如何有效挖掘海量数据背后丰富的有价值信息成为研究热点。跨模态检索旨在于在不同模态的数据间(图像、文本、语音、视频等)进行检索,如图像检索文本、文本检索音频、音频检索视频等等,具有非常重要的研究价值。其应用场景也非常广泛,例如视频网站的精彩片段检索、个性化语义短视频检索、智能搜索系统等。
3.然而不同模态的数据间往往呈现底层特征异构而高层语义相关的强异构特性。例如老虎这一语义,在图像特征的表示上有sift、lbp等,但是文本特征的表示是字典向量等,可以看出从特征的描述上同一语义在不同模态数据的表达类型完全不同。因此,跨模态检索的研究十分具有挑战性。
4.在跨模态图文检索中大多数方法采用固定的预先定义好的的距离度量(如欧氏距离或余弦距离)去优化特征嵌入学习或者针对固定特征维度学习传统的线性度量(如马氏距离),这种方法虽然简单易实施,但是此类方法将相似性计算限制在固定维度且无法对不等长维度的特征对的相似性进行有效度量,具有局限性。
技术实现要素:
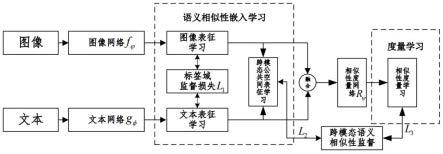
5.本发明的主要目的在于克服现有技术中的上述缺陷,提出一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,首先构建特征嵌入模块抽取每个模态的深度特征,然后在图像和文本的单模态表征空间和跨模态公共表征空间通过标签域监督信息和语义一致性监督信息分别进行表征学习,同时,设计一个深度相似性度量网络对融合后的图像文本对进行相似性比较,得到相似性得分,通过语义相似性矩阵监督相似性学习。通过损失函数将模型统一到一个整体的框架内,训练可得到端到端的跨模态图文检索模型,本发明能够有效解决跨模态图文检索中精确度不高的问题。
6.本发明采用如下技术方案:
7.融合语义相似性嵌入和度量学习的跨模态图文检索方法,步骤如下:
8.输入图像文本对其中xi是输入图像数据,xj是输入的文本数据,其中n表示图像文本对数;
9.根据图像特征提取网络提取图像的深度特征表征向量根据文本特征提取网络g
φ
提取文本的特征表征向量g
φ
(xj),其中图像特征提取网络中的参数代表,φ表示文本特征提取网络中的参数代表;
10.在图像特征提取网络和文本特征提取网络末端分别引入线性分类层,将图像深度特征表征向量和文本的特征表征向量g
φ
(xj)映射到标签空间得到预测图像特征向量
预测文本特征向量txt
p
=p(g
φ
(xj));
11.将图像深度特征表征向量和文本的特征表征向量g
φ
(xj)进行拼接得到拼接向量其中c(
·
,
·
)表示在深度上对特征进行拼接;
12.将拼接向量输入相似性度量网络r
ψ
中得到相似性分数矩阵其中n
image
、n
text
分别表示图像和文本样本集总数;
13.最后将图像深度特征表征向量文本的特征表征向量g
φ
(xj)、预测特征向量预测文本特征向量txt
p
=p(g
φ
(xj))和相似性分数矩阵s
i,j
在单模态表征空间、跨模态公共表征空间和相似性度量学习空间中进行训练学习,得到最后的检索网络模型。
14.具体地,所述的图像数据xi是图像的原始像素特征,文本数据xj是通过word2vec自然语言模型抽取的特征矢量。
15.具体地,所述的图像特征提取网络包括:vgg19网络和若干层全连接神经网络组成,其中vgg19网络初始参数在imagenet上进行预训练和微调得到,全连接神经网络的隐藏层单元数目分别为4096、1024、1024、256和c;其中隐藏层采用relu激活函数,c为数据集的总类别数;
16.所述的文本特征提取网络包括:textcnn网络和若干层全连接层组成,其中全连接层隐含层单元数分别为300、1024、1024、256和c,其中隐含层采用relu激活函数,c为数据集的总类别数。
17.具体地,所述的相似性度度量网络由三层全连接神经网络构成,其中每一层隐藏神经元个数分别为512、1024、1,所有层都采用relu激活函数,最后一层输出层采用sigmoid函数得到相似性分数矩阵s
i,j
。
18.具体地,其所述的单模态表征空间的标签域监督损失l1,定义为:
19.其中l=[y1,y2,...,yn],l表示标签向量,||||f表示frobenius范数。
[0020]
具体地,其所述的跨模态公共表征空间的损失l2,定义为:
[0021][0022]
其中||||f表示frobenius范数。
[0023]
具体地,其所述的度量学习空间的损失l3为:
[0024][0025]
这里令相似性得分回归逼近真实的样本对之间的语义一致性,1表示图像文本样本对之间的相似性矩阵,其元素{0,1}如果两个输入样本对属于同一类则为1,不是同一类则为0;
[0026]
最终得目标函数为:l=l1 λl2 l3,其中λ=0.1。
[0027]
具体地,所述训练采用adam优化器,设置学习率为10-4
,迭代训练500次,得到最终的检索网络模型。
[0028]
由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
[0029]
(1)本发明提出一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,首先构建特征嵌入模块抽取每个模态的深度特征,然后在图像和文本的单模态表征空间和跨模态公共表征空间通过标签域监督信息和语义一致性监督信息分别进行表征学习,同时,设计一个深度相似性度量网络对融合后的图像文本对进行相似性比较,得到相似性得分,通过语义相似性矩阵监督相似性学习。通过损失函数将模型统一到一个整体的框架内,训练可得到端到端的跨模态图文检索模型,本发明能够有效解决跨模态图文检索中精确度不高的问题。
[0030]
(2)本发明提供了一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,该方法着重于充分嵌入学习和非线性度量函数学习有效性,充分利用语义信息的相似性和深度卷积神经网络的非线性逼近特性更高的保留了跨模态数据之间的相似性,进一步提高了跨模态检索的精度。
附图说明
[0031]
图1为本发明融合语义相似性嵌入和度量学习的跨模态图文检索方法的框架示意图;
[0032]
以下结合附图和具体实施例对本发明作进一步详述。
具体实施方式
[0033]
本发明提出一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,首先构建特征嵌入模块抽取每个模态的深度特征,然后在图像和文本的单模态表征空间和跨模态公共表征空间通过标签域监督信息和语义一致性监督信息分别进行表征学习,同时,设计一个深度相似性度量网络对融合后的图像文本对进行相似性比较,得到相似性得分,通过语义相似性矩阵监督相似性学习。通过损失函数将模型统一到一个整体的框架内,训练可得到端到端的跨模态图文检索模型,本发明能够有效解决跨模态图文检索中精确度不高的问题。
[0034]
参见图1所示,本发明一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,其特征在于,步骤如下:
[0035]
1)设计图像特征提取网络和文本特征提取网络接收图像文本对其中xi是输入图像数据,xj是输入的文本数据,其中n表示图像文本对数,每个图像文本对都有一个与之对应的标签向量c是数据集中的类别数,且定义若第i个实例属于第j类,则y
ji
=1,否则y
ji
=0;
[0036]
(2)分别用图像特征提取网络和文本特征提取网络g
φ
提取图像的深度特征表征向量和文本的特征表征向量g
φ
(xj),其中φ表示需要学习图像和文本子网络的网
络参数;
[0037]
(3)在图像网络和文本网络末端分别引入线性分类层将图像和文本表征向量g
φ
(xj)映射到标签空间得到预测特征向量txt
p
=p(g
φ
(xj));
[0038]
(4)将和g
φ
(xj)进行融合其中c(
·
,
·
)表示在深度上对特征进行拼接;
[0039]
(5)将拼接之后的特征送入相似性度量网络r
ψ
中得到相似性分数矩阵i∈{1,n
image
},j∈{1,n
text
},其中n
image
、n
text
分别表示图像和文本样本集总数;
[0040]
(6)最后将g
φ
(xj)、txt
p
=p(g
φ
(xj))和s
i,j
在单模态表征空间,跨模态公共表征空间和相似性度量学习空间中进行训练学习,得到最后的网络模型算法。
[0041]
进一步的,步骤1)中,所述的一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,其特征在于,所述的xi是图像的原始像素特征,xj是通过word2vec自然语言模型抽取的特征矢量,且word2vec模型在google news上进行预训练。
[0042]
进一步的,步骤2)中,所述的一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,其特征在于,所述的图像特征提取网络vgg19网络和若干层全连接神经网络组成,其中vgg19网络初始参数在imagenet上进行预训练和微调得到,全连接神经网络的隐藏层单元数目分别为4096、1024、1024、256和c。其中所有层都采用relu激活函数,c为数据集的总类别数;所述的文本特征提取网络为textcnn网络和若干层全连接层组成,其中全连接层隐含层单元数分别为300、1024、1024、256和c,其中所有层都采用relu激活函数,c为数据集的总类别数。
[0043]
进一步的,步骤3)中,所述的一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,其特征在于,所述的相似性度度量网络由三层全连接神经网络构成,其中每一层隐藏神经元个数为512、1024、1,所有层都采用relu激活函数,最后一层输出层采用sigmoid得到相似性得分s
i,j
。
[0044]
进一步的,步骤4)中,所述的一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,其特征在于,其所述的单模态标签域监督损失l1,其定义为:
[0045]
其中l=[y1,y2,...,yn],l表示标签向量,||||f表示frobenius范数。
[0046]
进一步的,步骤5)中,所述的一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,其特征在于,其所述的跨模态公共表征空间损失l2,其定义为:
[0047][0048]
其中||||f表示frobenius范数。
[0049]
进一步的,步骤6)中,所述的一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,其特征在于,其所述的相似性度量学习空间损失l3为:
[0050][0051]
这里令相似性得分回归逼近真实的样本对之间的语义一致性,1表示图像文本样本对之间的相似性矩阵,其元素{0,1}如果两个输入样本对属于同一类则为1,不是同一类则为0。
[0052]
进一步的,步骤7)中,所述的最终得目标函数为:l=l1 λl2 l3,其中λ=0.1。
[0053]
进一步的,步骤8)中,所述的一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,其特征在于,所述的训练过程采用adam优化器,设置学习率为10-4
,并迭代训练500次,得到最终的检索模型。
[0054]
本发明提出一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,首先构建特征嵌入模块抽取每个模态的深度特征,然后在图像和文本的单模态表征空间和跨模态公共表征空间通过标签域监督信息和语义一致性监督信息分别进行表征学习,同时,设计一个深度相似性度量网络对融合后的图像文本对进行相似性比较,得到相似性得分,通过语义相似性矩阵监督相似性学习。通过损失函数将模型统一到一个整体的框架内,训练可得到端到端的跨模态图文检索模型,本发明能够有效解决跨模态图文检索中精确度不高的问题。
[0055]
本发明提供了一种融合语义相似性嵌入和度量学习的跨模态图文检索方法,该方法着重于充分嵌入学习和非线性度量函数学习有效性,充分利用语义信息的相似性和深度卷积神经网络的非线性逼近特性更高的保留了跨模态数据之间的相似性,进一步提高了跨模态检索的精度。
[0056]
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。