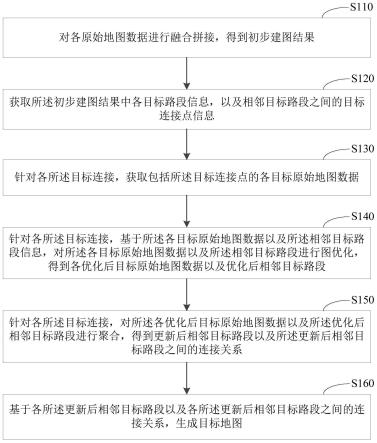
1.本发明涉及光学神经网络领域,具体涉及一种基于光学片上超表面的光子衍射神经元及其实现方法。
背景技术:
2.在大部分基于片上集成波导的光学神经网络设计中的主要结构单元为波导合束分束单元及马赫曾德尔干涉仪mach-zehnder interferometers(mzi)单元,其输入局限于两个输入通道,输出局限于一个或两个输出通道。这样的单元结构设计难以满足神经网络的计算需求,例如,在有多个输入通道的全连接神经网络中,每个输出神经元都需要与所有输入通道相连。即使对于连接较为稀疏的卷积神经网络而言,大小为3
×
3的卷积核也至少需要将9个输入通道与一个输出通道直接相连。这些设计都无法通过单个mzi结构实现,需要使用多个级联的mzi复合结构。然而使用多个级联的mzi实现单一神经元功能不仅会导致器件尺寸上的浪费,还会由于mzi中不可避免的能量损耗造成输出强度低,计算精度下降。
3.另一方面,衡量神经网络性能的一个标志性指标为网络参数数量。一般来说,对于相同的结构框架设计,宽度大、层数多等具有更多网络参数的神经网络通常性能更好。但是对于以mzi作为结构单元的神经网络而言,由于每一个mzi结构都需要对应的热光调制器和配套的电极结构,包含成百上千参数量的神经网络在制造工艺方面会面临困难,难以与计算机中参数量为百万量级的主流模型相比拟。在基于集成波导的光学平台上难以实现实用规模的神经网络计算的主要原因在于级联的mzi规模较大,且包含了额外的调制结构,造成整体集成度低,无法在有限的器件面积中实现足够规模的神经网络计算。因此,对目前需要进一步拓展功能的片上集成光学神经网络来说,提高神经元的集成度是一个亟待解决的问题。
技术实现要素:
4.为了提高神经元的集成度,解决片上集成光学神经网络中参数密度低的问题,本发明提出了一种基于光学片上超表面的光子衍射神经元及其实现方法,以实现高集成度多输入、多输出的全光片上集成光子衍射神经元。
5.类比于计算机神经网络,网络中前几个卷积层用于提取低层次特征,普适性较强,因此在迁移学习等任务中,均为直接使用预训练的权重,而仅需对于网络最后几层的权重进行微调训练;因此,针对在多数情况下,用于硬件实现的光学神经网络没有进行完全的片上训练的需求,从而在网络中的光学结构里都引入支持实时调节权重的光调制器是超出必要的。使用固定权重并去掉复杂的调制器件能够有效提高神经元的集成度;而相比于固定的mzi结构,使用自由度更高的光学片上超表面单元能够更加有效的利用器件面积,提高光学连接密度。
6.本发明的一个目的在于提出一种基于光学片上超表面的光子衍射神经元。
7.本发明的基于光学片上超表面的光子衍射神经元包括:介质基板、输入波导、输出
波导、优化区域和散射元;其中,介质基板为平板状,采用在设定波长下对光的传输没有损耗的材料;介质基板的一侧为入射端,另一侧为出射端,入射端一侧的形状为圆弧形;输入波导连接至介质基板的输入端,介质基板的出射端连接至输出波导;输入波导包括n个输入通道,输出波导包括m个输出通道;对应每一个输入通道,在介质基板上紧贴靠近输入波导的位置设置多个优化区域,所有的优化区域围绕入射端的圆弧放置;每一个优化区域为矩形,优化区域的宽度与输入波导末端尺寸一致,长度为宽度的0.8~1倍;在优化区域内形成各个散射元,散射元采用折射率与介质基板不同的材料,通过反向设计方法得到优化区域内的散射元的位置和形状,从而在介质基板上的优化区域内形成散射元构成光学片上超表面结构,m和n均为≥2的自然数;
8.在计算机中建立单独的神经元的计算机模型,加入符合以光子作为信息载体的训练模型的约束条件,包括需要满足能量守恒定律以及采用复数编码;采用优化器以梯度下降的优化方式对神经元构成的神经网络在计算机上进行训练;当对神经元的各个输入通道输入相干光时,神经网络的参数信息编码在每个输入通道的光的输入复振幅和输出通道的光的目标复振幅中,光的输入和目标复振幅中包含了光的振幅和和相位信息;由于使用光的振幅和相位计算缓慢且不稳定,将光的振幅和相位通过欧拉公式转换为复数的实部和虚部,使每一个神经元的权重矩阵成为一个复数矩阵;在训练过程中,采用损失函数作为预测值和目标值之间误差的度量,损失函数用于在优化器中计算并更新神经网络的每一层权重矩阵的实部和虚部;得到训练之后的神经网络的权重矩阵,每个神经元的权重矩阵的维数为n
×
m,用反向设计方法优化的每一个光学片上超表面结构需要实现输入通道与输出通道之间的全连接,通过权重矩阵得到每一个输出通道的目标复振幅;对每个神经元,1
×
m维的输出复振幅a
output
写为n
×
m维的权重矩阵w与1
×
n维的输入复振幅a
input
进行矩阵向量乘法之后的结果,即a
output
=wa
input
,并从输出通道的目标复振幅a
output
中提取出每个输出通道的目标平均相位和目标输出功率,其中,a
om
为第m输出通道的振幅,第m输出通道的目标平均相位为第m输出通道的目标输出功率为t
om
=|a
om
|2,m=1,
…
,m;
9.采用拓扑优化的密度惩罚算法对优化区域内的材料的折射率分布进行计算,将优化区域内的部分介质基板换成散射元,折射率的初始条件为散射元的折射率与介质基板的折射率的均值,简化各向同性材料惩罚指数为固定值;设定目标函数为:其中,神经元每个输出通道的平均相位和输出功率是无量纲且归一化的,和tm分别表示经算法优化得到的第m输出通道的平均相位和输出功率,和t
om
分别表示从神经网络的训练结果中获得的第m输出通道的目标平均相位和目标输出功率,m为输出通道的个数;在经过n次迭代,当误差小于设定阈值时目标函数已收敛,停止优化,将拓扑优化的结果二值化以匹配材料真实折射率,其中一个值为介质基板的折射率,一个值为散射元的折射率,从而在优化区域中得到散射元的位置和形状;
10.将优化出的各个光子衍射神经元在纵向独立平行排列成阵列,将各个光子衍射神经元的输入波导局部连接至上一层的输出波导,将输出波导局部连接到下一层光子衍射神经元的输入波导,或者非线性层或探测器,得到完整的片上光学神经网络;
11.光信号从输入波导的一个输入通道进入至优化之后的光学片上超表面结构,优化
区域内的散射元散射光信号;优化区域围绕圆弧放置,从而最大限度地减少散射损耗;经输入波导进入光学片上超表面结构的光信号在优化区域内发生设定的衍射,光学片上超表面结构对入射光信号的影响等同于权重矩阵与输入通道的光的输入复振幅进行矩阵向量乘法,继而在输出波导的每一个输出通道收集计算后的目标复振幅。
12.将所得的多输入多输出的高连接密度的光子衍射神经元进行局部连接,构成构型通用、高效且紧凑的光学神经网络。
13.对于光波长在1550nm附近的通信波段,介质基板采用硅、氮化硅、铌酸铌和有机聚合物等光波导介质材料中的一种。
14.本发明的另一个目的在于提出一种基于光学片上超表面的光子衍射神经元的实现方法。
15.本发明的基于光学片上超表面的光子衍射神经元的实现方法,包括以下步骤:
16.1)设置光子衍射神经元:
17.提供介质基板,介质基板为平板状,采用在设定波长下对光的传输没有损耗的材料;
18.质基板的一侧为入射端,另一侧为出射端,入射端一侧的形状为圆弧形;输入波导连接至介质基板的输入端,介质基板的出射端连接至输出波导;输入波导包括n个输入通道,输出波导包括m个输出通道;对应每一个输入通道,在介质基板上紧贴靠近输入波导的位置设置多个优化区域,所有的优化区域围绕入射端的圆弧放置;
19.每一个优化区域为矩形,优化区域的宽度与输入波导末端尺寸一致,长度为宽度的0.8~1倍;在优化区域内形成各个散射元,散射元采用折射率与介质基板不同的材料,通过反向设计方法得到优化区域内的散射元的位置和形状,从而在介质基板上的优化区域内形成散射元构成光学片上超表面结构,m和n均为≥2的自然数;
20.2)在计算机中建立单独的神经元的计算机模型,加入符合以光子作为信息载体的训练模型的约束条件,包括需要满足能量守恒定律以及采用复数编码;采用优化器以梯度下降的优化方式对神经元构成的神经网络在计算机上进行训练;当对神经元的各个输入通道输入相干光时,神经网络的参数信息编码在每个输入通道的光的输入复振幅和输出通道的光的目标复振幅中,光的输入和目标复振幅中包含了光的振幅和和相位信息;由于使用光的振幅和相位计算缓慢且不稳定,将光的振幅和相位通过欧拉公式转换为复数的实部和虚部,使每一个神经元的权重矩阵成为一个复数矩阵;在训练过程中,采用损失函数作为预测值和目标值之间误差的度量,损失函数用于在优化器中计算并更新神经网络的每一层权重矩阵的实部和虚部;得到训练之后的神经网络的权重矩阵,每个神经元的权重矩阵的维数为n
×
m,用反向设计方法优化的每一个光学片上超表面结构需要实现输入通道与输出通道之间的全连接,通过权重矩阵得到每一个输出通道的目标复振幅;对每个神经元,1
×
m维的输出复振幅a
output
写为n
×
m维的权重矩阵w与1
×
n维的输入复振幅a
input
进行矩阵向量乘法之后的结果,即a
output
=wa
input
,并从输出通道的目标复振幅a
output
中提取出每个输出通道的目标平均相位和目标输出功率,其中,a
om
为第m输出通道的振幅,第m输出通道的目标平均相位为第m输出通道的目标输出功率为t
om
=|a
om
|2;
21.3)采用拓扑优化的密度惩罚算法对优化区域内的材料的折射率分布进行计算,将优化区域内的部分介质基板换成散射元,折射率的初始条件为散射元的折射率与介质基板
的折射率的均值,简化各向同性材料惩罚指数为固定值;设定目标函数为:其中,神经元每个输出通道的平均相位和输出功率是无量纲且归一化的,和tm分别表示经算法优化得到的第m输出通道的平均相位和输出功率,和t
om
分别表示从神经网络的训练结果中获得的第m输出通道的目标平均相位和目标输出功率,m为输出通道的个数,m=1,
…
,m;在经过n次迭代,当误差小于设定阈值时目标函数已收敛,停止优化,将拓扑优化的结果二值化以匹配材料真实折射率,其中一个值为介质基板的折射率,一个值为散射元的折射率,从而在优化区域中得到散射元的位置和形状;
22.4)将优化出的各个光子衍射神经元在纵向独立平行排列成阵列,将各个光子衍射神经元的输入波导局部连接至上一层的输出波导,将输出波导局部连接到下一层光子衍射神经元的输入波导,或非线性层或探测器,得到完整的片上光学神经网络;
23.5)光信号从输入波导的一个输入通道进入至优化之后的光学片上超表面结构,优化区域内的散射元散射光信号;优化区域围绕圆弧放置,从而最大限度地减少散射损耗;经输入波导进入光学片上超表面结构的光信号在优化区域内发生设定的衍射,光学片上超表面结构对入射光信号的影响等同于权重矩阵与输入通道的光的输入复振幅进行矩阵向量乘法,继而在输出波导的每一个输出通道收集计算后的目标复振幅。
24.其中,在步骤2)中,以梯度下降的优化方式对神经元构成的神经网络进行训练中,采用优化器的误差反向传播算法,优化器的两个动量超参数(betas)设置范围为[0,1),学习率设置范围为0~1。在优化器中计算并用于更新网络变量的过程中,通过开源的python机器学习库pytorch后端所支持的自动化实现。
[0025]
在步骤3)中,各向同性材料惩罚指数的固定值的取值范围为3~5。迭代次数n为500~1000。损失函数的设定阈值小于0.01。
[0026]
本发明的优点:
[0027]
本发明通过将片上波导与光学片上超表面结构相结合,实现了高度集成的多输入多输出新型光子衍射神经元结构,解决了光学神经网络中参数密度低的问题,扩展了光学神经网络的功能,为大规模光学神经网络提供了可能。
附图说明
[0028]
图1为本发明的基于光学片上超表面的光子衍射神经元的一个实施例的示意图;
[0029]
图2为本发明的基于光学片上超表面的光子衍射神经元构成的光学神经网络的一个实施例的示意图。
具体实施方式
[0030]
下面结合附图,通过具体实施例,进一步阐述本发明。
[0031]
如图1所示,本实施例的基于光学片上超表面的光子衍射神经元包括:介质基板、输入波导、输出波导、优化区域和散射元;其中,介质基板为平板状,采用220nm厚的硅,在工作光波长1550nm对光的传输没有损耗,折射率为3.45;介质基板的一侧为入射端,另一侧为出射端,入射端一侧的形状为圆弧形;输入波导连接至介质基板的输入端,介质基板的出射端连接至输出波导;输入波导包括四个输入通道分别为in1~in4,输出波导包括四个输出
通道out1~out4;对应每一个输入通道,在介质基板上紧贴靠近输入波导的位置设置多个优化区域,优化区域如图1中的白色矩形实线所示,所有的优化区域围绕入射端的圆弧放置;每一个优化区域为矩形,优化区域的宽度与输入波导末端尺寸一致,长度为宽度的0.8倍,图1中沿着入射端的圆弧的方向是宽,与宽垂直的方向是长;在优化区域内形成各个散射元,散射元采用空气,即在硅的介质基板上形成空气孔,如图1中的白色矩形内的白色部分,折射率为1,通过反向设计方法得到优化区域内的散射元的位置和形状,从而在介质基板上的优化区域内形成散射元构成光学片上超表面结构;
[0032]
在计算机中建立单独的神经元的计算机模型,加入符合以光子作为信息载体的训练模型的约束条件,包括系统需要满足能量守恒定律以及采用复数编码;采用优化器以梯度下降的优化方式对神经元构成的神经网络在计算机上进行训练,具体涉及到使用自适应矩估计(adam)优化器的误差反向传播算法,优化器的两个动量超参数(betas)设置为(0.9,0.999),学习率设置为0.001;当对神经元的各个输入通道输入相干光时,神经网络的参数信息编码为在每个输入通道的光的相对振幅和相位上;由于使用光的振幅和相位计算缓慢且不稳定,将光的振幅和相位通过欧拉公式转换为复数的实部和虚部,输入光为输入复振幅,输出光为目标复振幅,使每一个神经元的权重矩阵成为一个复数矩阵;在训练过程中,采用均方误差损失函数mse作为预测值和目标值之间误差的度量,损失函数用于在优化器中计算并更新神经网络的每一层权重矩阵的实部和虚部,此过程通过pytorch(一个开源的机器学习框架,内置支持使用python的gpu加速)后端所支持的自动化实现;得到训练之后的神经网络的权重矩阵,每个神经元的权重矩阵的维数为4
×
4,用反向设计方法优化的每一个光学片上超表面结构需要实现输入通道与输出通道之间的全连接,通过权重矩阵得到每一个输出通道的目标复振幅;对每个神经元,1
×
4维的输出复振幅a
output
写为4
×
4维的权重矩阵w与1
×
4维的输入复振幅a
input
进行矩阵向量乘法之后的结果,即a
output
=wa
input
,并从输出通道的目标复振幅提取出每个输出通道的目标平均相位和目标输出功率;
[0033]
采用拓扑优化的密度惩罚算法对优化区域内的材料的折射率分布进行计算,将优化区域内的部分介质基板换成散射元,折射率的初始条件为散射元的折射率与介质基板的折射率的均值,初始条件为0.5,简化各向同性材料惩罚指数为固定值,取值范围5;设定目标函数为:其中,神经元每个输出通道的平均相位和输出功率是无量纲且归一化的,和tm分别表示经算法优化得到的第m输出通道的平均相位和输出功率,和t
om
分别表示从神经网络的训练结果中获得的第m输出通道的目标平均相位和输出功率,m为输出通道的个数;在经过500~1000次迭代,当时,认为目标函数已收敛,停止优化,将拓扑优化的结果二值化以匹配材料真实折射率,其中一个值为介质基板硅的折射率,一个值为散射元空气的折射率,从而在优化区域中得到散射元空气的位置和形状;
[0034]
如图2所示,将优化出的各个光子衍射神经元在纵向独立平行排列成阵列,将各个光子衍射神经元的输入波导局部连接至上一层的输出波导,将上一层的光子衍射神经元u1的输出波导局部连接到下一层的两个光子衍射神经元u2和u3的输入波导,得到完整的片上光学神经网络;
[0035]
光信号从输入波导的一个输入通道进入至优化之后的光学片上超表面结构,在图
1中光信号采用末端带箭头的白色虚线表示,即光信号从输入通道经光学片上超表面结构至输出通道,优化区域内的散射元散射光信号;优化区域围绕圆弧放置,从而最大限度地减少散射损耗;经输入波导进入光学片上超表面结构的光信号在优化区域内发生设定的衍射,光学片上超表面结构对入射光信号的影响等同于权重矩阵与入射光的复振幅进行矩阵向量乘法,继而在输出波导的每一个输出通道收集计算后的目标复振幅。
[0036]
最后需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。