一种otn中实现gmp映射的方法及系统
技术领域
1.本发明涉及gmp(通用映射规程)映射领域,具体涉及一种otn中实现gmp映射的方法及系统。
背景技术:
2.otn(optical transport network,光传送网)因具有强大的综合业务承载能力、可靠的信号管理和监控、灵活的大容量业务调度及疏导等特征,已成为传送网的主流技术。itu g.709协议定义了用于映射客户端信号的otn帧结构、比特率和格式。在映射方法中,由于gmp映射可以很好地将各种不同类型和速率的业务映射到otn帧中,实现业务时钟的透明传输,应用最为广泛。
3.otn光传送网中实现gmp映射,包含两个方面的处理内容。一是发端业务数据的插入和收端业务数据的提取。发端当前帧的cm(number of m-bit client data entities,m比特块客户数据个数)值决定了发端下一帧是否插入以及插入多少填充块,插入填充块的具体位置则由标准规定的sigma-delta算法决定;收端利用收端上一帧的cm值,剥离出当前帧中的所有填充块,并将当前帧承载的业务数据解下来;二是收端利用接收的cm和σc
nd
值恢复出客户侧业务时钟。由于不同的业务对于时钟恢复质量、时延等指标要求不同,gmp映射实现方法也有不同。
4.gmp映射的核心就是如何准确实时计算cm和σc
nd
的值,且得到的cm和σc
nd
值变化最小,以便业务时钟恢复。现有技术主要是发端采样数据通路fifo(first input first output,先进先出)缓存模块的水线,并对水线的变化量进行低通滤波,产生平滑的cm和σc
nd
值。收端利用cm和σc
nd
值恢复业务数据和时钟。这种方法很难滤除gmp映射和解映射过程中产生的高频抖动,对于时钟质量要求不太高的业务(如以太网、低阶odu、sdh)比较有效,但是不能满足无线业务的时钟透传需求。某些厂商的做法是将无线业务的时钟信息通过otn帧的保留开销进行传递,收端利用保留开销的时钟信息进行时钟恢复。这种做法弊端就是,当多种小颗粒业务同时映射到otn帧时,保留开销不一定够用,且无法与别的厂家设备对通。
5.面对无线业务cpri(common public radio interface,通用公共无线电接口)的承载需求,采用传统的gmp映射方法无法满足cpri业务指标的苛刻要求,如恢复时钟频率抖动
±
2ppb,时延抖动
±
8.138ns。
技术实现要素:
6.针对现有技术中存在的缺陷,本发明的目的在于提供一种otn中实现gmp映射的方法及系统,降低业务的传输时延,不需要占用otn的保留开销,可以与别的厂家设备对通,并能满足cpri业务指标的苛刻要求。
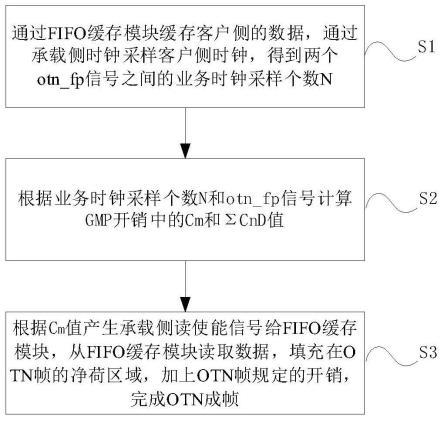
7.为达到以上目的,一方面,采取一种otn中实现gmp映射的方法,包括:
8.通过fifo缓存模块缓存客户侧的数据,通过承载侧时钟采样客户侧时钟,得到两
个otn_fp信号之间的业务时钟采样个数n;
9.根据业务时钟采样个数n和otn_fp信号计算gmp开销中的cm和σc
nd
值;
10.根据cm值产生承载侧读使能信号给fifo缓存模块,从fifo缓存模块读取数据,填充在otn帧的净荷区域,加上otn帧规定的开销,完成otn成帧。
11.优选的,所述根据业务时钟采样个数n和otn_fp信号计算gmp开销中的cm值,包括:
[0012][0013]
其中,k1和k2均为正整数,且p
m,server
表示承载侧能够承载的客户侧颗粒度最大数据块个数,w2表示客户侧的数据位宽,ts表示客户侧占用的时隙数,p表示承载侧otn帧或者复帧的净荷比特数。
[0014]
优选的,每次进行gmp映射时,将cm小数部分与之前每次gmp映射后剩余的小数部分进行累加求和,当累加结果小于1时,cm的整数部分直接作为gmp开销的cm值,累加求和后的小数部分直接转换σc
nd
值;
[0015]
当累加结果大于等于1时,cm的整数部分加1后,作为gmp开销中的cm值,累加求和的小数部分减1后再转换为σc
nd
。
[0016]
优选的,当(k1
×
(n1 n2
…
ni)-k2
×
(c
m1
′
c
m2
′
…
int(c
mi
))《k2时,
[0017]
第i次gmp开销的cm′
=c
mi
′
=int(c
mi
);
[0018]
第i次gmp开销的第i次gmp开销的
[0019]
当(k1
×
(n1 n2
…
ni)-k2
×
(c
m1
′
c
m2
′
…
int(c
mi
))≥k2时,
[0020]
第i次gmp开销的cm′
=c
mi
′
=int(c
mi
) 1;
[0021]
第i次gmp开销的第i次gmp开销的
[0022]
其中,i=1,2,3
……
,int()表示对括号内的数据取整数部分,m表示映射颗粒度,n表示σc
nd
的精度,取值根据otn协议确定。
[0023]
优选的,通过承载侧时钟采样客户侧时钟,得到两个otn_fp之间的业务时钟采样个数n包括:
[0024]
在otn的承载侧每间隔x
×
f/w1个时钟周期,产生一拍高电平有效的otn_fp信号;将otn_fp信号跨时钟域两级同步到业务时钟域cli_clk,得到同步后的指示信号cli_fp;最后在业务时钟域计算两个同步后的指示信号cli_fp之间间隔的业务时钟采样个数n;其中f为携带一个gmp开销的otn帧或者复帧包含的bit数,x为净荷区域的时隙个数,w1表示数据处理位宽。
[0025]
另一方面,采取一种otn中实现gmp映射的系统,包括:
[0026]
客户侧接口模块,用于与客户业务对接,产生客户侧的数据,包括客户侧时钟、客户侧写使能和客户侧写数据;
[0027]
fifo缓存模块,用于缓存客户侧的数据;还用于在接收承载侧读使能后,返回承载侧读数据;
[0028]
客户时钟采集模块,用于通过承载侧时钟采样客户侧时钟,得到两个otn_fp信号之间的业务时钟采样个数n;
[0029]cm
和σc
nd
生成模块,用于根据业务时钟采样个数n和otn_fp信号计算gmp开销中的cm和σc
nd
值;
[0030]
承载侧成帧模块,用于根据cm值产生承载侧读使能信号给fifo缓存模块,接收fifo缓存模块返回的承载侧读数据,填充在otn帧的净荷区域,加上otn帧规定的开销,完成otn成帧。
[0031]
优选的,所述cm和σc
nd
生成模块根据下式计算gmp开销中的cm值,
[0032][0033]
其中,k1和k2均为正整数,且p
m,server
表示承载侧能够承载的客户侧颗粒度最大数据块个数,w2表示客户侧的数据位宽,ts表示客户侧占用的时隙数,p表示承载侧otn帧或者复帧的净荷比特数。
[0034]
优选的,所述cm和σc
nd
生成模块还用于:
[0035]
将cm小数部分与之前每次gmp映射后剩余的小数部分累加求和,当累加结果大于等于1时,cm的整数部分加1后,作为gmp开销中的cm值,求和的小数部分减1后再转换为σc
nd
;
[0036]
当累加结果小于1时,cm的整数部分直接作为gmp开销的cm值,累加求和后的小数部分直接转换σc
nd
值。
[0037]
优选的,所述cm和σc
nd
生成模块的转换过程中,
[0038]
当(k1
×
(n1 n2
…
ni)-k2
×
(c
m1
′
c
m2
′
…
int(c
mi
))《k2时,
[0039]
第i次gmp开销的cm′
=c
mi
′
=int(c
mi
);
[0040]
第i次gmp开销的第i次gmp开销的
[0041]
当(k1
×
(n1 n2
…
ni)-k2
×
(c
m1
′
c
m2
′
…
int(c
mi
))≥k2时,
[0042]
第i次gmp开销的cm′
=c
mi
′
=int(c
mi
) 1;
[0043]
第i次gmp开销的第i次gmp开销的
[0044]
其中,i=1,2,3
……
,int()表示对括号内的数据取整数部分,m表示映射颗粒度,n表示σc
nd
的精度,取值根据otn协议确定。
[0045]
优选的,客户时钟采集模块用于:
[0046]
在otn的承载侧每间隔x
×
f/w1个时钟周期,产生一拍高电平有效的otn_fp信号;将otn_fp信号跨时钟域两级同步到业务时钟域cli_clk,得到同步后的指示信号cli_fp;最后在业务时钟域计算两个指示信号cli_fp之间间隔的业务时钟采样个数n;其中f为携带一个gmp开销的otn帧或者复帧包含的bit数,x为净荷区域的时隙个数,w1表示数据处理位宽。
[0047]
上述技术方案中的一个具有如下有益效果:
[0048]
本发明主要通过otn承载侧的时钟采样客户侧的时钟,得到业务时钟采样个数n,
由于cm和业务时钟采样个数n(即业务时钟采样个数)线性相关,gmp映射的c
nd
值可以由cm的小数部分得到,因此可以将客户侧时钟个数转换成gmp开销中的cm和σc
nd
值,完成gmp映射中关键过程,本发明可以应用在对时钟恢复质量要求较高的场景,降低了业务传输时延,不需要占用otn的保留开销。并且otn成帧完全满足标准,不包含私有协议,可以与别的厂家设备对通。
[0049]
本发明生成的cm和σc
nd
值抖动很小,可以达到比特级别,精度很高,因此恢复时钟性能好;cm值可以快速收敛到稳定状态,减小了gmp映射解映射过程中的缓存fifo的水位变化,降低了业务时延,同时提高了业务时钟恢复精度。
附图说明
[0050]
图1为本发明实施例otn中实现gmp映射的方法流程图;
[0051]
图2为本发明实施例otn中实现gmp映射的系统示意图;
[0052]
图3为本发明实施例otn帧结构示意图;
[0053]
图4为发明实施例gmp映射参数示意图。
具体实施方式
[0054]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0055]
本发明提供一种otn中实现gmp映射的方法的实施例,包括步骤:
[0056]
s1.通过fifo缓存模块缓存客户侧的数据,通过承载侧时钟采样客户侧时钟,得到两个otn_fp信号之间的业务时钟采样个数n。
[0057]
s2.根据业务时钟采样个数n和otn_fp信号计算gmp开销中的cm和σc
nd
值。
[0058]
s3.根据cm值产生承载侧读使能信号给fifo缓存模块,从fifo缓存模块读取数据,填充在otn帧的净荷区域,加上otn帧规定的开销,完成otn成帧。其中,otn成帧包括净荷填充和开销填充,cm用于净荷填充,cm和σc
nd
用于开销填充,协议中otn帧规定的开销包括根据cm和σc
nd
填充的开销。
[0059]
g.709标准中,将一个完整的otn帧净荷区域划分为若干个时隙,每个时隙都对应一个gmp开销。
[0060]
上述步骤s1中,假设携带一个gmp开销的otn帧或者复帧包含f bit,其中净荷区域包含p bit,净荷区域划分为x个时隙(x表示时隙个数),数据处理位宽为w1 bit(w1表示otn成帧时一个时钟周期的数据位宽),那么携带一个gmp开销的otn帧或者复帧占用的时钟个数为f/w1,需要了解的是,系统设计时f/w1结果应为正整数,即一个otn帧或者复帧的数据量占据正整数个时钟周期,否则otn成帧解帧操作由于存在数据拼接难以实现。
[0061]
具体的,在otn的承载侧每间隔x
×
f/w1个时钟周期,产生一拍高电平有效的otn_fp信号,由于每1个时隙对应了一个gmp开销,因此x个时隙的gmp开销在x
×
f/w1个otn时钟周期内传送完成。将otn_fp信号跨时钟域两级同步到业务时钟域cli_clk内,同步后的指示信号用cli_fp表示,在业务时钟域计算两个指示信号cli_fp之间的业务时钟个数n,即n为
获得的客户侧时钟个数。可以理解的是,otn_fp是otn时钟域承载侧的指示信号,cli_fp是业务时钟域客户侧的知识信号,是otn_fp经过时钟域同步后得到的。
[0062]
上述步骤s2中,为了更好的说明根据业务时钟采样个数n和otn_fp信号计算gmp开销中的cm值,下面首先提供一个推导n与cm和σc
nd
值的转化规则的实施例,然后说明在gmp映射中如何生成gmp开销的cm和σc
nd
值。
[0063]
gmp映射规定,对于任何给定的固定比特速率的客户侧信号,在一个承载帧周期或者承载复帧周期内,需要承载的客户侧n比特块的数量为:
[0064][0065]
其中,
[0066]fclient
表示:客户侧的数据比特速率,
[0067]fserver
表示:承载侧的净荷数据比特速率,注:承载侧的数据比特速率》承载侧的净荷数据比特速率》客户侧的数据比特速率。
[0068]
t
server
表示:承载侧帧净荷周期或者净荷复帧周期
[0069]bserver
表示:承载侧一个帧周期或者复帧周期的净荷比特数
[0070]cn
表示:一个承载帧周期或者复帧周期需要承载的客户侧n比特数据块的数量。
[0071]
在otn光传送网领域,以m字节块颗粒度的映射为例,上述(1)式将会是以下形式:
[0072][0073]
(2)式计算的cm非整数,将(2)式cm的整数部分表示为int(cm),小数部分表示为frac(cm),将(2)式改为:
[0074][0075]
一个承载帧或者复帧周期内,客户侧剩余没有映射完的n比特块的数量为c
nd
,c
nd
具有以下表达形式:
[0076][0077]
由(1)、(3)、(4)式可以得到:
[0078][0079]
(5)式说明了gmp映射的c
nd
值可以由(2)式cm的小数部分得到。
[0080]
假设客户侧的数据处理位宽为w2 bit,那么客户侧的时钟频率为假设客户侧的数据占用承载侧x个时隙中的ts个时隙,那么承载侧的数据比特速率为承载侧otn的数据处理位宽为w1bit,承载侧otn帧的时钟频率为客户侧的时钟与承载侧的时钟频率比值应等于同一时间间隔内两个时钟的计数比值,故可以得到:
[0081][0082]
由(2)(6)式可以得到:
[0083][0084]
当客户侧以8
×
mbit为颗粒度(占用ts个时隙),由gmp映射标准可知p
m,server
表示承载侧能够承载的8
×
mbit最大数据块个数。故(7)式可以改为如下:
[0085][0086]
系统设计时,w2为客户侧的数据位宽,ts为客户侧占用的时隙数,承载侧otn帧或者复帧的净荷比特数p,能够承载的最大客户侧数据块个数p
m,server
唯一确定。(8)式说明cm和业务时钟采样个数n线性相关,一一对应,n可以和cm互相转换。(8)式中可以将业务时钟采样个数n的系数写为一个最简分数形式,即:
[0087][0088]
其中,k1和k2均为正整数,且
[0089]
进一步的,下面说明通过业务时钟采样个数n如何生成gmp开销里的cm和σc
nd
值。由于实际gmp开销里的cm、σc
nd
都为正整数,为避免混淆,将实际gmp开销的cm、σc
nd
记为cm′
、σc
nd
′
。第一次gmp映射的cm′
、σc
nd
′
表示为c
m1
′
、σc
nd1
′
,第二次gmp映射的cm′
、σc
nd
′
表示为c
m2
′
、σc
nd2
′
,第i次gmp映射的cm′
、σc
nd
′
表示为c
mi
′
、σc
ndi
′
,i表示第i次gmp映射开销,取值为1,2,3
……
[0090]
假设第一次业务时钟采样个数n用n1表示,相应的(9)式中cm以c
m1
表示;第二次业务时钟采样个数n用n2表示,相应的(9)式中cm以c
m2
表示;第i次业务时钟采样个数n用ni表示,相应的(9)式中cm以c
mi
表示。定义符号int()表示对括号内的数据只取整数部分。int(c
m1
)表示c
m1
的整数部分,int(c
m2
)表示c
m2
的整数部分,int(c
mi
)表示c
mi
的整数部分,以此类推。cm′
、σc
nd
′
生成过程如下:
[0091]
第一次进行gmp映射:
[0092]
第一次gmp开销的cm′
=c
m1
′
=int(c
m1
);
[0093]
此时客户侧剩余没有映射完的n比特块的数量为此时客户侧剩余没有映射完的n比特块的数量为
[0094]
第一次gmp开销的σc
nd
′
=σc
nd1
′
=int(c
nd
),即第一次gmp映射时σc
nd
′
等于c
nd
的整数部分。
[0095]
第二次进行gmp映射时,先判断以cm′
=int(c
m2
)进行映射时剩余累积比特数是否超过gmp映射的颗粒度。判断过程为:由于(9)式中cm的小数部分体现了一次映射剩余没有映射完的比特数,可以将(9)式中c_m的小数部分进行累加求和,当累加结果小于1时,说明剩余累积比特数没有超过gmp映射的颗粒度;当累加结果大于等于1时,剩余累积比特数超
过gmp映射的颗粒度。
[0096]
因此将与1进行比较,由于在逻辑实现过程中小数计算不够简便,可以化为整数比较方式,即k1
×
n1-k2
×cm1
′
k1
×
n2-k2
×
int(c
m2
)与k2进行比较。
[0097]
当前者小于后者时,第二次gmp开销的cm′
=c
m2
′
=int(c
m2
);
[0098]
第二次gmp开销的第二次gmp开销的
[0099]
当前者不小于后者时:
[0100]
第二次gmp开销的cm′
=c
m2
′
=int(c
m2
) 1;
[0101]
第二次gmp开销的第二次gmp开销的
[0102]
从上述过程可以得知,对于每次进行gmp映射,将(9)式中cm小数部分与之前每次gmp映射后剩余的小数部分进行累加求和,当累加结果小于1时,说明剩余累积比特数还不能占满一个映射颗粒度,(9)式中cm的整数部分直接作为gmp开销的cm值,累加求和后的小数部分直接转换σc
nd
值。当累加结果大于等于1时,说明剩余累积比特块数可以占满一个映射颗粒度,(9)式中cm的整数部分需要加1后,作为gmp开销中的cm值,累加求和的小数部分减1后再转换为σc
nd
。
[0103]
对于第i次gmp映射,gmp开销的cm′
、σc
nd
′
可以表示如下:
[0104]
当(k1
×
(n1 n2
…
ni)-k2
×
(c
m1
′
c
m2
′
…
int(c
mi
))《k2时,
[0105]
第i次gmp开销的cm′
=c
mi
′
=int(c
mi
);
[0106]
第i次gmp开销的第i次gmp开销的
[0107]
当(k1
×
(n1 n2
…
ni)-k2
×
(c
m1
′
c
m2
′
…
int(c
mi
))≥k2时,
[0108]
第i次gmp开销的cm′
=c
mi
′
=int(c
mi
) 1;
[0109]
第i次gmp开销的第i次gmp开销的
[0110]
其中,n表示σc
nd
的精度,具体取值根据otn协议确定,常见有1/8、1、或者8。
[0111]
如图2所示,本发明提供一种otn中实现gmp映射的系统实施例,可以用来实现上述实施例。本实施例中,系统包括客户侧接口模块、fifo缓存模块、客户时钟采集模块、cm和σc
nd
生成模块和承载侧成帧模块。
[0112]
客户侧接口模块,用来与客户业务对接,产生客户侧的数据,客户侧的数据包括客户侧时钟、客户侧写使能和客户侧写数据,客户侧数据发送给fifo缓存模块,并且客户侧时钟还发送给客户时钟采集模块。
[0113]
fifo缓存模块,用于缓存客户侧的数据;还用于在接收到承载侧成帧模块发送过来的读使能后,将承载侧读数据发送给承载侧成帧模块。
[0114]
客户时钟采集模块,用于根据承载侧成帧模块送过来的otn_fp信号采样客户侧时钟,得到两个otn_fp信号之间的业务时钟采样个数n,并将业务时钟采样个数n送给cm和σc
nd
生成模块。
[0115]cm
和σc
nd
生成模块,用于根据业务时钟采样个数n和otn_fp信号,计算gmp开销中的cm和σc
nd
值,送给承载侧成帧模块。
[0116]
承载侧成帧模块,用于根据cm值产生承载侧读使能信号,发送给fifo缓存模块,还用于接收fifo缓存模块返回的承载侧读数据,将承载侧读数据填充在otn帧的净荷区域,加上otn帧规定的开销,完成otn成帧操作。
[0117]
可以知道的是,fifo缓存模块和承载侧成帧模块可以由本领域内的通用方法实现。
[0118]
为了进一步清晰阐述该gmp映射的具体实施方案,以cpri到某otn帧的gmp映射为例,说明上述系统实现gmp映射的过程。
[0119]
如图3所示,为某otn帧(以下称之为flexo_fr帧)的帧结构。flexo_fr帧结构为128行x 5280列结构,第1行第1~256列为am(帧对齐区域),第1行第257~512列为oh(开销)区域,每行的第5141~5280列为fec(前向纠错)区域,其它为净荷区域,净荷区域划分为24个时隙。gmp开销通过一个复帧(包含8个flexo-fr帧)传递。
[0120]
协议规定cpri业务映射到flexo_fr帧里,需要先将cpri接口数据进行8b10b解码,再进行64b66b编码,通过bmp映射到oduflex中,再将oduflex通过gmp映射到flexo_fr帧中。如图4所示,为gmp映射参数图,其中y表示cpri的字长,以byte为单位,不同的y值对应不同的cpri速率,且cpri业务线速率为491.52m
×y×
10/8。ts表示cpri在承载侧占用的时隙数。
[0121]
上述系统中,客户侧钟采集模块具体包括:
[0122]
首先,在otn的承载侧(时钟域)每间隔x
×
f/w1个时钟周期,产生一拍高电平有效的otn_fp信号;将otn_fp信号跨时钟域两级同步到业务时钟域cli_clk,得到同步后的指示信号cli_fp;最后在业务时钟域计算两个指示信号cli_fp之间间隔的始终个数,即为业务时钟采样个数n;其中f为携带一个gmp开销的otn帧或者复帧包含的bit数,x为净荷区域的时隙个数,w1表示数据处理位宽,每次计算n的误差为
±
1。
[0123]
下面通过两个实施例来说明客户侧钟采集模块具体实现过程。
[0124]
以cpri-7通过gmp映射到flexo_fr帧为例,系统设计时otn帧数据位宽w1=80bit。otn的时钟每间隔x
×
f/w1=24
×
5280
×
128
×
8/80=1622016个时钟周期产生一个otn_fp信号;otn_fp信号跨时钟域(采用两级同步方法)同步到业务时钟域cli_clk,同步后的信号为cli_fp;在业务时钟域对两个cli_fp之间的周期间隔进行计数,计数值为n。标称频率下,第1次计数值n1为1230621,第2次计数值n2为1230621,第3次计数值n3为1230622,每次计数n的误差为
±
1。
[0125]
以cpri-4通过gmp映射到flexo_fr帧为例,系统设计时otn帧数据位宽w1=80bit。otn的时钟每间隔x
×
f/w1=24
×
5280
×
128
×
8/80=1622016个时钟周期产生一个otn_fp信号;otn_fp信号跨时钟域(采用两级同步方法)同步到cpri-4的时钟域,同步后的信号为cli_fp;在cpri-4时钟域对两个cli_fp之间的周期间隔进行计数,计数值为n。标称频率下,第1次计数值n1为384569,第2次计数值n2为384569,第3次计数值n3为384570,第4次计数值n4为384539,...,每次计数n的误差为
±
1。
[0126]
上述系统中,cm和σc
nd
生成模块具体计算cm和σc
nd
值的实现过程如下:
[0127]
首先对于一个业务时钟采样个数n,根据上述实施例中的(9)式计算出cm值,然后将(9)式中cm的小数部分与之前每次gmp映射后剩余的小数部分累加求和,需要注意的是,第一次gmp映射时之前gmp映射累积剩余的小数部分为0。进而判断求和结果是否大于等于1。
[0128]
当累加结果大于等于1时,gmp开销中的cm′
等于(9)式中的整数部分加1,求和后的小数部分减1后再转换为σc
nd
′
。求和后的小数部分减1后,作为本次及之前gmp映射时累积没有映射完的剩余小数部分。
[0129]
当累加结果小于1时,gmp开销中的cm′
等于(9)式中的整数部分,求和后的小数部分直接转换为σc
nd
′
,求和后的小数部分作为本次及之前gmp映射时累积没有映射完的剩余小数部分。
[0130]
下面结合图3和图4详细进行说明。一个完整携带gmp开销的flexo_fr复帧包含5280
×
128
×
8bit,有效净荷为p=(5140
×
128-4
×
128)
×
8bit。p
m,server
=41088。
[0131]
以cpri-7通过gmp映射到flexo_fr帧为例,系统设计时,客户侧数据位宽为cpri-7业务线速率经过8b10b解码,数据处理位宽为32bit,cpri-7数据经过64b/66b编码,再通过bmp映射到oduflex中,最终等效的客户侧数据位宽即oduflex数据位宽,为w1=32
×
66/64
×
239/238,oduflex占用flexo_fr帧的8个时隙,即ts=8,映射颗粒度m=16
×
8byte。由上述实施例中的(8)式可得并化为最简分数形式:
[0132][0133]
上式可以简化为:
[0134][0135]
上式中分子分母存在最大公约数32
×
32
×
41088=2629632。
[0136]
那么(9)式化为最简分数可以得到k1=7887,k2=243712。
[0137]
第1次gmp映射,n1=1230621,首先判断k1
×
(n1)-k2
×
(int(c
m1
))与k2的比较结果,前者k1
×
(n1)-k2
×
(int(c
m1
))=77427,前者比后者k2小。
[0138]
第1次gmp开销
[0139][0140]
第2次gmp映射,n1=1230621,首先判断k1
×
(n1 n2)-k2
×
(c
m1
′
int(c
m2
)与k2的比较结果,前者k1
×
(n1 n2)-k2
×
(c
m1
′
int(c
m2
)=154854,前者比后者k2小。
[0141]
第2次gmp开销
[0142][0143]
第3次gmp映射,n1=1230621,首先判断k1
×
(n1 n2 n3)-k2
×
(c
m1
′
c
m2
′
int(c
m3
))与k2的比较结果,前者k1
×
(n1 n2 n3)-k2
×
(c
m1
′
c
m2
′
int(c
m3
))=232281,前者比后者k2小。
[0144]
第3次gmp开销
[0145][0146]
第4次gmp映射,n1=1230622,首先判断k1
×
(n1 n2 n3 n4)-k2
×
(c
m1
′
c
m2
′
c
m3
′
int(c
m4
))与k2的比较结果,前者k1
×
(n1 n2 n3 n4)-k2
×
(c
m1
′
c
m2
′
c
m3
′
int(c
m4
))=39826,前者比后者k2大。
[0147]
第4次gmp开销第4次gmp开销
[0148][0149]
以上为cpri-7业务的cm和σc
nd
生成模块具体实现过程,对于第5,6,7,...次的gmp映射都可以依此类推。
[0150]
以cpri-4通过gmp映射到flexo_fr帧为例,系统设计时,客户侧数据位宽为cpri-4业务线速率经过8b10b解码,数据处理位宽为32bit,cpri-4数据经过64b66b编码,再通过bmp映射到oduflex中,最终等效的客户侧数据位宽即oduflex数据位宽为w1=32
×
66/64
×
239/238,oduflex占用flexo_fr帧的3个时隙,即ts=3,映射颗粒度m=16*3byte。由(8)式可得并化为最简分数形式:
[0151][0152]
上式可以化简为:
[0153][0154]
上式中分子分母存在最大公约数32
×
32
×
41088=2629632,那么(9)式化为最简分数可以得到k1=7887,k2=91392。
[0155]
第1次gmp映射,n1=384569,首先判断k1
×
(n1)-k2
×
(int(c
m1
))与k2的比较结果,前者k1
×
(n1)-k2
×
(int(c
m1
)=69939,后者k2=91392,前者比后者小。
[0156]
第1次gmp开销第1次gmp开销
[0157][0158]
第2次gmp映射,n1=384569,首先判断k1
×
(n1 n2)-k2
×
(c
m1
′
int(c
m2
))与k2的比较结果,前者k1
×
(n1 n2)-k2
×
(c
m1
′
int(c
m2
))=139878,后者k2=91392,前者比后者大。
[0159]
第2次gmp开销第2次gmp开销
[0160][0161]
第3次gmp映射,n1=384570,首先判断k1
×
(n1 n2 n3)-k2
×
(c
m1
′
c
m2
′
int(c
m3
))与k2的比较结果,前者k1
×
(n1 n2 n3)-k2
×
(c
m1
′
c
m2
′
int(c
m3
))=124692,后者k2=91392,前者比后者大。
[0162]
第3次gmp开销第3次gmp开销
[0163][0164]
第4次gmp映射,n1=384569,首先判断k1
×
(n1 n2 n3 n4)-k2
×
(c
m1
′
c
m2
′
c
m3
′
int(c
m4
))与k2的比较结果,前者k1
×
(n1 n2 n3 n4)-k2
×
(c
m1
′
c
m2
′
c
m3
′
int(c
m4
)=102699,后者k2=91392,前者比后者大。
[0165]
第4次gmp开销第4次gmp开销
[0166][0167]
以上就是cpri-4业务的cm和σc
nd
生成模块的具体实现过程,对于cpri-4业务的第5,6,7,...次的gmp映射都可以依此类推。
[0168]
以上仅为本发明的实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均包含在申请待批的本发明的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。